Dataflowのパフォーマンスが気になった時のメモです。
Cloud monitoring、Cloud Profiler、メモリダンプがDataflowで使えます。
Cloud monitoring
Cloud monitoringでJVMのメモリ使用量などをモニタリングする事が出来ます。
わかること
- JVMのメモリ使用量
- スレッド数
- その他agent metrics
試してみる
デフォルトでは無効なので、--experiments=enable_stackdriver_agent_metricsで、パイプラインの起動時(もしくはテンプレートのビルド時)に有効にします(※)。
※ experimentsとなっていますが何か懸念事項があるかは不明です‥
Google提供のテンプレートのPubSubToTextで試してみます。下から二行目が追加した部分です。
mvn compile exec:java \
-Dexec.mainClass=com.google.cloud.teleport.templates.PubSubToText \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--project=${PROJECT_ID} \
--stagingLocation=gs://${PROJECT_ID}/dataflow/pipelines/${PIPELINE_FOLDER}/staging \
--tempLocation=gs://${PROJECT_ID}/dataflow/pipelines/${PIPELINE_FOLDER}/temp \
--runner=DataflowRunner \
--windowDuration=2m \
--numShards=1 \
--inputTopic=projects/${PROJECT_ID}/topics/windowed-files \
--outputDirectory=gs://${PROJECT_ID}/temp/ \
--outputFilenamePrefix=windowed-file \
--experiments=enable_stackdriver_agent_metrics \
--outputFilenameSuffix=.txt"
ジョブ起動後、Cloud Monitoringで指標を確認することが出来ます。デフォルトではインスタンス毎ですが、ジョブ名でGroup Byすることも出来ます。
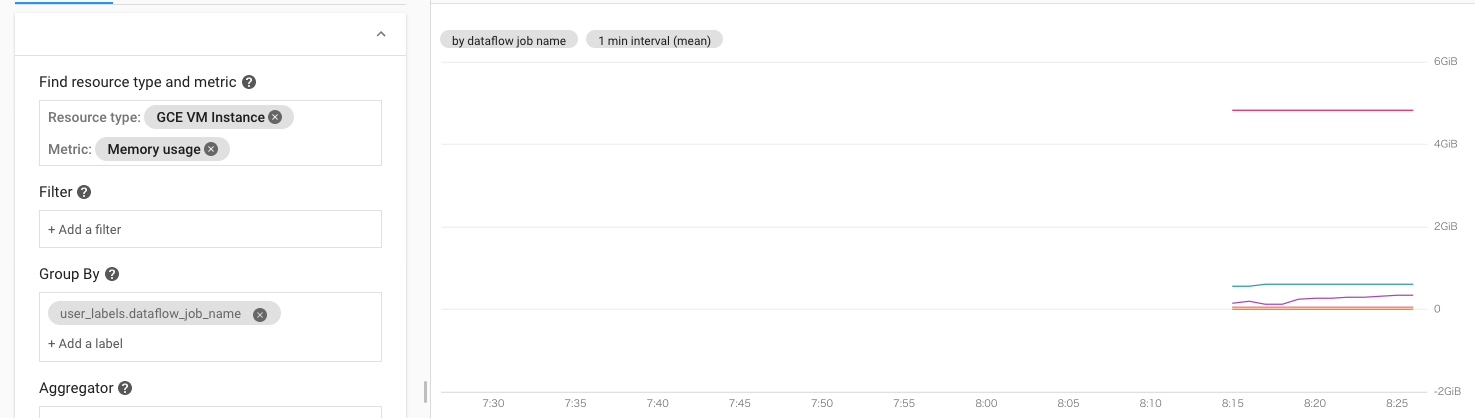
なお、Word Countでも試したのですが、こちらはMonitoringに表示されませんでした‥(原因は未調査。実行時間が短い?)
Stackdriver Profiler
Googleの中の人がMeidumで紹介している方法です。
わかること
- CPU時間のフレームグラフ
- 実時間のフレームグラフ
Stackdriver ProfilerはJavaだとヒープも取れそうですが、Dataflowで取れるかはわかりませんでした‥
試してみる
profilingAgentConfiguration='{ "APICurated": true }'オプションを有効にする必要があります。
なお、Cloud Monitoringと同時に使うことも出来ます。
* mvn compile exec:java \
-Dexec.mainClass=com.google.cloud.teleport.templates.PubSubToText \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--project=${PROJECT_ID} \
--stagingLocation=gs://${PROJECT_ID}/dataflow/pipelines/${PIPELINE_FOLDER}/staging \
--tempLocation=gs://${PROJECT_ID}/dataflow/pipelines/${PIPELINE_FOLDER}/temp \
--runner=DataflowRunner \
--windowDuration=2m \
--numShards=1 \
--inputTopic=projects/${PROJECT_ID}/topics/windowed-files \
--outputDirectory=gs://${PROJECT_ID}/temp/ \
--outputFilenamePrefix=windowed-file \
--experiments=enable_stackdriver_agent_metrics \
--outputFilenameSuffix=.txt"
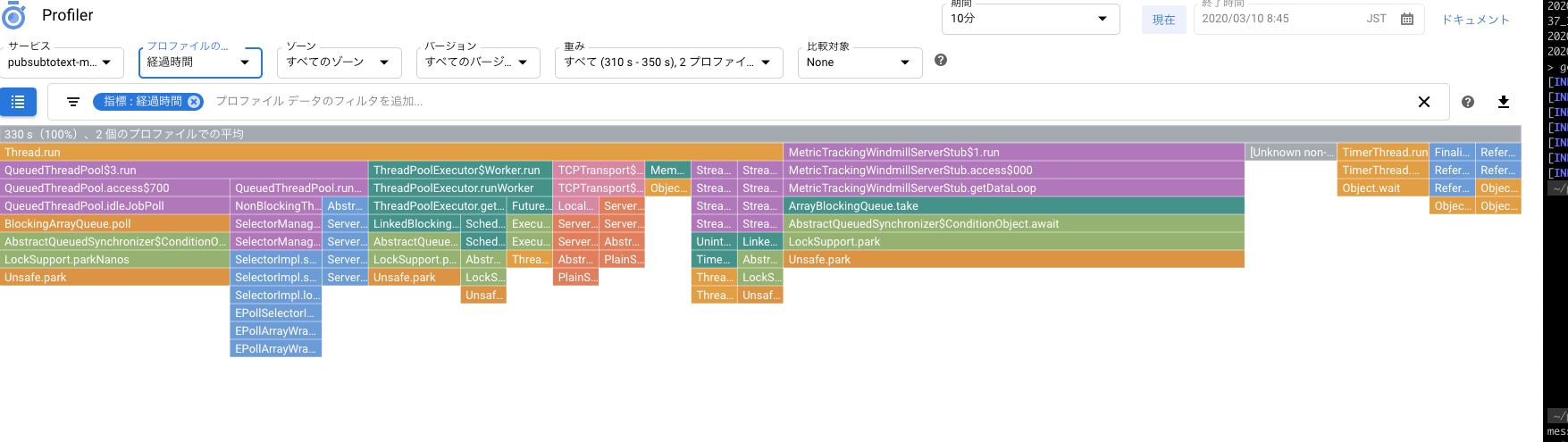
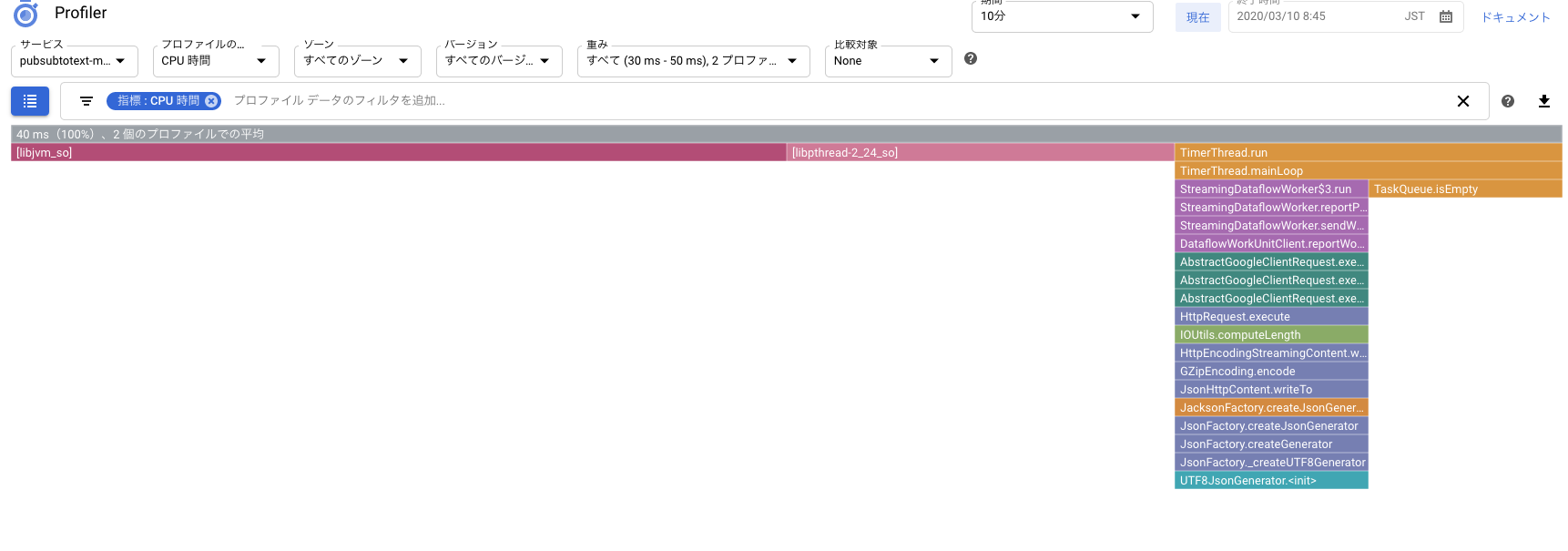
グラフの見方はStackdriver Profilerのクイックスタートや、フレームグラフの説明を参考にしてください。
メモリダンプ
Google Cloud Platform Communityで紹介されていますが、定番のメモリダンプも使えます。
上述の2つの方法と違い、ジョブ全体ではなく、インスタンス単位で見ることになります。
ダンプを取る方法は
- OOM時にGCSに出力するオプションを付ける
- --dumpHeapOnOOMと--saveHeapDumpsToGcsPath
- Dataflowワーカーに接続し、ヒープダンプをダウンロードする
- JMX経由で接続する
の三種類が紹介されています。今回はワーカーからのダウンロードを試してみます。
わかること
- インスタンス毎のJVMのメモリ使用状況
- 誰がメモリを多く使っている
- 参照の関係
試してみる
以下の手順で行います:
- パイプラインの起動
- ヒープダンプの作成
- ローカルにダウンロード
- 見てみる
特にオプションや注意点はないので、パイプラインの起動は省略します。
ヒープダンプの作成
Dataflowワーカーに入ってヒープダンプを作ります。
なお、GCEインスタンスにはDataflowのジョブID・ジョブ名のラベルが付くので、それでインスタンスを特定出来ます(下例)。
gcloud compute instances list --filter='labels.dataflow_job_name=${job_name}'
SSHトンネルを作ります:
gcloud compute ssh --project=$PROJECT --zone=$ZONE \
$WORKER_NAME --ssh-flag "-L 8081:127.0.0.1:8081"
ローカルにダウンロード
ブラウザでhttp://127.0.0.1:8081/heapzを開きます。
結構時間かかります(n1-standard-4で10分くらい)。
見てみる
VisualVMとか、好きなツールでダンプを見ませう。
スレッドやオブジェクトの状況が見れます。
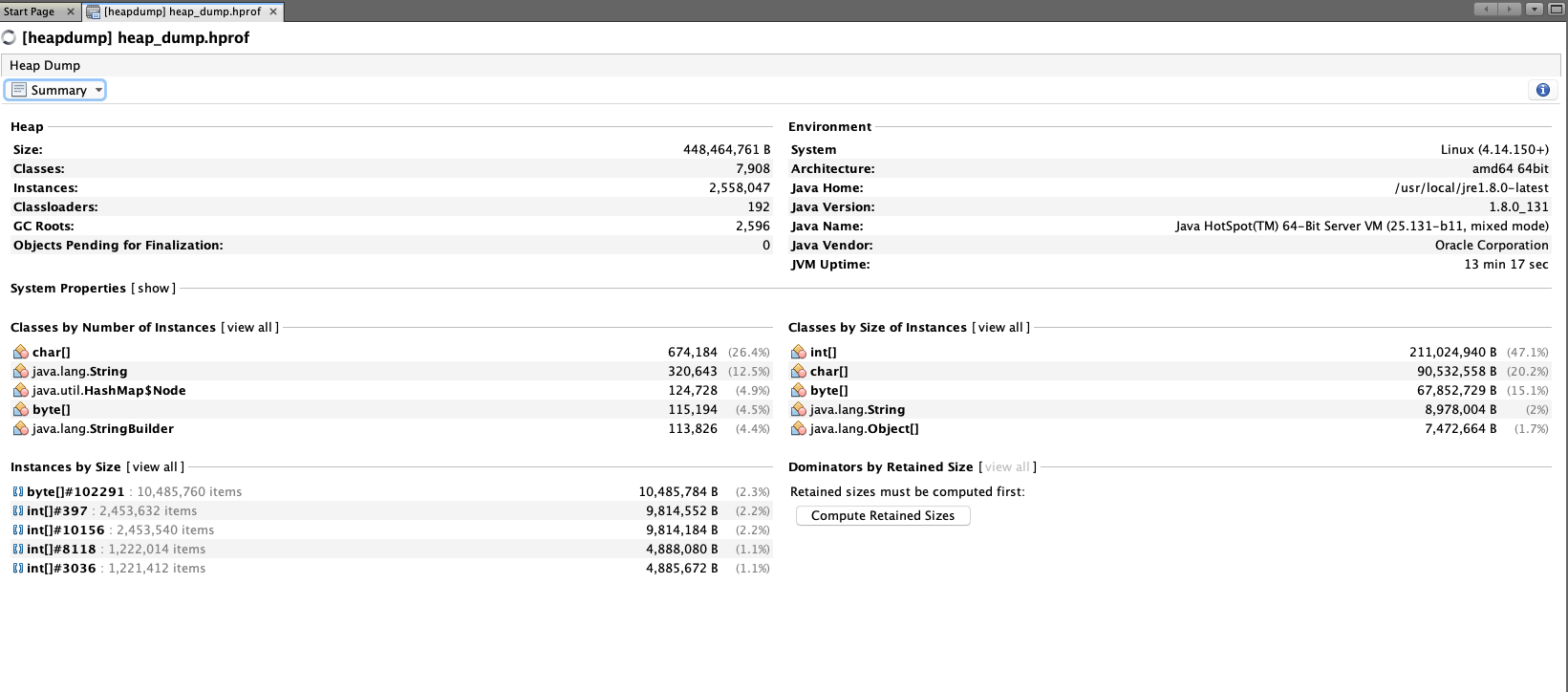
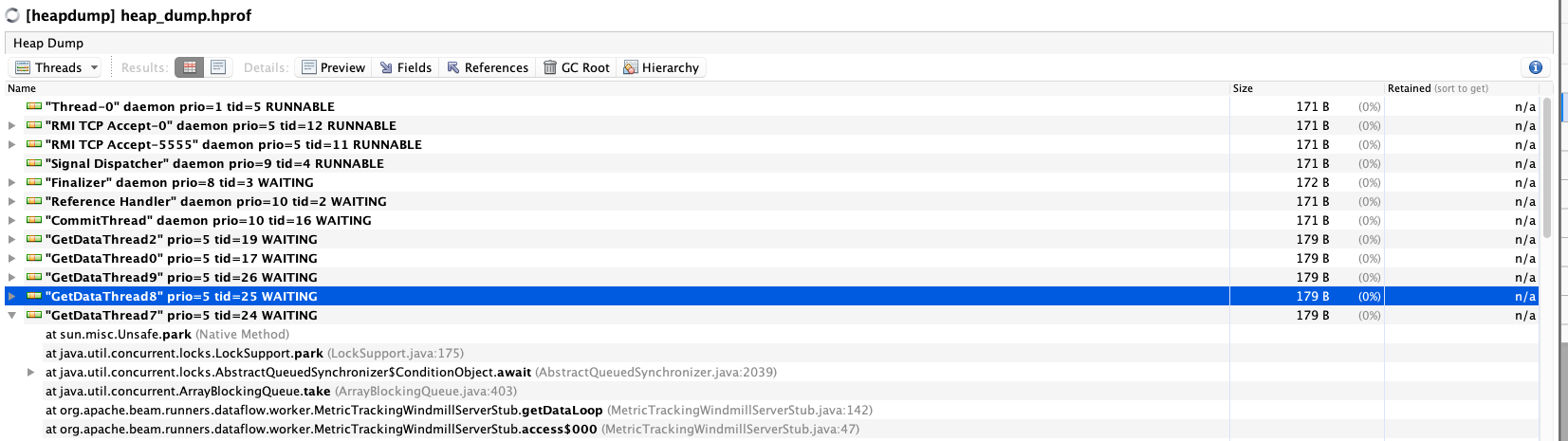
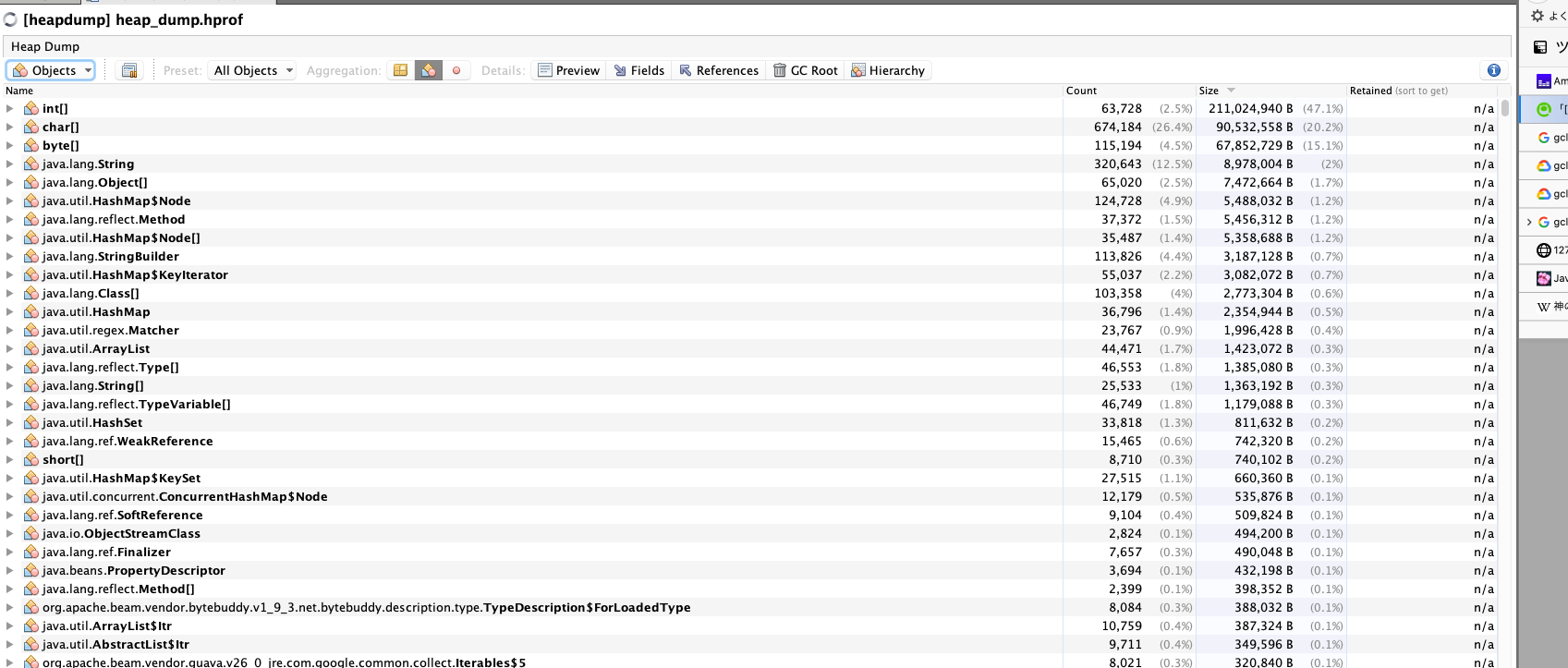
ヒープダンプの見方は先人が色々書いてくれていると思うので、頑張ってください(Javaパフォーマンスとか)。
注意点
今回試したワーカーからのダウンロードに関しては、いくつか注意点がいくつか記載されています:
- ダンプを取ることが、パイプラインのパフォーマンスに影響を与える
- ヒープダンプが一時的にワーカーのディスクに置かれるので、容量に注意
- 少なくとも30GB+メモリ分は必要らしい