だからどうしたという話ですが、GzipFileを使ったコードを書いていて気がついたのでメモです。
GzipFileとは
コンストラクタにファイル名を渡すとローカルのGzipファイル、fileobjを渡すことでファイル「っぽい」Gzipオブジェクトの読み書きが出来ます。
BufferedReaderを使っている箇所
GzipFileのコンストラクタ内では、下の図のように
- 実際のioClass(引数のfileobj、もしくはファイル名から取得したファイル)を
- 実際の読み込みを行う_GzipReaderでラップ
- さらに、それをBufferedReaderでラップ
する関係になっており、GzipFileをreadする時はBufferedReaderを経由することになります(※)。
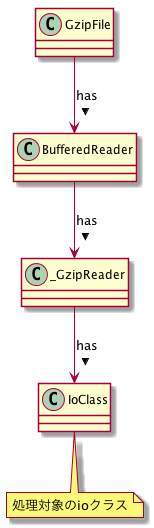
※より正確には、_GzipReaderとIoClassの間に、_PaddedFileというクラスが挟まります
バッファのサイズを変えたい時
GzipFileはBufferedReaderのバッファーサイズにデフォルト(io.DEFAULT_BUFFER_SIZE)を使います。
読み込み対象のioによっては、より大きな単位でバッファしたい時もあるかもしれません(※)。
が、GzipFileの機能ではバッファサイズが変更出来ないようなので、GzipFileのfileobjにBufferedReaderを渡しましょう。
※ 例えば、GCSはダウンロードする単位が小さい(数KB単位)だと、パフォーマンスが落ちるそうです。