はじめに
AWS の Advent Calendar なのに、少し Digdag 色強めですが、Digdag を EC2 の AutoScalingGroup で冗長構成にした話です
元々 Digdag でジョブを管理していたのですが、今回以下の 2 つのことを解決するため、再度 Digdag 構成を作り直しました
- Digdag サーバ(EC2)の冗長構成
- 割り込みタスクが即時実行されること(タスクのキュー待ちが発生しない)
Digdag サーバ(EC2)の冗長構成について
Digdag には、以下の機能がある
| 機能 | 説明 |
|---|---|
| REST API Server | クライアントからのリクエストを受け付ける |
| Task Agent | タスクの実行を行う |
| Workflow Executor | ワークフローの実行管理 |
| Schedule Executor | ワークフローのスケジュール実行管理 |
今までは EC2 を 1 台立てて、その中で Digdag サーバを立てて、上記全ての機能を担っていたが、それをやめて複数台の冗長構成にしたい
REST API Server に関しては 1 台で、それ以外の Task Agent、Workflow Executor、Schedule Executor を行うサーバを冗長構成にする
また、EC2 の AutoScalingGroup でオートスケール構成にする
割り込みタスクが即時実行されること(タスクのキュー待ちが発生しない)
現在、Digdag 上で毎時で約 450 タスクを起動するワークフローが実行されている
各々のタスクはすぐ終わるようなものではなく、キューから中々解放されない
キューが溜まっている時に、割り込みタスクが入るとキューに残ったまま実行されないので、即時実行されるようにしたい
現在、Digdag サーバの起動オプションで--max-task-threads 100を指定しているので、解決策として以下の 2 つを考えた
-
--max-task-threads 500にする -
--max-task-threads 100のまま、タスク実行を行う Digdag を 5 台構成にする
今回は冗長構成にするので、2.のタスク実行を行う Digdag を 5 台構成にするでいきたいと思います
今までの構成

ユーザもしくは、Bot から Digdag サーバがリクエストを受け、リクエストを受けたサーバと同じサーバ上でワークフローのタスクを実行する
タスクの実行は Docker で行い、その中で EMR クラスターに ssh して、Spark を実行している
今回主に作り直した箇所は、上図の赤枠の部分になります
目指したい構成
https://techblog.zozo.com/entry/digdag_ha
かなり参考になりました!
ありがとうございます![]()
出来上がった構成
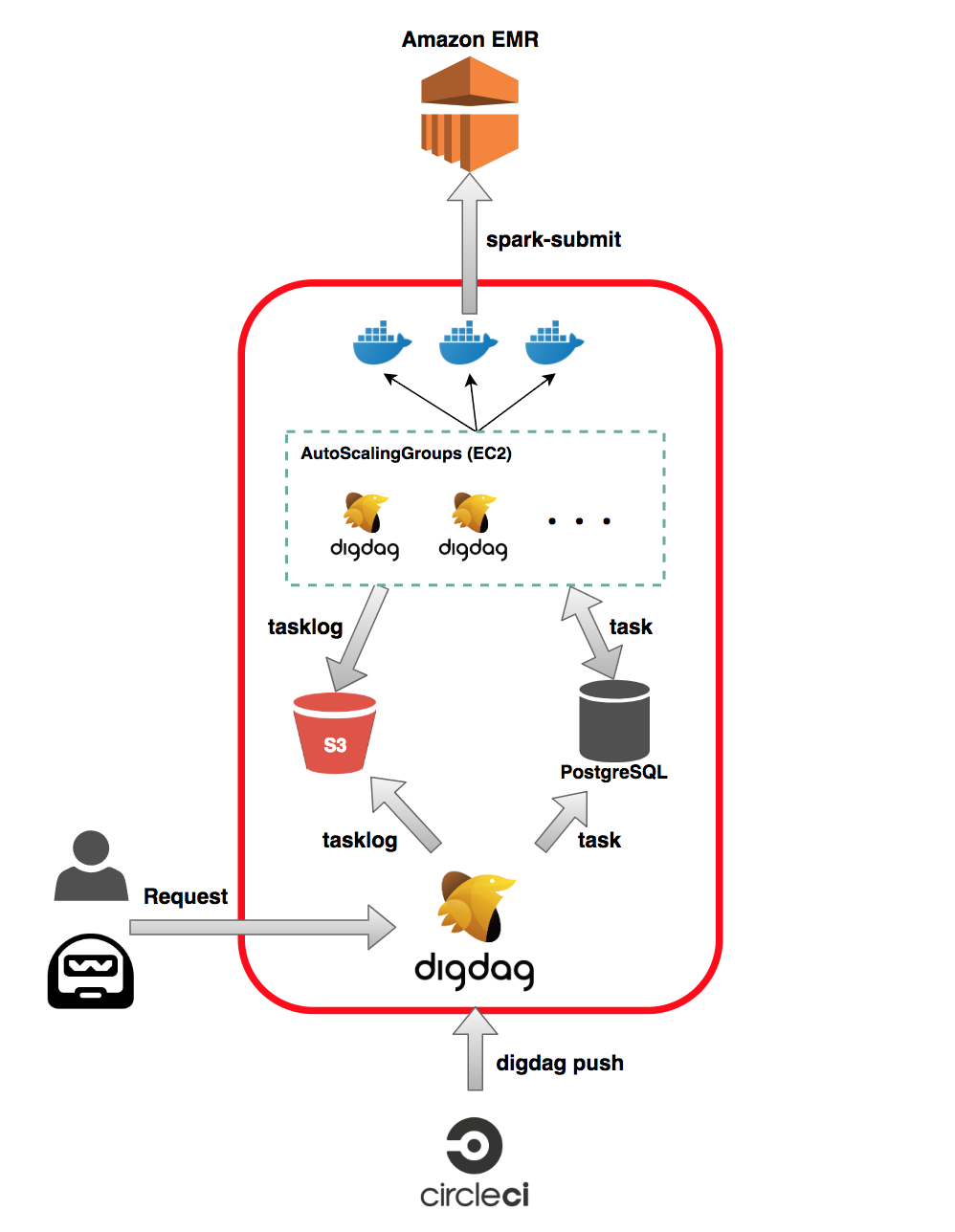
REST API Server としてのみ機能する Digdag サーバ
- 1 台構成
- ユーザもしくは、Bot からのリクエストを受け付ける唯一のサーバ
- タスクの実行は行わず、PostgreSQL のタスクキューにタスクをプッシュするまでが仕事
- PostgreSQL からタスクの状態を取得して、UI 上で確認できる機能
- EC2 インスタンスは、c5.large(安いインスタンスで問題無いと思う)
API Server 用の Digdag サーバを立ち上げるには、以下のコマンドを実行する
digdag server --disable-executor-loop --disable-local-agent ...
| オプション | 意味 |
|---|---|
| --disable-executor-loop | Workflow Executor と Schedule Executor を無効にする |
| --disable-local-agent | Task Agent を無効にする |
Task Agent、Workflow Executor、Schedule Executor の機能を持つ Digdag サーバ
- EC2 の AutoScalingGroup 構成で動く(今回は Max5 台)
- ユーザもしくは、Bot からのリクエストは受け付けない(API Server としての機能も持っているが、リクエストを飛ばさないようにする)
- Digdag サーバ 1 台ごとに Task Agent、Workflow Executor、Schedule Executor の機能を有している
- EC2 インスタンスは、c5.xlarge
Task Agent、Workflow Executor、Schedule Executor はそれぞれ以下の動きをしている
| 機能 | 動き |
|---|---|
| Task Agent | タスクキューからタスクを取り出して実行する |
| Workflow Executor | 実行中のタスクの状態をチェックし、実行可能タスクをキューにプッシュする |
| Schedule Executor | PostgreSQL 上のアクティブなスケジュールの状態をチェックし、タスクを開始する |
こちらの Digdag サーバは、--disable-executor-loopと--disable-local-agentを付けずに普通に起動すれば良い
digdag server ...
※ API Server サーバとしての機能を無効にするオプションは無い
タスクログや DB の設定について
Digdag サーバが複数台ある関係上、ローカル上でデータ・ファイル管理すると不都合なので、
Digdag のホームディレクトリに(/opt/digdagとか)に server.properties を作成し、以下の設定をする
## DBの設定(タスクキューテーブルなどの)
database.type = postgresql
database.user = ユーザ名
database.password = パスワード
database.host = PostgreSQLのホスト
database.port = 5432
database.database = digdag
## DigdagUI用の設定
server.bind = 0.0.0.0
server.port = 65432
## タスクログを吐き出す場所
log-server.type = s3
log-server.s3.bucket = S3のバケット名
log-server.s3.path = logs/tasklogs
Auto Scaling グループの作成について
起動設定(従来)または起動テンプレート(新規)を使って、作成するやり方がある
今回は、起動テンプレートを使って作成した
EC2 のダッシュボードから、Launch Templates を選択し、起動テンプレートの作成をする
従来の起動設定を使ったやり方と比較して、起動テンプレートを使うメリットは以下になると思う
- バージョン管理できる
- 構成の見える化
苦戦したことや検討が必要なこと
冗長構成に変えるのは、割と簡単にできたが、苦戦したことや検討が必要なことが多々あった
API Server は冗長構成にしなくてもいいのか
現在の構成だと、もし API Server が落ちたらリクエストを受け付けることができなくなるので、
本当はロードバランサーを挟んで複数台構成にすべき
(そのうち対応するかも)
スケーリングポリシーを設定していない
AutoScalingGroup を作成したのに、スケーリングポリシーを設定していないという、、
理由としては、Digdag タスクを Docker 上で実行しているので、EC2 の CPU 使用率があまり変わらず、メトリクスとして使えないという理由がある
AWS Fargate を使うか検討中
Digdag エラー その 1
java.lang.RuntimeException: Docker pull failed
原因と対応
なぜかタスク実行の Digdag で Docker が pull できない
対象のインスタンスに入って、docker psするとタスクキューが無いのにも関わらず、Docker が多数立ち上がったままになっていた
全て kill したら、このエラーは起きなくなった
タスクが失敗した際に、Docker が起動したままになっていたのか、原因は不明
(ちなみに最近は起きていない)
Digdag エラー その 2
docker: Error response from daemon: connection error: desc = "transport: dial unix /var/run/docker/containerd/docker-containerd.sock: connect: connection refused".
level=error msg="error waiting for container: context canceled"
Docker のよく分からないエラー
とりあえず再起動
service docker stop
service docker start
これも最近は起きていない
Digdag エラー その 3
java.lang.RuntimeException: Command failed with code 137
Digdag エラーだけだとよく分からない
Spark のエラーログを見てみると、以下のエラーが出ていた
WARN ShutdownHookManager: ShutdownHook '$anon$2' timeout, java.util.concurrent.TimeoutException
...
java.util.concurrent.TimeoutException
...
ERROR Utils: Uncaught exception in thread pool-4-thread-1
java.lang.InterruptedException
原因と対応
最初、今回の構成変更により、Digdag の並列数が増え、spark-submit する数が増えたので、Spark 上でメモリ解放待ちジョブがタイムアウトになったかと思い、以下を試してみた
-
--executor-memoryを上げてみる
⇒ 効果なし - Digdag の並列実行数を減らす
⇒ エラーは出なくなったけど、これやったら今回の構成変更で、せっかくスケールしやすくしたのにもったいない! - spark.network.timeout(default: 120)を上げてみる
⇒ 効果なし
その後、色々調べた結果、以下のページを発見
https://community.hortonworks.com/content/supportkb/208452/warn-shutdownhookmanager-shutdownhook-anon2-timeou.html
Spark 処理の最後で、SparkContext.stop()を実行してあげるとエラーは出なくなった
Digdag エラー その 4
fatal error: runtime: cannot allocate memory
とか
java.lang.RuntimeException: Command failed with code 2
↑Spark ではエラー無し
原因と対応
原因不明
まあまあの頻度でこの原因不明エラーが起きるので、Digdag 側でリトライ設定をしてみた
+exec_spark:
+exec_sh:
_retry: 3
sh>: spark.sh
タスクがエラーになると、そのタスクを 3 回までリトライする
かなり便利これ!
さいごに
本記事で「AutoScalingGroup のスケーリングポリシーを設定できていない」と書きましたが、これに対して Fargate を使う以外に考えてる案がもう 1 つあるので、紹介したいと思います
(まだ試せてない機能になりますが、、)
機械学習を用いた予測スケーリング機能(東京リージョンがまだ無し)
https://aws.amazon.com/jp/blogs/news/new-predictive-scaling-for-ec2-powered-by-machine-learning/
AWS の機械学習モデルに EC2 の推定トラフィックや利用状況を学習させ、予測し、適切な数の EC2 をプロビジョニングする
特徴は以下
- 2018/11/20 に発表された新しいサービス
- 予測に少なくとも 1 日分の履歴データが必要で、1 日毎に再評価され、次の 2 日間実行される
⇒ モデルに対して、適切な訓練データの量を判断するのが難しそう、モデルが過学習してしまうとサーバのちょっとした変化(Digdag による負荷の増減とか)にもスケーリング対応できなくなる恐れはないか - 無料で利用できる
⇒ さらにいい感じにモデルが学習でき、予測の精度が高ければ、手動スケーリング設定よりコストを抑えれる可能性がある - 現在は、EC2 のみサポート
- 定期的にトラフィックが変化しているアプリケーションに最適で、逆に不規則にトラフィックが変化するアプリケーションには向いていない
⇒ 予測外のトラフィックがあった場合に、どうゆう動きをするか気になる
モデルに対して適切な訓練データの量が判断できており、かつ、EC2 に対するトラフィックの増減が定期的な場合に効果を発揮してくれそう
本記事の構成では、EC2 内の Digdag が Docker を使っており、手動によるスケーリングポリシーの設定が難しい中で、いい感じにスケーリングしてくれたらかなり最高
もし東京リージョンがサポートされたら、是非試してみたい機能です!
2018/12/24追記
東京リージョン追加されてた
https://dev.classmethod.jp/cloud/aws/predictive-aws-autoscalling/