はじめに
Amazon EMRでApache Sparkを使って、レポートデータを集計するという業務に携わることになったのですが、
知らない用語が多すぎるので、簡単に基礎的な部分だけ、まとめたいと思います
Apache Hadoopの分散処理の構成
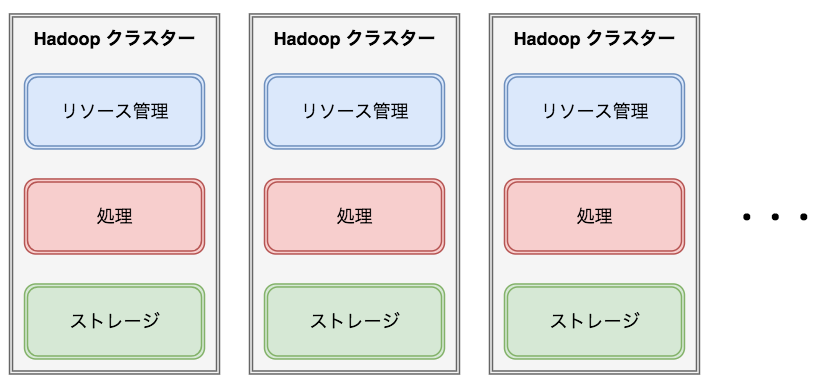
Amazon Elastic MapReduce(Amazon EMR)を使うと、Hadoopクラスターを立ち上げることができるので、
このクラスタ上にリソース管理、処理、ストレージのHadoopの分散構成を作る
■ リソース管理
Apache Mesos, Hadoop Yarn
■ 処理
Hadoop MapReduce, Apache Spark
■ ストレージ
HDFS, S3
ストレージとデータベース
Hadoopはログなどのファイルを取得し、ストレージに保管する
■ HDFS
Hadoop上で利用する分散ファイルシステム
データファイルロード時に128MB(デフォルト)ごとのブロックに分散される
各ブロックは3つ(デフォルト)にレプリケーションされ、複数ノードで保持している
メタデータ(データ格納先)は、NameNodeにシングルポイントで保持している
よって、NameNodeデーモンは常に起動しておく
write-once-read-manyモデル
Javaで書かれている
■ Apache HBase
HDFS上に構築するNoSQL分散データベース
スケールし、大量データに対応できる
データ取得
■ Apache Sqoop
HDFSとデータベースの双方向にデータをインポートできる
様々な形式でHDFSにインポートできる
データは、HadoopのMapReduceを使って書き込まれる
■ Apache Flume
データをHDFSへ一方通行で流す
■ Apache Kafka
Flumeより高機能
pub-subモデル
HDFSのファイルフォーマット
■ TextFile
writeが早い
特定のプログラミング言語に依存しない
バイナリを扱うのは難しいが、文字列なので見やすい
パフォーマンスは悪い
■ SequenceFile
key & valueをバイト列として格納している
MapReduceでの処理に適している
パフォーマンスが良い
■ AvroFile(Apache Avro)
シリアライズとデシリアライズが高速
スキーマの変更に強い
Hadoopのエコシステムで広く採用されている
ファイルにスキーマのメタデータを持つ
バイナリデータなので、avro-toolsを使ってスキーマやデータを扱う
パフォーマンスが良い
■ ParquetFile(Apache Parquet)
カラムナー型でデータを保存する
列方向に同じ種類のデータが保存されているので、パフォーマンスが良く、圧縮率も良い
逆に特定の行を取り出して、更新・削除することは苦手
ファイルにスキーマのメタデータを持つ
バイナリデータなので、parquet-toolsを使ってスキーマやデータを扱う
パフォーマンスが良い
Hadoop YARN
Yet Another Resource Negotiatorの略
Hadoopクラスターのリソース管理を行う

■ Master Node
・クラスターに1つだけ存在する
・Resource Manager(図ではRM)デーモンを実行する
⇒クラスター上で使用可能なノードのアプリケーション間の競合を調停し、どのタイミングでリソースを割り当てるかを決める
・HDFS Name Node(図ではNN)デーモンを実行する
⇒Data Nodeのメタデータを管理している
■ Core Node
・EMRだけの概念
・クラスターあたりに最低1つのCoreが必要
・Node Manager(図ではNM)デーモンを実行する
⇒RMと通信して、ノードのリソースを管理し、コンテナーを起動する
・HDFS Data Node(図ではDN)デーモンを実行する
⇒HDFSのデータの実体を保持
・Sparkを実行する
■ Task Node
・Taskはオプション
・Node Manager(図ではNM)デーモンを実行する
⇒RMと通信して、ノードのリソースを管理し、コンテナーを起動する
・Sparkを実行する
Hadoop MapReduce
Map処理とReduce処理を実装すれば、Hadoop側で分散して処理してくれる
■ Map
1度に1つのレコードを処理する
Key-Valueの組み合わせを作る
■ Reduce
Map出力後、動作する
集計処理などを実装する
以下はMapReduceで英文内の単語をカウントして、出力する例

各々のMapは独立している(変数などを共有していない)ため、分散させて並列処理することが可能
Reduceでは、同じキーを持つものを集約して処理(ここではSum)する
Reduceもキーが異なれば、分散させて並列処理することが可能
Apache Spark
Hadoopクラスター上で動いて、HDFS上のデータを処理する
MapReduceよりも高速
MapReduceがディスクにデータを保存するのに対し、Sparkはメモリ上に保存する
Scalaで書かれている
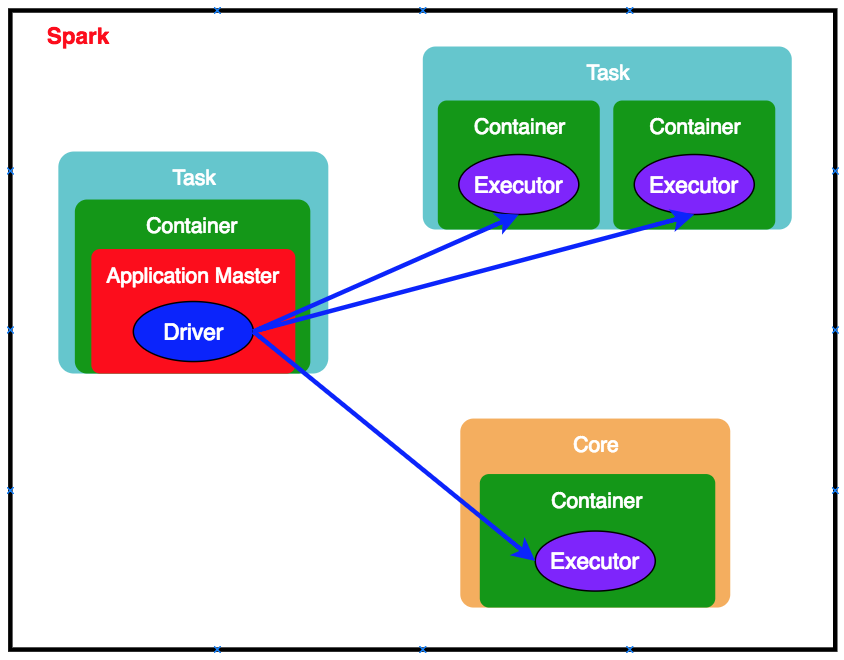
■ Container
・YARNから起動する
・リソース(メモリ・CPUコア)をノードに割り当てる
■ Application Master
・Resource ManagerがNode ManagerにApplication Master用のコンテナー割り当てを依頼し、作成される
・アプリケーションごとに1つ
■ Spark Driver
・Sparkアプリケーションを起動するプロセス
・Application Master内で起動される(YARNのclusterモードの場合)
※YARNのclientモードの場合は、クライアント側でDriverを起動する
・Executorにタスクを送信する
■ Executor
・以下の流れで起動される
① Application MasterがResource ManagerにExecutor起動用のリソース取得を依頼する
② 取得できた場合、Application MasterがNode ManagerにExecutorの起動を依頼する
③ Node ManagerがExecutorを起動する
・実際に処理(タスク)を行うスレッドになる
Sparkのアプリケーション構成
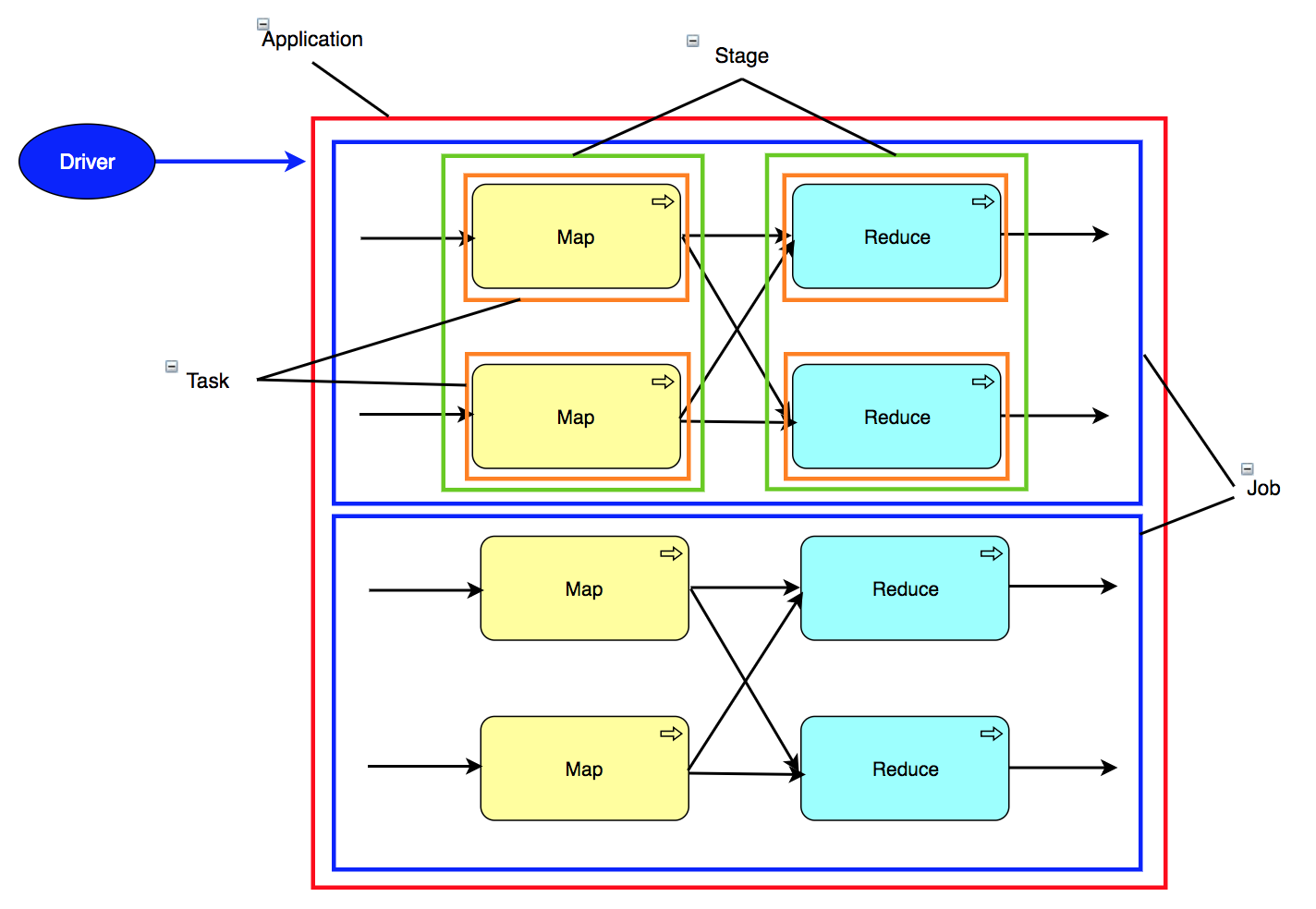
赤枠:Application
1つのDriverから管理されるJobのセット
青枠:Job
Taskのセット
緑枠:Stage
並列可能な実行中のTaskのセット
オレンジ枠:Task
1つのExecutorに送られる作業単位
RDD (Resilient Distributed Dataset)
Sparkでは、RDDにデータを保持して操作する
イミュータブルな分散コレクション
RDDのデータを操作する方法は、変換(Transformations)とアクション(Actions)の2通りがある
■ 変換
RDDはイミュータブルのため、変更する場合は、新しいRDDを作る
新しいRDDを作る(変換)の際は、filter, mapなどの関数をサポートする
変換に使える関数一覧
■ アクション
RDDに対して、countやreduceなどの関数をサポートする
アクションに使える関数一覧
変換は遅延評価されるため、アクションが実行されるまでRDDにあるデータは処理されない(その操作が要求されたことを示すメタデータのみを保存)
アクションを実行されて、初めて変換処理が実行される
Spark SQL
SQLライクな関数を使って、RDDを操作できる
Spark SQLのエントリーポイントはSQLContextである
SQLContextはSparkContextを使って生成する
DataFrameというRDDより抽象化されたデータ構造を使って操作する
DataFrameもイミュータブルである