まえがき
最近、AWS Glueが一般人でも使えるようになりました。そこでどんなものかと、調べてみました。一人で調べ物した結果なので、機能を正しく把握できているかいまいち自信がありませんが、理解した限りで公開します。
ハンズオンは他にゆずることにして、概観的な話を中心とします。
概要
AWS Glueは、日々行われるデータ集約やETL処理を自動化、およびサーバレス化するサービスです。
いま、未加工のCSVやJSONによるログデータや、
アプリケーションで使用している既存のデータベースなどがあるものの、
そのままでは分析が難しく、データ分析のために整備された領域が求められているとします。
AWS Glueの文脈では、前者をデータストア、後者をデータカタログと位置づけます。
データカタログは主に、フルマネージドなHDFS上のストレージ領域です。
たとえば、Amazon Athenaからデータカタログを分析することができます。
AWS Glueは以下の3要素からなります。
- データ分析の中央リポジトリでありデータを一元管理するデータカタログ
- 様々なデータストアからデータカタログにデータを集約するクローラ
- データカタログ内のデータをETLするジョブ
AWS Glueによって、データ分析基盤のサーバレス化を進めることができます。たとえば、 (Customer's Application)-> S3 -(Glue Crawler)-> Data Catalog -> (Athena) は、データ収集から分析・可視化までをエンドツーエンドでサーバレスに構築する一例です。ここで、データの加工が必要であるならば、Data Catalog -(Glue Job)-> Data Catalogを加えればよいでしょう。
AWS Glueはフルマネージドであり、その処理はスケールアウトするため、ユーザはデータ規模やインフラ運用を意識することなく、データを加工するスクリプト(ETLの"T"に対応)の作成に集中することができます。ほかにも、AWS Glueは、データカタログ上のテーブルメタデータのバージョン管理機能や、クローラでの入力データからのスキーマ自動推論機能、クラシファイアでの検査に基づきスキーマの変更を検知する機能などを備えています。
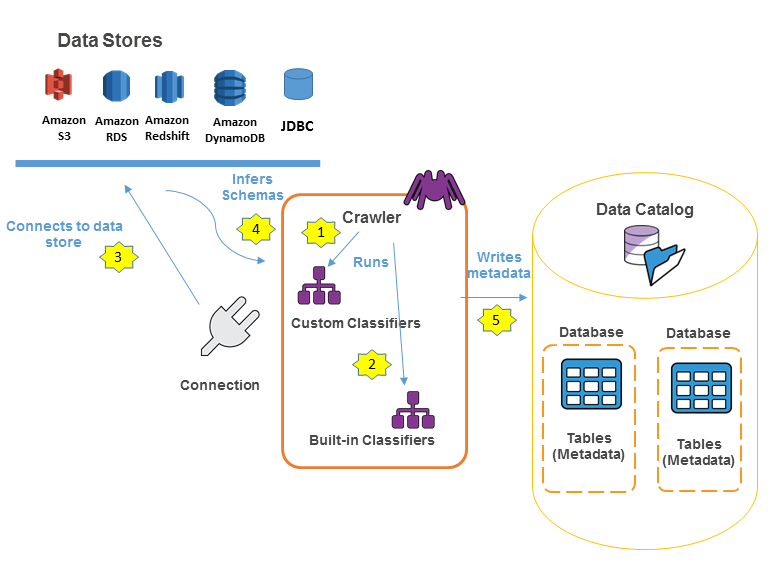
クローラ
AWS Glueにおけるクローラとは、データストアのデータを、
データカタログに移住させるために使われる機能です。
クローラの目的は、散在する複数のデータストアそれぞれを見張らせ、
最新のデータを発見し、それらのデータをデータカタログへと集約し、データカタログを最新に保つことにあります。
クローラは、クラシファイアという要素を通じて、カラム名変更、型変換などの簡単な変換処理を行ったり、
半構造データをテーブルの形式に整えたり、スキーマの変更を検知できたりします。
クラシファイアは、デフォルトのものを使うことも、自分でカスタマイズすることもできます。
作成されたクローラには、ジョブ実行方法(オンデマンドか、スケジュールベースか、イベントベースか)が定義されています。
たとえば、クローラを定期実行させておくことで、データカタログがデータストアに対しおおむね最新であることが保証されます。
ジョブ
クローラを使って単にデータをデータカタログへと移住させただけでは、
クエリを叩けてもデータが使いにくく、ユーザにとって分析が難しい場合があります。
このとき、より分析に適した形にするために、ETL処理が必要です。
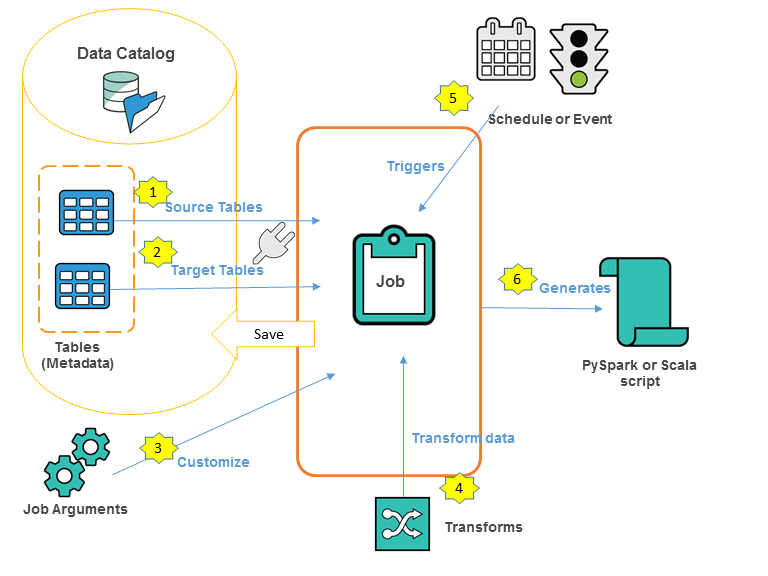
AWS Glueにおけるジョブとは、抽出・変換・ロード(ETL)作業を実行するビジネスロジックです。
ジョブが開始されると、そのジョブに対応するETL処理を行うスクリプトが実行されます。
こちらもクローラと同様に定期実行などの自動化が可能です。
ユーザは、ジョブ作成者として、抽出元(データソース)、およびロード先(データターゲット)を定義します。
ただし、データソースおよびデータターゲットは、どちらもデータカタログ上のデータです。
ユーザは、ジョブ処理環境を調整したり、生成されるスクリプトをビジネスニーズに基づいて編集したりします。
最終的に、Apache Spark API (PySpark) スクリプトが生成されます。
こうして作成されたジョブは、データカタログで管理されます。
参考文献
AWS Glue 概要
- http://docs.aws.amazon.com/glue/latest/dg/components-key-concepts.html
- http://dev.classmethod.jp/cloud/aws/studying-aws-glue-introcution-in-aws-reinvent-2016-movie/
- https://aws.amazon.com/jp/glue/
- http://dev.classmethod.jp/cloud/aws/aws-solution-days-2017-report-introduction-of-aws-glue/
- https://aws.amazon.com/jp/glue/faqs/
クローラ
- http://docs.aws.amazon.com/glue/latest/dg/populate-data-catalog.html
- http://docs.aws.amazon.com/glue/latest/dg/add-crawler.html
ジョブ