はじめに
この記事はSpark, SQL on Hadoop etc. Advent Calendar 2014の16日目の記事です。
Spark Programming Guideによると、RDD.persist(StorageLevel.OFF_HEAP)はTachyonが使われるとあります。
experimentalと書いてあるだけあって、いざ使おうとするとエラーが発生します。この機能を使うためにはTachyonを事前にインストールしなければなりません。
日本語のドキュメントがほとんど見つからなかったので、この機会にTachyonのことを書こうと思います。
今回は次の3つにチャレンジしました。
(1) Tachyonのインストール
(2) spark-shellからTachyonにデータを保存する
(3) SparkのサンプルアプリであるSparkTachyonPi(SparkPiがOFF_HEAP領域に結果を保存するように拡張されたものです)を動かす
Tachyonとは
TachyonはSparkの開発元であるUC BerkeleyのAmpLabによって様々な実行系と連携可能な分散ファイルシステムとして開発されました。
MapReduceやSparkのキャッシュと考えると分かりやすいです。
メモリだけを使って構成されるので、write性能はHDFSの100倍にも達します。さらに、Sparkを使ったワークフローを4倍速くした事例もあります。
構成図はこんな感じです。
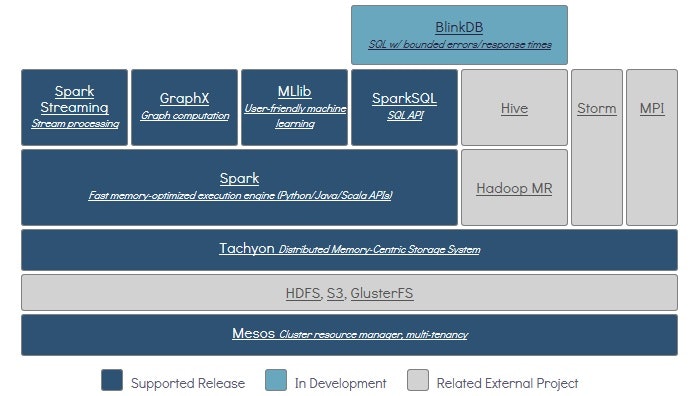
(https://amplab.cs.berkeley.edu/software/より)
上の図ではHDFSの下がMesosになっていますが、YARNの上でも当然動きます。
Tachyonの特徴
メモリの速度でI/O可能な分散ファイルシステム
TachyonはHDFSと同じくマスタ・ワーカ型で動作し、各サーバ上のワーカがローカルのメモリにデータを保存します。この時、データの複製を作りません。そのため、ネットワークを介したデータ転送がボトルネックになるHDFSと比べて圧倒的に高いwrite性能が出ます。いわば、純粋なメモリの速度でデータのやりとりができるわけです。(readはローカルにある場合に限りますが)。
じゃあサーバやメモリが故障したらデータが失われるのかというと、そうではありません。Tachyonはデータとジョブの関係をDAGとして記憶しておき、あるジョブの結果が失われるとジョブを再実行することでデータを復旧します。Sparkジョブ実行中にRDDの再計算が発生する処理をストレージのレイヤーに落とし込んだイメージです。
もう一つ大事なこととして、Tachyonはoff-heap領域として扱われるためGCが発生しません。SparkがTachyonを使うメリットには、Executorに割り振っていたメモリのいくつかをTachyonに分けることでGC時間を短縮することが期待できるわけです。
Tachyonの論文によれば、off-heapにデータを確保し続けるわけではなくて、一定量までデータがたまるとHDFSへデータを逃がしてくれます。デフォルトではLRUであり、プラガブルだと書かれています(3.5 Data Evictionを参照して下さい)。ただ、ソースを確認した限りではプラガブルになっていませんでした。この処理はtachyon.worker.WorkerStorageの中のmemoryEvictionLRUメソッドで定義されています。
複数の実行系間でデータを共有できる
TachyonはMapReduceやSparkなどと連携可能です。SparkジョブがTachyonに書き出した結果をMapReduceジョブが使うということもできます。
残念なことにこのような使い方をした事例は見つかりませんでしたが、Pivotal社が来るDatalake時代に向けてTachyonに期待しているそうです。
Tachyonを使ってみる
前置きが長くなりましたが、ようやくTachyonを実際に使うにはどうすればいいのかを書いていこうと思います。
今回はHadoop2.4.1とSpark1.1.0が動作している環境にTachyonをインストールしました。
インストール手順
1.Tachyonのページから最新版であるtachyon-0.5.0.tar.gzをダウンロード。(2014/12/10時点)
2.Tachyonのビルド
展開したできたtachyon-0.5.0の中でMavenを使ってビルドします。
$ mvn -Dhadoop.version=2.4.1 -DskipTests clean package
3.Tachyonのconfを設定する
slavesにスレーブサーバのホスト名を書きます。
compute-0-1
compute-0-2
compute-0-3
次に、tachyon-env.shを作ります。
$ cp conf/tachyon-env.sh.template conf/tachyon-env.sh
作成したtachyon-env.shを環境に合わせて書き換えます。
今回はデフォルトから修正した箇所だけまとめました。
export TACHYON_MASTER_ADDRESS=compute-0-0
export TACHYON_UNDERFS_ADDRESS=hdfs://compute-0-0:8020
export TACHYON_RAM_FOLDER=/tmp/tachyon-workspace
TachyonのUser groupを見ているとTACHYON_MASTER_ADDRESSのホスト名の前に"tachyon://"が必要だという説明をしている人もいましたが、その設定では動かなかったのでホスト名だけでよいと思います。
また、TACHYON_RAM_FOLDERはtachyonのデータが実際に保存される場所ということでメモリである/tmpの下を指定しました。あらかじめ権限は設定してあります。
4.上で作ったtachyon-0.5.0ディレクトリをスレーブサーバに配布します。
5.Tachyonと連携するためにSparkの設定を追加します
spark.tachyonStore.url tachyon://compute-0-0:19998
6.core-site.xmlにTachyonと連携するための設定を追加します
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
7.Tachyonを起動します
$ ./bin/tachyon format
Connection to compute-0-1... Formatting Tachyon Worker @ compute-0-1
Removing local data under folder: /tmp/tachyon-workspace/tachyonworker/
Connection to compute-0-1 closed.
Connection to compute-0-2... Formatting Tachyon Worker @ compute-0-2
Removing local data under folder: /tmp/tachyon-workspace/tachyonworker/
Connection to compute-0-2 closed.
Connection to compute-0-3... Formatting Tachyon Worker @ compute-0-3
Removing local data under folder: /tmp/tachyon-workspace/tachyonworker/
Connection to compute-0-3 closed.
Formatting Tachyon Master @ compute-0-0
Formatting JOURNAL_FOLDER: /disk/disk1/tachyon-0.5.0/libexec/../journal/
Formatting UNDERFS_DATA_FOLDER: hdfs://compute-0-0:8020/tmp/tachyon/data
Formatting UNDERFS_WORKERS_FOLDER: hdfs://compute-0-0:8020/tmp/tachyon/workers
$ ./bin/tachyon-start.sh all SudoMount
Killed 0 processes
Killed 0 processes
Connection to compute-0-1... Killed 0 processes
Connection to compute-0-1 closed.
Connection to compute-0-2... Killed 0 processes
Connection to compute-0-2 closed.
Connection to compute-0-3... Killed 0 processes
Connection to compute-0-3 closed.
Starting master @ compute-0-0
Connection to compute-0-1... Formatting RamFS: /tmp/tachyon-workspace (1gb)
Starting worker @ compute-0-1
Connection to compute-0-1 closed.
Connection to compute-0-2... Formatting RamFS: /tmp/tachyon-workspace (1gb)
Starting worker @ compute-0-2
Connection to compute-0-2 closed.
Connection to compute-0-3... Formatting RamFS: /tmp/tachyon-workspace (1gb)
Starting worker @ compute-0-3
Connection to compute-0-3 closed.
$ jps
1684 TachyonMaster
5388 HistoryServer
20070 NameNode
2769 QuorumPeerMain
20430 ResourceManager
1889 Jps
Tachyonを使ってみる
インストールが済んだところでTachyonを実際に使ってみました。
まずはRDDをTachyonに保存できるかを確認しています。
事前にHDFSにtestという名前でテキストファイルを置いておきました。
$ spark-shell.sh --master-yarn-client
scala> val rdd = sc.textFile("test")
rdd: org.apache.spark.rdd.RDD[String] = test MappedRDD[1] at textFile at <console>:12
scala> rdd.saveAsTextFile("tachyon://compute-0-0:19998/task2")
エラーも出ません。
本当に保存できたのか確認するために、TachyonのWeb UIを使ってみます。
ブラウザからマスタのポート番号19999へ接続してみます。
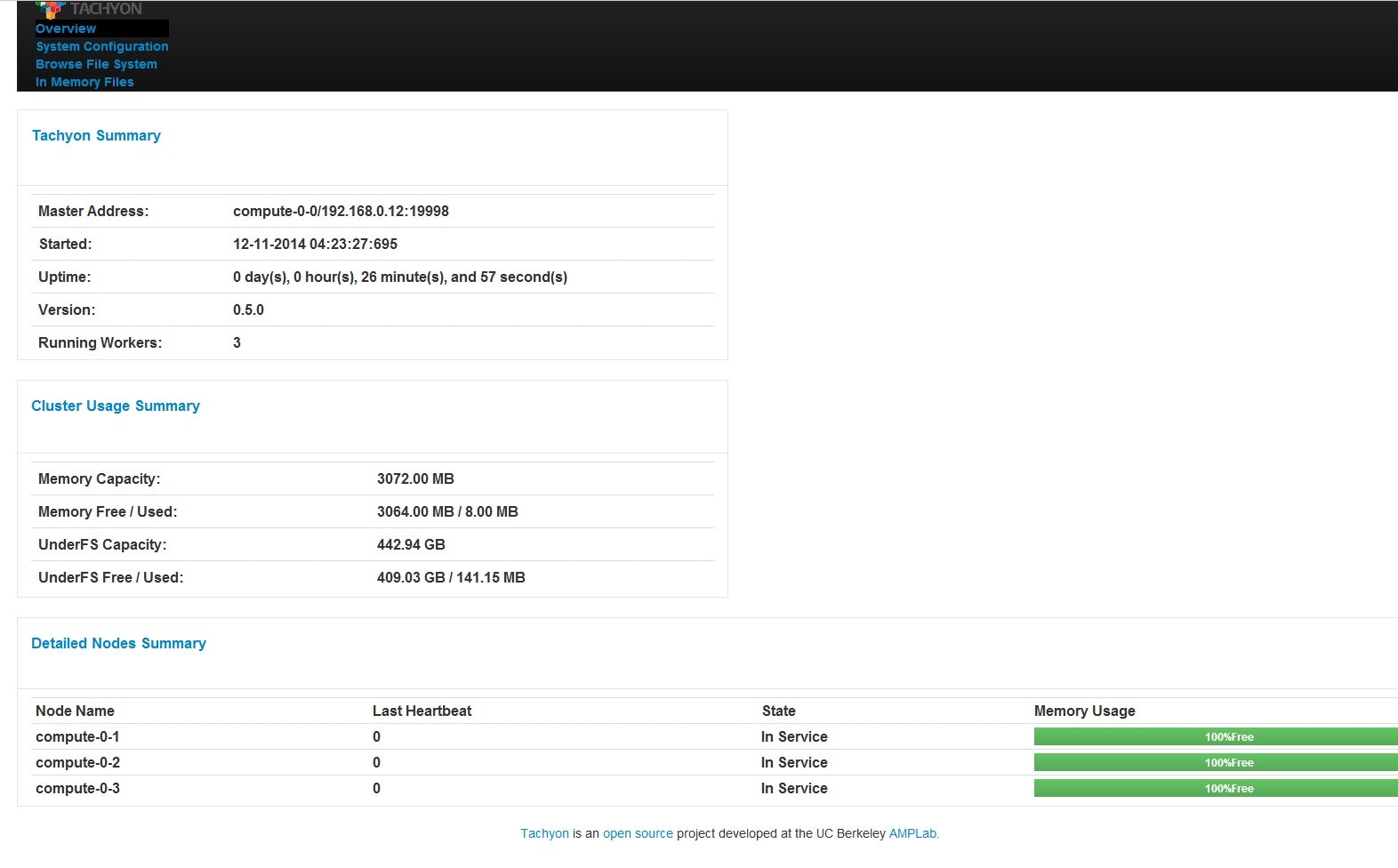
今回置いたtestというファイルが40Bほどの小さなファイルなので、ワーカの"Memory Usage"が100%のままになっています。
ここで、上にある"In Memory Files"に移動します。
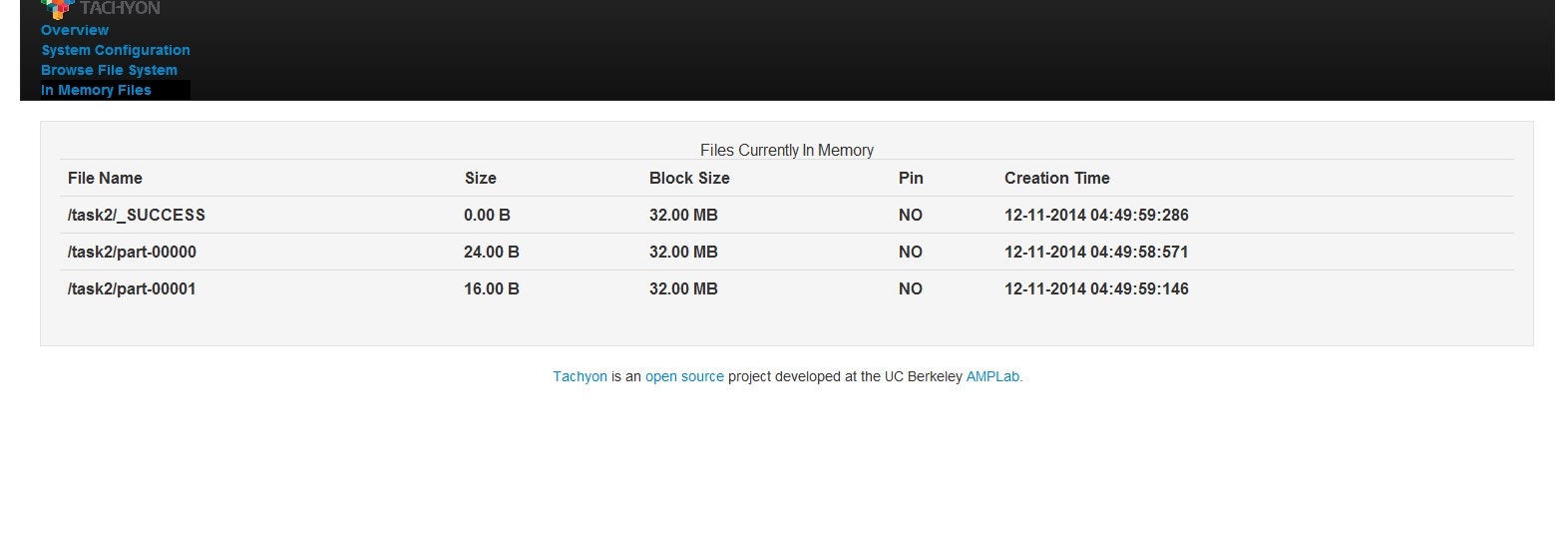
tachyon://compute-0-0:19998/task2の下に二つのファイルpart-00000とpart-00001という名前で保存されていることがわかります。それぞれのデータサイズの合計値は40Bになっています。
ただ、実際に運用するシーンではWeb UIではなくCUIで確認することが多いと思います。
HDFSの"hdfs dsf"に相当するコマンドをTachyonも持っています。
CUIでデータが置かれているかを確認してみます。
$ tachyon tfs ls /test2
24.00 B 12-11-2014 11:46:01:040 In Memory /test2/part-00000
16.00 B 12-11-2014 11:46:01:658 In Memory /test2/part-00001
0.00 B 12-11-2014 11:46:01:792 In Memory /test2/_SUCCESS
$ tachyon tfs cat /test2/part-00000
"222",6
"444",6
"111",6
当然ですが"hdfs dfs -cat"と比べてレスポンスが段違いです。
Tachyonが正しく動いていることを確認したので、SparkTachyonPiを実行してみます。
$ ./spark-submit --master yarn-client --num-executors 3 --class org.apache.spark.examples.SparkTachyonPi ../examples/target/spark-examples_2.10-1.1.0.jar 10
Pi is roughly 3.144644
無事に動きました。
最後に一つだけ
Tachyonに保存したデータの実際の保存先がメモリかどうかはTACHYON_RAM_FOLDERのパスをどこに指定するかに依存します。デフォルトでは/mnt/ramdiskが指定されていますがこのままではメモリに保存されません。
デフォルトの設定でtachyon tfs lsを実行すると実データの場所がNot In Memoryになっていて設定忘れに気づきました。便利なコマンドです。
$ ./tachyon tfs ls /test2
24.00 B 12-11-2014 08:21:51:716 Not In Memory /test2/part-00000
16.00 B 12-11-2014 08:21:52:338 Not In Memory /test2/part-00001
0.00 B 12-11-2014 08:21:52:485 In Memory /test2/_SUCCESS
Web UIではこの設定のままでも、"In Memoery Files"の項目でデータがあることを確認できたので注意が必要です。