はじめに
こんにちは、山田です。
今回は最近はまっているChatGPT APIの概要と各種パラメータを指定した際の挙動について記載していきます。
よろしくお願いします。
ChatGPT APIについて
ChatGPT APIは、OpenAIが提供する自然言語処理に基づくAPIの一つで、言語モデル「GPT-3.5」を使用して自然な対話を行うことが可能です
ChatGPTのAPIを利用することで以下のような機能を実装することが可能です。
・チャットボットの開発
・情報検索
・文書の生成
・プログラミングコード作成
ChatGPT API利用料金
利用料金に関しては、1000トークン当たり、$0.002になります。
トークンの数え方に関しては、英語の場合は1単語=1トークンになるのですが、日本語の場合はややこしくひらがなは1文字が1トークン以上、漢字だと1文字2,3トークンになるそうです。
実際に使用したトークン数に関しては、ChatGPT APIからのレスポンスの中に記載されています。
ChatGPT APIリクエスト例
ChatGPT APIのリクエスト例を記載します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
roleには以下のう表の3つの役割があります。
| role名 | 詳細 |
|---|---|
| system | ChatGPTの設定 |
| user | ユーザーからの質問 |
| assisant | ChatGPTからの回答 |
ChatGPT APIからのレスポンス
ChatGPT APIからのレスポンス例を以下に記載します。
{
"choices": [
"finish_reason": "stop",
"index": 0,
"message": {
"content": "犬にとって人気のある食べ物としては肉、魚、チーズ、キャロットなどが挙げられます。",
"role": "assistant"
}
}
],
"created": 1678452478,
"id": "chatcmpl-6sWS66bsUc5XJTFKRLu0KQVcZCfFh",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 225,
"prompt_tokens": 31,
"total_tokens": 256
}
}
contentの部分が、ChatGPTからの回答になります。また、total_tokensが今回の質問・回答で使用したトークン数になります。
各パラメータについて
ChatGPT APIで使用できる各種パラメーターの詳細は以下の通りです。
| パラメータ名 | 詳細 |
|---|---|
| model | gpt-3.5-turboを指定 |
| message | 文脈を生成するためのメッセージ |
| n | 回答の数。3を指定すれば3つの回答を得られる。 |
| stop | トークンの生成を停止する文字列 |
| max_tokens | 生成されるレスポンスのトークンの最大数 |
| frequency_penalty | -2.0 から 2.0 の間の数値を指定。値が低い場合、生成された文章に既に含まれている単語やフレーズが強調されすぎて、文章の多様性が低下する可能性がある。値が髙い場合、生成された文章が同じ単語やフレーズを繰り返すことが少なくなり、より多様な文章を生成することができる。 |
| temperature | サンプリング温度を 0〜1 の間で指定します。高いサンプリング温度では、出現確率が均一化され、より多様な文章が生成される傾向がある。一方、低いサンプリング温度では、出現確率の高い単語が優先され、より一定の傾向を持った文章が生成される傾向がある。 |
| logit_bias | トークンの生成確率を調整するために、各トークンに対してlogit_biasを設定することができる。正の値を持つトークンは出現確率が上がり、負の値を持つトークンは出現確率が下がる。logit_bias = {'トークンID': 2.0, 'トークンID': -1.5, 'トークンID': 1.0} |
各種パラメータを指定した際の動作について
各種のパラメータを指定した場合どのような挙動になるか記載していきます。
今回はラインと連携したLamdaを使用して動作の確認をしていきます。
stop
stopパラメータを指定します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#stopパラメータ指定
stop = 'ワン',
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
「ワンと回答して」と質問しても回答が得られず、「にゃーと回答して」と質問すると回答を得られています。

max_tokens
max_tokensパラメータを指定します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#max_tokensパラメータ指定
max_tokens = 5,
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
max_tokens=5を指定すると以下の様に途中で回答が切れるのが確認できます。

frequency_penalty
frequency_penaltyパラメータを指定します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#frequency_penaltyパラメータ指定
frequency_penalty = -2,
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
とんでもないことになります、気を付けましょう。
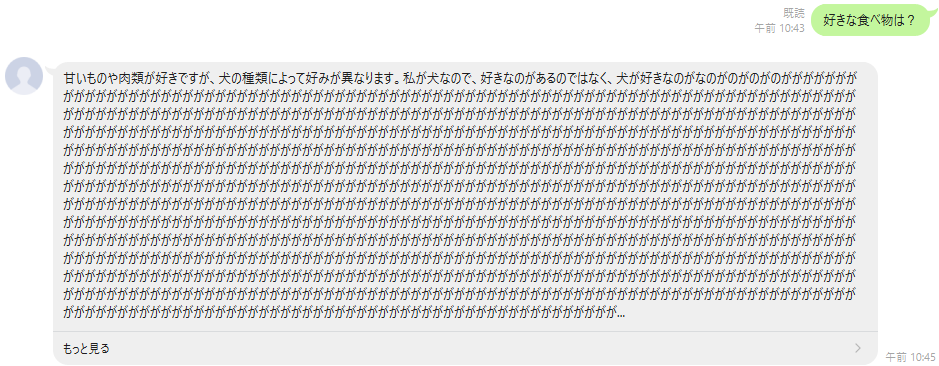
temperature
temperatureパラメータを指定します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#temperatureパラメータ指定
temperature = 0,
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
temperature=0に指定すると、一定の傾向をもった文章が生成されることが確認できます。

logit_bias
logit_biasパラメータを指定します。
#モジュールをインポート
import openai
#API-KEYを設定
openai.api_key = os.environ['ChatGPT_API_KEY']
#関数を使用してChatGPTに問い合わせを送信
response_data = openai.ChatCompletion.create(
#モデル指定
model="gpt-3.5-turbo",
#logit_biasパラメータ指定
logit_bias = {96096:20},
#ChatGPTに問い合わせるメッセージ
messages=[
{"role": "system", "content":"あなたは犬です"},
{"role": "user", "content": "好きな食べ物は?" }
)
logit_bias = {96096:20},の部分に関しては、文字列を指定するのではなくトークンIDを指定する必要があります。
トークンIDを調べる方法は以下の通りです。
tiktokenパッケージインストール
pip install tiktoken
以下の様に記載して実行すればトークンIDを取得できます。
import tiktoken
from tiktoken.core import Encoding
encoding: Encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens = encoding.encode(' Dolphin')
print(tokens)
今回は Dolphinという単語のトークンIDを調べています。
[96096]
調べたトークンIDを基に、logit_biasを設定します。
logit_bias = {96096:20}と記載すればおおよそ出現確率が5倍になります。
以下の様に回答の中に Dolphinが連発しています。

終わりに
今回はChatGPT APIの概要と各種パラメーターのついて記載しました。
もう少しで「GPT-4.0」が発表になるそうなので、楽しみにしています。
最後まで拝見いただきありがとうございました。