目的
強化学習を材料の構造最適化に利用してみたいと考えている.この時,構造最適化において,構造は直線の組み合わせで出来上がっていることに気づいた.
よって,強化学習において直線を用いて画像を表現する手法がないかと調べたとき,こちらの論文SPIRAL(2018)及び,Learning to Paint With Model-based Deep Reinforcement Learning(2019)を発見した.今回は,より細かい描写として,SPIRALと違い人物画像の表現を可能にしている後者の方を読んでみたので,その内容を忘れないうちにまとめておく.
また,前者のSPIRALは描き方を学ぶ敵対的強化学習モデルSPIRALにまとめてある.
論文紹介・画像引用・GIF引用
- Learning to Paint With Model-based Deep Reinforcement Learning
- 深層強化学習によるストロークで質感豊かな自然なペイント生成
- Frame Skip Is a Powerful Parameter for Learning to Play Atari
- Wasserstein Generative Adversarial Networks
- Weight Normalization
- CNNで画像中のピクセルの座標情報を考慮できるCoordConv
- Real-Time Single Image and Video Super-Resolution Using an Efficient
Sub-Pixel Convolutional Neural Network - Sub-Pixel Convolutionについて#5【画像処理&機械学習】論文LT会!で発表しました
Learning to Paint With Model-based Deep Reinforcement Learning
Abstract



ある程度の画像は数百のストロークを用いて表すことが出来る.
この研究では,深層強化学習を利用してAgentに位置や色を決定させ,目標とする画像をストロークを用いて表現させる手法を提案した.
本研究のポイントは,
- SPIRALとは違い,高品質なレベルの絵を生成できるようになった.
- ピクセルレベルで品質を高める為,敵対的学習を強化学習に適用
- 今までの論文のように独立的選択肢から選ばせるのではなく,連続的ストロークパラメータとして,位置,色,透過率をagentに選択させた.これによって豊富な表現をなせるようになった.そのため,連続的空間を扱えるDDPGモデルを適用した.
- 今までの論文ではレンダラーが微分不可能なステップであった.対し,本研究では**レンダリング用に,微分可能なニューラルレンダラーを開発した.**これにより,画像からの直接的なフィードバックを行えるようにした.よって,質および収束が早い強化学習を行うことが出来る.
- レンダラーは,ストロークのパラメータから直接的に描画を行える学習したNNモデルを適用した.
OverView

本研究のアルゴリズムの全体図は上の図の通りである.
Agentは,現状のキャンバスの図と,目標とする画像,そして何ステップ目かを毎回のストローク決定の入力とする.
また,学習には敵対的学習を用いている.
Agent Model
ターゲット画像を$I$,最初の空白のキャンバスを$C_0$,agentが決定したステップ$t$におけるactionを$a_t$とする.そしてそのactionを基にキャンバス$C_t$は$C_{t+1}$となる.
状態空間を$S$,action空間を$A$,遷移関数を$trans(s_t,a_t)$とし,その時の報酬関数を$r(s_t,a_t)$とする.
これらの前提の下,アルゴリズムモデルを説明していく.
State and Transition Function
現状のキャンバス,ターゲット画像,そして,残りのステップ数が何個かを補助的に示すため,状態$s_t$は以下の式で表現する.
$$s_t=(C_t,I,t)$$
そして,$s_{t+1}=trans(s_t,a_t)$とする.
これを画像形式でAgent Modelに入力する.
Action
Agent Modelが出力し,neural network rendererに入力する$a_t$には,
- 位置
- 形状(ダイレクトに三角形や丸を指定するバイナリ形式ではなく,曲率など)
- 色
- 透過率
の四つを指定するパラメータが含まれている.
Reward
現状のキャンバスと,ターゲット画像との違いを知ることがAgentを学習させるうえで重要な要素である.よって,Rewardは次のように設計される.
$$r(s_t,a_t)=L_t-L_{t+1}$$
ここでの$L_t$は,$I$と$C_t$との違いを表す値である.
また,最終的なキャンバスがターゲット画像に近づくように学習させるため,Agentの目的は次の推定合計報酬関数を最大化することとする.
$$\sum_{i=t}^{T} \gamma^{i-t}r(s_i,a_i)$$
$$\gamma\in [0,1]$$
Learning
Model-based DDPG
DDPGは,連続的行動空間を扱うことが出来る強化学習手法である.
元祖DDPGは行動決定を行うActor$\pi (s)$と,状態価値を推定するCriticの二つのネットワークモデルから構成されている.
Actor$\pi (s)$は状態$s_t$からaction$a_t$を求める.
Criticは将来的に受け取る報酬を価値関数$Q(s,a)$という形で現時点での$a_t$および$s_t$から推定するものであり,学習にはQ学習の時と同じように以下の式と,replay bufferを利用する.
$$Q(s_t,a_t)=r(s_t,a_t)+\gamma Q(s_{t+1},\pi (s_{t+1}))$$

今回,元祖DDPGは今回の実画像を構成する複雑な情報を扱うには困難である.そのため,Model-based-DDPGという手法(図の右側)を今回新しく作成した.
元祖DDPGは現時点のaction及び状態からしか価値を推定できず,Criticにおける学習段階では状態に関する環境を推定せざるを得なかった.対してModel-based-DDPGはCriticの学習時に,微分可能なレンダラーを含めることによって,環境を知ったうえで学習を行え,効率が上がる.
よって,Criticに関しては,actionの結果であり,actionの計算情報を含んだキャンバスの価値関数$V(s_t)$を推定する形に変更する.
$V(s_t)$は次のとおりである.
$$V(s_t)=r(s_t,a_t)+\gamma V(s_{t+1})$$
$r(s_t,a_t)$は,$s_t$において$a_t$を起こした時に得られる報酬を表す.
Actor$\pi (s_{t+1})$は,$r(s_t,a_t)+V(trans(s_{t},a_t))$
を最大化する為に学習される.ここでの遷移関数$s_{t+1}=trans(s_{t},a_t)$は微分可能なレンダラーを示す.
Action Bundle
RLにおける効率的学習手法の一つとしてFrame Skipがある.
Frame Skipとは,kステップごとに状態を観測して一つの行動を選択し,次のkステップに連続して同じ行動を行う手法を指す.これにより,計算コストがかからず,また,時間的に離れた状態と行動の間の関連付けをAgentが学習しやすくなる.
本研究ではkステップごとに観測するのはframe skipと比べて同じだが,次のkステップ(ストローク)の動き自体は,同じではなく,kこの別々のactionを同時に出力するAction Bundleという手法を適用した.
実験的には,k=5の時に良い結果が出たとのこと.また,一貫性を保つために減衰定数を$\gamma$から$\gamma ^k$に変更した.
Reward
GANの上位互換であるWGANにおける目的関数を利用した報酬関数を適用した.
WGANにおけるDiscriminatorの目的関数は次のとおりである.
$$ max( E_{y \sim \mu}[D(y)] -E_{x \sim \nu}[D(x)])$$
ここでの$\nu$はfake samples,$\mu$はreal samplesの分布を示している.
条件付きGANの学習の時,fake samples$\nu$は出力画像とターゲットのペアの集合,real samples$\mu$はターゲットとターゲットのペアの集合となる.

また,本研究ではターゲットと出力画像の違いを小さくしたいため,$L_2$距離を報酬に含めた方がよさそうだが,$D$に関するスコアのみを報酬にした方が良い結果となった.
報酬関数は,reward項においてあった式において,$L_t=$$D$の目的関数とした.
$$r(s_t,a_t)=L_t-L_{t+1}$$
この式を利用することにより,マイステップごとにリアルさを増す画像を出力できるようになる.
Network Architecture

- Actor,Criticの両方にてResNet-18のように,Resブロックを採用
- ActorにおいてはBatch Normalizationは有効だった.
- CriticにおいてはBNだと学習があまり変わらなかった.そこで,Weight NormalizationとTReLUをCriticに利用した.結果,学習が安定.学習の安定化,高速化に効果がある手法とのこと.Weight Normalizationに関してはここを参照.
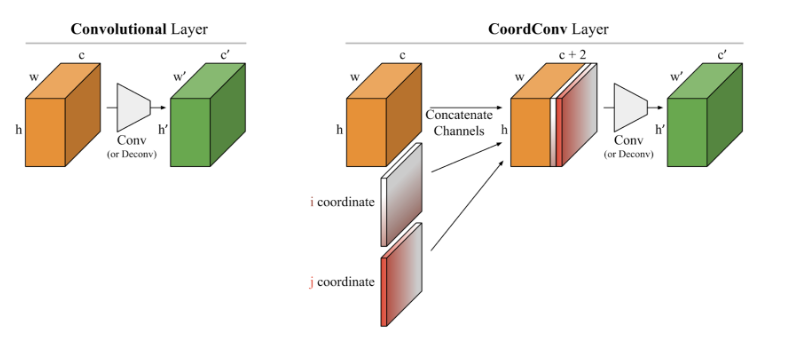
- Actor,Criticの両方にてCoord-Convを一番最初の層に適用した.畳み込むべき対象に,位置情報を持つチャネルを付加し,位置情報を学習しやすくする手法.Coord-Convに関しては詳しくはここを参照.
Stroke-based Renderer
ここでは,ニューラルネットワークを用いて自作した微分可能なレンダラーに関する説明を行う.
Neural Renderer
 このNeural Rendererは入力をストロークのセットパラメータ$a_t$とし,出力をレンダリングされたストロークの画像$S$とする.
学習用のデータは,別のレンダリングソフトによってランダムに作成された画像を利用する.そして,教師あり学習を用いて学習される.
このNeural Rendererは入力をストロークのセットパラメータ$a_t$とし,出力をレンダリングされたストロークの画像$S$とする.
学習用のデータは,別のレンダリングソフトによってランダムに作成された画像を利用する.そして,教師あり学習を用いて学習される.
また,チェッカーボード効果を排除し,計算速度を高める為,Subpixel upsamplingを利用した.Subpixel upsamplingとは,高解像度化を目指す論文にあった手法であり,下の図のように既存の画像の間に,0の値(グレースケールの部分)を入れていき,サブピクセル空間に広げることを指す.これを畳み込むことによって,畳み込み結果の特徴ベクトルは,隣接セルの情報を空間方向に持てるようになる.詳しくはここを参照.

Stroke Design
ストロークのデザインに必要なパラメータは,位置,形状,色,そして透過率が一般的である.
今回,ブラシの動きを再現するため,教師データとしてはSPIRALと同じくベジェ曲線を用いて作成したデータを用いている.ベジェ曲線に関してはここを参照.
ベジェ曲線を表すのに必要なパラメータは13こあり,これらをNeural Network rendererの入力パラメータとする.
Results
 図の詳細:
図の詳細:
- a:SPIRALの20ストローク(有効のみ)
- b:20ストローク(有効のみ)
- c:200ストローク(有効のみ)
- d:$L_2$を報酬とした場合,200ストローク
- e:200ストローク
- f:1000ストローク
- g:ターゲット画像
結果,細かい描写が必要なターゲット画像に対しても,SPIRALと比べて良い結果を出している.
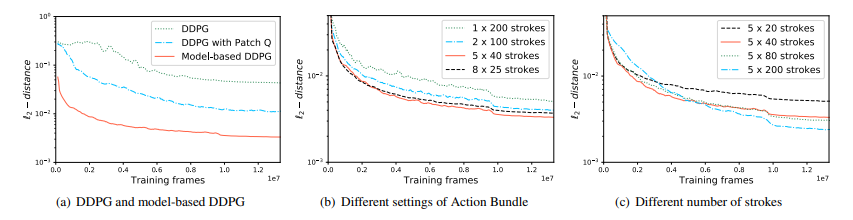
損失関数$L_2$に関してもNeural Network rendererを用いた方が良い結果となった.
また,Action Bundleの数はCelebAに関しては5ステップが最良の結果となった.
また,全体のストローク数は増やせば増やすほど良い結果となった.
SPIRALとのここまでの差の要因
- Neural Network rendererを適用したことによるend-to-endの学習が可能
- RNNモデルを利用していないことにより,モデルが単純化
- SPIRALは最終的な報酬しか与えなかった.対して,本手法は毎度報酬を与えていたことにより,学習しやすくなった.
まとめ
レンダリングモデル自体もニューラルネットワークを適用することが本研究の肝.
自身の研究でも,NNを用いていないところをNNに変換することにより,学習が圧倒的によくなる可能性を示唆してくれる良い論文だった.