[GeneratedRegex]とは
System.Text.RegularExpressions.GeneratedRegexAttributeは.NET 7で導入された属性で、これを指定すると正規表現に相当するコードをコンパイル時に生成してくれます。
RegexOptions.Compiledと違い初期化処理に時間が掛からず、Native AOTでも機能してくれます。
使い方は簡単。こんな感じです。
using System.Text.RegularExpressions;
public partial class Sample {
[GeneratedRegex(@"Hello,? World\!?")]
private static partial Regex _reg_helloworld();
}
具体的には、
-
実装するクラスに
partialを付ける。
これは部分クラスと言い、クラスの定義を複数のファイルに分割できるものです(Microsoft Learn)。 -
実装して欲しいメソッドを定義する。
ここでアクセスビリティの指定は必須です。つまりprivateは省略できません。
加えてpartialキーワードを記してください。
中身は空で良いです。複数回呼び出してもキャッシュされてるので自前でキャッシュは不要です。
これはpartialメソッドと呼びます。 -
[GeneratedRegex(@"")]行を追加する。
また最新のVisual Studioをご利用の場合はアナライザーが追加されているので、
-
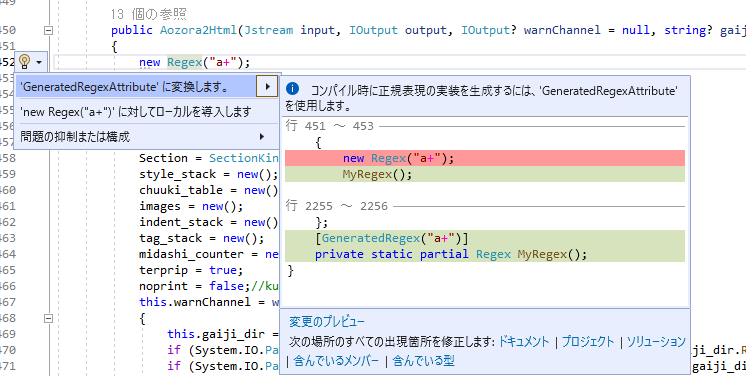
コード中の適当な
new Regex("")に対して右クリックメニューの「クイックアクションとリファクタリング」(Ctrl + .)を選択。 -
「'GeneratedRegexAttribute'に変換します」選択。
これだけです。いつもの奴です。名前には迷いそうです。
<TargetFrameworks>で複数指定している方は#if NET7_0_OR_GREATERで分岐してください。
partialメソッド
人によってはpartialというキーワードは見慣れていると思いますが、メソッド行という少し不思議な場所に入っています。
これは新しいpartialメソッドです。
新しいというからには古い方がある訳ですが、マニアックな話になるので以下の記事を参照してください。
- 「partial メソッドの拡張 (C# 9.0 候補機能)」, ++C++; // 未確認飛行 C, 2020
簡単に言えば古い方があるせいで、新しい方ではアクセスビリティ指定が必須になっています。
なお残念ながら現状ではプロパティには使えません。
- 「GeneratedRegex」検索トップのツイート:「GeneratedRegexはPartial MethodよりもPropertyのほうが自然だったよねえ」
- partial メソッド (C# リファレンス), Microsoft Learn
生成コードを確認
さて、話はこれだけで要するに「new Regex()を見かけたら、クイックフィックスで[GeneratedRegex()]に書き換えたらなんか早くなるよ」というだけです。
知らない内に割とすごい機能が実装されていてクイックフィックスから気付くってのはVisual Studioあるあるです。
これだけ知ってりゃ十分。
しかし面白いのは、これからです。メソッド名にマウスオーバーしてみましょう。
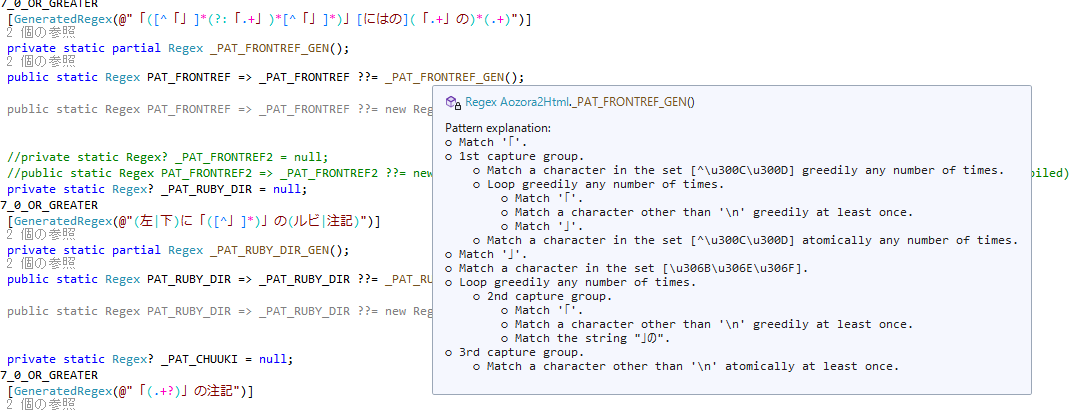
あの難しい正規表現が平易な英語で説明されてます。IntelliSenseにも出て来るので便利です。
いや全然平易でも便利でもないと思いますけど、とにかく出てきます。
そしてそこにカーソルを合わせてF12(右クリックで「定義へ移動」)。
そうするとなんと生成されたコードが覗けます!
そうですSource Generatorは割とリアルタイムでソースコードを生成していて、それがサクッと確認できます。
今は。確か当初は無理でした。
まずは下のような場所に飛びます。特に面白くはないです。
namespace Aozora
{
partial class Aozora2Html
{
/// <remarks>
/// Pattern explanation:<br/>
/// <code>
/// </code>
/// </remarks>
[global::System.CodeDom.Compiler.GeneratedCodeAttribute("System.Text.RegularExpressions.Generator", "7.0.7.6804")]
private static partial global::System.Text.RegularExpressions.Regex _PAT_RUBY_DIR_GEN() => global::System.Text.RegularExpressions.Generated._PAT_RUBY_DIR_GEN_1.Instance;
}
}
InstanceでF12、さらに飛びます。
シンプルな例
[GeneratedRegex(@".")]
private static partial Regex _PAT_BOUKI_GEN2();
/// <summary>Custom <see cref="Regex"/>-derived type for the _PAT_BOUKI_GEN2 method.</summary>
[GeneratedCodeAttribute("System.Text.RegularExpressions.Generator", "7.0.7.6804")]
file sealed class _PAT_BOUKI_GEN2_24 : Regex
{
/// <summary>Cached, thread-safe singleton instance.</summary>
internal static readonly _PAT_BOUKI_GEN2_24 Instance = new();
/// <summary>Initializes the instance.</summary>
private _PAT_BOUKI_GEN2_24()
{
base.pattern = ".";
base.roptions = RegexOptions.None;
ValidateMatchTimeout(Utilities.s_defaultTimeout);
base.internalMatchTimeout = Utilities.s_defaultTimeout;
base.factory = new RunnerFactory();
base.capsize = 1;
}
/// <summary>Provides a factory for creating <see cref="RegexRunner"/> instances to be used by methods on <see cref="Regex"/>.</summary>
private sealed class RunnerFactory : RegexRunnerFactory
{
/// <summary>Creates an instance of a <see cref="RegexRunner"/> used by methods on <see cref="Regex"/>.</summary>
protected override RegexRunner CreateInstance() => new Runner();
/// <summary>Provides the runner that contains the custom logic implementing the specified regular expression.</summary>
private sealed class Runner : RegexRunner
{
/// <summary>Scan the <paramref name="inputSpan"/> starting from base.runtextstart for the next match.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
protected override void Scan(ReadOnlySpan<char> inputSpan)
{
if (TryFindNextPossibleStartingPosition(inputSpan))
{
// The search in TryFindNextPossibleStartingPosition performed the entire match.
int start = base.runtextpos;
int end = base.runtextpos = start + 1;
base.Capture(0, start, end);
}
}
/// <summary>Search <paramref name="inputSpan"/> starting from base.runtextpos for the next location a match could possibly start.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
/// <returns>true if a possible match was found; false if no more matches are possible.</returns>
private bool TryFindNextPossibleStartingPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
// Empty matches aren't possible.
if ((uint)pos < (uint)inputSpan.Length)
{
// The pattern begins with a character in the set [^\n].
// Find the next occurrence. If it can't be found, there's no match.
ReadOnlySpan<char> span = inputSpan.Slice(pos);
for (int i = 0; i < span.Length; i++)
{
if ((span[i] != '\n'))
{
base.runtextpos = pos + i;
return true;
}
}
}
// No match found.
base.runtextpos = inputSpan.Length;
return false;
}
}
}
}
複雑な例。
/// <summary>Custom <see cref="Regex"/>-derived type for the _PAT_FRONTREF_GEN method.</summary>
[GeneratedCodeAttribute("System.Text.RegularExpressions.Generator", "7.0.7.6804")]
file sealed class _PAT_FRONTREF_GEN_20 : Regex
{
/// <summary>Cached, thread-safe singleton instance.</summary>
internal static readonly _PAT_FRONTREF_GEN_20 Instance = new();
/// <summary>Initializes the instance.</summary>
private _PAT_FRONTREF_GEN_20()
{
base.pattern = "「([^「」]*(?:「.+」)*[^「」]*)」[にはの](「.+」の)*(.+)";
base.roptions = RegexOptions.None;
ValidateMatchTimeout(Utilities.s_defaultTimeout);
base.internalMatchTimeout = Utilities.s_defaultTimeout;
base.factory = new RunnerFactory();
base.capsize = 4;
}
/// <summary>Provides a factory for creating <see cref="RegexRunner"/> instances to be used by methods on <see cref="Regex"/>.</summary>
private sealed class RunnerFactory : RegexRunnerFactory
{
/// <summary>Creates an instance of a <see cref="RegexRunner"/> used by methods on <see cref="Regex"/>.</summary>
protected override RegexRunner CreateInstance() => new Runner();
/// <summary>Provides the runner that contains the custom logic implementing the specified regular expression.</summary>
private sealed class Runner : RegexRunner
{
/// <summary>Scan the <paramref name="inputSpan"/> starting from base.runtextstart for the next match.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
protected override void Scan(ReadOnlySpan<char> inputSpan)
{
// Search until we can't find a valid starting position, we find a match, or we reach the end of the input.
while (TryFindNextPossibleStartingPosition(inputSpan) &&
!TryMatchAtCurrentPosition(inputSpan) &&
base.runtextpos != inputSpan.Length)
{
base.runtextpos++;
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
}
}
/// <summary>Search <paramref name="inputSpan"/> starting from base.runtextpos for the next location a match could possibly start.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
/// <returns>true if a possible match was found; false if no more matches are possible.</returns>
private bool TryFindNextPossibleStartingPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
// Any possible match is at least 4 characters.
if (pos <= inputSpan.Length - 4)
{
// The pattern begins with a character in the set \u300C.
// Find the next occurrence. If it can't be found, there's no match.
int i = inputSpan.Slice(pos).IndexOf('「');
if (i >= 0)
{
base.runtextpos = pos + i;
return true;
}
}
// No match found.
base.runtextpos = inputSpan.Length;
return false;
}
/// <summary>Determine whether <paramref name="inputSpan"/> at base.runtextpos is a match for the regular expression.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
/// <returns>true if the regular expression matches at the current position; otherwise, false.</returns>
private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
int matchStart = pos;
char ch;
int capture_starting_pos = 0;
int capture_starting_pos2 = 0;
int charloop_capture_pos = 0;
int charloop_starting_pos = 0, charloop_ending_pos = 0;
int charloop_starting_pos1 = 0, charloop_ending_pos1 = 0;
int charloop_starting_pos2 = 0, charloop_ending_pos2 = 0;
int loop_iteration = 0;
int loop_iteration1 = 0;
int stackpos = 0;
ReadOnlySpan<char> slice = inputSpan.Slice(pos);
// Match '「'.
if (slice.IsEmpty || slice[0] != '「')
{
UncaptureUntil(0);
return false; // The input didn't match.
}
// 1st capture group.
//{
pos++;
slice = inputSpan.Slice(pos);
capture_starting_pos = pos;
// Match a character in the set [^\u300C\u300D] greedily any number of times.
//{
charloop_starting_pos = pos;
int iteration = slice.IndexOfAny('「', '」');
if (iteration < 0)
{
iteration = slice.Length;
}
slice = slice.Slice(iteration);
pos += iteration;
charloop_ending_pos = pos;
goto CharLoopEnd;
CharLoopBacktrack:
UncaptureUntil(charloop_capture_pos);
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (charloop_starting_pos >= charloop_ending_pos)
{
UncaptureUntil(0);
return false; // The input didn't match.
}
pos = --charloop_ending_pos;
slice = inputSpan.Slice(pos);
CharLoopEnd:
charloop_capture_pos = base.Crawlpos();
//}
// Loop greedily any number of times.
//{
loop_iteration = 0;
LoopBody:
Utilities.StackPush(ref base.runstack!, ref stackpos, base.Crawlpos(), pos);
loop_iteration++;
// Match '「'.
if (slice.IsEmpty || slice[0] != '「')
{
goto LoopIterationNoMatch;
}
// Match a character other than '\n' greedily at least once.
//{
pos++;
slice = inputSpan.Slice(pos);
charloop_starting_pos1 = pos;
int iteration1 = slice.IndexOf('\n');
if (iteration1 < 0)
{
iteration1 = slice.Length;
}
if (iteration1 == 0)
{
goto LoopIterationNoMatch;
}
slice = slice.Slice(iteration1);
pos += iteration1;
charloop_ending_pos1 = pos;
charloop_starting_pos1++;
goto CharLoopEnd1;
CharLoopBacktrack1:
UncaptureUntil(base.runstack![--stackpos]);
Utilities.StackPop(base.runstack!, ref stackpos, out charloop_ending_pos1, out charloop_starting_pos1);
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (charloop_starting_pos1 >= charloop_ending_pos1 ||
(charloop_ending_pos1 = inputSpan.Slice(charloop_starting_pos1, charloop_ending_pos1 - charloop_starting_pos1).LastIndexOf('」')) < 0)
{
goto LoopIterationNoMatch;
}
charloop_ending_pos1 += charloop_starting_pos1;
pos = charloop_ending_pos1;
slice = inputSpan.Slice(pos);
CharLoopEnd1:
Utilities.StackPush(ref base.runstack!, ref stackpos, charloop_starting_pos1, charloop_ending_pos1, base.Crawlpos());
//}
// Match '」'.
if (slice.IsEmpty || slice[0] != '」')
{
goto CharLoopBacktrack1;
}
pos++;
slice = inputSpan.Slice(pos);
// The loop has no upper bound. Continue iterating greedily.
goto LoopBody;
// The loop iteration failed. Put state back to the way it was before the iteration.
LoopIterationNoMatch:
if (--loop_iteration < 0)
{
// Unable to match the remainder of the expression after exhausting the loop.
goto CharLoopBacktrack;
}
pos = base.runstack![--stackpos];
UncaptureUntil(base.runstack![--stackpos]);
slice = inputSpan.Slice(pos);
goto LoopEnd;
LoopBacktrack:
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (loop_iteration == 0)
{
// No iterations of the loop remain to backtrack into. Fail the loop.
goto CharLoopBacktrack;
}
goto CharLoopBacktrack1;
LoopEnd:;
//}
// Match a character in the set [^\u300C\u300D] atomically any number of times.
{
int iteration2 = slice.IndexOfAny('「', '」');
if (iteration2 < 0)
{
iteration2 = slice.Length;
}
slice = slice.Slice(iteration2);
pos += iteration2;
}
base.Capture(1, capture_starting_pos, pos);
goto CaptureSkipBacktrack;
CaptureBacktrack:
goto LoopBacktrack;
CaptureSkipBacktrack:;
//}
if ((uint)slice.Length < 2 ||
slice[0] != '」' || // Match '」'.
(((ch = slice[1]) != 'に') & (ch != 'の') & (ch != 'は'))) // Match a character in the set [\u306B\u306E\u306F].
{
goto CaptureBacktrack;
}
// Loop greedily any number of times.
//{
pos += 2;
slice = inputSpan.Slice(pos);
loop_iteration1 = 0;
LoopBody1:
Utilities.StackPush(ref base.runstack!, ref stackpos, base.Crawlpos(), pos);
loop_iteration1++;
// 2nd capture group.
//{
int capture_starting_pos1 = pos;
// Match '「'.
if (slice.IsEmpty || slice[0] != '「')
{
goto LoopIterationNoMatch1;
}
// Match a character other than '\n' greedily at least once.
//{
pos++;
slice = inputSpan.Slice(pos);
charloop_starting_pos2 = pos;
int iteration3 = slice.IndexOf('\n');
if (iteration3 < 0)
{
iteration3 = slice.Length;
}
if (iteration3 == 0)
{
goto LoopIterationNoMatch1;
}
slice = slice.Slice(iteration3);
pos += iteration3;
charloop_ending_pos2 = pos;
charloop_starting_pos2++;
goto CharLoopEnd2;
CharLoopBacktrack2:
UncaptureUntil(base.runstack![--stackpos]);
Utilities.StackPop(base.runstack!, ref stackpos, out charloop_ending_pos2, out charloop_starting_pos2);
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (charloop_starting_pos2 >= charloop_ending_pos2 ||
(charloop_ending_pos2 = inputSpan.Slice(charloop_starting_pos2, Math.Min(inputSpan.Length, charloop_ending_pos2 + 1) - charloop_starting_pos2).LastIndexOf("」の")) < 0)
{
goto LoopIterationNoMatch1;
}
charloop_ending_pos2 += charloop_starting_pos2;
pos = charloop_ending_pos2;
slice = inputSpan.Slice(pos);
CharLoopEnd2:
Utilities.StackPush(ref base.runstack!, ref stackpos, charloop_starting_pos2, charloop_ending_pos2, base.Crawlpos());
//}
// Match the string "」の".
if (!slice.StartsWith("」の"))
{
goto CharLoopBacktrack2;
}
pos += 2;
slice = inputSpan.Slice(pos);
base.Capture(2, capture_starting_pos1, pos);
Utilities.StackPush(ref base.runstack!, ref stackpos, capture_starting_pos1);
goto CaptureSkipBacktrack1;
CaptureBacktrack1:
capture_starting_pos1 = base.runstack![--stackpos];
goto CharLoopBacktrack2;
CaptureSkipBacktrack1:;
//}
// The loop has no upper bound. Continue iterating greedily.
goto LoopBody1;
// The loop iteration failed. Put state back to the way it was before the iteration.
LoopIterationNoMatch1:
if (--loop_iteration1 < 0)
{
// Unable to match the remainder of the expression after exhausting the loop.
goto CaptureBacktrack;
}
pos = base.runstack![--stackpos];
UncaptureUntil(base.runstack![--stackpos]);
slice = inputSpan.Slice(pos);
goto LoopEnd1;
LoopBacktrack1:
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (loop_iteration1 == 0)
{
// No iterations of the loop remain to backtrack into. Fail the loop.
goto CaptureBacktrack;
}
goto CaptureBacktrack1;
LoopEnd1:;
//}
// 3rd capture group.
{
capture_starting_pos2 = pos;
// Match a character other than '\n' atomically at least once.
{
int iteration4 = slice.IndexOf('\n');
if (iteration4 < 0)
{
iteration4 = slice.Length;
}
if (iteration4 == 0)
{
goto LoopBacktrack1;
}
slice = slice.Slice(iteration4);
pos += iteration4;
}
base.Capture(3, capture_starting_pos2, pos);
}
// The input matched.
base.runtextpos = pos;
base.Capture(0, matchStart, pos);
return true;
// <summary>Undo captures until it reaches the specified capture position.</summary>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
void UncaptureUntil(int capturePosition)
{
while (base.Crawlpos() > capturePosition)
{
base.Uncapture();
}
}
}
}
}
}
キャッシュされてますね。
あとはRunnerFactory.Runner内でなんかやってますね。
具体的には正規表現と同じことをやる愚直なC#コードのようなものが確認できます。
複雑な方。めっちゃ長いコード、goto祭り。
地獄ですね。
でもこれが正規表現が存在しなかった世界であなたが書かなければならなかったコードです。
読む気にはなるわきゃないでしょうけど、読んでみると割と楽しいこともあります。
そしてこれをコピペすれば.NET 7以前にも移植できるかもしれません。
後述しますが「file ローカル型」が使えないのでそこは修正してください。
公式ブログ(後述)に挙げられている例を覗いてみましょう。
[GeneratedRegex(@"[A-Za-z][A-Z][a-z][0-9][A-Za-z0-9][0-9A-F][0-9a-f][0-9A-Fa-f]\p{Cc}\p{L}[\p{L}\d]\p{Ll}\p{Lu}\p{N}\p{P}\p{Z}\p{S}")]
private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
int matchStart = pos;
ReadOnlySpan<char> slice = inputSpan.Slice(pos);
if ((uint)slice.Length < 17 ||
!char.IsAsciiLetter(slice[0]) || // Match a character in the set [A-Za-z].
!char.IsAsciiLetterUpper(slice[1]) || // Match a character in the set [A-Z].
!char.IsAsciiLetterLower(slice[2]) || // Match a character in the set [a-z].
!char.IsAsciiDigit(slice[3]) || // Match '0' through '9'.
!char.IsAsciiLetterOrDigit(slice[4]) || // Match a character in the set [0-9A-Za-z].
!char.IsAsciiHexDigitUpper(slice[5]) || // Match a character in the set [0-9A-F].
!char.IsAsciiHexDigitLower(slice[6]) || // Match a character in the set [0-9a-f].
!char.IsAsciiHexDigit(slice[7]) || // Match a character in the set [0-9A-Fa-f].
!char.IsControl(slice[8]) || // Match a character in the set [\p{Cc}].
!char.IsLetter(slice[9]) || // Match a character in the set [\p{L}].
!char.IsLetterOrDigit(slice[10]) || // Match a character in the set [\p{L}\d].
!char.IsLower(slice[11]) || // Match a character in the set [\p{Ll}].
!char.IsUpper(slice[12]) || // Match a character in the set [\p{Lu}].
!char.IsNumber(slice[13]) || // Match a character in the set [\p{N}].
!char.IsPunctuation(slice[14]) || // Match a character in the set [\p{P}].
!char.IsSeparator(slice[15]) || // Match a character in the set [\p{Z}].
!char.IsSymbol(slice[16])) // Match a character in the set [\p{S}].
{
return false; // The input didn't match.
}
// The input matched.
pos += 17;
base.runtextpos = pos;
base.Capture(0, matchStart, pos);
return true;
}
これはなかなか素直、そして意外に賢い。[A-Z]を[ZA-Y]に変えてもIsAsciiLetterUpper()を使ってくれます。
こうなると、やりたいことを正規表現で書いてみて、ソースコードをちょっと借りると言った勉強法さえ可能かもしれません。
例えば正規表現の使えない、あるいは遅い組み込み環境で複雑な文字処理をしたい時等では便利ではないでしょうか?
file ローカル型
ところでfile sealed class ...という見慣れない修飾子が気になった方も居るでしょう。
これはC# 11で導入された「fileローカル型」です。
要するにそのファイル内だけからアクセスできる型です。
- 「file ローカル型」, ++C++; // 未確認飛行 C, 2022
まさにこの[GeneratedRegex]の為に産まれた機能だそうです。
partialメソッドのMicrosoft Learnに挙げられてるのも[RegexGenerated("(dog|cat|fish)")](改名前の[GeneratedRegex]、後述)ですし、割と影響デカい雰囲気はあります。
パフォーマンス
実際パフォーマンスはどうなるのか。
それについては公式ブログが参考になります。
とても長い記事ですが、.NET 7で行った様々な高速化が載ってます。これ以外にも正規表現はだいぶ早くなったそうな。
[GeneratedRegex]に関してはRegexOptions.Compiledが機能しないAOT環境では20倍速くなるそうです。はやい。
- Performance Improvements in .NET 7, .Net Blog, Stephen Toub - MSFT, 2022
| Method | Mean | Ratio |
|---|---|---|
| Interpreter | 9,036.7 us | 1.00 |
| Compiled | 9,064.8 us | 1.00 |
| SourceGenerator | 426.1 us | 0.05 |
上のブログより。Native AOT環境。
.NET 7では正規表現に関して多くの改善が行われています。それについては以下の記事も参照してください。同じく長いです。
- Regular Expression Improvements in .NET 7, .Net Blog, Stephen Toub - MSFT, 2022
さて、手元に正規表現を多用した青空文庫形式をHTMLに変換してくれるツールがあるので試してみましょう。
こちらはTargetFrameworksで.NET 7と.NET Standard 2.0の両方に対応しています。
計測は手軽にPowerShell。新旧で比較します。
入力ファイルは732KBの「吾輩は猫である」(夏目漱石)と2KBの「最後の丘」(漢那浪笛)
PS >Measure-Command { ./aozora2html.exe 789_ruby_5639.zip }
「吾輩は猫である」(夏目漱石) - 749,051B
| .NET | 平均(sec) | 1 | 2 | 3 |
|---|---|---|---|---|
| .NET 6 | 6.490 | 6.494 | 6.453 | 6.525 |
| .NET 7 | 6.653 | 6.788 | 6.593 | 6.578 |
「最後の丘」(漢那浪笛) - 1,576B
| .NET | 平均(sec) | 1 | 2 | 3 |
|---|---|---|---|---|
| .NET 6 | 0.628 | 0.642 | 0.623 | 0.620 |
| .NET 7 | 0.623 | 0.625 | 0.627 | 0.618 |
起動のみ
| .NET | 平均(sec) | 1 | 2 | 3 |
|---|---|---|---|---|
| .NET 6 | 0.192 | 0.198 | 0.188 | 0.189 |
| .NET 7 | 0.211 | 0.213 | 0.208 | 0.212 |
微増・微減・増。
元々RegexOptions.Compiledオプションをオンにしてたので大ファイルで同等~微増はまだ分かりますが、起動が遅くなるのは解せません。
何かミスってる臭いですね。
なおReadyToRunのAOTでも試しましたが同様に変化なしでした。正規表現以外が遅いんですねたぶん。
名前の変遷
ところで前述のとおりMicrosoft Learnの「partial メソッド」記事には、記事執筆当時は以下の例が記されています。
- partial メソッド (C# リファレンス), Microsoft Learn
- archive.org
- Issue
- Pull Request
[RegexGenerated("(dog|cat|fish)")]
partial bool IsPetMatch(string input);
[GeneratedRegex]ではなく[RegexGenerated]と誤植されています。
これ実は誤植ですが、元々の名前由来です。元々の名前は[RegexGenerated]ではなく[RegexGenerator]です。
- RegexGeneratorAttribute.cs, GitHub, 2022/7/23
- Commit, GitHub, 2022/7/28
だから何だという話ですが、検索する時にノーヒットなら"RegexGenerator"を試すのも一つです。
ちなみにQiitaで検索してみましたが3つともノーヒットでした。
.NET Blogで最初に記事を見た時は[RegexGenerator]でした。
.NET 7 addresses all of this with the new GeneratedRegex source generator. (EDIT: After this blog post was published, the RegexGenerator attribute was renamed to GeneratedRegex.)
個人的には生成結果にも付く属性ですし、[RegexGenerator]は変ですが、アルファベットソートで順番に来て欲しいので[RegexGenerated]みたいな名前はしっくりきます。
実際は[GeneratedRegex]です。どうでもいい余談ですね。
変換コード
なおクイックフィックスは<TargetFrameworks/>指定時に#if NET7_0_OR_GREATERのような場合分けはしてくれません。
私は今回変換するにあたり以下のコードを用いてざっくり変換しました。いくつか取りこぼした分は手作業で修正しました。
もちろん自分のコードに合わせて書き換えて下さい。なお実際は変数にキャッシュする必要はありません。
using System.Text.RegularExpressions;
using var sr = new StreamReader(args[0], System.Text.Encoding.UTF8);
using var sw = new StreamWriter(args[1], false, System.Text.Encoding.UTF8);;
var text = await sr.ReadToEndAsync();
var regex = new Regex(@"[\n\r]*[\s\t]*private static Regex\? _(\w+) = null;[\n\r]*[\s\t]*public static Regex \w+\s*=>\s*_\w+ \?\?= new Regex\(@""([^\""]+)"", RegexOptions.Compiled\);", RegexOptions.Singleline);
var result = regex.Replace(text, """"
private static Regex? _$1 = null;
#if NET7_0_OR_GREATER
[GeneratedRegex(@"$2")]
private static partial Regex _$1_GEN();
public static Regex $1 => _$1 ??= _$1_GEN();
#else
public static Regex $1 => _$1 ??= new Regex(@"$2", RegexOptions.Compiled);
#endif
""""
);
await sw.WriteLineAsync(result);
宣伝/日記
aozora2htmlSharp
話は逸れますが、今回この記事を書くきっかけとなったプロジェクト、aozora2htmlSharpの宣伝をします。
これはaozorahack様のRuby版aozora2htmlをC#に書き換えたものです。
つまり公式とほぼ同じ挙動をする青空文庫形式の変換器です。
RubyとC#との違いも大きく、色々と苦労しました。現在数か月放置状態ですが。
ビュワーを作ったりするのに便利だと思います。
私がaozora2htmlを移植したのも私が開発している高機能電子書籍リーダー、BookViewer 3への入力に使う目的です。
これもまたすごいビュワーです。自慢です。
aozora2htmlSharpでHTMLに変換し、それをEPUBに変換し(未実装)、それをWebView2でBibiというEPUBビュワーに食わせて(実装済み)、ついでに青空文庫クライアントも作りたい(未実装)。なので道は長いです。
BookViewer 3はUWPのアプリなので.NET Standard 2.0までしか対応せず、そのせいでGeneratedRegexは使えません。
速くバックポートして欲しいです。それかUWPの.NET Standardをあげて欲しいです。
…と思っていたのですが、実際差がなかったのでそれ以前の問題ですね。悲しいです。
今回GeneratedRegex対応しても大差なかったのは、おそらくSliceやらSpanやら使うべき場所で使ってなかったりパフォーマンスを気にしてなかったりでそもそも遅いからでしょう。
実は[GeneratedRegex]を呼んでなかったとか.NET 7使ってなかったとかはないと思いますが、あるかも知れません。
冷静に考えて私のパソコンは古いとはいえ750KB変換するのに6秒ってのは何かが狂ってます。
でもRubyのコードをできるだけそのまま移植する上では自然でしたし、そういうコード普段書かないので仕方ないです。
修正するとすれば相当先です。悪しからず。
計算と哲学
それから去年私は「計算と哲学 Advent Calendar 2021」を作成し、自分で7記事書きました。
なかなか面白い記事が書けたと思うので是非覗いてみてください。
2021年のアドベントカレンダーですが、別に今からでも参加しても構いません。