自分のブログの記事で、ここも投稿します。
ブログの方が読みやすいと思います。
site: http://kura.gq/machine-learning/decision-tree-python-sklearn/133/05/
課題の目的
Pythonのscikit-learn使て、決定⽊学習モデルを実行します。具体的には、決定⽊学習モデルを習って、デモのアヤメ(iris)データセットを分類して、結果を表示します。
解説
アイリス(iris)データセットとは
アイリスのデータセットはよく知られたデータセットです。sklearnパッケージの中には、このデータセットがあります。「¥sklearn¥datasets¥data¥iris.csv」で見つけました。
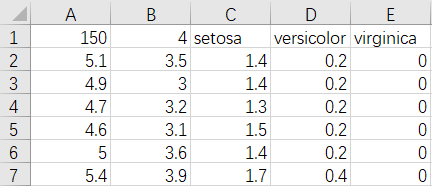
このデータセットには、データポイントが150個で、各データポイントには4つの変数があります。AからDまでは、ガクの長さ、ガクの幅、花弁の長さ、花弁の幅ということです。Eは花の種類で、この中で、0はsetosa、1はversicolor、2はvirginicaです。
scikit-learnの機能
scikit-learn のDecisionTreeClassifierは、決定⽊学習モデル使て、データセットに対して分類できるクラスです。 入力は「n_samples、n_features」を使用して、「n_samples」はトレーニングサンプルで、「n_features」はクラスラベルです。
例の実装
環境構築
Python3の中に、scikit-learnをインストールします。結果の可視化のため、Graphvizをインストールします。
具体的には、Graphvizはここに(https://graphviz.gitlab.io/download/)ダウンロードして、インストールします。
そして、パッケージのscikit-learn、Graphviz、pydotplusをインストールします。pycharmの場合は、ここまではいいです。
パケージをロード
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'C:¥Program Files(x86)¥Graphviz2.38¥bin¥'
アイリスのデータを読み込み、決定⽊学習モデルを使用してモデルを習って取得します。
iris = load_iris()
clf = tree.DecisionTreeClassifier().fit(iris.data, iris.target)
モデルをドットファイルiris.dotに保存します。
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
結果の可視化
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
結果
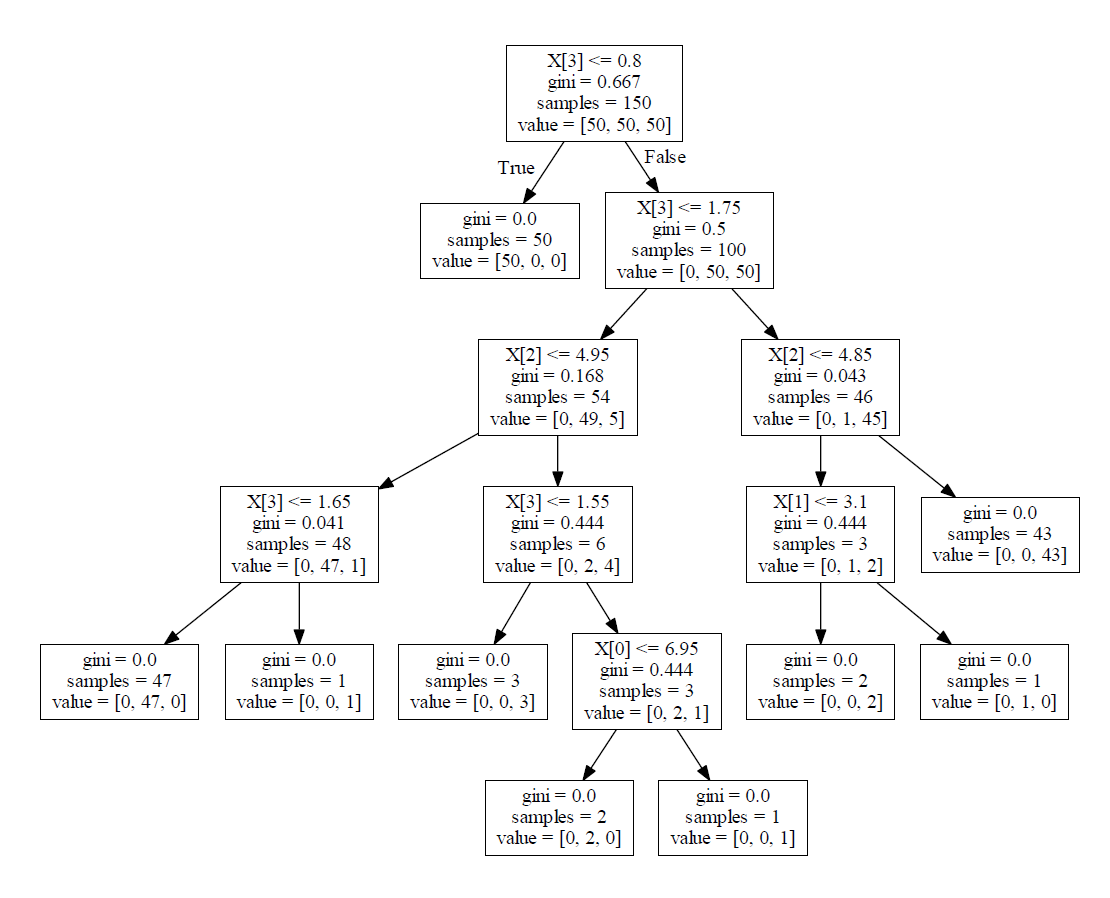
結果の解説:
X[0]からX[3]までは、ガクの長さ、ガクの幅、花弁の長さ、花弁の幅です。sampleは、このノード上のデータポイントの数です。valueは、このノード上のデータポイントの種類です。例えば、[0, 47, 1]とは、setosaは0個、versicolorは47個、virginicaは1個です。
決定木の意味は、次の例で説明されています。
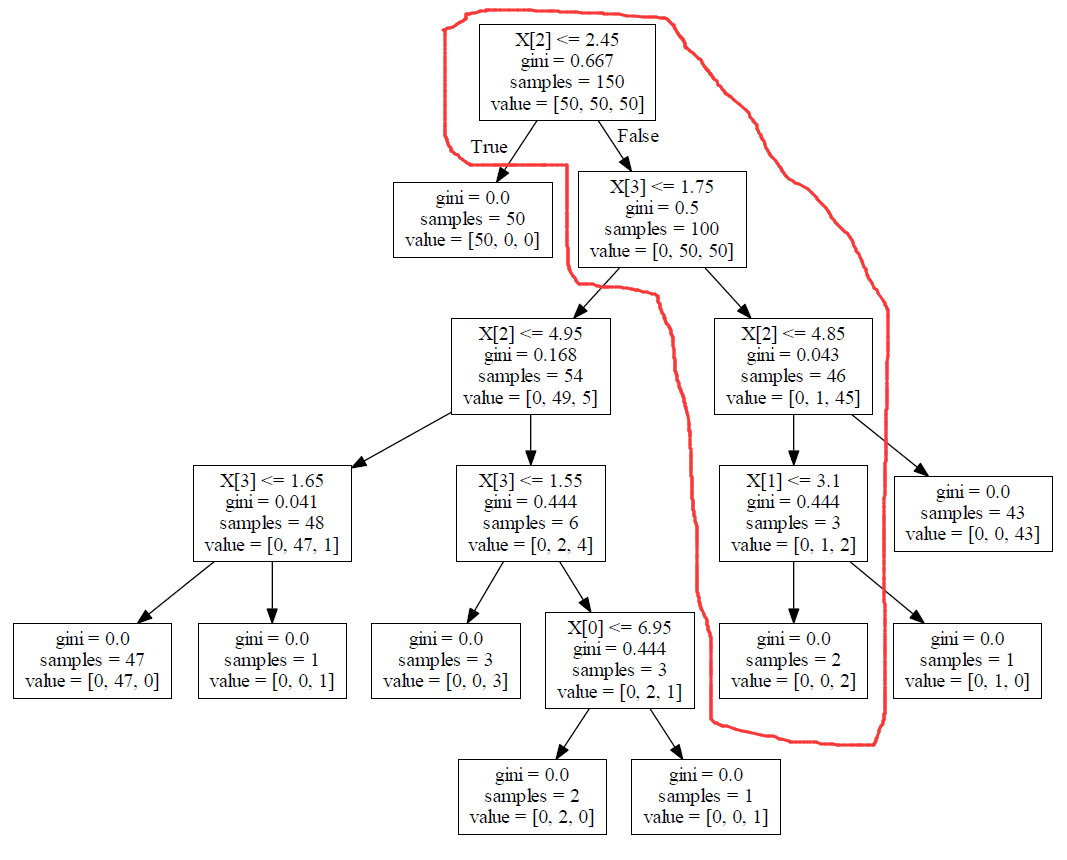
データポイント一つにとって、もし:
花弁の長さ <= 2.45 は False、
そして、花弁の幅 <= 1.75 は False、
そして、花弁の長さ <= 4.85 は True、
そして、ガクの幅 <= 3.10 は True、
このデータポイントはvirginicaです。