この記事はNSSOL Advent Calendarの11日目の記事です。
概要
弊社ではDeep Learning開発を効率的化する「KAMONOHASHI」というプラットフォームを開発しています。1
私はその開発に携わっています。
「KAMONOHASHI」は内部でKubernetes(k8s)を使用しています。
「KAMONOHASHI」の追加機能を検討していた際に、Kubernetes(k8s)でNFSボリュームマウントする必要のある機能の改修が持ち上がりました。
私はそれまでUXがメイン担当だったので「Docker何それ???」、「Ku、Kube...読めない」な状態だったのですが、「Docker,k8s触りたいです!」などと軽率に言ってみたところ先輩方から「せっかくだからやってみなよ」というありがたいコメントをいただき、機能改修にチャレンジしてみることになりました。
そんなコンテナ初心者がk8sによるNFSボリュームマウントに挑戦した際に、勉強していった内容や、`先輩たち「k8sちょっと勉強してyamlを書き換えるだけだよー」→全然違った()というお話を書いています。
対象読者
Docker/Kubernetes(k8s)これからがんばるぞ!でもコンテナ詳しくない...という程度。
結構初歩的なことから書いているので、Docker/Kubernetes ちょっと知りたいと思っている方におすすめです。
すでにコンテナチョットデキル、な方はozota先輩のAdvent Calendarを読むのをおすすめします。2
今回やったこと
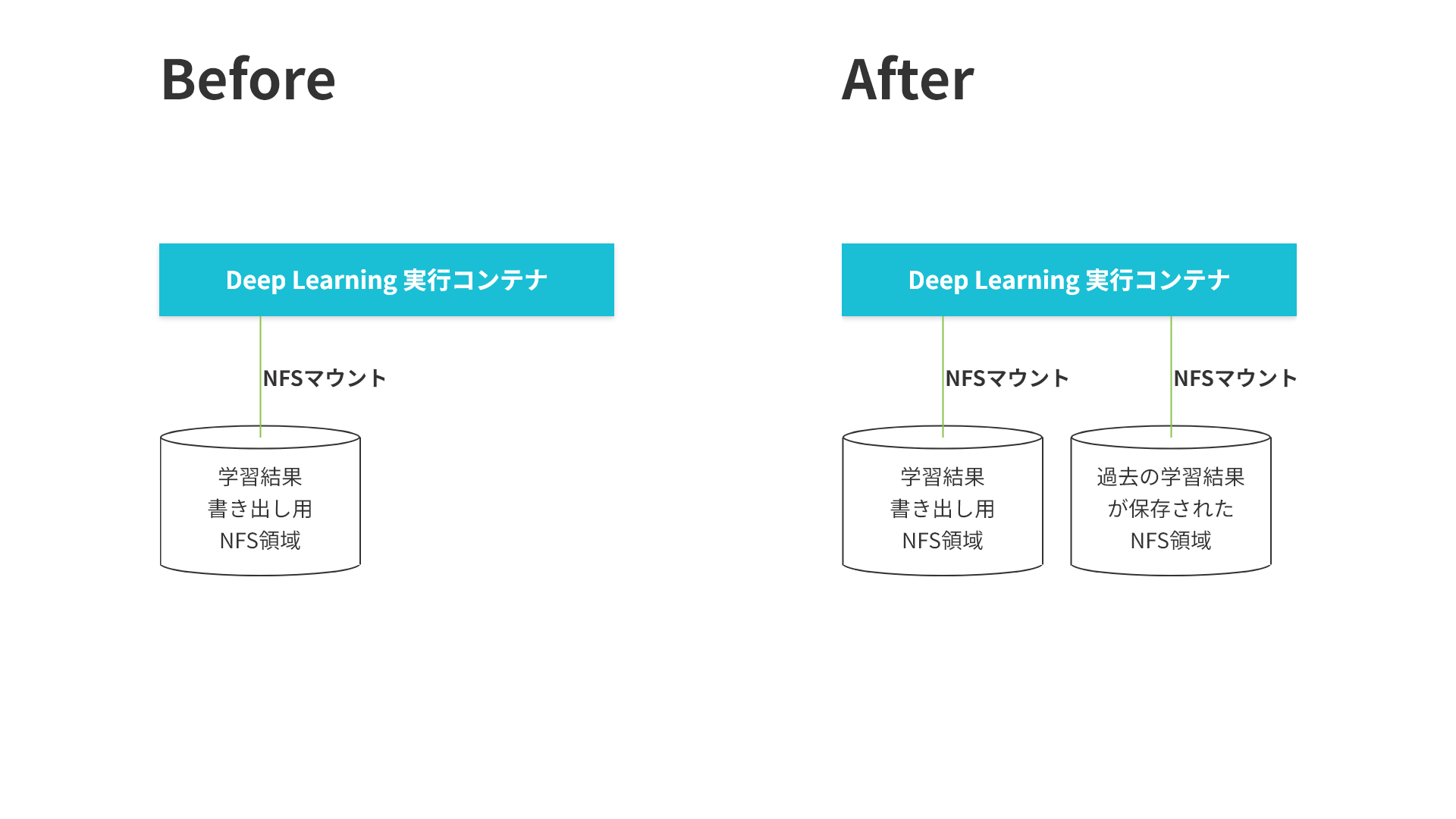
KAMONOHASHIではDeep Learningの学習結果をNFSに保存しています。これはNFS共有を通じて、
Deep Learningの学習途中でも学習の進捗が分かるようにするためです。
AIの精度向上度合いをグラフ表示したりしています。
これまでは学習結果の書き出しのみにNFSを使用していたのですが、
以前学習した結果を次の学習の入力にする機能が欲しいという要望を受け、
新規学習開始時にNFSに保存されている過去の学習結果もマウントするように改修しました。
勉強・実装した内容
1. Dockerの概要を掴む
2. Dockerでボリュームマウントを試す
3. k8sの概要を掴む
4. k8sのボリュームマウントを試す
5. 実装
6. 最後にどんでん返しが起こる
1.Dockerの概要を掴む
-
QiitaのDocker解説記事でDocker概要をつかむ
- 記事を読んでコンテナとはプロセスを隔離して起動する技術であることをなんとなく理解しました。
- Docker登場以前にあった課題とDockerの機能によって解決する課題を下記にまとめました。
|従来技術|何が問題だったか|Dockerが解決する内容|
|:--|:--|:--|
|構成管理|同じ定義書を利用しても、隣の人とまったく同じ環境になる保証がない|gitのようにcommit, push, pullを使った作業の履歴管理ができる。構成管理ツールを使いDockerイメージを作り、レジストリを介して共有することにより解決|
|構成管理|ひとつのプロジェクトで、複数バージョンのソフトウェアを同時に使うのは困難|OSディストリビューションごとアプリが分離できるので同時に扱えるように |
|VM|VMスナップショットからは作業履歴を追いにくい|イメージに対して編集した内容は、$ docker historyで確認できる|
|VM|サーバは数分で起動するが、数分だと時間がかかりすぎ|起動も停止も一瞬 |
|VM|ポータビリティが下がるベンダーロックインの心配|Windowsを含めた大手OS、クラウド各社がサポートを表明| -
Docker公式チュートリアルを流しました。解説記事も必要に応じて参考にしました。
2.Dockerでボリュームマウントを試す
- Dockerにおけるマウントとは3
コンテナの外にあるデータを、コンテナの中で利用できる状態にすること。
あるいはコンテナの中にあるデータを、コンテナの外で利用できる状態にすること。
- ボリュームマウントとは
コンテナの内/外のファイルやディレクトリをコンテナの外/内で利用できるようにする機能のこと。
- Qiitaの記事を参考にvolumeマウントについて試しました。
docker run -v /host/path:/container/path some_image
// ホストの /host/path を、コンテナの /container/path にマウント
KAMONOHASHIではファイルの随時書き込みを行うNFSの機能と、ブラウザアクセスを行う機能を併せ持つminioのnas gateway機能を利用しています。これにより、学習中にリアルタイムにログを確認したり、データをブラウザからダウンロードしたりすることを可能にしています。
ということでminioのイメージを使用しコンテナを起動してみました。
起動する際に、ホストの/mnt/dataをコンテナの/dataにマウントしました。
docker run -it -p 9000:9000 --name minio \
-e "MINIO_ACCESS_KEY=****" \
-e "MINIO_SECRET_KEY=****" \
-v /mnt/data:/data \
minio/minio server /data
docker inspect --format='{{.Mounts}}' コンテナID
[{bind /mnt/data /data true rprivate} ]
ホストの/mnt/dataがコンテナの/dataにマウントされていることが確認できました。
3.k8sの概要を掴む
- k8sを使うと何が出来るのか4
前段ではDockerを利用することでホスト上にコンテナを立ち上げることができました。
しかしKAMONOHASHIでコンテナを利用しようとすると下記のようなことを考える必要がありました。
- 複数のDockerホストの管理
- コンテナのスケジューリング
- コンテナの死活監視
- ログの管理
- Infrastructure as Code
コンテナオーケストレーションエンジンであるKubernetes(k8s)を利用することで、これらの課題を解決することができます。k8sではYAMLでマニフェストを書くことで、実行するコンテナなどを宣言的なコードにより管理しています。
ちょうど社内でk8s勉強会が実施されていたため、Katacodaでハンズオンしつつコンテナ仮想化技術からkubernetesの基礎知識を学びました。Katacodaは、コンテナ技術に強い無料の学習サイトで、ブラウザから簡単に試すことができるため、とりあえず触ってみたい人にはおすすめだそうです。5
実際ハンズオンで触ってみて、k8sの環境構築をせずにいきなりk8sのコマンドを叩けるのが、環境構築で躓きそうな私にとってはありがたいポイントでした。(ちなみにk8sの環境構築についてはozota先輩が12/1の記事に書いています。)
![]() 先輩から一言
先輩から一言
Kubernetesは一般向けには上記のメリットがあるのですが、Deep LearningプラットフォームであるKAMONOHASHIにとっての一番のメリットは、GPUのスケジューリング機能です。詳しく知りたい人は「nvidia-docker」や「device plugin」で検索してください。この記事の内容からはそれてしまうので解説はしません
4.k8sのボリュームマウントを試す
- k8sでのvolumeの書き方
k8sでコンテナ(Pod)を作成する際の、データの格納場所(Volume)を指定する方法を調査しました。
コンテナ(Pod)が死んでしまうと、データが消滅してしまうので、Volumeに格納しておく事で、状態を維持できます。
タイプは何種類もありますがここではhostpath,nfsの書き方を紹介します。
-
-
hostpath
k8sノード上の領域をコンテナにマッピングするプラグイン。
-
hostpath
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory

-
-
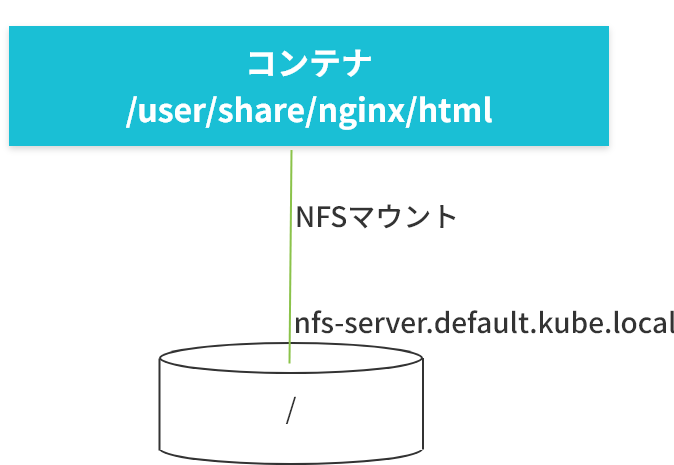
nfs
PodがTerminateされてもnfsボリュームの内容は保存されます。
-
nfs
apiVersion: v1
kind: Pod
metadata:
name: nfs-web
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: nfs
nfs:
server: nfs-server.default.kube.local
# directory location on nfs
path: "/"
![]() 先輩から一言
先輩から一言
Kubernetesに詳しい人はPV・PVCについて気になる方もいるかもしれません。 KAMONOHASHIでは、記述が簡単、内部コンポーネントが少ない(PV回りのバグを避けられる期待)、容量の制限は不要(割り切り)等の考慮から上記の方法を採用しています。
5.実装
4.まででk8sによるNFSマウントの記述方法が分かりました。 いよいよKAMONOHASHIの実装です。
KAMONOHASHIはWebアプリであり、ユーザーが学習を開始するリクエストを投げた際に内部でKubernetesのYAMLを組み立てています。
また、KAMONOHASHIでは学習実施ごとにNFS上のディレクトリ(nfs-server:/training/trainingId/)を作成し、 コンテナ内の/kqi/outputにマウントしています。ユーザーにはそこに学習結果を書き出してもらうという仕様です。
# 学習2の結果(/kqi/output)をnfs(nfs-server:/training/2/)にマウント
apiVersion: v1
kind: Pod
metadata:
name: training2
spec:
containers:
- name: training2
image: tensorflow
ports:
- containerPort: 80
volumeMounts:
- name: nfs
# k8sコンテナのvolume
mountPath: "/kqi/output"
volumes:
- name: nfs
nfs:
server: nfs-server
# directory location on nfs
path: "/training/2/"
ついに、以前の学習結果のマウントを指定した場合の学習結果のNFSマウントを試します。
# 過去の学習1の結果をコンテナの/kqi/parentにマウントして学習2を実行する
apiVersion: v1
kind: Pod
metadata:
name: training2
spec:
containers:
- name: training2
image: tensorflow
ports:
- containerPort: 80
volumeMounts:
- name: parent
# k8sコンテナのvolume
mountPath: "/kqi/parent"
volumes:
- name: parent
nfs:
server: nfs-server
# directory location on nfs
path: "/training/1/"
完成です!

...と思いきや、完全に間違っていました。
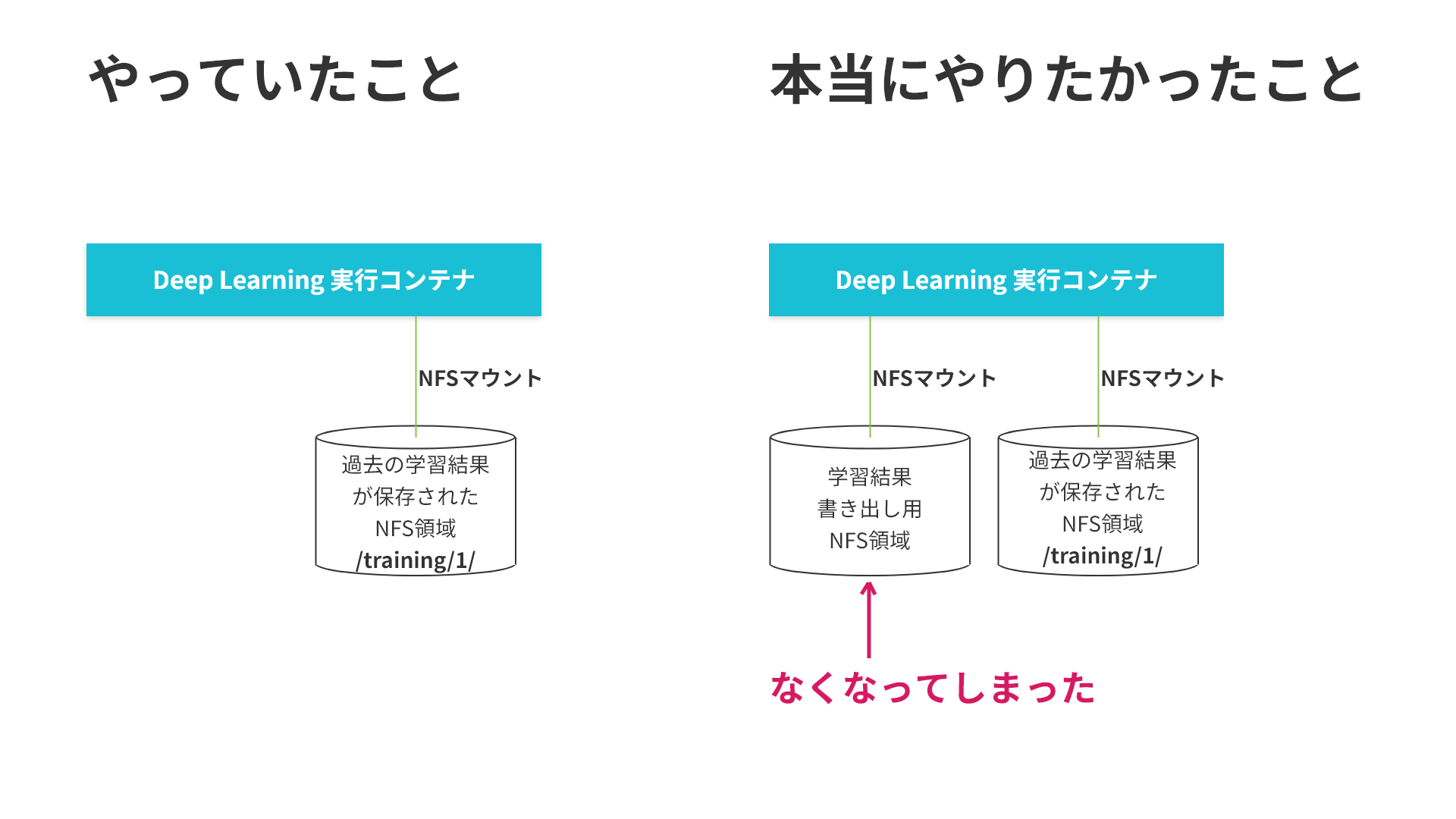
以前の学習結果(/kqi/parent/)を読み込んで新しい学習を実行する際に、新しい学習の結果を保存するディレクトリ(/kqi/output/)を用意するのを忘れていました。ここを修正すればOKのはず。。。
6.最後にどんでん返しが起こる
なんとKAMONOHASHIの仕様上、volumeMountsのmountPathを条件によって変更する記述は実はyamlファイルを書かなくてもできるようになっていました。ここまでyamlを必死に書いていた自分は唖然としました
![]() 先輩から一言
先輩から一言
後でNFSマウントはどうせ増えるだろうとソースコードに拡張性を持たせてたのですが、実装したのがずいぶん昔で完全に忘れていました。 ごめん!
おわりに
今回はk8sによるNFSボリュームマウントに挑戦した話を書きました。
冒頭に、
先輩たち「k8sちょっと勉強してyamlを書き換えるだけだよー」→全然違った()
と書いた通り、コンテナ初心者には結構難しかったです。
特に2個のボリュームをマウントしている例が意外とネット上では見つからず初心者にとっての混乱ポイントでした。
僭越ながら、これからdocker,k8sを始める方の参考になれば幸いです。
ちなみに、今回苦戦して開発した機能で、KAMONOHASHIユーザの方々のkaggle6位に貢献できたようで、ユーザが喜ぶ機能を作れてよかったなあと思っています。6
-
KAMONOHASHIは新日鉄住金ソリューションズ株式会社の登録商標です。 ↩
-
同じグループの先輩。インドに行っている間に弊社のAdvent Calendarが埋まってしまったため、個人で毎日記事を執筆しています。 ↩
-
大変分かりやすい解説記事でした。今こそはじめようKubernetes入門 ↩
-
今回執筆時に見つけたブログです。コンテナ技術の学習するなら圧倒的にKatacodaがおすすめ ↩
-
詳細はもうすぐ広報がでると期待しています。 ↩