この記事は何?
kunishou が 2022 年 1 月 ~ 2023 年 3 月の期間に Kaggle の NLP コンペに参加していたときにまとめていた NLP トリックの雑なメモ書きです 。
最近、2023-24年のKaggleコンペから学ぶ、NLPコンペの精度の上げ方 という記事を拝見し、「そういえば、自分も NLP コンペのトリックをメモしてたな...」と思い出しました。
もともとは自分の振り返り目的でメモを取っており、たくさん蓄積してきたらそのうち何らかの形でアウトプットしようと考えていましたが、2023年後半に興味が LLM に移ってしまったため、 供養の意味も込め、上記記事に便乗してアップしてみます 。
メモリ最適化など今となっては当たり前となっている技術も多いですが、メモのどれかがコンペに取り組む上での何らかのヒントになれば幸いです。
(メモを取る中で頭の整理で作成した NLP トリックマップ)
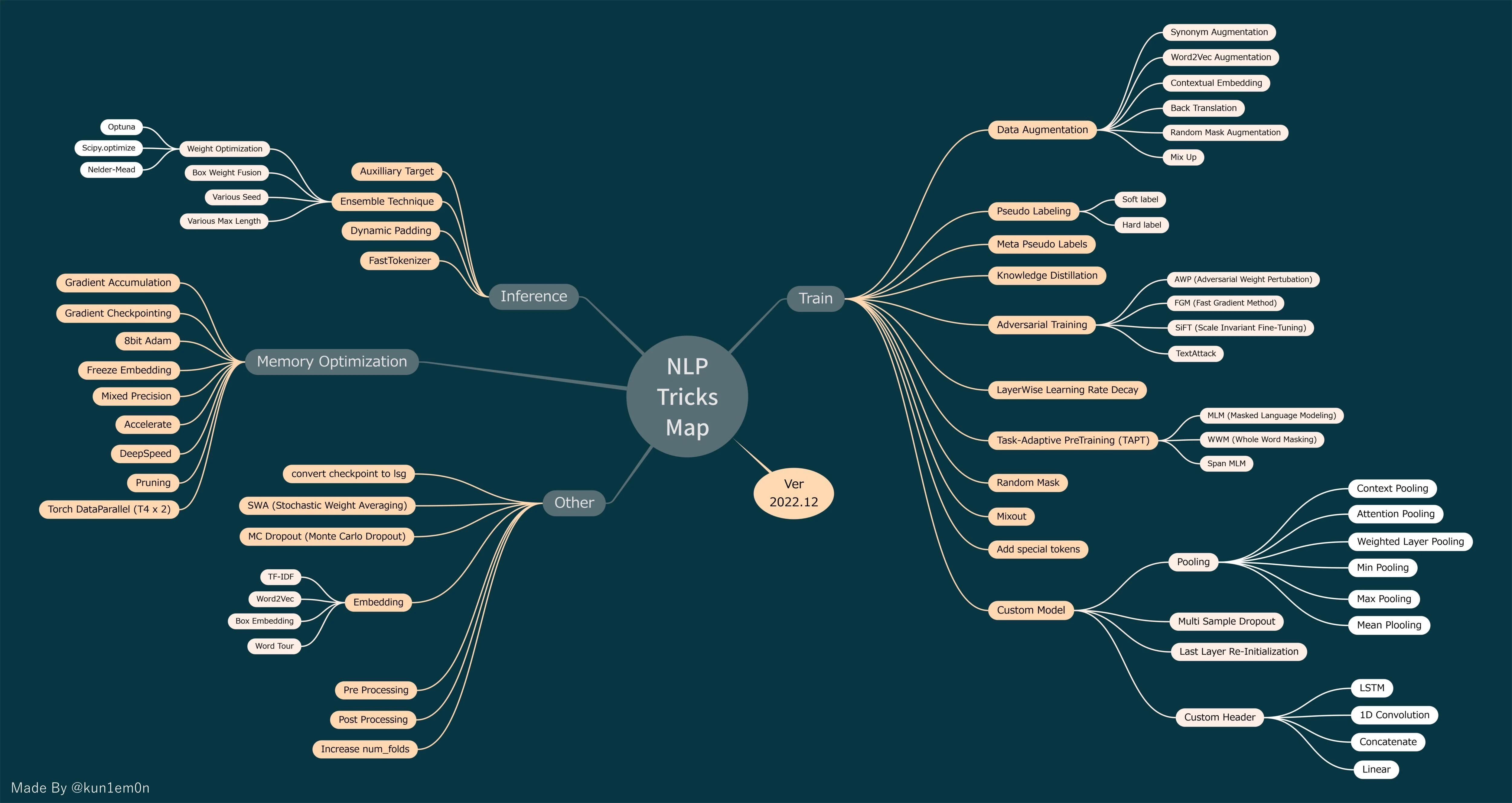
留意点
- 雑なメモ書き、リンク集です(見づらくてすみません)。
- 2022 年 1 月 ~ 2023 年 3 月までのコンペに参加する中でメモしたものです (そのため、少し情報は古いです)。
- 距離学習系のコンペ( Learning Equality コンペ等)や Pooling 系の話は入っていません。
- メモリ最適化など、2024 年 7 月現在の今となっては当たり前になった手法も書かれています( 読み飛ばして大丈夫です )。
- 記事中の Feedback Pirze 1 とは Feedback Prize - Evaluating Student Writing、Feedback Prize 2 とは Feedback Prize - Predicting Effective Arguments、Feedback Prize 3 とは Feedback Prize - English Language Learning のコンペを指します。
1. Memory Optimization
- メモリ最適化手法です。今では当たり前になった手法となっているので読み飛ばしても大丈夫です。
Methods and tools for efficient training on a single GPU
- メモリ最適化に関する huggingface 公式チュートリアル(このページを見れば大丈夫)
8bit Adam
- 字の如くAdamの8bit版。32bit Adamと比較してメモリ使用量を抑制
Adafactor
- Adam を元にした最適化アルゴリズムで、メモリ容量の削減とパラメータスケールに応じた学習率の調整を行う手法
Gradient Checkpointing
- 計算速度を犠牲にしてメモリ使用量を抑える手法
- Feedback Prize 1 コンペにおいて Kaggle GPU で Adam を使ってバッチサイズ 1 のシーケンス長 512 で DeBERTa-v2-xlarge を訓練しようとすると、OOM エラーが発生するが、8-bit Adam、float16、gradient checkpointing を使えば、バッチサイズ 8 で訓練できたとのこと
Mixed Precison Training
- 通常、32 ビットの単精度浮動小数点数で実施される計算を半分の 16 ビットの半精度浮動小数点数で行なうようにすることで計算時のメモリを半分に抑える手法
- PyTorch の場合、amp.autocast() を用いることで簡単に実装可能
- huggingface Trainer クラスを使用する場合は training_argments で fp16=True とすれば実施可能
Accelerate
huggingface 公式ページを参照
DeepSpeed
- GPU と CPU をパラレルに使用する方法。GPU 側で OverFlow したメモリを CPU 側にオフロードする
- CPU 側でも計算させるため、学習速度は遅くなる。huggingface Trainer クラスを使用する場合は training_argments で引数宣言すれば簡単に実装可能
2. Optimizer
Adabelief-Optimizer
- NeurIPS2020 にて Spotlight に選ばれた手法
- SGD のような「高い汎化性能」と Adam のような「速い収束性」「より良い安定性」の 3 つを兼ね備えたオプティマイザー
- Feedback Prize 1 で試してみたがあまり精度は向上せず( AdamW のほうが精度良かった)
3. Model Ensemble
Weighted Box Fusion
- NER タスクのコンペ( Feedback Prize 1 )において種類の異なる Transformer のアンサンブルに使用された
Ensemble Weight Optimization
- いくつかのモデルをアンサンブルする際の重みの決定方法のあれこれ
- Optuna 、リッジ回帰、 Nelder-Mead 、Hill-Climbing 、シンプルに平均を取る など
- Feedback Prize 3 の上位解法 を見ると Nelder-Mead が多い印象(ただ、1st place solution は Optuna を使っていたりするので単純にどれが最も良いとは言えない)
4. Data Augmentation
Synonym Augmentation , Word2Vec Augmentaion , Contextual Embedding , Back Translation
- nlpaug モジュールを用いた様々な Data Augmentation 手法
- Feedback Prize 1 では Back Translation が一番効果があったとのこと
- 自分がこれまでコンペで色々と試した経験上、これらの Augmentation 方法では劇的な精度向上効果は得られませんでした
Let'S Talk Text Augmentations
Presudo Labeling
- 一般的な手法なので説明は省略
- ハードラベル or ソフトラベル
- リークにはけっこう気を付ける
Meta Pseudo Labels (MPL) ★
5. Faster Inference
Uniform Length Batching
- 学習でインプットするデータのシーケンス長をソートして、バッチごとのシーケンス長をそろえることで無駄なゼロパディングの計算を抑制、推論速度を向上
Uniform Dynamic Padding
FastTokenizer
- 標準の Tokenizer を huggingface で用意されている FastTokenizer に変更することで
推論時間を短縮
参考
6. Adversarial Training
各種 Advesarial Training の概要資料
Advesarial Weigthed Pertubations ( AWP ) ★
FGM: Adversarial Training Methods for Semi-Supervised Text Classification (ICLR2017)
TextAttack
- インプットするテキストに対して単語の並びを変えたり、一部を類義語に変えたりして摂動を加えるライブラリ
- 回帰と分類タスクのみ利用可能か?あまり効果がないというQiita記事もあり
97. Other Tricks
Layer-wise Learning Rate Decay ( LLRD )
- ファインチューニング時の学習率を一律ではなく層によって変える手法。層が深くなるにつれて減衰させた学習率を各層の訓練に適用
- Feedback Prize - Predicting Effective Arguments にてよく利用されていた
( layerwise_* 周辺が該当 )
Last Layer Re-Initialization ( LLRI )
- 事前学習モデルの最後の層の重みを指定した層分だけ初期化してからファインチューニングすることでコンペのタスクにより最適化させる手法
- Feedback Prize - Predicting Effective Arguments にてよく利用されていた
( def re_initializing_layer が該当 )
Convert_checkpoint_to_lsg ★
- Short sequence モデルを Long seqence モデルに変換する手法
- 例えば、RoBERTa の Max length を 512 → 2048 に拡張する等が可能
- アンサンブルするモデルに多様性を持たせる目的で利用されていた(Feedback Prize 1 の 2nd place solution で Chris チームが利用)
Task-adaptive pretraining with MLM (Masked Lnaguage Modeling)
- コンペデータを用いてモデルを MLM で事前学習させることで精度を向上させる手法
- 過去のコンペでは MLM をするだけでメダル圏に入れるようなコンペもあった
Task-adaptive pretraining with WWM (Whole Word Masking)
- WWM は MLM をより厳しくした事前学習方法。 MLM では精度上がらなかったけど、WWMでは精度が上がったという人もコンペでは見かけた
- ただし、WWM は MLM より学習時間が半端なく長い
Span MLM
- MLM のマスキングの確率を 40〜50 % に変更
- 通常のランダムマスキングの代わりに、長さ 3 〜 15 の連続したトークンをマスキング
- 連続した token をマスクするという点では WWM とも似ているか
Knowledge Distillation
- 一般的な手法なので説明は省略
Stochastic Weight Averaging (SWA)
- 訓練中に複数のエポックから得られる異なるモデルの重みを平均化することで、より優れた性能を持つモデルを得る
Multi Sample Dropout
- 過学習対策の手法
- 回帰タスクには不向きな例もあり
Mix Out ( 正則化手法 )
Ranodm Mask
Auxilliary Target Learning
関連する複数の課題を同時に学習し、精度の向上を図るマルチタスク学習
NBME 1st solution (スライド28)を参照
Adding Special Tokens
DeBERTa で "\n" を加える等
Custom Trainer / Model
Custom Trainer や Custom Model の方法について書かれた記事
Prompt Learning
SVM with Embedding Featrues
- これはテクニックではないですが、Embeddingしたベクトルを特徴量とし、モデルに SVM を用いると高い精度が出ることが稀にあります( Feedback Prize 3 の 1st place solution など)。理由は不明なのでこのあたりを解説してくれる Discussion があればぜひ読んでみたいです。
Box Embedding / Word2Box
- Kaggle で使われた実績のあるものではなく個人的に気になっている技術です
- 単語を箱で表現する技術。抽象的な単語ほど箱の面積が大きくなるので、これを文章に適用して文章の抽象度のようなものを算出し、その抽象度を特徴量として追加したら精度向上しないか? (ネット上を探しても、試してみたような記事もあまりなく詳細は不明)
98. Other Links
有益な記事のリンクです
・Kaggleで学んだBERTをfine-tuningする際のTips①~⑤
AI SHIFT さんのとても勉強になる記事です
https://www.ai-shift.co.jp/techblog/2138
https://www.ai-shift.co.jp/techblog/2145
https://www.ai-shift.co.jp/techblog/2170
https://www.ai-shift.co.jp/techblog/2985
https://www.ai-shift.co.jp/techblog/3161
BERTの精度を向上させる手法10選
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing ★
- DeBERTa に関する日本語の解説記事
- DeBERTa V1~V3 の違いがとても分かりやすく説明されている
- V3 で敵対的学習(SiFT)が行われてることをこの記事を読んで初めて知りました
- 一読しておくと DeBERTa のお気持ちが少しは分かるようにかも?
99. Kaggle Solutions
NBME 1st solution ( currypurin さん )
Kaggle NBME解法まとめ
Kaggle Feedback Prize 2021コンペ反省会 ( shimacos さん )
Feedback Prize 1 は初めて参加した Kaggle NLP コンペでしたが、こちらの資料でモデルに Relative Positoinal Attension 系や Sinusosidal Positional Encoder 系など色々あることを知りとても勉強になりました(なぜ DeBERTa は token length 512 以上を扱えるのか)。
kaggle Feedback Prize 2022 上位解法まとめ
Kaggle Feedback Prize 3 上位解法まとめ
私がコンペの振り返りのために自分でまとめたものです