はじめに
Firestoreは、NoSQLのドキュメントデータベースです。
この記事では、Google Cloud で Firestore を使い始めるための手順を紹介します。具体的には、Pythonのプログラムを用いてローカル環境からGoogle Cloud上のFirestoreにアクセスを行い、データを格納するところまでを目指します。
(公式ドキュメントが一番参考になるので、何か困ったら公式ドキュメントを参考にしましょう)
本記事は、2023年11月17日時点の情報です。
名前が似ている「Filestore」というサービスもありますので、間違えないように気をつけましょう。
モード選択では、ネイティブモードを選択しています。
実施環境
- OS:macOS Ventura 13.5 (M2 mac)
- ブラウザ:Google Chrome 119.0.6045.123(Official Build) (arm64)
- Python:3.9.6
手順
1. Googleアカウントを作成
Googleアカウントを作ります。ここの手順は本題とは関係ないので、省略します。Google Chrome上でログインしておきましょう。
2. Google Cloudに登録
Firestoreは、利用登録を行なって課金を有効化しないと使えない(はず)です。クレジットカードを登録する必要がありますが、無料枠の範囲内であれば無料で使用することができます。無料枠を超過したとしても、フルアカウントを有効化しなければお金はかからないみたいです。

3. コンソールに移動してプロジェクトを作成
手順2の、コンソールというボタンを押しても移動できます。
Google Cloudの利用登録を行なった場合は、自動的にプロジェクトが作られます。そうではない人は、利用したいプロジェクトに移動するか、新しくプロジェクトを作成します。
4. Firestoreを有効化
左上のハンバーガーメニューを開き、「プロダクトとソリューション」→「すべてのプロダクト」をクリックします。

すると、様々なGoogle Cloud上のサービスが並んでいる画面が表示されます。ここで、「データベース」という項目にある「Firestore」をクリックします。
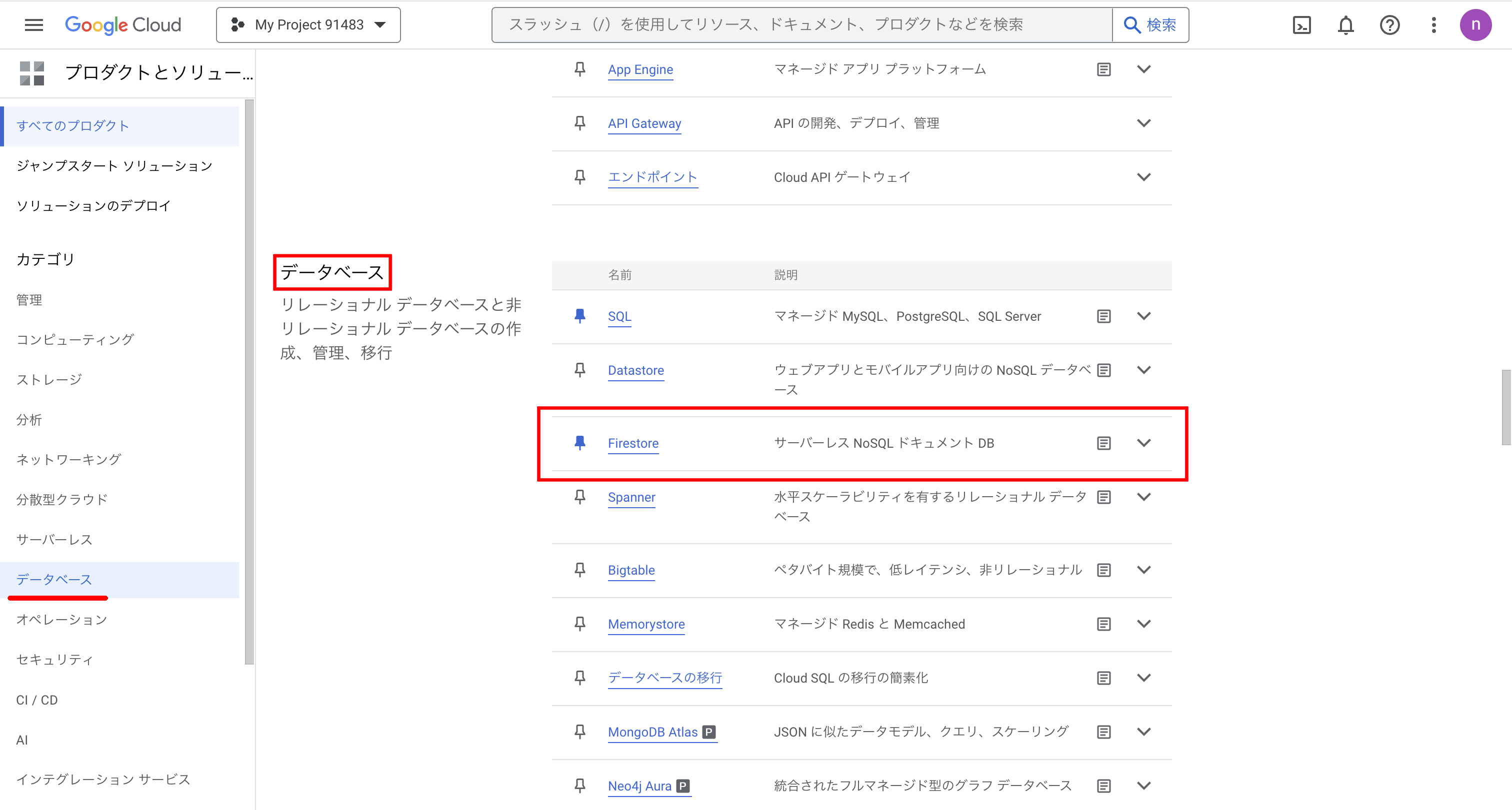
最初は「Firestore APIが有効になっていません」というエラーメッセージが見られるかもしれませんが、数秒待ってからリロードすれば無くなります。無くならない場合は、Google Cloudの課金が有効になっていない可能性があります。
5. Firestoreデータベースを作成する
「CREATE DATABASE」をクリックし、データベースを作成します。

次に、Firestoreのモードを選択します。ここでは、ネイティブモードを選択しました。
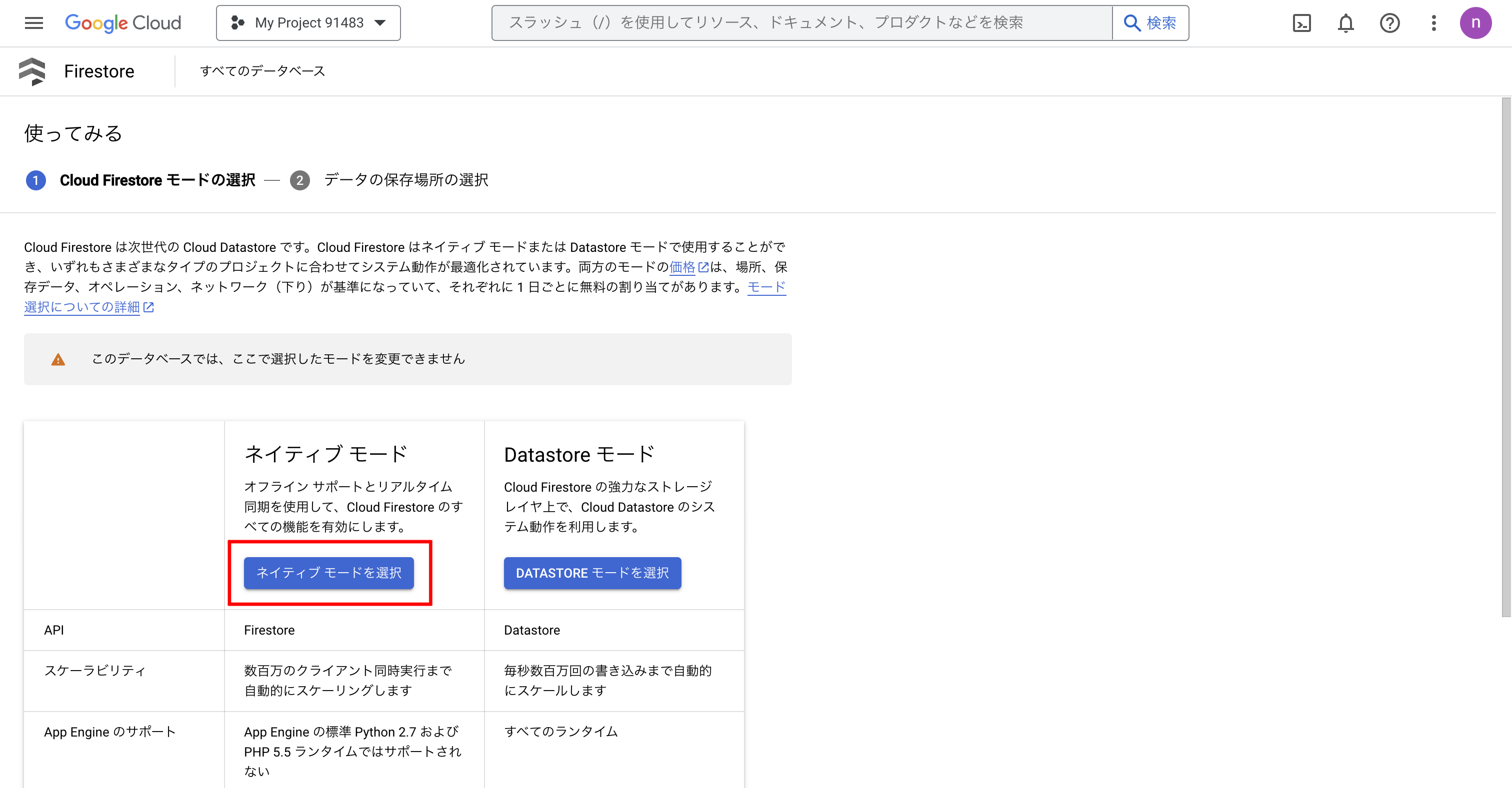
最後にロケーションを選択します。データの保存場所によっては費用や可用性が異なる上、一度作成すると変更ができないため慎重に選択します。ここでは「us-west1(Oregon)」を選択しました。
「データベースを作成」をクリックすることで、IDが(default)のFirestoreデータベースが作成されます。

一番最初のデータベースはブラウザ上で作成できますが、複数のデータベースを作成する場合は、gcloud CLIを使って設定する必要があります。
また、特に理由がない限り、(default)データベースのみを用いて開発を行います。後の手順でデータベースにアクセスする際、接続先を指定しない場合は「(default)データベース」に接続されることになっています。
6. サービスアカウントを設定
手順5でFirestoreの設定が終わりました。本手順では、ローカルからアクセスするための権限設定を行います。
左上のハンバーガーメニューを開き、「IAMと管理」→「サービスアカウント」をクリックします。
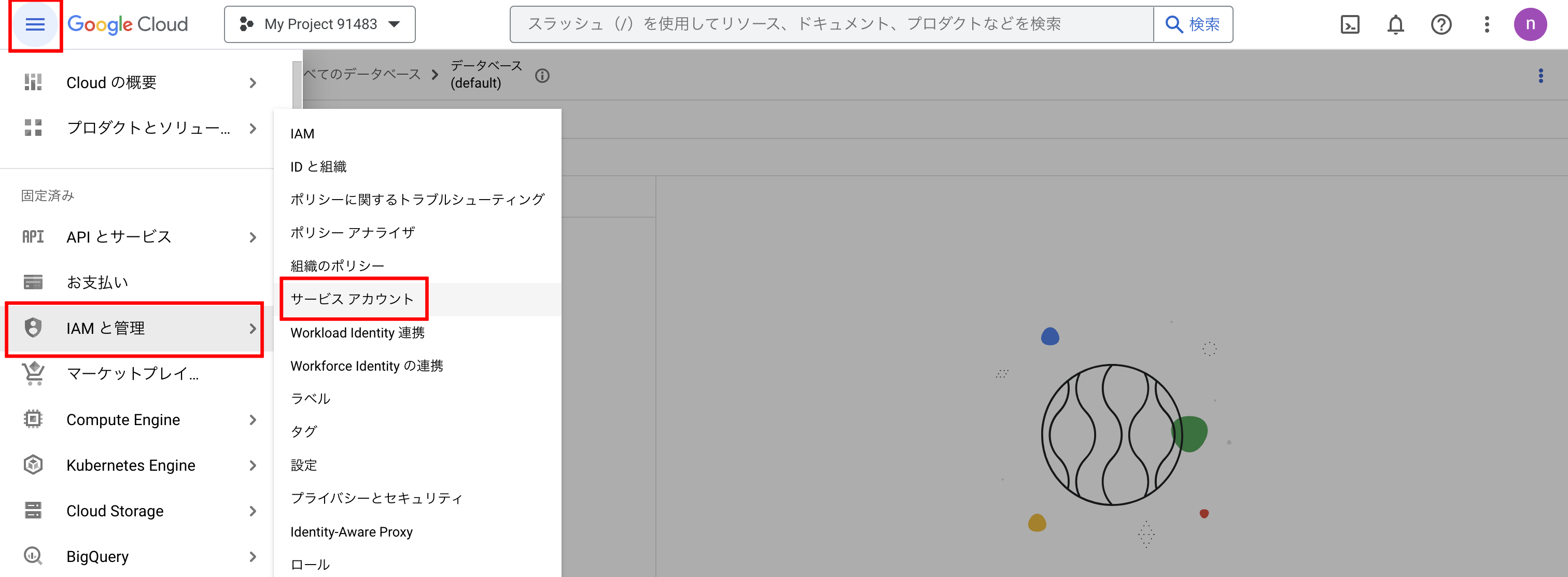
画面上部の「サービスアカウントを作成」をクリックします。
項目1でサービスアカウントの名前を設定し、項目2で下の二つのロールを付与します。項目3には何も書かずに「完了」を押します。
- 必要なロール
- Firebase ルールシステム
- Firestoreサービスエージェント
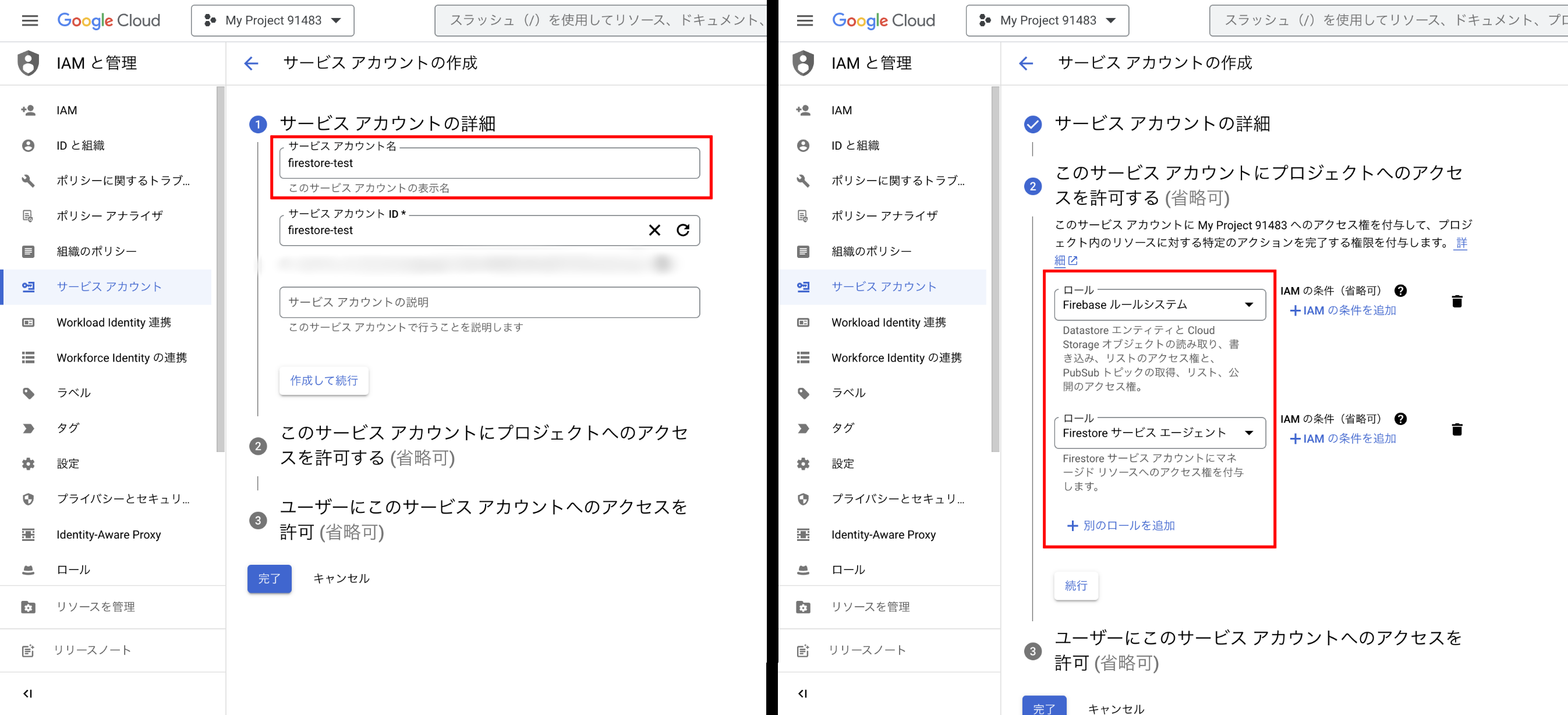
すでにサービスアカウントを作成していた場合は、このページからロールの変更はできません。「IAM」から「アクセス権を付与」を選び、「プリンシパル」にサービスアカウント([サービスアカウントID]@[プロジェクトID].iam.gserviceaccount.com)を指定してロールを付与します。
7. サービスアカウントの鍵を生成
作成したアカウントがあるはずなので、青くなっている「[サービスアカウントID]@[プロジェクトID].iam.gserviceaccount.com」をクリックします。
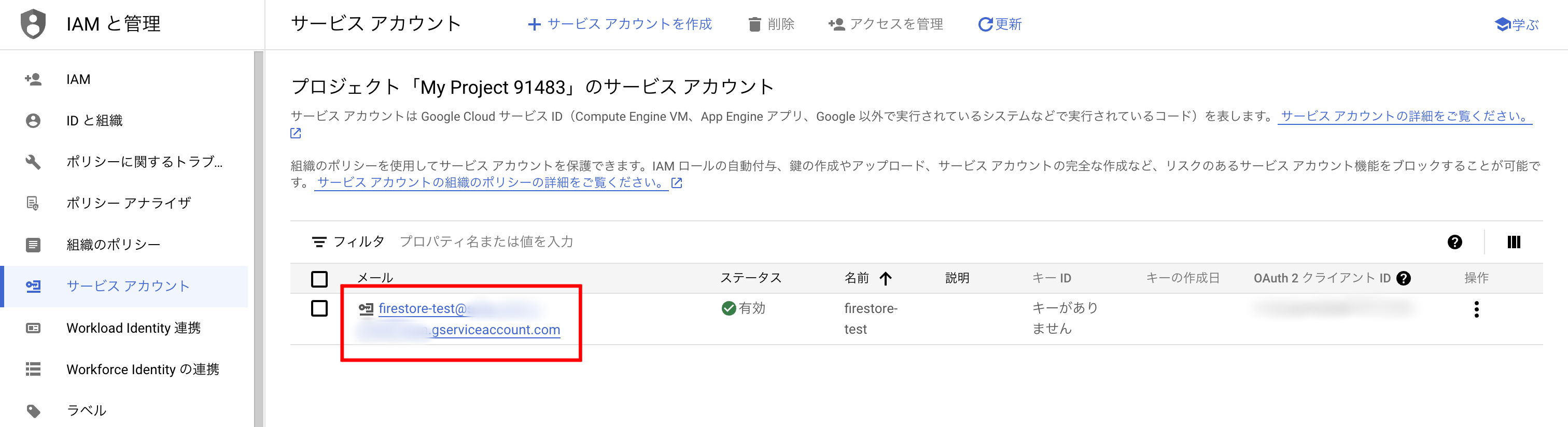
次に上部のタブから「キー」を選択し、「鍵を追加」→「新しい鍵を作成」をクリックします。

JSONにチェックされていることを確認し、「作成」をクリックします。すると、JSONファイルがダウンロードされます。
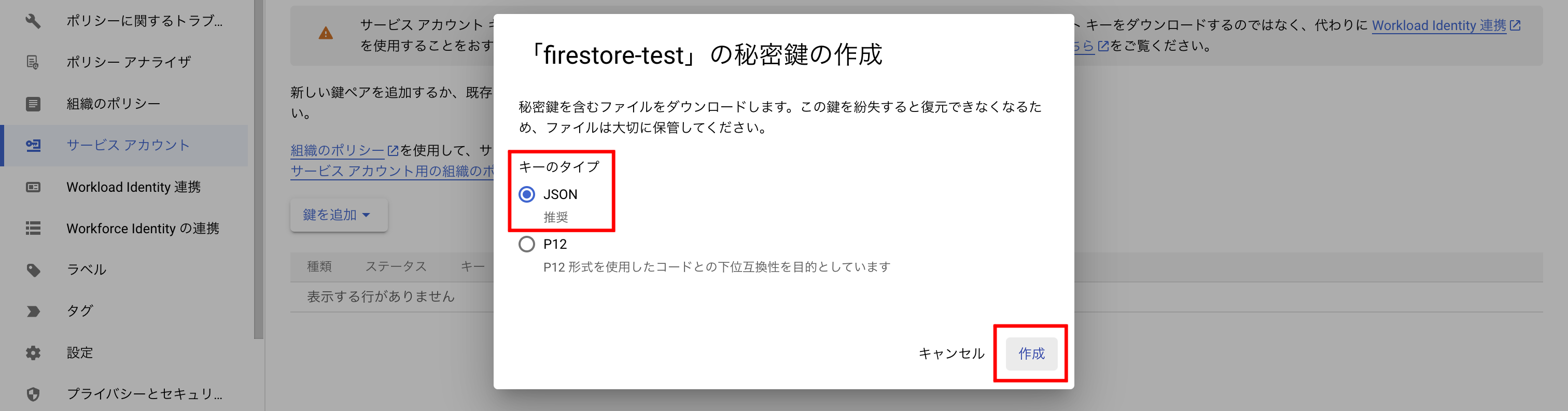
このJSONファイルを使えば、誰でもこのプロジェクトにアクセスできてしまうので、外部に漏らさないでください。
8. Pythonプログラムを準備
以降は、それぞれ慣れている環境があると思うので、環境に合わせて作業を行います。基本的には「google-cloud-firestore」を追加して、下記の「main.py」を実行するだけです。公式ドキュメントを参照すれば、他言語でのサンプルコードも見られます。
ここでは、macOSのターミナル上で完結する手順を紹介します。
(以下では、Python3.9.6を使用しています)
1. ターミナルを起動して、任意の場所に作業フォルダを作成して移動する
cd [任意の場所]
mkdir [好きなフォルダ名]
cd [上のフォルダ名]
2. Pythonファイルを作成してプログラムを書く
touch main.py
vi main.py
viはiを押してから入力モードになります。下のコードをコピペして貼り付け、エスケープキーを押下、:wqで保存します。JSONファイルのパスは、それぞれの環境に合わせて書き換えましょう。
from google.cloud import firestore
def upload_to_firestore():
# JSONファイルのパス
key_gcf = "[ダウンロードしたJSONファイルへのパス]"
# JSONファイルを用いて Firestore に接続
db = firestore.Client.from_service_account_json(key_gcf)
# 保存したいデータを辞書型で用意
data = {"name": "サーモン", "ProductionArea": "ノルウェー", "price": 350}
# データを保存
db.collection("sushi").document("salmon").set(data)
if __name__ == '__main__':
upload_to_firestore()
Firestoreはデータベースの中に複数のコレクションを保持し、コレクション内に複数のドキュメントを保持しているという構造になっています。そのため、データベースにアクセスした後は、コレクション名とドキュメント名を指定して保存します。今回の場合は、sushiというコレクションにsalmonというドキュメント名を指定しています。保存するデータは変数dataに格納された辞書型のデータです。
このとき、同じコレクションやドキュメントがなければ、それぞれ自動で作成されます。しかし、ドキュメントに関して、名前が一致したものがあった場合はデータが上書きされ、元のデータは消えます。
3. Pythonの仮想環境を作成して入る
python3 -m venv venv
source venv/bin/activate
4. 環境に「google-cloud-firestore」をインストール
pip install --upgrade google-cloud-firestore
5. 実行
python3 main.py
ここまで問題なく作業することができた場合、Google Cloud Firestoreにデータを保存できているはずです。ブラウザ上でFirestoreのページにアクセスし、データが保存されているか確認しましょう。

データの操作
これまででデータベースに接続して、データのやり取りができるようになりました。以降では、簡単な操作について記載します。
前提
文字コードはUTF-8を使用します。
Firestoreのデータベース
基本的に、これを用いてデータの操作を行います。
db = firestore.Client.from_service_account_json([JSONファイルのパス str])
コレクション
複数のドキュメントをまとめておく単位です。名前にはデータベースに存在するものでも、存在しないものでも指定できます。
coll_ref = db.collection([コレクション名 str])
ドキュメント
コレクション内に保存されるドキュメントです。コレクションと同様に、名前は任意で決められます。
doc_ref = db.collection([コレクション名 str]).document([ドキュメント名 str])
# こちらでも良い
doc_ref = coll_ref.document([ドキュメント名 str])
C (Create)
データを追加する関数は、set()とadd()が用意されています。
関数:set()
ドキュメントを新しく作成して、データを保存します。このとき、すでに同じ名前のドキュメントがあった場合、上書きされるため、元のデータは消えます。コレクションも、無かった場合は自動で作成されます。
doc_ref.set([任意のデータ 辞書型])
# こちらでも良い
db.collection([コレクション名 str]).document([ドキュメント名 str]).set([任意のデータ 辞書型])
coll_ref.document([ドキュメント名 str]).set([任意のデータ 辞書型])
関数:add()
ドキュメントを新しく作成して、データを保存します。set()とは異なり、コレクションに対して起動します。ドキュメント名には、ランダムな文字列が生成されて与えられます。戻り値は、タイムスタンプと追加したデータのドキュメントです。
time, doc_ref = coll_ref.add([任意のデータ 辞書型])
# こちらでも良い
time, doc_ref = db.collection([コレクション名 str]).add([任意のデータ 辞書型])
R (Read)
関数:get(), stream()
関数はget()とstream()が用意されています。私が見た限りだと挙動は同じで、公式ドキュメントではstream()の使用が推奨されています。
# ドキュメントに対して実行すると、得られるのはDocumentSnapshot型
doc = db.collection([コレクション名 str]).document([ドキュメント名 str]).get()
if doc.exists:
# あった場合の処理
got_dict = doc.to_dict() # 辞書型へ変換
print(got_dict)
else:
# なかった場合の処理
# コレクションに対して実行することで、全てのデータを取得できる(リストで得られる)
docs = db.collection([コレクション名 str]).get()
for doc in docs:
got_dict = doc.to_dict() # 辞書型へ変換
print(got_dict)
関数:where()
コレクションに対して、where()を使用して検索することができます。
docs = db.collection([コレクション名 str]).where(
filter=firestore.FieldFilter([フィールド名 str], [比較演算子 str], [比較したい値])
).get()
for doc in docs:
got_dict = doc.to_dict() # 辞書型へ変換
print(got_dict)
関数:order_by()
コレクションに対して、order_by()を使用して並び替えができます。where()を適用する場合、where()の後に適用します。この場合、最初にwhere()でフィルターをかけた値で並び替える必要があります。また、order_by()は.order_by("xxx").order_by("ooo")のように複数回適用できます。
docs = db.collection([コレクション名 str]).where(
filter=firestore.FieldFilter([フィールド名 str], [比較演算子 str], [比較したい値])
).order_by([whereと同じフィールド名 str]).stream()
for doc in docs:
got_dict = doc.to_dict() # 辞書型へ変換
print(got_dict)
関数:limit(), limit_to_last()
最後に、limit()を指定して取得するデータの個数を指定できます。後ろから取る場合はlimit_to_last()を用います。
# order_by()で、逆順に並び替える場合は direction=firestore.Query.DESCENDING を引数に指定
docs = db.collection([コレクション名 str]).where(
filter=firestore.FieldFilter([フィールド名 str], [比較演算子 str], [比較したい値])
).order_by(
[whereと同じフィールド名 str], direction=firestore.Query.DESCENDING
).limit(3).stream()
# この場合、データは3つ取得される
for doc in docs:
got_dict = doc.to_dict() # 辞書型へ変換
print(got_dict)
U (Update)
関数:update()
ドキュメントに対してupdate()を使用できます。Firestore内のドキュメントにフィールドがある場合は上書きされ、無いデータは追加されます。元々あったデータは、上書きされない限り残ります。
db.collection([コレクション名 str]).document([ドキュメント名 str]).update([任意のデータ 辞書型])
特定のフィールドを削除したい場合は、値にfirestore.DELETE_FIELDを指定します。
doc = db.collection([コレクション名 str]).document([ドキュメント名 str]).update({
[削除したいフィールド名 str]: firestore.DELETE_FIELD
})
あるフィールドの値が辞書型である場合、ドット表記が行えます。
doc = db.collection([コレクション名 str]).document([ドキュメント名 str])
doc.update({[フィールド名].[データ内のフィールド名]: [任意のデータ]})
# 例えば、下記のようなデータには{"Japan.Tokyo": "sushi"}として変更が可能
# {"Japan": {
# "Tokyo": "mochi",
# "Hukuoka": "ramen",
# "Yokohama": "Shumai"
# }}
フィールド内の配列を変更する場合は、要素を指定して追加と削除ができる。ただし、同じデータがある場合は追加されない。
doc = db.collection([コレクション名 str]).document([ドキュメント名 str])
# データを追加する(同じデータがすでにある場合は追加されない)
doc.update({[フィールド名 str]: firestore.ArrayUnion([任意のデータ])})
# データを削除する
doc.update({[フィールド名 str]: firestore.ArrayRemove([任意のデータ])})
D (Delete)
ドキュメント名を指定して消去することができます。
db.collection([コレクション名 str]).document([ドキュメント名 str]).delete()
おわりに
以上、ほぼ全てを公式ドキュメントを参照して記載しました。上記以上を知りたい場合は、公式ドキュメントからどうぞ。結局、公式ドキュメントが一番わかりやすいです。