前回の「基礎編 3: 遅いトランザクションのパフォーマンス調査方法」では、メインのトランザクションを軸にボトルネックを調査する一般的な方法を紹介しました。
今回はそれ以外を軸にした場合やサービス連携時のパフォーマンス調査など、より幅広い視点でパフォーマンス調査を行う方法を紹介します。
外部サービスが遅いか知りたい場合の調査方法
モダンなサービスであれば1つのモノリシックなアプリっていうのはほぼないでしょう。自社内であれ、サードパーティであれ何かしらの外部サービスを呼出しいることでしょう。New Relic の調査によると、外部サービスが呼び出しがパフォーマンスのボトルネックになるケースは 18% くらいあるそうです。
パフォーマンス上の問題があった場合に、それが自分たちのアプリ内の問題なのか、外部サービスの問題をなのかをいち早く切り分けることが効率良く障害分析する重要な要素となります。頑張って深掘りしていって、ようやく原因が分かったと思ったらそれが外部サービスだったらどうしようもないですよね。
New Relic には、外部サービスのパフォーマンスを知る手段がいくつかあります。
External services で現在呼出しているサービス一覧を確認
現在のタイムピッカーで選択している期間に呼出された全外部サービス呼出しの一覧を確認したい場合は、左メニューの「External services」をクリックします。すると、以下のようにドメイン単位で API 一覧が表示されます。ドメインをクリックすると、そのドメインで呼ばれた API が表示されます。

このページを見れば、どの API が呼ばれており、どれくらいのパフォーマンスなのか一目で分かります。そのため、Overview ページなどで外部サービスに時間が掛かっている見たいだなーと思ったら、ここを見れば具体的にどの API コールが問題なのかが簡単に分かります。
また、New Relic では、同じ New Relic アカウントで複数のアプリを管理していおり、それらが呼出し関係にある場合、呼び出されているアプリから呼出し先のアプリへシームレスに移動できる機能がいくつかあります。自分たちが管理している別アプリが原因で遅そーだなーと思って、わざわざ、APM のメニューからそのアプリに遷移して、トランザクションを選択するなどの必要がないような UI となっています。
この外部サービス呼出しにもその機能があります。
選択したサービスが同じ New Relic アカウントで管理しているサービスの場合、外部サービスのトランザクション部分がリンクになります。クリックすると、呼出し先プリに遷移し、そのトランザクションが表示されます。これにより、シームレスにパフォーマンス調査が行えます。

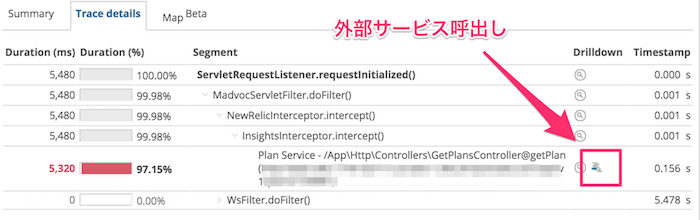
トレースディテールで確認
前回紹介したトレースディテールでは、上記で説明したように、同じアカウント内で管理しているサービスを呼出している処理には、以下のように専用のアイコンが表示されます。これをクリックすることで、呼出し先のアプリのトランザクション画面にシームレスに移動でき、ストレスなく、パフォーマンス調査を続行できます。
サービスマップで自社管理内のアプリのパフォーマンスを一目で把握
同じ New Relic アカウントで管理しているサービスという言葉を使って説明してきました。上記では、ある外部サービスやトランザクションが呼出しているアプリへの移動が簡単にできると言ってきましたが、そもそも各アプリの呼出し関係などのサービス全体としてのアーキテクチャがどうなっているか知りたいですよね。それを一目で見れるのがサービスマップです。
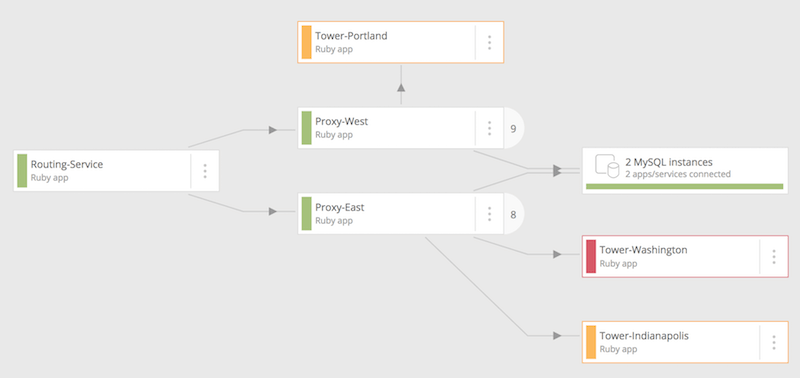
どのサービスがどのサービスを呼出しているかが、簡単に分かります。また、各サービスの先頭の色は、健康状態を示しています。緑:正常、黄:警告、赤:致命的な状態です。これは、アラートと結びついています。
自分のチームで管理しているアプリでアラートが発生したときに、その原因が自分たちのアプリなのか、呼出し先のアプリの問題なのか、このマップをみれば、切り分けがしやすいです。呼出し先にでアラートが出ていないようであれば、自分たちのアプリだと察しが着きますし、逆なら、呼出し先の可能性が出てきます。
また、サービス名をクリックすると、以下のように直近30分のパフォーマンスが表示されます。わざわざ各アプリの画面に遷移してパフォーマンスを確認しなくても、ここだけで各サービスのパフォーマンスを表示、比較ができます。

サービスマップを表示する方法
サービスマップは、トップメニューの下のサブメニューの真中の "Service maps" をクリックするか、左メニューの上から2番目の "Service maps" をクリックすると、表示されます。
サービスマップは基本、自動的に呼出し関係を把握し、チャートを作ってくれます。
DB処理のパフォーマンスを確認したいなら、Databases ページへ
次に、DB処理を軸にパフォーマンスを確認したい場合は、Databases ページを利用します。左メニューの上から4番目の "Databases" をクリックします。
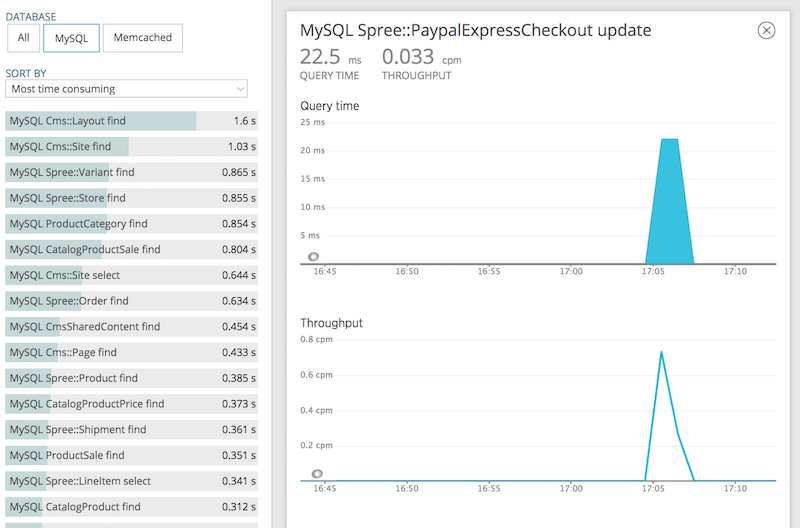
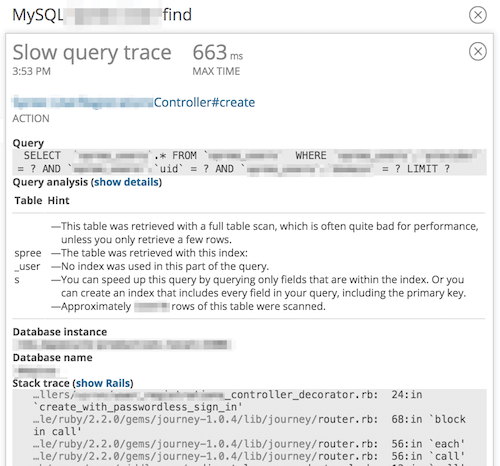
ここではタイムピッカーで選択している時間帯に呼び出されたDB処理を並べて表示します。ここで、どの処理が遅いかが簡単にわかりますし、処理が遅い場合は、SQL やスタックトレースなども表示されます。(前回のトレースディテールでみた内容と同じ)
言語処理系のパフォーマンスを確認したなら、VM ページを
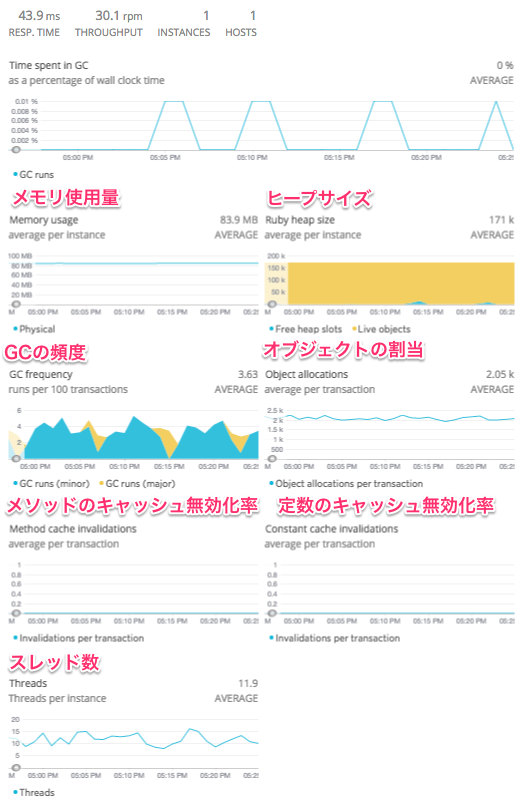
Overview ページで、言語処理系のパフォーマンスが低下している場合に、その原因の調査に役立つ情報(GCやヒープサイズ)を提供してくれるページがあります。
注: これは言語によって提供している場合としていない場合があります。現在提供しているのは、Ruby, Java, Node.js のみっぽい。利用できる場合は、左メニューの "MONITORING" の一番下に、"xx VMs" というメニューが表示されます。

Ruby VM の場合
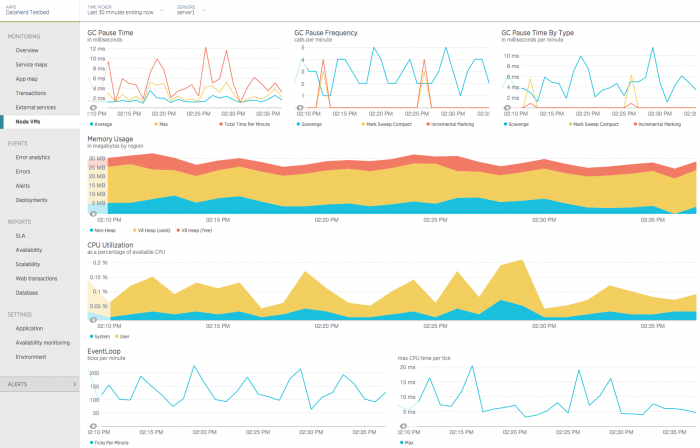
Node.js VM の場合
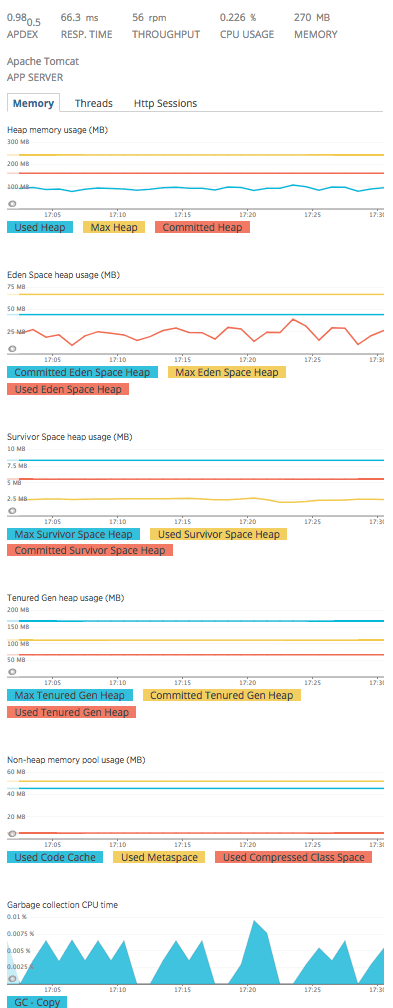
JVM の場合
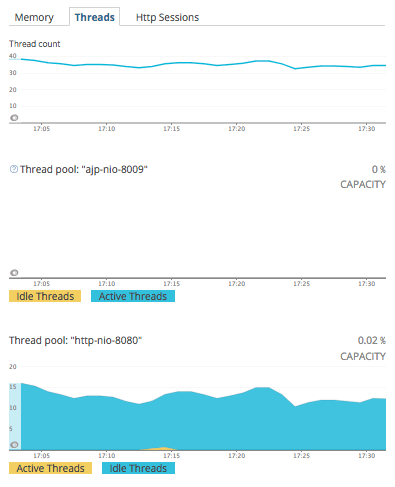
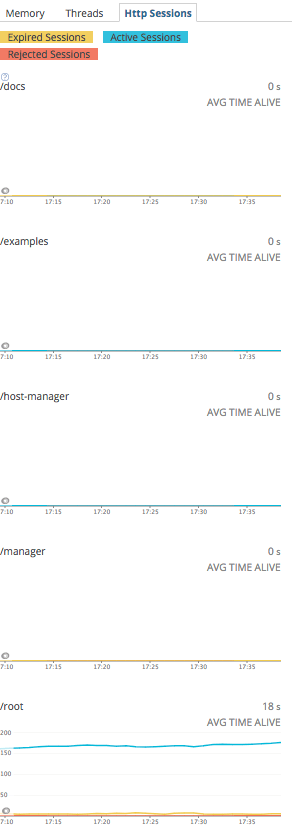
JVM の場合は、見ての通り、メモリ、スレッド、HTTP セッションとタブが分かれている。
メモリタブ
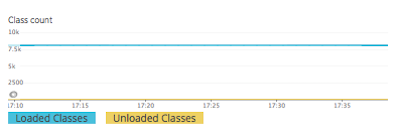
スレッドタブ
HTTP セッションタブ
詳しくはドキュメントをご覧ください。
パフォーマンス低下の原因がサーバーかアプリか知りたいならヘルスマップ
APM のアラートが発生した場合に、それがアプリではなく、サーバーリソースが枯渇したことにより、アプリのパフォーマンスが低下しているということがままあります。問題が発生した際に、それがアプリなのかサーバーなのか判断する必要があります。その判断に役立つのが、New Relic APM と New Relic Infrastructure の連携機能である**ヘルスマップ**です。
この機能は、New Relic のサーバー監視製品である New Relic Infrastructure と連携機能なので、もちろん、New Relic Infrastructure を導入していないと使えない機能となっています。Infrastructure については次回軽く説明します。
ホストを軸にアプリとの関係や健康状態をチェック
ヘルスマップでは、その名の通り、アプリとサーバー(ホスト)の健康状態を示してくれるものです。以下は、ホストを軸(ホスト単位で、箱が表示)にそのホストの健康状態やパフォーマンス情報と、そのホストで稼働しているアプリの健康状態を表示しています。
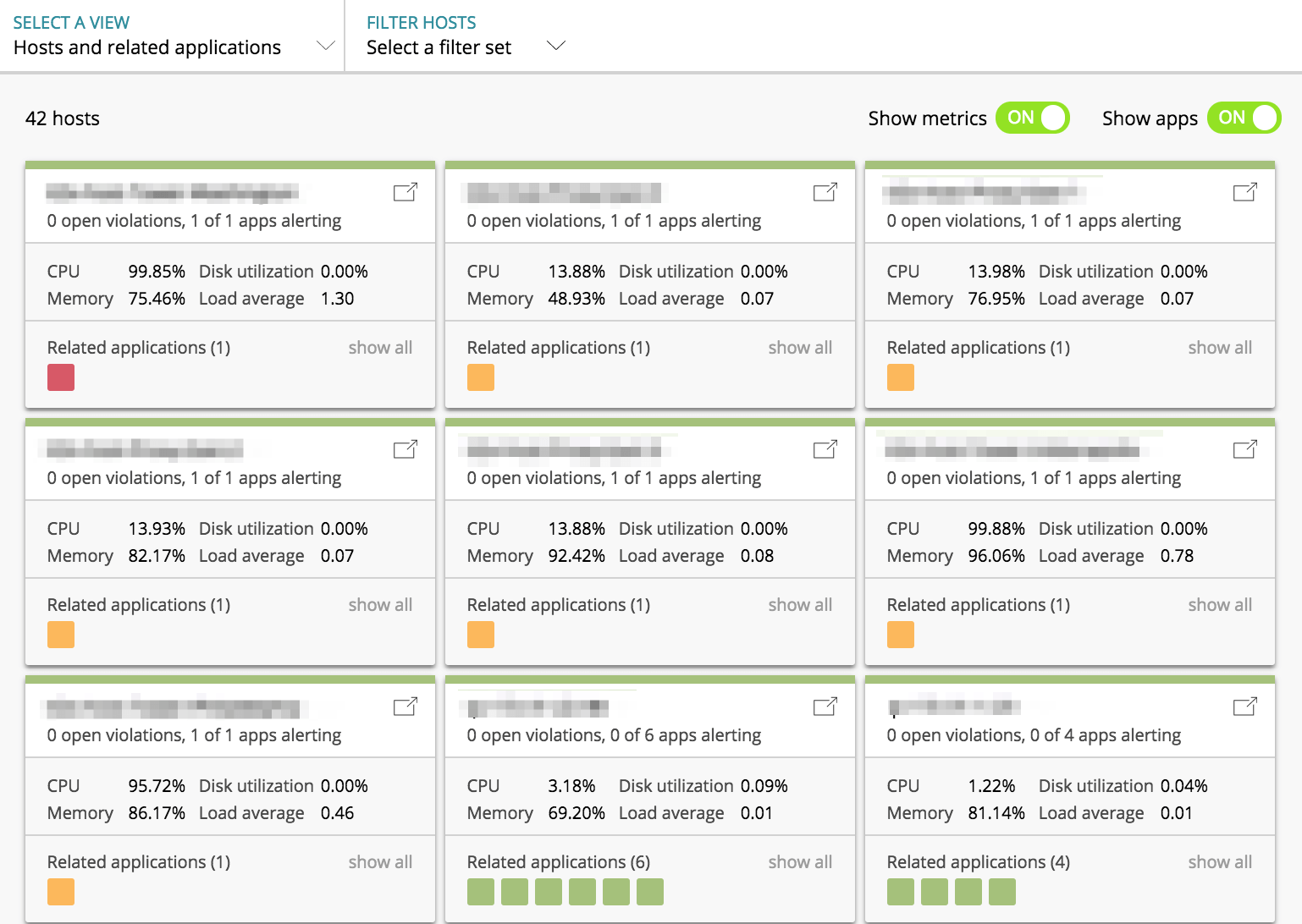
例えば、一番左上のホストの "Related applications" には、1つだけ赤いボックスがあります。これは、このホストで稼働しているアプリが1つで、そのアプリに致命的なインシデントが発生していることを示しています。逆にいうと、アプリにアラートが出ているが、このホスト自体は緑(ボックスの上の線が緑)なので、サーバーリソースの問題ではないことが分かります。
アプリを軸にホストとの関係や健康状態をチェック
以下は、逆に、アプリを軸にしたマップです。アプリ単位でボックスがあり、そのアプリで利用しているホストの健康状態を知ることができます。この切替は、画面右上の "Select A VIEW" から行えます。
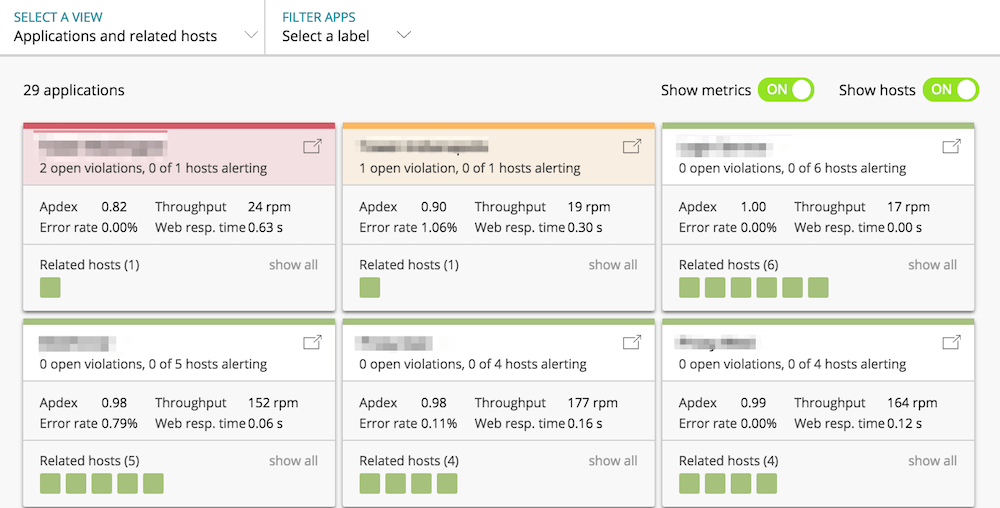
基本的に左上のボックスから右下に掛けて注目すべき順番に並んでいます。
このように New Relic の製品を組み合わせることで、簡単にアプリとサーバーとの関係性や問題の切り分けもスムーズに行えるようになります。
アクセス方法
画面トップの右の方の "Maps" というメニューをクリックすると表示されます。(デフォルトで、"Health map"がアクティブに鳴っています)
まとめ
今回は、外部サービス、DB、言語処理系、サーバーと4つのレイヤーを軸にパフォーマンス低下の原因を調査するのに役立つ情報を紹介しました。次回は、今回ちょっと紹介したサーバー監視である New Relic Infrastrucutre について簡単に紹介します。