リカバリ
DB上のページは「Atomicな複数更新」かつ「コミット時に全ページをForce」かつ「No-Steal」という、設計上の非常に遅い選択肢を選ばない限り、プロセス・OS・電源の障害からの復旧は基本的に一貫性が無い状態がスタート時点になる前提が必要である。
一貫性のないDBのページを復旧するためにログを残しており、一貫性のないページとログからDBの一貫性を取り戻す作業をリカバリと呼ぶ。
どのようなリカバリが必要とされるかはDB側のページ一貫性設計に大きく依存する。
基本的な戦略としては、DBのACID特性を維持するために「すべてのトランザクションをALL or Nothingに倒す」「ユーザに完了を報告した可能性のあるトランザクションはすべてALL側へ倒す」というのが前提となる。(CやIに関してはログを生成した時点で解決していると言える)
前述したようにStealのあるDBでは未コミットなページ更新がディスクに反映されてしまっている可能性もある(Atomicity違反)。またForceのないDBではコミット済みのデータがディスクに反映されていない可能性もある(Durability違反)。StealかつNo-ForceなDBでは1つのページの中にRedoすべき更新とUndoすべき更新が両方載っている可能性すらあるので、ログに書かれている順番通りにRedoとUndoを適切に行う必要がある。
その適切なプロトコルはそれぞれの場合でもあまり自明ではなく、様々な要素と複雑に絡み合っている。このアドベントカレンダーでは一番有名なARIESでのリカバリの実装について後日説明する。
チェックポイント
さて、No-Force戦略で動くデータベースは基本的にLRUなどでのページ置換アルゴリズムに従ってメモリに置くページを決める。
それを愚直に実装してしまった場合、大きな問題に悩まされる事になる。
例えば、1年走り続けているDBシステムがあって、特定の1ページが一度もLRU的に不要と見做されなかった場合、つまりhotなページとしてメモリの中に生き続けてしまう。
するとディスクに正しくRedo用のログが書き込まれていたとしても、そのDBの電源断からの再起動時にはそのページに関しては1年分の更新をすべて再度行わないと最新のコミットされたデータまで追いつかない。1年分の処理のリプレイは並々ならぬ時間が掛かる事だろう。
そこで考案されたのがチェックポイントである。この技法は定期的にメモリ内のページをディスクへと強制的に書き戻す事によって、再起動時のコストを小出しに支払う。
注意して欲しいのが、チェックポイントとは飽くまで再起動時のリカバリ時間を短縮するための高速化であって、原理上それは存在しなくてもDBの中身はログから復旧可能である。たまに「チェックポイントをとっているからDBはリカバリができる」と話す人もいるが、時間が掛かるだけでログさえあれば復旧は原理的に可能である。
チェックポイントの取り方も数多くの研究がなされているが、古典的なタイプのものは前回の記事でも引用した Principles of Transaction-Oriented Database Recoveryの中でまとまっている。
- Transaction Oriented Checkpoints(TOC): 純粋に毎回Forceする戦略。言うまでもなくパフォーマンスに悪影響が大きい。
- Transaction Consistent Checkpoints(TCC): 定期的に出されるチェックポイントシグナルを受け取ったらメモリ内のページを全てディスクに書き出すまで新規トランザクションの開始を抑制する戦略。一貫性のあるディスク内ページが定期的に得られるものの、チェックポイント中は新しいトランザクションを受け付けられない。
- Action Consistent Checkpoints(ACC): チェックポイントシグナルを受け取ったらその瞬間のメモリ内のページを全てディスクに書き出す戦略。当然ダーティなページも全て書き込まれるのでリカバリ時のコストは高いが上の2つと比べればチェックポイント時のコストは遥かに少ない。
- fuzzy: その他いろいろな亜種が提案されており、ダーティなページの一覧(Dirty Page Table)と走っているトランザクションの一覧(Transaction Table)のみをディスクに書き、メモリ内のページをディスクに書き出す操作を伴わない物。冒頭で書いた超長いRedoなどの問題は解決しないが、Redo時にどのページを洗えば良いか明白になるのでリカバリ動作が高速になるというメリットがある。最近のfuzzy checkpointと見比べて両方に含まれるhotなページがあったらそれを選択的にディスクに書き出すなど、適応的な方法もある。
上記の事を踏まえて改めてPrinciples of Transaction-Oriented Database Recoveryの図を見てみると面白い。
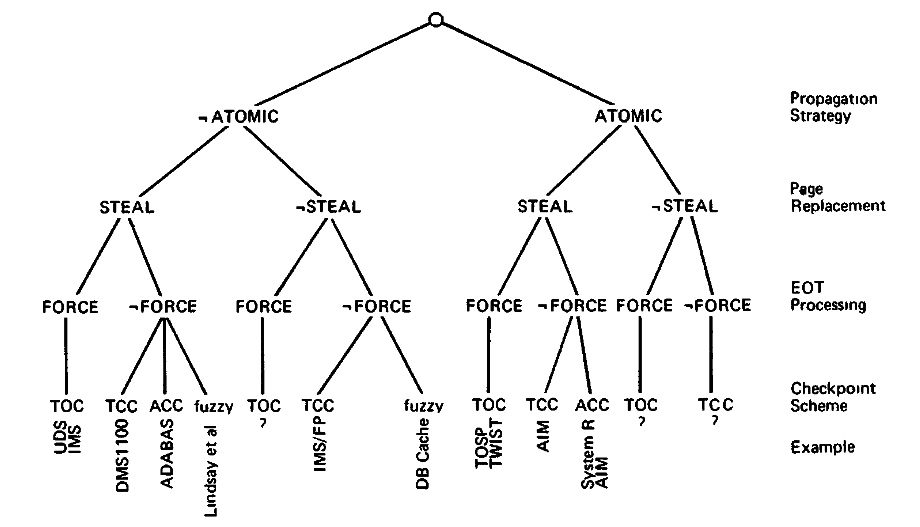
- ¬FORCEなシステムでしかTOC以外のチェックポイント選択肢はない。むしろFORCEしないとTOCは選べない
- ¬ATOMICなシステムでしかfuzzyなチェックポイントは使われない、なぜなら複数ページの書き込みが常に一貫性を守るのならdirtyなページを管理するメリットが少ないから。
実施例は複雑にからみ合っており、それぞれの中で無数に細かい実装上の選択がある。
それら全てについて語る時間も知識も無いので、この日記では。一番有名な金字塔ARIESに絞って説明を行う。