はじめに
こんにちは、クマ松です。
ある日の朝に同僚から、彼が所属するプロジェクトで発生した障害に関して、こんな相談を受けました。
障害の内容
===========ここから============
AWSアカウントAのAWS DMSから
AWSアカウントBのAurora.Mysqlクラスターのデータを取得できなくなった。
取得できなくなったタイミングは、深夜作業中にMySQLをr5.12xlargeからr5.8xlargeへ変更したあとくらいから。
AWS DMSのあるVPCとAuroraのVPCはVPCピアリングで接続されており、ネットワーク構成は変更していない。
エラー文言はこんな感じ。
AWS DMSのタスクを何度再開してもダメ。
Test Endpoint failed: Application-Status: 1020912, Application-Message: Cannot connect to ODBC provider ODBC general error., Application-Detailed-Message: RetCode: SQL_ERROR SqlState: HY000 NativeError: 2003 Message: [unixODBC][MySQL][ODBC 8.0(w) Driver]Can't connect to MySQL server on 'xxxxx.ap-northeast-1.rds.amazonaws.com' (110)
===========ここまで============
いかがでしょう。原因分かりますか?
取得できなくなったタイミングは、MySQLをr5.12xlargeからr5.8xlargeへ変更したあとくらいから
当初は、パラメータグループの設定値が悪さをしているのかと思いました。
インスタンスタイプのサイズを小さくしたことが直接的な原因のように思えたので、パラメータとして設定可能な値が変わってしまったのではないかと考え、そういう事象が発生した例が無いかエラー文言を頼りに調査しました。
Can't connect to MySQL server on 'xxxxx.ap-northeast-1.rds.amazonaws.com'
しかしこのエラーについてどんなに調べても、「Security Group、ACLの設定を見直せ」と指南するブログしか出てきません。
信じられないけどネットワークの問題なんだろうと思って調査をし直しました。
結論
直接の原因は単純で、DMSの参照先であるPrimaryインスタンスが配置されたサブネットのルートテーブルに、DMSインスタンスからのルートが許可されていなかったからでした。
インスタンスのサイズを変える前までは接続できていたのに、何故急に接続できなくなったのでしょう?
Auroraの可用性
Amazon Auroraには自動フェイルオーバーという機能があります。
Primaryインスタンスに障害が発生すると、Aurora ReplicaがPrimaryインスタンスに昇格します。
自動フェイルオーバーが発生してもDMSのアクセス先になるエンドポイントは変わりません。
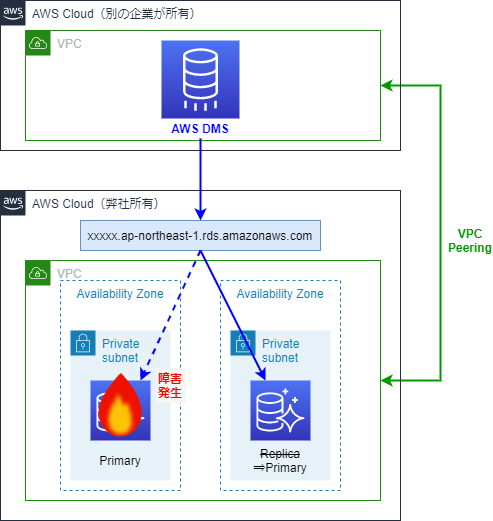
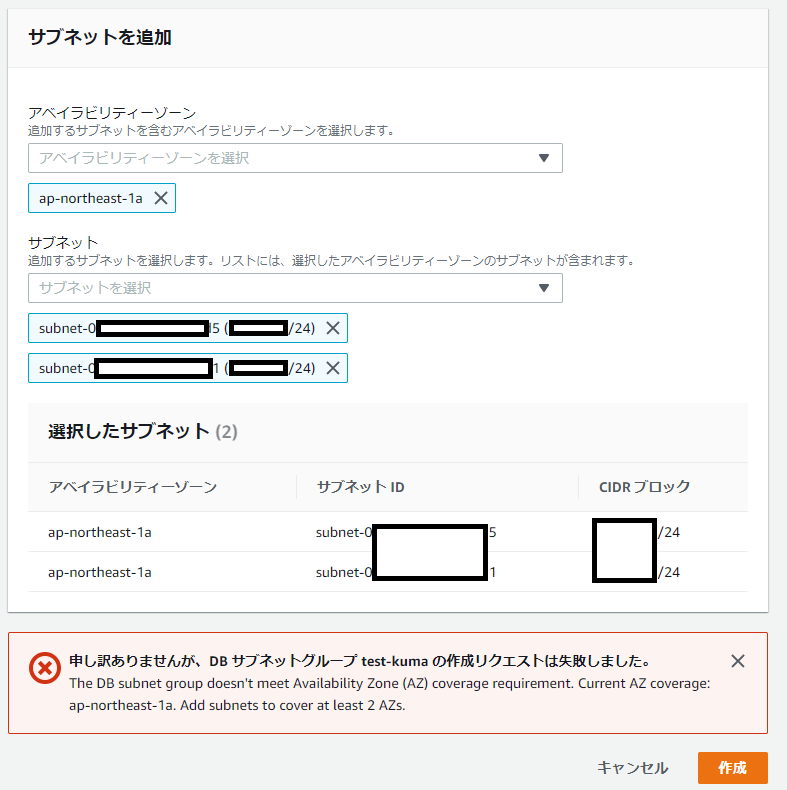
そしてAuroraでは、DBサブネットグループを作成することで、PrimaryやReplicaなどのインスタンスが作成されるサブネットを指定することができます。
このDBサブネットグループには2つ以上のサブネットを指定する必要があり、かつ1つのアベイラビリティゾーン内のサブネットのみで構成することはできません。

何が起こったか
DMSが継続的レプリケーションを実施するためにはPrimaryに接続する必要があります。
参考:How do I troubleshoot binary logging errors that I received when using AWS DMS with Aurora MySQL as the source?
インスタンスのサイズ変更をした際に、Auroraがフェイルオーバーをし、元々ReplicaだったインスタンスがPrimaryに変わってしまっていました。
そして結果的に、Primaryインスタンスが配置されたサブネットと、Replicaインスタンスが配置されたサブネットが変わってしまいました。
更に悪いことに、それぞれのサブネットのルートテーブルの設定値が異なっており、新Primaryインスタンス側のサブネットのルートテーブルに、DMSからのアクセスを可能にするルートが設定されていませんでした。
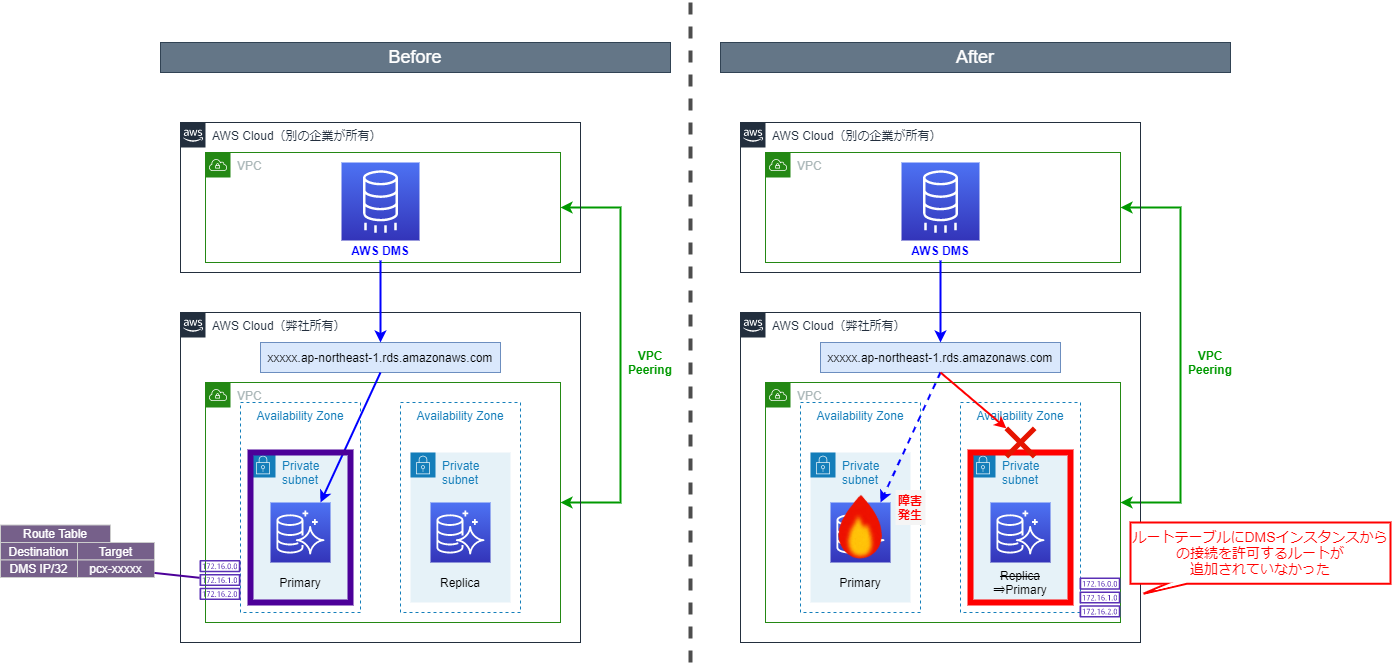
実はこのAWSアカウントは、昨年別ベンダーから弊社が譲り受けたものらしく、アカウント運用者がネットワーク設計の詳細を把握できていませんでした。(もちろん、「だからうちに責任はない」とは言いません)
譲り受けた後に、コスト最適化の観点でリソース過多になっているEC2やRDSが無いか調査をした結果、インスタンスのサイズ変更をすることになりました。
かつ深夜作業中の本番障害であり、この担当者は「ネットワークに関しては、既存の設定を何も変えていない」という焦りから、「ネットワークの問題ではないはずだ」という先入観を持ってしまっていました。
新Primaryインスタンスが配置されたサブネットのルートテーブルに必要なルートを追加したところ、無事DMSのタスクが動き始めました。
当初は自分が全く関わっていないプロジェクトの障害なんてヘルプできる気がしなかったのですが、原因に気づいたときパズルが解けたみたいで嬉しかったです。

ここから得られる教訓
- RDSはフェイルオーバーする前提で、サブネットのネットワーク設計をする
- AWS資格の為の勉強は、いざと言うときの知識の引き出しになる
- 調査に悩んだら、基本に立ち返る