2024年5月6日、現状のGoogle検索結果で動作するように更新しました。
ニュースタブ・動画タブ・画像タブで動作します。
Googleの検索結果を手軽に一覧でCSV保存したい
Google検索はとても便利なので、日常的に利用しているのですが、
検索結果をまとめて一覧化したいことがありますよね。
検索画面に表示されるサイト名やページタイトル、URLをCSVファイルとして一覧で取得できれば、
ExcelやNumbers、Calcなどで使えて便利です。
スクレイピングやAPIで取得するなどの方法もありますが、
画面に表示されている検索結果を取得したい用途があるので、
ブラウザから誰でも利用できる、ブックマークレットを作りました。
ただし、最新のブラウザでなければ動作しません。
使い方
ブラウザで新しいブックマークを作り、次の内容をURL欄に貼り付けます。
ブックマークの名前は、Google検索結果CSVダウンロードなどで良いでしょう。
Googleの検索結果画面で、登録したブックマークをクリックすると動作します。
javascript:((e,t,r,i,n,o,s,d)=>{const a=(t,r=e)=>r.querySelector(t),c=(t,r=e)=>r.querySelectorAll(t),l=(t,r=e.body)=>r.appendChild(t),v=t=>e.createElement(t),p=(e,...t)=>t.reduce((e,t)=>e.concat(t),e),u=e=>`"${e.map(e=>I(b(e)||"",[/"/g,/\n/g],['""',""])).join('","')}"`,f=e=>{let t=e;try{t=decodeURI(e)}catch(e){}return t},m=e=>e.filter(e=>!!e),b=e=>e&&"object"==typeof e&&s in e?e[s]:e||"",h=e=>e.join("\n"),g=async e=>{const r=await U(),i=e<=(O=R())[o];if(0===O[o]||i)return!1;if(r)return!0;const n=m([j(),w()]);return 0!==n[o]&&(await t.all(n),!0)},y=(e,t)=>Array.from(c(e)).map(t),j=()=>{const e=a("div[data-dt=1] > div[role=progressbar]");if(!e)return!1;const r=a("h1 + a",e.parentNode);return!!r&&(!/transform: ?scale\(0\)/.test(r.getAttribute("style"))&&new t(t=>{r.click();const i=new MutationObserver(r=>{for(const n of r)if("attributes"===n.type&&"style"===n.attributeName){const r=e.getAttribute("style");/display: ?none/.test(r)&&(i.disconnect(),t(!0))}});i.observe(e,{attributes:!0})}))},w=()=>{const r=a("#pnnext",N);if(!r)return!1;void 0===L&&(L=v("iframe"),k(L,{display:"none"}),l(L));const o=v("div");return k(o,{background:"black",color:"white",left:0,padding:"8px 20px",position:"fixed",top:0,zIndex:1e3}),o[s]="Loading...",l(o),new t(t=>{L[n]("load",()=>{N=L.contentWindow.document,o.remove();const r=v("div");r[i]=a("#rso",N)[i],c("div.ITCGwe",r).forEach(e=>e.parentNode.removeChild(e));const n=a("#rso");for(const e of r.children)l(e,n);N!==e&&(a("#botstuff")[i]=a("#botstuff",N)[i]),t(!0)},{once:!0}),L.src=r.href})},x=(e,t,r="")=>(e||"").replace(t,r),I=(e,t,r)=>t.reduce((e,t,i)=>x(e,t,r[i]),e),R=()=>m(p(y('#rso div.MjjYud > div.g, div[id^="arc-srp_"] div.MjjYud > div.g, #rso div.K7khPe, #rso div.RzdJxc, #rso div.m7jPZ',e=>{const t=a("div.yuRUbf a, div.RzdJxc a, div.m7jPZ > a.WlydOe",e);if(!t)return!1;const r=t.href;let i,n,s,d,c;if(e.classList.contains("RzdJxc"))i=a("[role=heading] span.cHaqb",e),n=a("span.Sg4azc > span",e),s=a("div.OwbDmd > span",e),d=a("div.V8fWH",e),c=a("cite",e),n=n&&x(b(n)," · ");else if(e.classList.contains("m7jPZ"))i=a("[role=heading]",t),s=a("div.OSrXXb > span",t),c=a("div.MgUUmf > span",t);else{if(i=a("h3",t),n=a("cite",t),s=a("div.VwiC3b > span.Sqrs4e span, div.IsZvec > div.fG8Fp",e),d=a("div.VwiC3b > span:not(.Sqrs4e):last-of-type, div.IsZvec > span.aCOpRe > span",e),c=a("span.VuuXrf",t),!s&&!a("cite span",t)){const e=b(n).split(" · ");try{n=e[0].trimEnd(),s=e[1].trimStart()}catch(e){}}if(!d){const t=a("div.VwiC3b",e).childNodes;d=t.item(t[o]-1).textContent}}return{href:r,decoded:f(r),title:i,breadcrumb:n,date:s,desc:d&&(s?x(b(d),b(s)).trimStart():b(d)),siteName:c}}),y("#rso > div.MjjYud [data-attrid~=images]",e=>{const t=a("a[target=_blank]",e);if(!t)return!1;const r=t.href,i=a("h3 img",e).src;return{href:r,decoded:f(r),title:a("div.toI8Rb",t),breadcrumb:i.startsWith("data:")?null:i,date:a("div.wr8GYd > span",e),description:a("div.toI8Rb",t),siteName:a("div.guK3rf > span",t)}}),y("#rso > div.MjjYud a.WlydOe",e=>{const t=e.href;return{href:t,decoded:f(t),title:a("[role=heading]",e),breadcrumb:null,date:a("div.OSrXXb > span",e),description:a("div.GI74Re",e),siteName:a("div.MgUUmf > span",e)}}),y("#rso > div.MjjYud > div > div.g",e=>{const t=a("div.xe8e1b a",e);if(!t)return!1;const r=t.href;return{href:r,decoded:f(r),title:a("h3",t),breadcrumb:a("cite",t),date:a("div.gqF9jc > span > span",e),description:a("div.ITZIwc",e),siteName:a("div.gqF9jc > span:nth-of-type(2)",e)}}))),U=()=>{const i=e.scrollingElement;return!(!i||i.scrollTop+i.clientHeight>=i.scrollHeight-50)&&new t(t=>{e.body.scrollIntoView({behavior:"smooth",block:"end"});const i=()=>{clearTimeout(o),o=r(()=>{e.removeEventListener("scroll",i),t(!0)},1e3)};let o;e[n]("scroll",i,{passive:!0}),i()})},k=(e,t)=>{for(let r in t)e.style[r]=t[r]};let L,N=e,O=[];(async()=>{const t=prompt("Enter maximum number of items as an integer","everything");if(!t)return;const i=parseInt(t);if(!(i<=0)){for(;await g(i););0!==O[o]?(alert(`Found: ${O[o]}`),void 0!==L&&L.remove(),(()=>{const t=new Blob([new Uint8Array([239,187,191]),h(p([u(d)],O.map(e=>u(Object.values(e)))))],{type:"text/csv"}),i=e.createElement("a"),n=URL.createObjectURL(t);i.download=e.title+".csv",i.href=n,i.click(),r(()=>URL.revokeObjectURL(n),1e3)})()):alert("No item found.\nIf you think this script works incorrectly contact the creator.\nThx in advance.")}})()})(document,Promise,setTimeout,"innerHTML","addEventListener","length","innerText",["href","decoded","title","breadcrumb","date","description","siteName"])
ページをブックマークしておき、編集画面を選んだ後、URL欄にペーストするのがコツです。
動作イメージ
Google Chromeのブックマークツールバーを表示させている場合のイメージです。
Google検索結果画面でブックマークをクリックすると、ブックマークレットが実行され、ダイアログが表示されます。
最初に、取得したい件数を入力してください。
例えば、100件のデータが欲しい場合は、 100 と入力します。
そうすると、おおよそ100件のデータが取得されて、CSVファイルがダウンロードされます。
すべての検索結果が欲しい場合は、表示されている初期値のまま確定してください。
もし、初期値 everything が表示されていない場合は、数字以外の文字を入力してください。
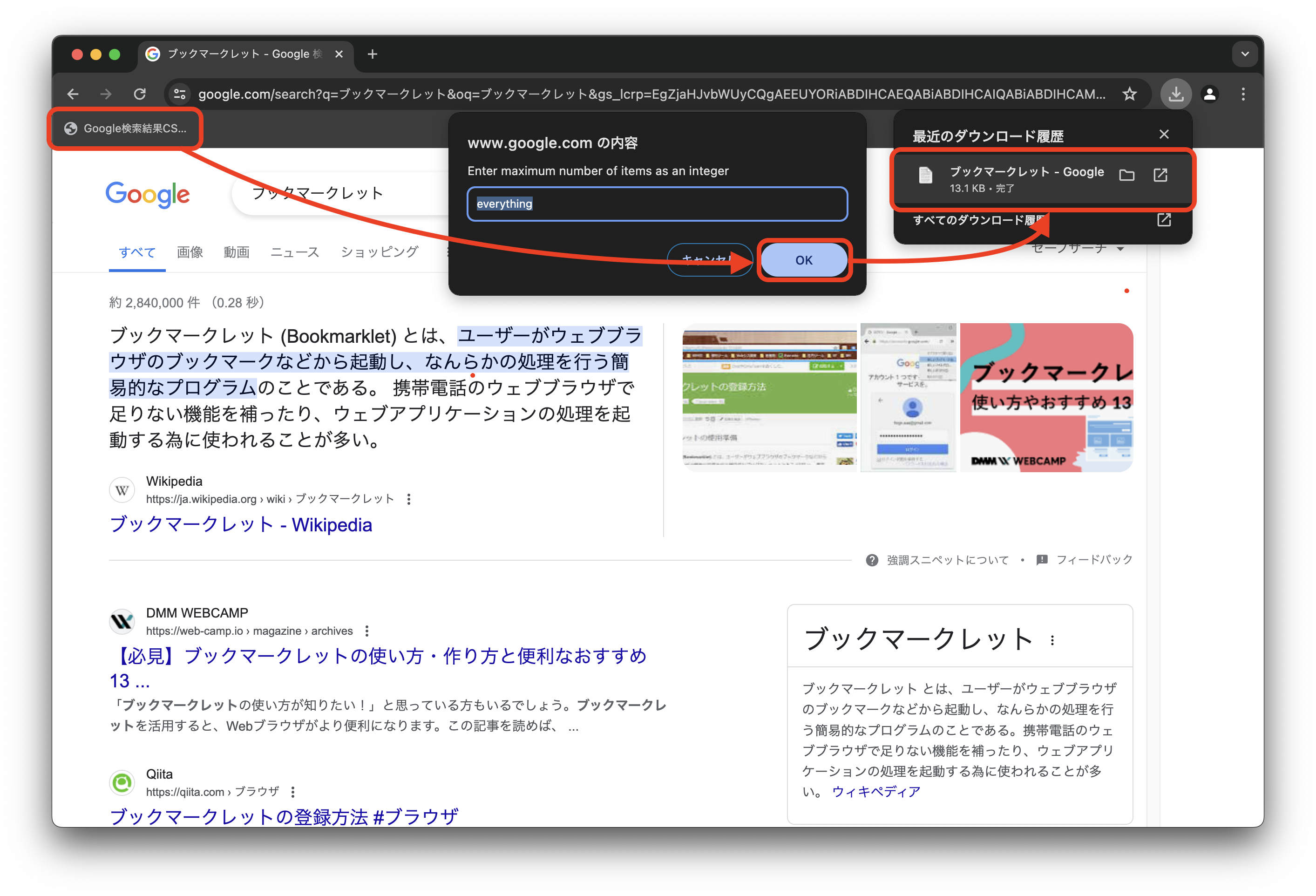
2024年5月最新版から、自動で次のページが読み込まれるようになりました。
ダウンロードしたCSVファイルはそのまま開けます。
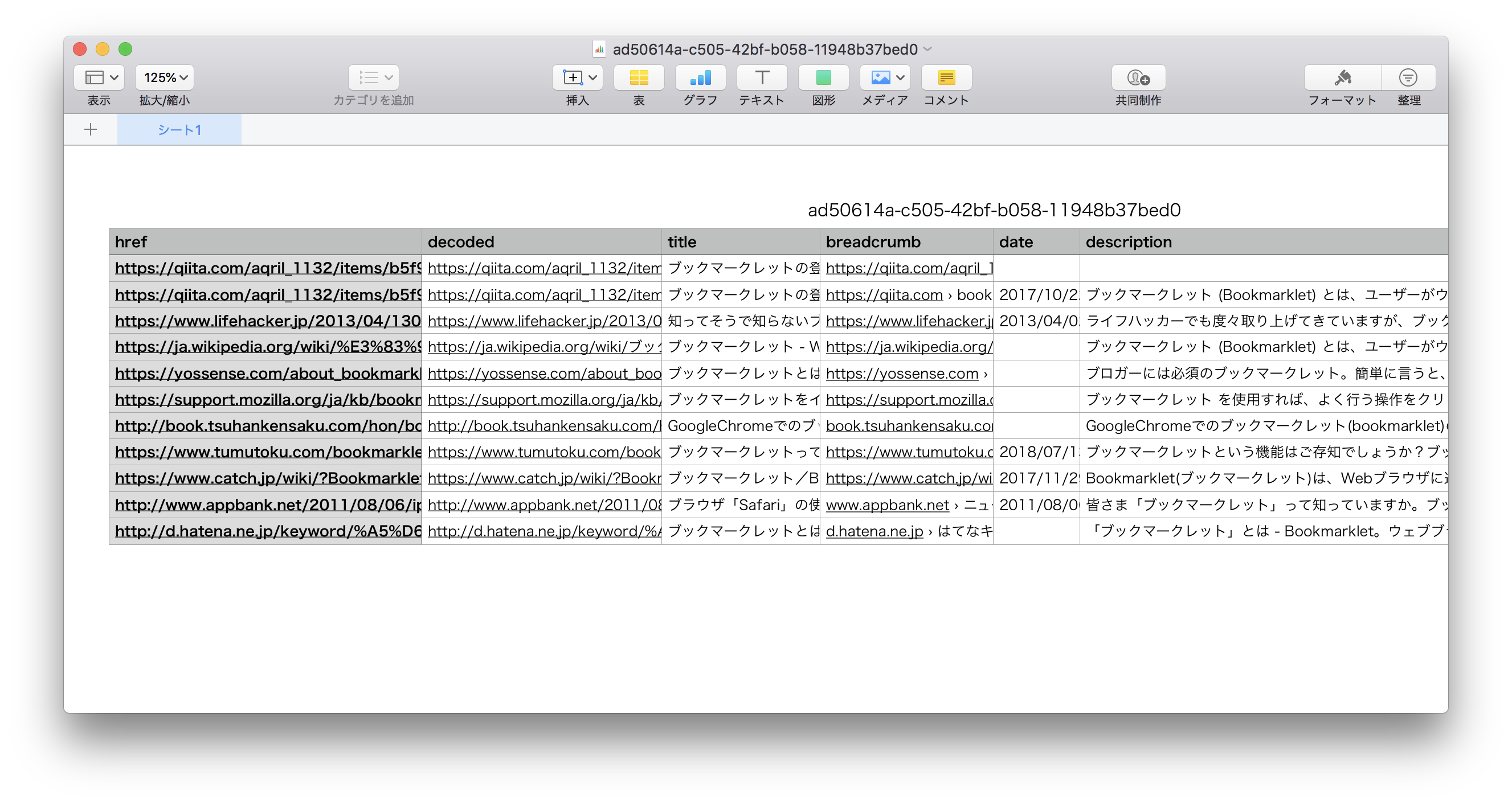
保存されるCSV
UTF-8でエンコードされています。
Excel、Numbers、CalcやGoogle Spreadsheetでそのまま開けます。
| ヘッダ | 説明 | 空文字可能性 | 具体例 |
|---|---|---|---|
href |
URL | NO | https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%83%E3%82%AF%E3%83%9E%E3%83%BC%E3%82%AF%E3%83%AC%E3%83%83%E3%83%88 |
decoded |
decodeURI()したURL |
NO | https://ja.wikipedia.org/wiki/ブックマークレット |
title |
サイト名 or ページ名 | YES | ブックマークレット - Wikipedia |
breadcrumb |
パンくずの表示 | YES | https://ja.wikipedia.org/wiki/ブックマークレット |
date |
更新日 | YES | 2019/1/15 |
description |
ページの概要 | YES | ブックマークレット (Bookmarklet) とは、ユーザーがウェブブラウザのブックマークなどから起動し、なんらかの処理を行う簡易的なプログラムのことである。携帯電話のウェブブラウザで足りない機能を補ったり、ウェブアプリケーションの処理を起動する為に使 ... |
siteName |
サイトの名前 | YES | Wikipedia |
2024年5月最新版から、
siteNameが追加されました。
対象ブラウザ
最新のブラウザを利用してください。
動作確認結果
2024年5月6日時点
| ブラウザ | バージョン | 動作 |
|---|---|---|
| Google Chrome | 124.0.6367.119 (Official Build) (arm64) | OK |
| Firefox | 125.0.3 | OK |
| Safari | 17.4.1 | OK |
| Edge (Blink) | 124.0.2478.80 (公式ビルド) (arm64) | OK |
| Edge (EdgeHTML) | 動作未確認 | 今後も対応しません。 |
| Internet Explorer | 11.1082.18362.0 | NG 今後も対応しません。 |
ソースコード
ブックマークレット用に変換する前のソースコードです。
ここをクリックしてソースコードを表示
/**
* @typedef EntryKeys
* @type {['href', 'decoded', 'title', 'breadcrumb', 'date', 'description', 'siteName'] as const}
*/
/**
* @typedef Entry
* @type {{
* [Key in EntryKeys[number]]: string | Element | null | undefined
* }}
*/
(
/**
* @param {Document} document
* @param {typeof Promise} Promise
* @param {typeof setTimeout} setTimeout
* @param {'innerHTML'} html
* @param {'addEventListener'} on
* @param {'length'} size
* @param {'innerText'} text
* @param {EntryKeys} heading
*/
(document, Promise, setTimeout, html, on, size, text, heading) => {
/**
* @param {string} query
* @param {Element | undefined} doc
*/
const $ = (query, doc = document) => doc.querySelector(query)
/**
* @param {string} query
* @param {Element | undefined} doc
*/
const $$ = (query, doc = document) => doc.querySelectorAll(query)
/**
* @param {Element} child
* @param {Element | undefined} parent
*/
const appendChild = (child, parent = document.body) => parent.appendChild(child)
/**
* @param {string} tag
*/
const createElement = tag => document.createElement(tag)
const cleanup = () => {
if (iframe !== undefined) {
iframe.remove()
}
}
/**
* @template T
* @param {T[]} base
* @param {(T | T[])[]} arr
*/
const concat = (base, ...arr) => /** @type {T[][]} */ (arr).reduce((prev, item) => prev.concat(item), base)
/**
* @param {(string | Element)[]} row
*/
const convert = row => `"${row.map(s => replaceArr(
getText(s) || '',
[/"/g, /\n/g],
['""', '']
)).join('","')}"`
/**
* @param {string} href
*/
const decode = href => {
let out = href
try {
out = decodeURI(href)
} catch (e) {}
return out
}
const download = () => {
const blob = new Blob([
new Uint8Array([0xEF, 0xBB, 0xBF]),
joinLines(concat(
[
convert(heading)
],
ret.map(item => convert(Object.values(item)))
))
], {
type: 'text/csv'
})
const a = document.createElement('a')
const url = URL.createObjectURL(blob)
a.download = document.title + '.csv'
a.href = url
a.click()
setTimeout(() => URL.revokeObjectURL(url), 1000)
}
/**
* @template T
* @param {T[]} array
* @returns {(Exclude<T, 0 | '' | false | null | undefined>)[]}
*/
const filter = array => array.filter(item => !!item)
/**
* @param {HTMLElement | null | undefined} element
*/
const getText = element => element && typeof element === 'object' && text in element
? element[text]
: element || ''
/**
* @param {string[]} array
*/
const joinLines = array => array.join('\n')
/**
* @param {number} maxItems
*/
const loop = async (maxItems) => {
const canScroll = await scroll()
ret = scan()
const hasReachedMax = maxItems <= ret[size]
if (ret[size] === 0 || hasReachedMax) {
return false
}
if (canScroll) {
return true
}
const next = filter([
nextAuto(),
nextOldSchool()
])
if (next[size] === 0) {
return false
}
await Promise.all(next)
return true
}
const main = async () => {
const input = prompt('Enter maximum number of items as an integer', 'everything')
if (!input) {
return
}
const maxItems = parseInt(input)
if (maxItems <= 0) {
return
}
while (await loop(maxItems)) {
continue
}
if (ret[size] === 0) {
alert('No item found.\nIf you think this script works incorrectly contact the creator.\nThx in advance.')
return
}
alert(`Found: ${ret[size]}`)
cleanup()
download()
}
/**
* @template T
* @param {string} query
* @param {(item: Element) => T} callback
*/
const mapElements = (query, callback) => Array.from($$(query)).map(callback)
const nextAuto = () => {
const progressBar = $('div[data-dt=1] > div[role=progressbar]')
if (!progressBar) {
return false
}
const moreLink = $('h1 + a', progressBar.parentNode)
if (!moreLink) {
return false
}
if (/transform: ?scale\(0\)/.test(moreLink.getAttribute('style'))) {
return false
}
/**
* @type {Promise<true>}
*/
const promise = new Promise((resolve) => {
moreLink.click()
const observer = new MutationObserver((mutations) => {
for (const mutation of mutations) {
if (mutation.type === 'attributes' && mutation.attributeName === 'style') {
const currentValue = progressBar.getAttribute('style')
if (/display: ?none/.test(currentValue)) {
observer.disconnect()
resolve(true)
}
}
}
})
observer.observe(progressBar, {
attributes: true
})
})
return promise
}
const nextOldSchool = () => {
/**
* @type {HTMLAnchorElement}
*/
const pnnext = $('#pnnext', doc)
if (!pnnext) {
return false
}
if (iframe === undefined) {
iframe = createElement('iframe')
setStyle(iframe, {
display: 'none'
})
appendChild(iframe)
}
const progress = createElement('div')
setStyle(progress, {
background: 'black',
color: 'white',
left: 0,
padding: '8px 20px',
position: 'fixed',
top: 0,
zIndex: 1000
})
progress[text] = 'Loading...'
appendChild(progress)
/**
* @type {Promise<true>}
*/
const promise = new Promise(resolve => {
iframe[on]('load', () => {
doc = iframe.contentWindow.document
progress.remove()
const wrapper = createElement('div')
wrapper[html] = $('#rso', doc)[html]
$$('div.ITCGwe', wrapper).forEach(item => item.parentNode.removeChild(item))
const last = $('#rso')
for (const child of wrapper.children) {
appendChild(child, last)
}
if (doc !== document) {
$('#botstuff')[html] = $('#botstuff', doc)[html]
}
resolve(true)
}, {
once: true
})
iframe.src = pnnext.href
})
return promise
}
/**
* @param {string | null | undefined} string
* @param {string | RegExp} from
* @param {string} to
*/
const replace = (string, from, to = '') => (string || '').replace(from, to)
/**
* @param {string | null | undefined} string
* @param {(string | RegExp)[]} from
* @param {string[]} to
*/
const replaceArr = (string, from, to) => from.reduce((prev, pattern, index) => replace(prev, pattern, to[index]), string)
const scan = () => filter(concat(
// All tab
mapElements('#rso div.MjjYud > div.g, div[id^="arc-srp_"] div.MjjYud > div.g, #rso div.K7khPe, #rso div.RzdJxc, #rso div.m7jPZ', item => {
/**
* @type {HTMLAnchorElement}
*/
const a = $('div.yuRUbf a, div.RzdJxc a, div.m7jPZ > a.WlydOe', item)
if (!a) {
return false
}
const href = a.href
/**
* @type {HTMLElement | string | null | undefined}
*/
let title
/**
* @type {HTMLElement | string | null | undefined}
*/
let breadcrumb
/**
* @type {HTMLElement | string | null | undefined}
*/
let date
/**
* @type {HTMLElement | string | null | undefined}
*/
let desc
/**
* @type {HTMLElement | string | null | undefined}
*/
let siteName
if (item.classList.contains('RzdJxc')) {
// YouTube
title = $('[role=heading] span.cHaqb', item)
breadcrumb = $('span.Sg4azc > span', item)
date = $('div.OwbDmd > span', item)
desc = $('div.V8fWH', item)
siteName = $('cite', item)
breadcrumb = breadcrumb && replace(getText(breadcrumb), ' · ')
} else if (item.classList.contains('m7jPZ')) {
// News
title = $('[role=heading]', a)
date = $('div.OSrXXb > span', a)
siteName = $('div.MgUUmf > span', a)
} else {
title = $('h3', a)
breadcrumb = $('cite', a)
date = $('div.VwiC3b > span.Sqrs4e span, div.IsZvec > div.fG8Fp', item)
desc = $('div.VwiC3b > span:not(.Sqrs4e):last-of-type, div.IsZvec > span.aCOpRe > span', item)
siteName = $('span.VuuXrf', a)
if (!date && !$('cite span', a)) {
const parts = getText(breadcrumb).split(' · ')
try {
breadcrumb = parts[0].trimEnd()
date = parts[1].trimStart()
} catch (error) {}
}
if (!desc) {
const nodes = $('div.VwiC3b', item).childNodes
desc = nodes.item(nodes[size] - 1).textContent
}
}
return /** @type {Entry} */ ({
href,
decoded: decode(href),
title,
breadcrumb,
date,
desc: desc && (
date
? replace(getText(desc), getText(date)).trimStart()
: getText(desc)
),
siteName
})
}),
// Images tab
mapElements('#rso > div.MjjYud [data-attrid~=images]', item => {
/**
* @type {HTMLAnchorElement | null}
*/
const a = $('a[target=_blank]', item)
if (!a) {
return false
}
const href = a.href
const src = $('h3 img', item).src
return /** @type {Entry} */ ({
href,
decoded: decode(href),
title: $('div.toI8Rb', a),
breadcrumb: src.startsWith('data:') ? null : src,
date: $('div.wr8GYd > span', item),
description: $('div.toI8Rb', a),
siteName: $('div.guK3rf > span', a)
})
}),
// News tab
mapElements('#rso > div.MjjYud a.WlydOe', item => {
const href = /** @type {HTMLAnchorElement} */ (item).href
return /** @type {Entry} */ ({
href,
decoded: decode(href),
title: $('[role=heading]', item),
breadcrumb: null,
date: $('div.OSrXXb > span', item),
description: $('div.GI74Re', item),
siteName: $('div.MgUUmf > span', item)
})
}),
// Videos tab
mapElements('#rso > div.MjjYud > div > div.g', item => {
/**
* @type {HTMLAnchorElement | null}
*/
const a = $('div.xe8e1b a', item)
if (!a) {
return false
}
const href = a.href
return /** @type {Entry} */ ({
href,
decoded: decode(href),
title: $('h3', a),
breadcrumb: $('cite', a),
date: $('div.gqF9jc > span > span', item),
description: $('div.ITZIwc', item),
siteName: $('div.gqF9jc > span:nth-of-type(2)', item)
})
})
))
const scroll = () => {
const scrollingElement = document.scrollingElement
if (!scrollingElement || scrollingElement.scrollTop + scrollingElement.clientHeight >= scrollingElement.scrollHeight - 50) {
return false
}
/**
* @type {Promise<true>}
*/
const promise = new Promise(resolve => {
document.body.scrollIntoView({
behavior: 'smooth',
block: 'end'
})
const listener = () => {
clearTimeout(timer)
timer = setTimeout(() => {
document.removeEventListener('scroll', listener)
resolve(true)
}, 1000)
}
let timer
document[on]('scroll', listener, {
passive: true
})
listener()
})
return promise
}
/**
* @param {HTMLElement} target
* @param {Object.<string, string>} style
*/
const setStyle = (target, style) => {
for (let key in style) {
target.style[key] = style[key]
}
}
let doc = document
/**
* @type {HTMLIFrameElement}
*/
let iframe
/**
* @type {Entry[]}
*/
let ret = []
main()
})(document, Promise, setTimeout, 'innerHTML', 'addEventListener', 'length', 'innerText', [
'href',
'decoded',
'title',
'breadcrumb',
'date',
'description',
'siteName'
])
※ Minifierはこちらを使用しています。
※ Minify後の文字数をなるべく削減するために、少々トリッキーなコーディングをしています。
免責
Google検索結果画面の仕様が変わると、動作しなくなることが予想されます。
その際にはご容赦ください。