0. はじめに
XでSB Intuitions株式会社殿が以下のポストをしているのを見たので、LLM時代の昨今ではありますがSLM(Small Language Model)として注目が高まっていた新たなBERTをお試ししてみた個人的な備忘録を残します
/
— SB Intuitions (@sbintuitions) February 12, 2025
📢 130Mパラメータの高性能・長系列対応BERTモデルを公開しました‼️
\
📝 モデルの特徴
・2ヶ月前に公開されたばかりのModernBERTアーキテクチャを採用
・これまでの最良モデルと同水準の性能を1/3のサイズで達成
・一般的なモデルの16倍の長さの文章を処理可能(日本語最長)
詳細はこちら⬇️
公式ドキュメントは以下
-
動作環境
・ OS : Windows11 pro
・ GPU : GeForce RTX 4070 Ti SUPER
・ python : 3.12.8
・ torch : 2.5.1+cu121
・ transformers : 4.48.3
-
検証に必要なライブラリ
・ torch
・ transformers
・ fugashi
・ ipadic
・ unidic_lite
・ japanize-matplotlib
・ pandas
・ numpy
・ matplotlib
・ seaborn
・ scikit-learn
・ protobuf
・ sentencepiece
・ scikit-learn
・ accelerate
1. ModernBERTとは?
すでに以下のような記事が出ているので詳細は見ていただくとして、例のごとく私はざっくり目にお話しします
https://zenn.dev/tossy21/articles/9359144226929t color="Red">一番の特徴は何といっても「長文のコンテキスト」を扱えることだと思います。
従来の「BERT/RoBERTa」は入力のシーケンス長が512トークンとなっており、それ以上の文章を入れる場合は文章を区切る必要がありました。
しかし、この「ModernBERT」ではなんと最大8192トークンまで対応しているため、かなりの長文を一気に処理することができます。
そしてFlash AttentionやUnpaddingといった技術により、計算時間が短縮されて「早さ」と「効率」が改善されているようです。
さらに学習データに「Sarashina2」という日本語に強いLLMと同じデータで学習されている為、コード等にも強いとされています
2. 長文トークンで試してみる
お試しに青空文庫の走れメロスを入れてみることにする。
2-1. トークン数を調べてみる
text = """
メロスは激怒した。必ず、かの邪智暴虐じゃちぼうぎゃくの王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。きょう未明メロスは村を出発し、野を越え山越え、十里はなれた此このシラクスの市にやって来た。メロスには父も、母も無い。女房も無い。十六の、内気な妹と二人暮しだ。この妹は、村の或る律気な一牧人を、近々、花婿はなむことして迎える事になっていた。結婚式も間近かなのである。メロスは、それゆえ、花嫁の衣裳やら祝宴の御馳走やらを買いに、はるばる市にやって来たのだ。先ず、その品々を買い集め、それから都の大路をぶらぶら歩いた。メロスには竹馬の友があった。セリヌンティウスである。今は此のシラクスの市で、石工をしている。その友を、これから訪ねてみるつもりなのだ。久しく逢わなかったのだから、訪ねて行くのが楽しみである。歩いているうちにメロスは、まちの様子を怪しく思った。ひっそりしている。もう既に日も落ちて、まちの暗いのは当りまえだが、けれども、なんだか、夜のせいばかりでは無く、市全体が、やけに寂しい。のんきなメロスも、だんだん不安になって来た。路で逢った若い衆をつかまえて、何かあったのか、二年まえに此の市に来たときは、夜でも皆が歌をうたって、まちは賑やかであった筈はずだが、と質問した。若い衆は、首を振って答えなかった。しばらく歩いて老爺ろうやに逢い、こんどはもっと、語勢を強くして質問した。老爺は答えなかった。メロスは両手で老爺のからだをゆすぶって質問を重ねた。老爺は、あたりをはばかる低声で、わずか答えた。
「王様は、人を殺します。」
「なぜ殺すのだ。」
「悪心を抱いている、というのですが、誰もそんな、悪心を持っては居りませぬ。」
「たくさんの人を殺したのか。」
「はい、はじめは王様の妹婿さまを。それから、御自身のお世嗣よつぎを。それから、妹さまを。それから、妹さまの御子さまを。それから、皇后さまを。それから、賢臣のアレキス様を。」
「おどろいた。国王は乱心か。」
「いいえ、乱心ではございませぬ。人を、信ずる事が出来ぬ、というのです。このごろは、臣下の心をも、お疑いになり、少しく派手な暮しをしている者には、人質ひとりずつ差し出すことを命じて居ります。御命令を拒めば十字架にかけられて、殺されます。きょうは、六人殺されました。」
聞いて、メロスは激怒した。「呆あきれた王だ。生かして置けぬ。」
メロスは、単純な男であった。買い物を、背負ったままで、のそのそ王城にはいって行った。たちまち彼は、巡邏じゅんらの警吏に捕縛された。調べられて、メロスの懐中からは短剣が出て来たので、騒ぎが大きくなってしまった。メロスは、王の前に引き出された。
「この短刀で何をするつもりであったか。言え!」暴君ディオニスは静かに、けれども威厳を以もって問いつめた。その王の顔は蒼白そうはくで、眉間みけんの皺しわは、刻み込まれたように深かった。
「市を暴君の手から救うのだ。」とメロスは悪びれずに答えた。
「おまえがか?」王は、憫笑びんしょうした。「仕方の無いやつじゃ。おまえには、わしの孤独がわからぬ。」
「言うな!」とメロスは、いきり立って反駁はんばくした。「人の心を疑うのは、最も恥ずべき悪徳だ。王は、民の忠誠をさえ疑って居られる。」
「疑うのが、正当の心構えなのだと、わしに教えてくれたのは、おまえたちだ。人の心は、あてにならない。人間は、もともと私慾のかたまりさ。信じては、ならぬ。」暴君は落着いて呟つぶやき、ほっと溜息ためいきをついた。「わしだって、平和を望んでいるのだが。」
「なんの為の平和だ。自分の地位を守る為か。」こんどはメロスが嘲笑した。「罪の無い人を殺して、何が平和だ。」
「だまれ、下賤げせんの者。」王は、さっと顔を挙げて報いた。「口では、どんな清らかな事でも言える。わしには、人の腹綿の奥底が見え透いてならぬ。おまえだって、いまに、磔はりつけになってから、泣いて詫わびたって聞かぬぞ。」
「ああ、王は悧巧りこうだ。自惚うぬぼれているがよい。私は、ちゃんと死ぬる覚悟で居るのに。命乞いなど決してしない。ただ、――」と言いかけて、メロスは足もとに視線を落し瞬時ためらい、「ただ、私に情をかけたいつもりなら、処刑までに三日間の日限を与えて下さい。たった一人の妹に、亭主を持たせてやりたいのです。三日のうちに、私は村で結婚式を挙げさせ、必ず、ここへ帰って来ます。」
「ばかな。」と暴君は、嗄しわがれた声で低く笑った。「とんでもない嘘うそを言うわい。逃がした小鳥が帰って来るというのか。」
「そうです。帰って来るのです。」メロスは必死で言い張った。「私は約束を守ります。私を、三日間だけ許して下さい。妹が、私の帰りを待っているのだ。そんなに私を信じられないならば、よろしい、この市にセリヌンティウスという石工がいます。私の無二の友人だ。あれを、人質としてここに置いて行こう。私が逃げてしまって、三日目の日暮まで、ここに帰って来なかったら、あの友人を絞め殺して下さい。たのむ、そうして下さい。」
それを聞いて王は、残虐な気持で、そっと北叟笑ほくそえんだ。生意気なことを言うわい。どうせ帰って来ないにきまっている。この嘘つきに騙だまされた振りして、放してやるのも面白い。そうして身代りの男を、三日目に殺してやるのも気味がいい。人は、これだから信じられぬと、わしは悲しい顔して、その身代りの男を磔刑に処してやるのだ。世の中の、正直者とかいう奴輩やつばらにうんと見せつけてやりたいものさ。
「願いを、聞いた。その身代りを呼ぶがよい。三日目には日没までに帰って来い。おくれたら、その身代りを、きっと殺すぞ。ちょっとおくれて来るがいい。おまえの罪は、永遠にゆるしてやろうぞ。」
「なに、何をおっしゃる。」
「はは。いのちが大事だったら、おくれて来い。おまえの心は、わかっているぞ。」
メロスは口惜しく、地団駄じだんだ踏んだ。ものも言いたくなくなった。
竹馬の友、セリヌンティウスは、深夜、王城に召された。暴君ディオニスの面前で、佳よき友と佳き友は、二年ぶりで相逢うた。メロスは、友に一切の事情を語った。セリヌンティウスは無言で首肯うなずき、メロスをひしと抱きしめた。友と友の間は、それでよかった。セリヌンティウスは、縄打たれた。メロスは、すぐに出発した。初夏、満天の星である。
メロスはその夜、一睡もせず十里の路を急ぎに急いで、村へ到着したのは、翌あくる日の午前、陽は既に高く昇って、村人たちは野に出て仕事をはじめていた。メロスの十六の妹も、きょうは兄の代りに羊群の番をしていた。よろめいて歩いて来る兄の、疲労困憊こんぱいの姿を見つけて驚いた。そうして、うるさく兄に質問を浴びせた。
「なんでも無い。」メロスは無理に笑おうと努めた。「市に用事を残して来た。またすぐ市に行かなければならぬ。あす、おまえの結婚式を挙げる。早いほうがよかろう。」
妹は頬をあからめた。
「うれしいか。綺麗きれいな衣裳も買って来た。さあ、これから行って、村の人たちに知らせて来い。結婚式は、あすだと。」
メロスは、また、よろよろと歩き出し、家へ帰って神々の祭壇を飾り、祝宴の席を調え、間もなく床に倒れ伏し、呼吸もせぬくらいの深い眠りに落ちてしまった。
眼が覚めたのは夜だった。メロスは起きてすぐ、花婿の家を訪れた。そうして、少し事情があるから、結婚式を明日にしてくれ、と頼んだ。婿の牧人は驚き、それはいけない、こちらには未だ何の仕度も出来ていない、葡萄ぶどうの季節まで待ってくれ、と答えた。メロスは、待つことは出来ぬ、どうか明日にしてくれ給え、と更に押してたのんだ。婿の牧人も頑強であった。なかなか承諾してくれない。夜明けまで議論をつづけて、やっと、どうにか婿をなだめ、すかして、説き伏せた。結婚式は、真昼に行われた。新郎新婦の、神々への宣誓が済んだころ、黒雲が空を覆い、ぽつりぽつり雨が降り出し、やがて車軸を流すような大雨となった。祝宴に列席していた村人たちは、何か不吉なものを感じたが、それでも、めいめい気持を引きたて、狭い家の中で、むんむん蒸し暑いのも怺こらえ、陽気に歌をうたい、手を拍うった。メロスも、満面に喜色を湛たたえ、しばらくは、王とのあの約束をさえ忘れていた。祝宴は、夜に入っていよいよ乱れ華やかになり、人々は、外の豪雨を全く気にしなくなった。メロスは、一生このままここにいたい、と思った。この佳い人たちと生涯暮して行きたいと願ったが、いまは、自分のからだで、自分のものでは無い。ままならぬ事である。メロスは、わが身に鞭打ち、ついに出発を決意した。あすの日没までには、まだ十分の時が在る。ちょっと一眠りして、それからすぐに出発しよう、と考えた。その頃には、雨も小降りになっていよう。少しでも永くこの家に愚図愚図とどまっていたかった。メロスほどの男にも、やはり未練の情というものは在る。今宵呆然、歓喜に酔っているらしい花嫁に近寄り、
「おめでとう。私は疲れてしまったから、ちょっとご免こうむって眠りたい。眼が覚めたら、すぐに市に出かける。大切な用事があるのだ。私がいなくても、もうおまえには優しい亭主があるのだから、決して寂しい事は無い。おまえの兄の、一ばんきらいなものは、人を疑う事と、それから、嘘をつく事だ。おまえも、それは、知っているね。亭主との間に、どんな秘密でも作ってはならぬ。おまえに言いたいのは、それだけだ。おまえの兄は、たぶん偉い男なのだから、おまえもその誇りを持っていろ。」
花嫁は、夢見心地で首肯うなずいた。メロスは、それから花婿の肩をたたいて、
「仕度の無いのはお互さまさ。私の家にも、宝といっては、妹と羊だけだ。他には、何も無い。全部あげよう。もう一つ、メロスの弟になったことを誇ってくれ。」
花婿は揉もみ手して、てれていた。メロスは笑って村人たちにも会釈えしゃくして、宴席から立ち去り、羊小屋にもぐり込んで、死んだように深く眠った。
眼が覚めたのは翌る日の薄明の頃である。メロスは跳ね起き、南無三、寝過したか、いや、まだまだ大丈夫、これからすぐに出発すれば、約束の刻限までには十分間に合う。きょうは是非とも、あの王に、人の信実の存するところを見せてやろう。そうして笑って磔の台に上ってやる。メロスは、悠々と身仕度をはじめた。雨も、いくぶん小降りになっている様子である。身仕度は出来た。さて、メロスは、ぶるんと両腕を大きく振って、雨中、矢の如く走り出た。
私は、今宵、殺される。殺される為に走るのだ。身代りの友を救う為に走るのだ。王の奸佞かんねい邪智を打ち破る為に走るのだ。走らなければならぬ。そうして、私は殺される。若い時から名誉を守れ。さらば、ふるさと。若いメロスは、つらかった。幾度か、立ちどまりそうになった。えい、えいと大声挙げて自身を叱りながら走った。村を出て、野を横切り、森をくぐり抜け、隣村に着いた頃には、雨も止やみ、日は高く昇って、そろそろ暑くなって来た。メロスは額ひたいの汗をこぶしで払い、ここまで来れば大丈夫、もはや故郷への未練は無い。妹たちは、きっと佳い夫婦になるだろう。私には、いま、なんの気がかりも無い筈だ。まっすぐに王城に行き着けば、それでよいのだ。そんなに急ぐ必要も無い。ゆっくり歩こう、と持ちまえの呑気のんきさを取り返し、好きな小歌をいい声で歌い出した。ぶらぶら歩いて二里行き三里行き、そろそろ全里程の半ばに到達した頃、降って湧わいた災難、メロスの足は、はたと、とまった。見よ、前方の川を。きのうの豪雨で山の水源地は氾濫はんらんし、濁流滔々とうとうと下流に集り、猛勢一挙に橋を破壊し、どうどうと響きをあげる激流が、木葉微塵こっぱみじんに橋桁はしげたを跳ね飛ばしていた。彼は茫然と、立ちすくんだ。あちこちと眺めまわし、また、声を限りに呼びたててみたが、繋舟けいしゅうは残らず浪に浚さらわれて影なく、渡守りの姿も見えない。流れはいよいよ、ふくれ上り、海のようになっている。メロスは川岸にうずくまり、男泣きに泣きながらゼウスに手を挙げて哀願した。「ああ、鎮しずめたまえ、荒れ狂う流れを! 時は刻々に過ぎて行きます。太陽も既に真昼時です。あれが沈んでしまわぬうちに、王城に行き着くことが出来なかったら、あの佳い友達が、私のために死ぬのです。」
濁流は、メロスの叫びをせせら笑う如く、ますます激しく躍り狂う。浪は浪を呑み、捲き、煽あおり立て、そうして時は、刻一刻と消えて行く。今はメロスも覚悟した。泳ぎ切るより他に無い。ああ、神々も照覧あれ! 濁流にも負けぬ愛と誠の偉大な力を、いまこそ発揮して見せる。メロスは、ざんぶと流れに飛び込み、百匹の大蛇のようにのた打ち荒れ狂う浪を相手に、必死の闘争を開始した。満身の力を腕にこめて、押し寄せ渦巻き引きずる流れを、なんのこれしきと掻かきわけ掻きわけ、めくらめっぽう獅子奮迅の人の子の姿には、神も哀れと思ったか、ついに憐愍れんびんを垂れてくれた。押し流されつつも、見事、対岸の樹木の幹に、すがりつく事が出来たのである。ありがたい。メロスは馬のように大きな胴震いを一つして、すぐにまた先きを急いだ。一刻といえども、むだには出来ない。陽は既に西に傾きかけている。ぜいぜい荒い呼吸をしながら峠をのぼり、のぼり切って、ほっとした時、突然、目の前に一隊の山賊が躍り出た。
「待て。」
「何をするのだ。私は陽の沈まぬうちに王城へ行かなければならぬ。放せ。」
「どっこい放さぬ。持ちもの全部を置いて行け。」
「私にはいのちの他には何も無い。その、たった一つの命も、これから王にくれてやるのだ。」
「その、いのちが欲しいのだ。」
「さては、王の命令で、ここで私を待ち伏せしていたのだな。」
山賊たちは、ものも言わず一斉に棍棒こんぼうを振り挙げた。メロスはひょいと、からだを折り曲げ、飛鳥の如く身近かの一人に襲いかかり、その棍棒を奪い取って、
「気の毒だが正義のためだ!」と猛然一撃、たちまち、三人を殴り倒し、残る者のひるむ隙すきに、さっさと走って峠を下った。一気に峠を駈け降りたが、流石さすがに疲労し、折から午後の灼熱しゃくねつの太陽がまともに、かっと照って来て、メロスは幾度となく眩暈めまいを感じ、これではならぬ、と気を取り直しては、よろよろ二、三歩あるいて、ついに、がくりと膝を折った。立ち上る事が出来ぬのだ。天を仰いで、くやし泣きに泣き出した。ああ、あ、濁流を泳ぎ切り、山賊を三人も撃ち倒し韋駄天いだてん、ここまで突破して来たメロスよ。真の勇者、メロスよ。今、ここで、疲れ切って動けなくなるとは情無い。愛する友は、おまえを信じたばかりに、やがて殺されなければならぬ。おまえは、稀代きたいの不信の人間、まさしく王の思う壺つぼだぞ、と自分を叱ってみるのだが、全身萎なえて、もはや芋虫いもむしほどにも前進かなわぬ。路傍の草原にごろりと寝ころがった。身体疲労すれば、精神も共にやられる。もう、どうでもいいという、勇者に不似合いな不貞腐ふてくされた根性が、心の隅に巣喰った。私は、これほど努力したのだ。約束を破る心は、みじんも無かった。神も照覧、私は精一ぱいに努めて来たのだ。動けなくなるまで走って来たのだ。私は不信の徒では無い。ああ、できる事なら私の胸を截たち割って、真紅の心臓をお目に掛けたい。愛と信実の血液だけで動いているこの心臓を見せてやりたい。けれども私は、この大事な時に、精も根も尽きたのだ。私は、よくよく不幸な男だ。私は、きっと笑われる。私の一家も笑われる。私は友を欺あざむいた。中途で倒れるのは、はじめから何もしないのと同じ事だ。ああ、もう、どうでもいい。これが、私の定った運命なのかも知れない。セリヌンティウスよ、ゆるしてくれ。君は、いつでも私を信じた。私も君を、欺かなかった。私たちは、本当に佳い友と友であったのだ。いちどだって、暗い疑惑の雲を、お互い胸に宿したことは無かった。いまだって、君は私を無心に待っているだろう。ああ、待っているだろう。ありがとう、セリヌンティウス。よくも私を信じてくれた。それを思えば、たまらない。友と友の間の信実は、この世で一ばん誇るべき宝なのだからな。セリヌンティウス、私は走ったのだ。君を欺くつもりは、みじんも無かった。信じてくれ! 私は急ぎに急いでここまで来たのだ。濁流を突破した。山賊の囲みからも、するりと抜けて一気に峠を駈け降りて来たのだ。私だから、出来たのだよ。ああ、この上、私に望み給うな。放って置いてくれ。どうでも、いいのだ。私は負けたのだ。だらしが無い。笑ってくれ。王は私に、ちょっとおくれて来い、と耳打ちした。おくれたら、身代りを殺して、私を助けてくれると約束した。私は王の卑劣を憎んだ。けれども、今になってみると、私は王の言うままになっている。私は、おくれて行くだろう。王は、ひとり合点して私を笑い、そうして事も無く私を放免するだろう。そうなったら、私は、死ぬよりつらい。私は、永遠に裏切者だ。地上で最も、不名誉の人種だ。セリヌンティウスよ、私も死ぬぞ。君と一緒に死なせてくれ。君だけは私を信じてくれるにちがい無い。いや、それも私の、ひとりよがりか? ああ、もういっそ、悪徳者として生き伸びてやろうか。村には私の家が在る。羊も居る。妹夫婦は、まさか私を村から追い出すような事はしないだろう。正義だの、信実だの、愛だの、考えてみれば、くだらない。人を殺して自分が生きる。それが人間世界の定法ではなかったか。ああ、何もかも、ばかばかしい。私は、醜い裏切り者だ。どうとも、勝手にするがよい。やんぬる哉かな。――四肢を投げ出して、うとうと、まどろんでしまった。
ふと耳に、潺々せんせん、水の流れる音が聞えた。そっと頭をもたげ、息を呑んで耳をすました。すぐ足もとで、水が流れているらしい。よろよろ起き上って、見ると、岩の裂目から滾々こんこんと、何か小さく囁ささやきながら清水が湧き出ているのである。その泉に吸い込まれるようにメロスは身をかがめた。水を両手で掬すくって、一くち飲んだ。ほうと長い溜息が出て、夢から覚めたような気がした。歩ける。行こう。肉体の疲労恢復かいふくと共に、わずかながら希望が生れた。義務遂行の希望である。わが身を殺して、名誉を守る希望である。斜陽は赤い光を、樹々の葉に投じ、葉も枝も燃えるばかりに輝いている。日没までには、まだ間がある。私を、待っている人があるのだ。少しも疑わず、静かに期待してくれている人があるのだ。私は、信じられている。私の命なぞは、問題ではない。死んでお詫び、などと気のいい事は言って居られぬ。私は、信頼に報いなければならぬ。いまはただその一事だ。走れ! メロス。
私は信頼されている。私は信頼されている。先刻の、あの悪魔の囁きは、あれは夢だ。悪い夢だ。忘れてしまえ。五臓が疲れているときは、ふいとあんな悪い夢を見るものだ。メロス、おまえの恥ではない。やはり、おまえは真の勇者だ。再び立って走れるようになったではないか。ありがたい! 私は、正義の士として死ぬ事が出来るぞ。ああ、陽が沈む。ずんずん沈む。待ってくれ、ゼウスよ。私は生れた時から正直な男であった。正直な男のままにして死なせて下さい。
路行く人を押しのけ、跳はねとばし、メロスは黒い風のように走った。野原で酒宴の、その宴席のまっただ中を駈け抜け、酒宴の人たちを仰天させ、犬を蹴けとばし、小川を飛び越え、少しずつ沈んでゆく太陽の、十倍も早く走った。一団の旅人と颯さっとすれちがった瞬間、不吉な会話を小耳にはさんだ。「いまごろは、あの男も、磔にかかっているよ。」ああ、その男、その男のために私は、いまこんなに走っているのだ。その男を死なせてはならない。急げ、メロス。おくれてはならぬ。愛と誠の力を、いまこそ知らせてやるがよい。風態なんかは、どうでもいい。メロスは、いまは、ほとんど全裸体であった。呼吸も出来ず、二度、三度、口から血が噴き出た。見える。はるか向うに小さく、シラクスの市の塔楼が見える。塔楼は、夕陽を受けてきらきら光っている。
「ああ、メロス様。」うめくような声が、風と共に聞えた。
「誰だ。」メロスは走りながら尋ねた。
「フィロストラトスでございます。貴方のお友達セリヌンティウス様の弟子でございます。」その若い石工も、メロスの後について走りながら叫んだ。「もう、駄目でございます。むだでございます。走るのは、やめて下さい。もう、あの方かたをお助けになることは出来ません。」
「いや、まだ陽は沈まぬ。」
「ちょうど今、あの方が死刑になるところです。ああ、あなたは遅かった。おうらみ申します。ほんの少し、もうちょっとでも、早かったなら!」
「いや、まだ陽は沈まぬ。」メロスは胸の張り裂ける思いで、赤く大きい夕陽ばかりを見つめていた。走るより他は無い。
「やめて下さい。走るのは、やめて下さい。いまはご自分のお命が大事です。あの方は、あなたを信じて居りました。刑場に引き出されても、平気でいました。王様が、さんざんあの方をからかっても、メロスは来ます、とだけ答え、強い信念を持ちつづけている様子でございました。」
「それだから、走るのだ。信じられているから走るのだ。間に合う、間に合わぬは問題でないのだ。人の命も問題でないのだ。私は、なんだか、もっと恐ろしく大きいものの為に走っているのだ。ついて来い! フィロストラトス。」
「ああ、あなたは気が狂ったか。それでは、うんと走るがいい。ひょっとしたら、間に合わぬものでもない。走るがいい。」
言うにや及ぶ。まだ陽は沈まぬ。最後の死力を尽して、メロスは走った。メロスの頭は、からっぽだ。何一つ考えていない。ただ、わけのわからぬ大きな力にひきずられて走った。陽は、ゆらゆら地平線に没し、まさに最後の一片の残光も、消えようとした時、メロスは疾風の如く刑場に突入した。間に合った。
「待て。その人を殺してはならぬ。メロスが帰って来た。約束のとおり、いま、帰って来た。」と大声で刑場の群衆にむかって叫んだつもりであったが、喉のどがつぶれて嗄しわがれた声が幽かすかに出たばかり、群衆は、ひとりとして彼の到着に気がつかない。すでに磔の柱が高々と立てられ、縄を打たれたセリヌンティウスは、徐々に釣り上げられてゆく。メロスはそれを目撃して最後の勇、先刻、濁流を泳いだように群衆を掻きわけ、掻きわけ、
「私だ、刑吏! 殺されるのは、私だ。メロスだ。彼を人質にした私は、ここにいる!」と、かすれた声で精一ぱいに叫びながら、ついに磔台に昇り、釣り上げられてゆく友の両足に、齧かじりついた。群衆は、どよめいた。あっぱれ。ゆるせ、と口々にわめいた。セリヌンティウスの縄は、ほどかれたのである。
「セリヌンティウス。」メロスは眼に涙を浮べて言った。「私を殴れ。ちから一ぱいに頬を殴れ。私は、途中で一度、悪い夢を見た。君が若もし私を殴ってくれなかったら、私は君と抱擁する資格さえ無いのだ。殴れ。」
セリヌンティウスは、すべてを察した様子で首肯うなずき、刑場一ぱいに鳴り響くほど音高くメロスの右頬を殴った。殴ってから優しく微笑ほほえみ、
「メロス、私を殴れ。同じくらい音高く私の頬を殴れ。私はこの三日の間、たった一度だけ、ちらと君を疑った。生れて、はじめて君を疑った。君が私を殴ってくれなければ、私は君と抱擁できない。」
メロスは腕に唸うなりをつけてセリヌンティウスの頬を殴った。
「ありがとう、友よ。」二人同時に言い、ひしと抱き合い、それから嬉し泣きにおいおい声を放って泣いた。
群衆の中からも、歔欷きょきの声が聞えた。暴君ディオニスは、群衆の背後から二人の様を、まじまじと見つめていたが、やがて静かに二人に近づき、顔をあからめて、こう言った。
「おまえらの望みは叶かなったぞ。おまえらは、わしの心に勝ったのだ。信実とは、決して空虚な妄想ではなかった。どうか、わしをも仲間に入れてくれまいか。どうか、わしの願いを聞き入れて、おまえらの仲間の一人にしてほしい。」
どっと群衆の間に、歓声が起った。
「万歳、王様万歳。」
ひとりの少女が、緋ひのマントをメロスに捧げた。メロスは、まごついた。佳き友は、気をきかせて教えてやった。
「メロス、君は、まっぱだかじゃないか。早くそのマントを着るがいい。この可愛い娘さんは、メロスの裸体を、皆に見られるのが、たまらなく口惜しいのだ。」
勇者は、ひどく赤面した。
"""
from transformers import AutoTokenizer
# 使用するモデル名を定義
model_name = "sbintuitions/modernbert-ja-130m"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(model_name)
ids = tokenizer.encode(text, return_tensors='pt')[0]
tokens = tokenizer.convert_ids_to_tokens(ids)
print(f"トークン数は:{len(ids)} です")
print(ids)
print(tokens)
トークン数は:5821 です
tensor([ 1, 25, 332, ..., 278, 25, 2])
['<s>', '<0x0A>', '\u3000', 'メロ', 'スは', '激怒', 'した', '。'
・・・(途中略)・・・
'勇者', 'は', '、', 'ひどく', '赤', '面', 'した', '。', '<0x0A>', '</s>
これにより走れメロスはModernBERTでは5821トークンであることがわかった(つまりこれを丸ごと入れることができるはず)
2-2. Embeddings(ベクトル化)してみる
ではこの文章を本当にそのまま一括でベクトル化できるのか?を次に試してみる。
※text変数は長いので省略するが↑と同じものとする
import torch
from transformers import AutoTokenizer, AutoModel
model_name = "sbintuitions/modernbert-ja-130m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 推論モード
model.eval()
# テキストをトークナイズしてテンソルに変換
inputs = tokenizer(text, return_tensors="pt")
# モデルに入力して出力を取得
with torch.no_grad():
outputs = model(**inputs)
# 隠れ層のベクトル
last_hidden_states = outputs.last_hidden_state
# トークン平均の埋め込みベクトルを取得
sentence_vector = last_hidden_states.mean(dim=1)
print(f"埋め込み次元は{sentence_vector.shape}です")
print(sentence_vector)
埋め込み次元はtorch.Size([1, 512])です
tensor([[-4.4106e-01, 4.0484e-01, -2.5774e+00, -6.7377e-01, -8.4023e-01,
8.9258e-01, 8.3952e-01, -6.9833e-01, 1.3394e+00, -1.4031e+00,
・・・(略)
これでこのモデルが本当に5821トークンをベクトル化できることが判明した。
仮にmodel_nameの部分を東北大BERTとして有名であるcl-tohoku/bert-base-japanese-v3でやろうとしてもそのままだと当然できない(RuntimeErrorで512トークンに落とすように言われる)
トークン数は:7696 です
tensor([ 2, 16383, 7049, ..., 449, 385, 3])
['[CLS]', 'メロ', '##ス', 'は', '激怒', 'し', 'た', '。',
7 # モデルに入力して出力を取得
8 with torch.no_grad():
----> 9 outputs = model(**inputs)
RuntimeError: The size of tensor a (7696) must match the size of tensor b (512) at non-singleton dimension 1
3. livedoor ニュースコーパスで分類をしてみる
今回もlivedoor ニュースコーパスを使ってファインチューニングしてみてみる。
データは以下から入手可能で、実行ファイルと同じ階層に解凍しておく
!wget "https://www.rondhuit.com/download/ldcc-20140209.tar.gz"
3-1. ニュースコーパスからデータフレームを作成
ファイルpathは以下のような感じの場合を想定(.の場所に実行ファイル)
./text/dokujo-tsushin/dokujo-tsushin-4778030.txt
import os
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import numpy as np
# Livedoorコーパスの抽出先フォルダ
extract_folder = "./"
def read_articles_from_directory(directory_path):
"""ディレクトリから記事を読み込む関数"""
# LICENSE.txt以外の全ファイルを取得
files = [f for f in os.listdir(directory_path) if f != "LICENSE.txt"]
articles = []
for file in files:
with open(os.path.join(directory_path, file), "r", encoding="utf-8") as f:
lines = f.readlines()
articles.append({
"title": lines[2].strip(),
"sentence": ''.join(lines[3:]).strip(),
"file": file
})
return articles
def read_category_from_directory(directory_path
"""LICENSE.txtからカテゴリ情報を取得する関数"""
with open(os.path.join(directory_path, "LICENSE.txt"), "r", encoding="utf-8") as f:
lines = f.readlines()
category = lines[-2].strip()
return category
# メインディレクトリを取得
directories = [d for d in os.listdir(os.path.join(extract_folder, "text"))
if d not in ["CHANGES.txt", "README.txt"]]
# 全てのデータフレームを格納するリスト
all_dfs = []
# 各ディレクトリからデータを読み込む
for directory in directories:
dir_path = os.path.join(extract_folder, "text", directory)
category = read_category_from_directory(dir_path)
articles = read_articles_from_directory(dir_path)
df = pd.DataFrame(articles)
df["category"] = category
all_dfs.append(df)
# 全てのデータフレームを結合
full_df = pd.concat(all_dfs, ignore_index=True)
# カテゴリを数値に変換(ラベルエンコード)
label_encoder = LabelEncoder()
full_df['category_id'] = label_encoder.fit_transform(full_df['category'])
# カテゴリとIDの対応関係を保存
category_mapping = dict(zip(label_encoder.classes_, label_encoder.transform(label_encoder.classes_)))
print("カテゴリとIDのマッピング:")
for category, idx in category_mapping.items():
print(f"{category}: {idx}")
# AIモデルへのinput用にタイトルと本文を結合したテキストを作成
full_df['text_for_bert'] = full_df['title'] + ' ' + full_df['sentence']
display(full_df.head(2))
カテゴリとIDのマッピング:
ITライフハック: 0
MOVIE ENTER: 1
Peachy: 2
Sports Watch: 3
livedoor HOMME: 4
エスマックス: 5
トピックニュース: 6
家電チャンネル: 7
独女通信: 8
| title | sentence | file | category | category_id | text_for_input | |
|---|---|---|---|---|---|---|
| 0 | 友人代表のスピーチ、独女はどうこなしている? | もうすぐジューン・ブライドと呼ばれる…… | dokujo-tsushin-4778030.txt | 独女通信 | 8 | 友人代表のスピーチ、独女はどうこなしている? もうすぐジューン・ブライドと呼ばれる…… |
| 1 | ネットで断ち切れない元カレとの縁 | 携帯電話が普及する以前、恋人への…… | dokujo-tsushin-4778031.txt | 独女通信 | 8 | ネットで断ち切れない元カレとの縁 携帯電話が普及する以前、恋人への…… |
3-2. トークン数も入れて比較してみる
検証なので、以下2モデルのトークン数もカラムに格納して可視化をしてみる
・ sbintuitions/modernbert-ja-130m
・ cl-tohoku/bert-base-japanese-v3
import torch
from transformers import AutoTokenizer
import matplotlib.pyplot as plt
import seaborn as sns
# トークナイザ
modernbert_tokenizer = AutoTokenizer.from_pretrained("sbintuitions/modernbert-ja-130m")
tohoku_tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v3")
# トークン数をカウントする関数
def count_tokens(text, tokenizer):
return len(tokenizer.encode(text))
full_df['modernbert_tokens'] = [count_tokens(text, modernbert_tokenizer) for text in full_df['text_for_input']]
full_df['tohoku_tokens'] = [count_tokens(text, tohoku_tokenizer) for text in full_df['text_for_input']]
print(f"ModernBERTの最大トークン数:{max(full_df['modernbert_tokens'])}")
print(f"東北大学BERTの最大トークン数:{max(full_df['tohoku_tokens'])}")
print(f"東北大学BERTで512トークンを超える記事数: {(full_df['tohoku_tokens'] > 512).sum()}")
display(full_df.head(1))
# グラフのスタイル設定
plt.style.use('ggplot')
sns.set(font='IPAexGothic')
fig, axes = plt.subplots(2, 1, figsize=(14, 10))
# ModernBERTのヒストグラム
sns.histplot(data=full_df, x='modernbert_tokens', ax=axes[0], bins=50, kde=True, color='blue')
axes[0].set_title('ModernBERT_tokens')
axes[0].set_xlabel('トークン数')
axes[0].set_ylabel('counts')
axes[0].legend()
# 東北大学BERTのヒストグラム
sns.histplot(data=full_df, x='tohoku_tokens', ax=axes[1], bins=50, kde=True, color='green')
axes[1].axvline(x=512, color='red', linestyle='--', alpha=0.7, label='BERT (512 tokens)')
axes[1].set_title('東北大BERT_v3_tokens')
axes[1].set_xlabel('トークン数')
axes[1].set_ylabel('counts')
axes[1].legend()
plt.tight_layout()
plt.show()
ModernBERTの最大トークン数:5061
東北大学BERTの最大トークン数:6689
東北大学BERTで512トークンを超える記事数: 4885
| title | sentence | file | category | category_id | text_for_input | modernbert_tokens | tohoku_tokens | |
|---|---|---|---|---|---|---|---|---|
| 0 | 友人代表のスピーチ、独女はどうこなしている? | もうすぐジューン・ブライドと呼ばれる…… | dokujo-tsushin-4778030.txt | 独女通信 | 8 | 友人代表のスピーチ、独女はどうこなしている? もうすぐジューン・ブライドと呼ばれる…… | 582 | 945 |
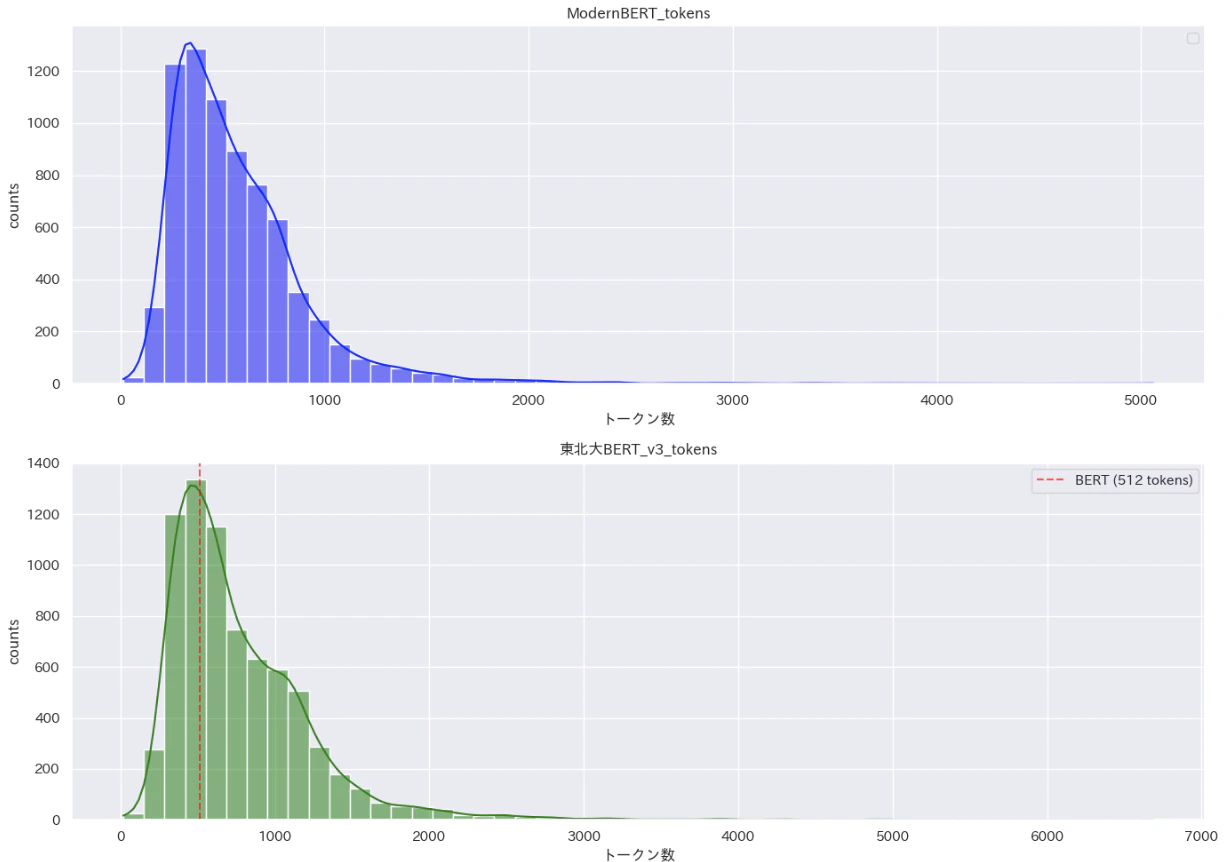
図を見るとわかるが、tohoku_BERTは512トークンまでしか入力できないので、約半分は全文を入れることができないことがわかる。なので、例えばタイトルだけを使用するとか、最初から512トークンまでを使うとか、文章分割しつつ入れるかの3択から選ぶことになる。
一方のModernBERTはこれ全文をそのまま使用できることになるので、その差は歴然である。
3-3. AI分類精度を比較(ModernBERT vs tohoku_BERT)
学習は各カテゴリから等しく7割を学習し、検証用で2割、精度確認用に残り1割を使用することにして9クラス分類の精度を比較することにする(パラメータ等はなるべくデフォルトに近いようにしたつもりです)
なお、ModernBERTの分類に関しては以下Notebookを参考にしてみました
https://colab.research.google.com/github/AnswerDotAI/ModernBERT/blob/main/examples/finetune_modernbert_on_glue.ipynb#scrollTo=oIWIz7qlfzBE
また、残念ながら手持ちのGPU(GeForce RTX 4070 Ti SUPER ※16GB)では8192トークンだと「CUDA out of memory」となる為、今回の検証では泣く泣く最大2048トークンとしました、なお東北大のはそのまま最大512トークンです
import os
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from tqdm import tqdm
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
DataCollatorWithPadding
)
import random
import gc
sns.set(font='IPAexGothic')
# シードを固定
def set_seed(seed_value=42):
"""シードを固定する関数"""
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
os.environ['PYTHONHASHSEED'] = str(seed_value)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
set_seed(42)
# GPU設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用デバイス: {device}")
# トークナイザーの並列処理を無効化
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# データ読み込み
extract_folder = "./"
def read_articles_from_directory(directory_path):
"""ディレクトリから記事を読み込む関数"""
files = [f for f in os.listdir(directory_path) if f != "LICENSE.txt"]
articles = []
for file in files:
with open(os.path.join(directory_path, file), "r", encoding="utf-8") as f:
lines = f.readlines()
articles.append({
"title": lines[2].strip(),
"sentence": ''.join(lines[3:]).strip(),
"file": file
})
return articles
def read_category_from_directory(directory_path):
"""LICENSE.txtからカテゴリ情報を取得する関数"""
with open(os.path.join(directory_path, "LICENSE.txt"), "r", encoding="utf-8") as f:
lines = f.readlines()
category = lines[-2].strip()
return category
# メインディレクトリを取得
directories = [d for d in os.listdir(os.path.join(extract_folder, "text"))
if d not in ["CHANGES.txt", "README.txt"]]
# 全てのデータフレームを格納するリスト
all_dfs = []
# 各ディレクトリからデータを読み込む
for directory in directories:
dir_path = os.path.join(extract_folder, "text", directory)
category = read_category_from_directory(dir_path)
articles = read_articles_from_directory(dir_path)
df = pd.DataFrame(articles)
df["category"] = category
all_dfs.append(df)
# 全てのデータフレームを結合
full_df = pd.concat(all_dfs, ignore_index=True)
# カテゴリを数値に変換
label_encoder = LabelEncoder()
full_df['category_id'] = label_encoder.fit_transform(full_df['category'])
# BERTモデル用にタイトルと本文を結合したテキストを作成
full_df['text_for_input'] = full_df['title'] + ' ' + full_df['sentence']
# カテゴリ情報
id2label = {idx: label for idx, label in enumerate(label_encoder.classes_)}
label2id = {label: idx for idx, label in id2label.items()}
print(f"データセットサイズ: {len(full_df)}")
print(f"カテゴリ数: {full_df['category'].nunique()}")
print("\nカテゴリごとの記事数:")
print(full_df['category'].value_counts())
print("\nカテゴリとIDのマッピング:")
for category, idx in label2id.items():
print(f"{category}: {idx}")
# カテゴリごとに均等にデータを分割
# 学習:検証:テスト = 7:2:1
train_dfs = []
val_dfs = []
test_dfs = []
# バランスよくカテゴリを分けて分割
for category in full_df['category'].unique():
category_df = full_df[full_df['category'] == category]
# まず学習データと残りのデータを分割
train_category, temp_category = train_test_split(
category_df, train_size=0.7, random_state=42
)
# 残りのデータを検証データとテストデータに分割(検証:テスト = 2:1)
val_category, test_category = train_test_split(
temp_category, train_size=2/3, random_state=42
)
train_dfs.append(train_category)
val_dfs.append(val_category)
test_dfs.append(test_category)
# 分割したデータを結合
train_df = pd.concat(train_dfs, ignore_index=True)
val_df = pd.concat(val_dfs, ignore_index=True)
test_df = pd.concat(test_dfs, ignore_index=True)
print(f"\n学習データサイズ: {len(train_df)}")
print(f"検証データサイズ: {len(val_df)}")
print(f"テストデータサイズ: {len(test_df)}")
# データセットクラス
class LivedoorDataset(Dataset):
"""Livedoorコーパス用のデータセットクラス"""
def __init__(self, texts, labels, tokenizer=None, max_length=512):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = int(self.labels[idx])
if self.tokenizer:
# トークン化済みデータを返す
encoding = self.tokenizer(
text,
max_length=self.max_length, # 最大長
padding="max_length", # 最大長までパディング
truncation=True, # 最大長を超える場合は切り詰める
return_tensors="pt"
)
# バッチ次元を削除([1, n] → [n])
item = {key: val.squeeze(0) for key, val in encoding.items()}
# ラベルをテンソルに変換
item['labels'] = torch.tensor(label, dtype=torch.long)
return item
else:
# 生テキストとラベルを返す
return {"text": text, "label": label}
# 評価メトリクスの計算関数
def compute_metrics(eval_pred):
"""評価メトリクスを計算する関数"""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
accuracy = accuracy_score(labels, predictions)
f1 = f1_score(labels, predictions, average='weighted')
return {
'accuracy': accuracy,
'f1': f1
}
# 混同行列を可視化する関数
def plot_confusion_matrix(y_true, y_pred, class_names, title, accuracy, f1):
"""混同行列を可視化する関数"""
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(
cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names,
yticklabels=class_names
)
plt.title(f"{title} (正解率: {accuracy:.4f}, F1: {f1:.4f})")
plt.ylabel('正解ラベル')
plt.xlabel('予測ラベル')
plt.tight_layout()
plt.show()
return cm
# トレーニング関数
def train_and_evaluate_model(model_name, train_df, val_df, test_df, num_labels, output_dir):
"""モデルのトレーニングと評価を行う関数"""
print(f"\n============= {model_name} 検証 =============")
# トークナイザーとモデルのロード
tokenizer = AutoTokenizer.from_pretrained(model_name)
# モデル名に応じてmax_lengthを設定(modernbertはGPU限界の2048とする)
max_length = 2048 if "modernbert" in model_name.lower() else 512
# データセット作成(train/val/test)
train_dataset = LivedoorDataset(
train_df['text_for_input'].values,
train_df['category_id'].values,
tokenizer,
max_length=max_length
)
val_dataset = LivedoorDataset(
val_df['text_for_input'].values,
val_df['category_id'].values,
tokenizer,
max_length=max_length
)
test_dataset = LivedoorDataset(
test_df['text_for_input'].values,
test_df['category_id'].values,
tokenizer,
max_length=max_length
)
# 分類モデルのロード
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels,
id2label=id2label,
label2id=label2id
)
# 「modernbert」がモデル名に含まれてるか否か判断(以下分岐用)
is_modernbert = "modernbert" in model_name.lower()
# トレーニング設定
training_args_dict = {
"output_dir" : output_dir, # 出力dir
"learning_rate" : 8e-5 if is_modernbert else 5e-5, # 学習率(modernBERTとtohokuで分けてる)
"per_device_train_batch_size" : 8 if is_modernbert else 16, # 学習バッチサイズ(modernBERTとtohokuで分けてる)
"per_device_eval_batch_size" : 8 if is_modernbert else 16, # 評価バッチサイズ(modernBERTとtohokuで分けてる)
"num_train_epochs" : 3, # epoch数
"weight_decay" : 8e-6 if is_modernbert else 0.01, # 重みの減衰率 正則化パラメータ(modernBERTとtohokuで分けてる)
"adam_beta1" : 0.9, # Adamオプティマイザ 一次モーメント推定係数
"adam_beta2" : 0.98 if is_modernbert else 0.999, # Adamオプティマイザ 二次モーメント推定係数(modernBERTとtohokuで分けてる)
"adam_epsilon" : 1e-6, # Adamオプティマイザの数値安定性
"lr_scheduler_type" : "linear", # 学習率のスケジューリング方法(線形)
"warmup_ratio" : 0.1, # ウォームアップ期間のトレーニング比率(最初の10%のステップで学習率を0から設定値まで徐々に上げる)
"logging_strategy" : "epoch", # ログを記録するタイミング(Epoch毎)
"evaluation_strategy" : "epoch", # 検証データでの評価タイミング(Epoch毎)
"save_strategy" : "epoch", # モデルの保存(Epoch毎)
"load_best_model_at_end" : True, # トレーニング終了時に最良のモデルをロード
"metric_for_best_model" :"f1", # 「最良」のモデルを判断するメトリクス(F1スコア)
"push_to_hub": False, # Hugging Face Hubにモデルをアップロードしない
"seed": 42, # シード値の設定
"data_seed": 42, # データシャッフルのシード値
}
# ModernBERTの場合のみ追加設定を適用(でないと動かなかったので)
if is_modernbert:
training_args_dict.update({
"bf16": True, # BFloat16(16ビット浮動小数点数)精度を使用
"bf16_full_eval": True, # (評価)BFloat16精度を使用
"gradient_accumulation_steps": 2, # 勾配累積(8×2=16の実効バッチサイズ)
})
# TrainingArgumentsインスタンスを作成
training_args = TrainingArguments(**training_args_dict)
# データコレータ(各バッチごとに動的パディングで最適なパディングを行いながらデータを処理)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# Trainerの初期化
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
# モデルのトレーニング
trainer.train()
# 学習未使用のテストデータでの評価
test_results = trainer.evaluate(test_dataset)
print(f"\nテスト結果: {test_results}")
# テストデータの予測と混同行列
predictions = trainer.predict(test_dataset)
pred_labels = np.argmax(predictions.predictions, axis=1)
true_labels = predictions.label_ids
# 混同行列
accuracy = test_results['eval_accuracy']
f1 = test_results['eval_f1']
cm = plot_confusion_matrix(
true_labels,
pred_labels,
label_encoder.classes_,
f"{model_name.split('/')[-1]}混同行列",
accuracy,
f1
)
# メモリ解放(連続推論をする為)
del model, trainer
torch.cuda.empty_cache()
gc.collect()
return test_results, cm, true_labels, pred_labels
# ModernBERTの検証
modernbert_results = train_and_evaluate_model(
"sbintuitions/modernbert-ja-130m",
train_df,
val_df,
test_df,
len(label_encoder.classes_),
"./modernbert_livedoor_output"
)
# 東北大学BERTの検証
tohoku_results = train_and_evaluate_model(
"cl-tohoku/bert-base-japanese-v3",
train_df,
val_df,
test_df,
len(label_encoder.classes_),
"./tohokubert_livedoor_output"
)
# 結果の比較
modernbert_accuracy = modernbert_results[0]["eval_accuracy"]
tohoku_accuracy = tohoku_results[0]["eval_accuracy"]
modernbert_f1 = modernbert_results[0]["eval_f1"]
tohoku_f1 = tohoku_results[0]["eval_f1"]
print("\n=========== モデル比較結果 ===========")
print(f"ModernBERT精度: {modernbert_accuracy:.4f}")
print(f"東北大学BERT精度: {tohoku_accuracy:.4f}")
print(f"ModernBERT F1スコア: {modernbert_f1:.4f}")
print(f"東北大学BERT F1スコア: {tohoku_f1:.4f}")
※print出力結果は省略
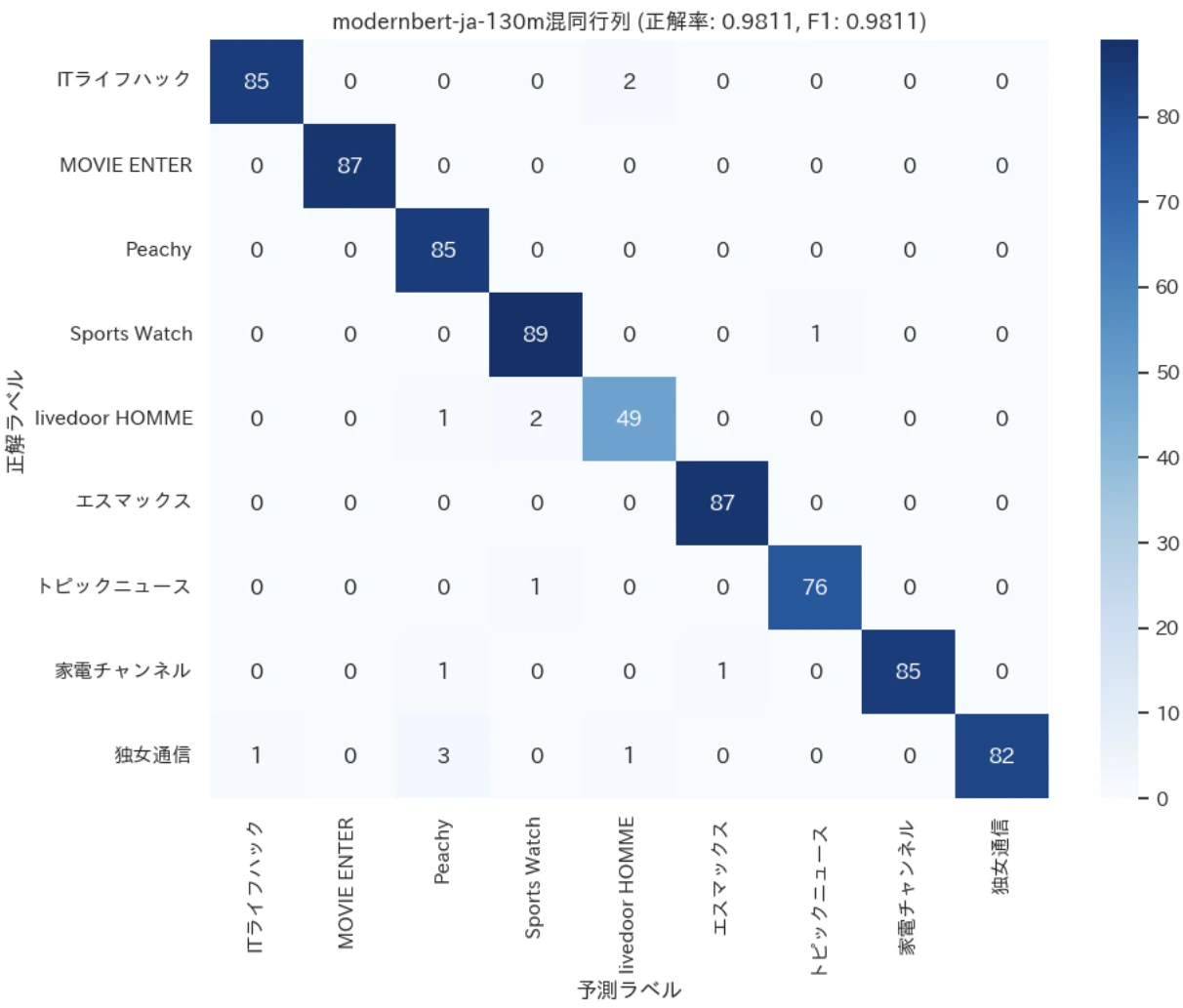
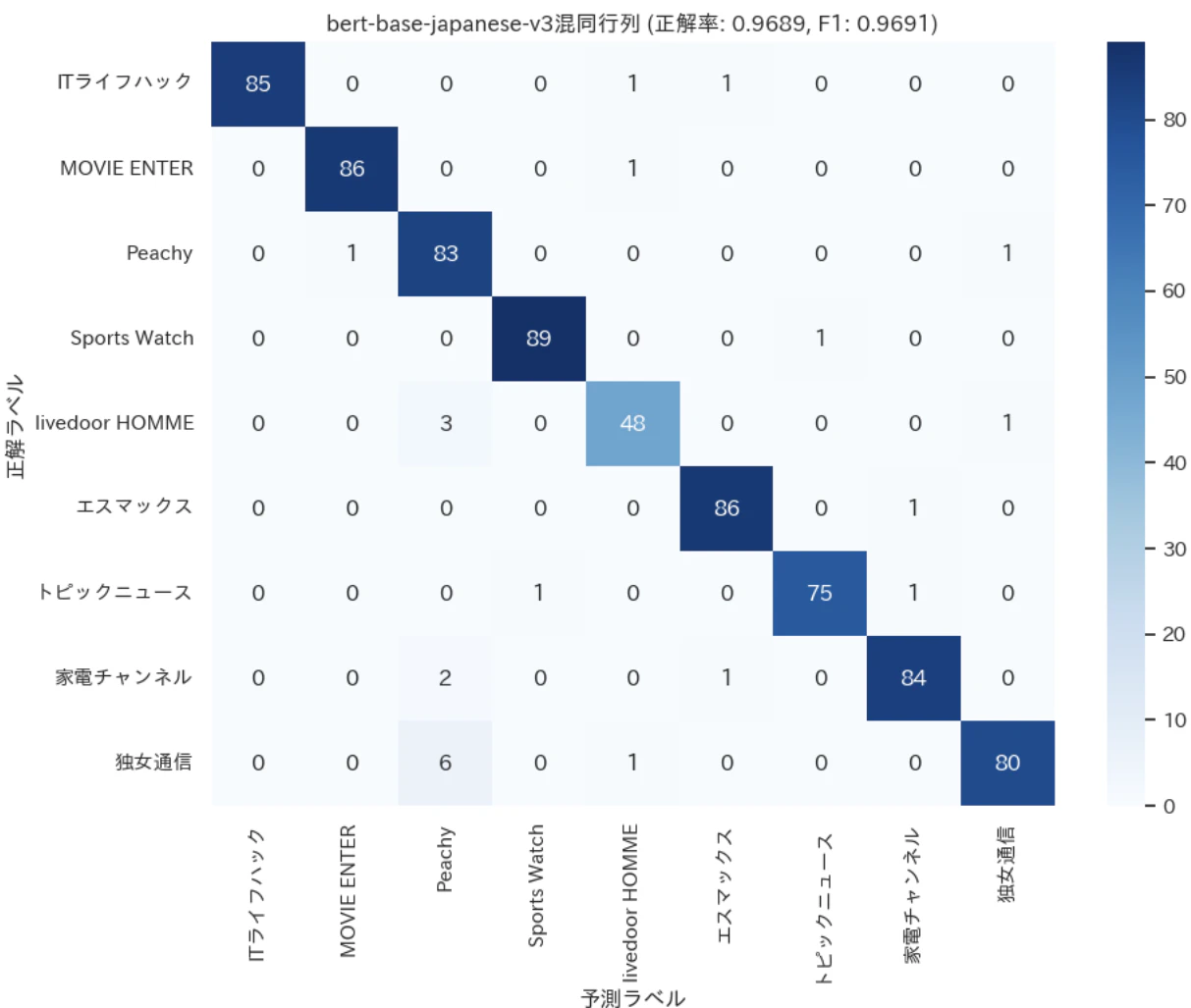
結果は図で示すように僅差でModernBERTの勝利となったが、東北大のBERTも先頭512トークンの使用だけでも分類では十分強いんだなと改めて感じました
(この僅差が2048トークンのおかげなのか、ModernBERTの性能でこの差が出ているのかは検証してませんが、GPUメモリがあれば面倒な前処理なしで使えるのはやはりいいですね)
4. おわりに
英語であればlongformer等があったが、日本語モデルだと今まで512トークンが最大入力だったので、今回SB Intuitionsさんが日本語モデルを出してもらったのはとても嬉しく思ったし、DecoderだけでなくEncoder関連も盛り上がってくれることを願います
参考記事