DataFrameの形の変換
seabornでFigにする際に有用。
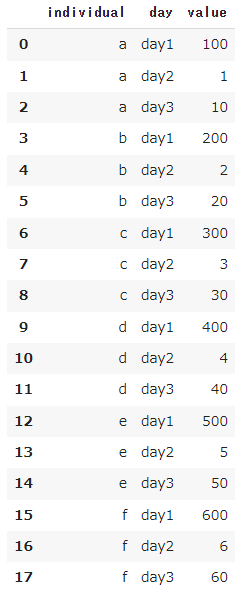
df = df.stack().reset_index()
df = pd.DataFrame({'day1': [100, 200, 300, 400, 500, 600],
'day2': [1, 2, 3, 4, 5, 6],
'day3': [10, 20, 30, 40, 50, 60]})
df.index=['a', 'b', 'c', 'd', 'e', 'f']
df

df = df.stack().reset_index()
df
配列からデータラベルを作る方法
import numpy as np
group = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2]
group = np.array(group, dtype='int64')
labels = np.array(['A', 'B', 'C'])[group]
print(labels)
['A' 'A' 'A' 'A' 'A' 'B' 'B' 'B' 'B' 'B' 'C' 'C' 'C' 'C' 'C']
文字列から条件に合う文字列を抽出する
findall()は全ての一致部分をリストで返す。
import re
text = '[りんご][ゴリラ][ラッパ][パンツ]'
# そのまま抽出する
print(re.findall('\[(.*?)\]', text))
# コンパイルしてから抽出する。結果は同じ。
p = re.compile('\[(.*?)\]') #抽出指定:開始[ 終了] 非貪欲マッチ*?
print(p.findall(text))
['りんご', 'ゴリラ', 'ラッパ', 'パンツ']
乱数の生成
np.random.default_rng()でGeneratorインスタンスを生成。
.integers()で整数の乱数、.uniform()でfloatになる
条件を指定して乱数を生成。
第一引数low
第二引数high
第三引数size
出力はlow以上high未満になる。
引数endpointをTrueにすると以上・以下になる。(.integers()のみ)
rng = np.random.default_rng()
print(rng.integers(40,100))
# 53
print(rng.integers(100))
# 87
print(rng.integers(40, 100, size=3))
# [71 47 40 60]
print(rng.integers(40, 100, size=(3,2)))
# [[86 76]
# [54 71]
# [58 90]]