はじめに
弊社では、ビッグデータ分析のためにAWSのクエリサービスAmazon Athenaをよく利用しています。
簡単に使い始めることができて、本当に便利なサービスです。
SQL on Hadoopでは、パーティション数が多くなりすぎるとクエリ実行時間が長くなるので、 「パーティションの数は多くとも1万個くらいに抑えましょう」という定石があります1。
一方、Athenaではクエリ実行時に、スキャンしたデータ量に応じて $5/1TB 課金されます。パーティションを細分化しておけば、スキャンするデータ量が削減できます。
結局のところ、パーティションをどれくらい細分化すれば良いかは、定石だけではわかりません。
さて、我々のシステムでは、次々と送られてくる発生するログをS3に配置し、EMRで日次ETL処理した結果をAthenaで分析・集計します。
クエリ対象期間は1週間固定であるにもかかわらず、日に日にクエリが遅くなってきました。
そこで調査したところ、パーティション保持数がパフォーマンスに影響を与えているようなので、実験をした記録です。
実験からわかったこと
パーティション保持数が一定以上大きくなりすぎると、パフォーマンスが悪くなります。
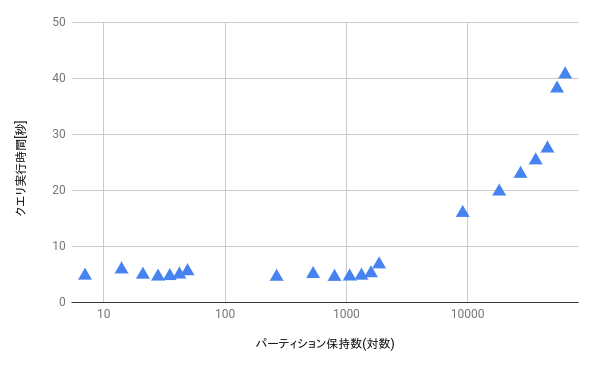
パーティション保持数が10,000弱からクエリ実行時間が長くなっていることが分かります。10,000という数字は環境によると思うので、参考程度に思っておいてください。
実験の概要
実験の対象は、概算集計用に1/100でサンプリングしたアクセスログテーブルです。
期間を指定したクエリなので、year/month/dayのパーティションは必須です。
保持期限は 1[週間] 〜 7[週間]の7種類を用意しました。
パーティション保持数とクエリ実行時間の影響を計測するために保持期限をさらに長くできれば良いのですが、データの都合で8週以上のデータをロード出来ませんでした。
そのため、パーティション設計を変更することでパーティション保持数を大幅に増やしています。
パーティション保持数[パーティション] = 保持期間[日] \times \textrm{(year/month/day)}以降のパーティション数[パーティション/日]
パーティション設計として以下の3種類を用意しました。
今回の実験で利用するクエリはアクセスログから特定のURL群のレコード群を取り出すクエリです。
そのため、URLに関するパーティションを追加することで、スキャンするデータ量を削減できます。
実験対象テーブル
下記の3テーブルはEMR上のhiveでdynamic partitionを利用してデータをinsertしています。
year/month/dayパーティションのテーブル
CREATE EXTERNAL TABLE `access_log_daily_sampling_ymd`(
`uid` bigint,
`time` bigint,
`url` string,
`domain` string)
PARTITIONED BY (
`year` string,
`month` string,
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://hoge-bucket/fuga-prefix/'
TBLPROPERTIES (
'parquet.compress'='SNAPPY',
'transient_lastDdlTime'='**********')
year/month/day/domain5文字目パーティションのテーブル
CREATE EXTERNAL TABLE `access_log_daily_sampling_ymddomain5`(
`uid` bigint,
`time` bigint,
`url` string,
`domain` string)
PARTITIONED BY (
`year` string,
`month` string,
`day` string,
`domain_5th_char` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://hoge-bucket/fuga-prefix/'
TBLPROPERTIES (
'parquet.compress'='SNAPPY',
'transient_lastDdlTime'='**********')
year/month/day/domain56文字目パーティションのテーブル
CREATE EXTERNAL TABLE `access_log_daily_sampling_ymddomain56`(
`uid` bigint,
`time` bigint,
`url` string,
`domain` string)
PARTITIONED BY (
`year` string,
`month` string,
`day` string,
`domain_5and6th_char` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://hoge-bucket/fuga-prefix/'
TBLPROPERTIES (
'parquet.compress'='SNAPPY',
'transient_lastDdlTime'='**********')
データ容量
今回実験で利用するデータ容量/ファイル数を集計しました。
for d in 14 15 16 17 18 19 20; do
echo 2018/10/${d}
aws s3 ls s3://hoge-bucket/fuga-prefix/year=2018/month=10/day=${d} --summarize --recursive --human-readable| tail -n 1
done
2018/10/14
Total Size: 737.2 MiB
2018/10/15
Total Size: 767.8 MiB
2018/10/16
Total Size: 751.1 MiB
2018/10/17
Total Size: 754.6 MiB
2018/10/18
Total Size: 732.7 MiB
2018/10/19
Total Size: 708.7 MiB
2018/10/20
Total Size: 687.6 MiB
実験内容
ALTER TABLE ADD PARTITIONなどでパーティション保持期間[日]を変更し、以下のクエリを3回実行し平均時間を計測しグラフ化します。
year/month/dayパーティションのテーブル用クエリ
WITH
tmp1 AS (
select t1.uid as uid
from access_log_daily_sampling_ymd t1
join (select domain_5th_char, domain, url from urls) t2
on t1.url = t2.url
where concat(t1.year,t1.month,t1.day) between '20181014' and '20181020'
group by t1.uid
),
tmp2 AS (
select distinct tmp1.uid
from tmp_kw_core
)
SELECT COUNT(uid) * 100
from tmp2;
year/month/day/domain5文字目パーティションのテーブル用クエリ
WITH
tmp1 AS (
select t1.uid as uid
from access_log_daily_sampling_ymddomain5 t1
join (select domain_5th_char, domain, url from urls) t2
on t1.domain_5th_char = t2.domain_5th_char and t1.url = t2.url
where concat(t1.year,t1.month,t1.day) between '20181014' and '20181020'
group by t1.uid
),
tmp2 AS (
select distinct tmp1.uid
from tmp_kw_core
)
SELECT COUNT(uid) * 100
from tmp2;
year/month/day/domain56文字目パーティションのテーブル用クエリ
WITH
tmp1 AS (
select t1.smn_uid as uid
from access_log_daily_sampling_ymddomain56 t1
join (select domain_5and6th_char, domain, url from urls) t2
on t1.domain_5and6th_char = t2.domain_5and6th_char and t1.url = t2.url
where concat(t1.year,t1.month,t1.day) between '20181014' and '20181020'
group by t1.uid
),
tmp2 AS (
select distinct tmp1.uid
from tmp_kw_core
)
SELECT COUNT(uid) * 100
from tmp2;
urlsテーブルは下記のような内容で、100行のテーブルです。
| url | domain | domain_5th_char | domain_5and6th_char |
|---|---|---|---|
| http://www.domain1.com/ | www.domain1.com | d | do |
| http://domain2.co.jp/ | domain2.co.jp | i | in |
まとめ
- Athenaでは、パーティション数を増やすとコストが抑えられるがクエリが遅くなる。
- クエリ速度に問題がある場合には、パーティション設計を見直しましょう。
-
https://community.hortonworks.com/questions/2517/maximum-hive-table-partitions-allowed-recommended.html ↩
-
アクセスログの中から特定のURLへの接触ログだけを抽出するクエリを多く実行するため、url文字列を活用したパーティションを追加しています。ドメインは
www.で始まることが多いため、ドメインの1~4文字目でパーティションを切ると、パーティション間で偏りが生じます。そのため、今回の実験ではドメインの5,6文字目をパーティションとしています。 ↩ ↩2