はじめに
ソネット・メディア・ネットワークスでは、2017年12月に新サービスVALIS-Cockpitをリリースしました。弊社のデータサイエンティストが開発した分析手法をパッケージ提供し、広告主企業のマーケターが各種分析を利用できるサービスです。
VALIS-Cockpit開発チームでは、データサイエンティストチームが作った分析用のソースコードを、安定的に提供できるようブラッシュアップしています。その中で、アドホック分析としては問題ないが、製品としてリリースすると確率的に問題が発生するソースコードに出会ったのでこの場で紹介します。
pandas.read_csv(pd.read_csv)
アドホックな分析で良く使う pd.read_csv ですが、製品として使うには厄介な存在です。
問題が起きないパターン
よく有るのは下記のようなcsvファイルです。
$ cat sample1.csv
col1,col2,col3
1,2,3
4,5,6
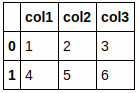
このファイルであれば、オプションの指定なしで、何も考えなくてもcsvファイルを読み込むことが出来ます。
import pandas as pd
df = pd.read_csv('sample1.csv')
df.head()
問題が起きるパターン
では、次のようなファイルはいかがでしょうか。先程の sample1.csv に加えて1行分のデータが加わりました。しかし、col2については欠損値となっています。前工程のファイル出力の仕様が雑だと、0 という値が欠損値として出力されたりします。
$ cat sample2.csv
col1,col2,col3
1,2,3
4,5,6
7,,9
同様のコードでcsvファイルを読み込んでみましょう。
import pandas as pd
df = pd.read_csv('sample2.csv')
df.head()
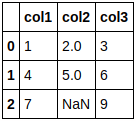
col2の型が変わっています。df.dtypesを参照するとわかりますが、int64 から float64 に変わっていることがわかります。読み込むデータによって型が異なると、その後の様々な処理結果も変わってしまいます。そのため、製品版のコードにする際には、様々なデータが入力されることを想定し、欠損値を含むデータであっても想定通りの型として読み込むべきです。
問題の有る対策方法
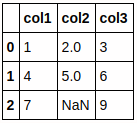
import pandas as pd
import numpy as np
df = pd.read_csv('sample.csv', dtype={'col1':np.int64, 'col2':np.int64, 'col3':np.int64})
df.head()
一見、これでうまく行きそうに見えますが、これでもだめです。col2は float64 になっています。
正しい対策方法
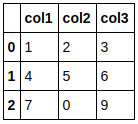
integerのカラムとして扱うためには以下のように、明示的に変換してあげる必要があります。fillnaがないと、ValueError: Cannot convert NA to integer って怒られてしまいます。
import pandas as pd
import numpy as np
df = pd.read_csv('sample.csv')
df['col2'] = df['col2'].fillna(0).astype(np.int64)
df.head()
まとめ
pd.read_csv を製品版ソースで利用する場合には以下のことに気をつけましょう。
- 各カラムのデータ型はなにか?
- 各カラムに欠損値を含む可能性はあるか?
- 各工程の入出力ファイルの仕様を明確にする(特に欠損値処理)。