はじめに
研究開発の一環で、PDFからできるだけ正確にテキストデータを抽出する必要がでてきた。
今回はDoclingを使ってテキスト化してみたので、せっかくなので作業記録として残してみる。
尚、テキストはマークダウン形式で出力する。
Doclingを試そうと思った経緯
過去にもPDFからのテキスト抽出したことがあり、その際にはPython+PyMuPDF4LLMライブラリで問題なく抽出できていたが、今回扱うことになったPDFの内容によるものなのか、以下のような現象が見られた。
※サンプルとして、EDINETのPDFドキュメントを使用
【入力PDF】
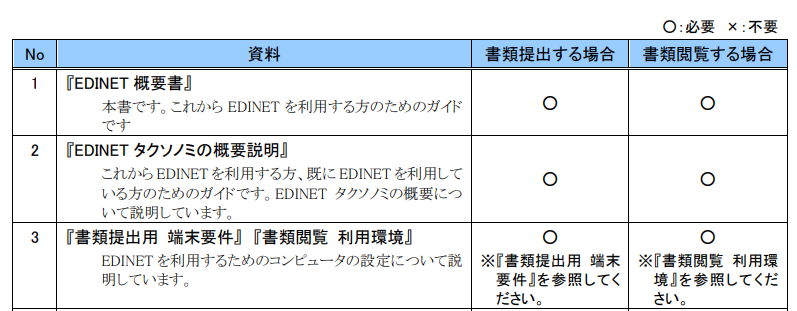
【出力マークダウン(PyMuPDF4LLM使用)】

どうもドキュメント内の表まわりにて、表以外の部分がラベルと認識されたり、本来のラベルの文字列ではなく「col1,col2...」などの表記になっている箇所が散見された。
PyMuPDF4LLMライブラリのパラメータ等で対応できればそれがよかったが、いくつかパラメータをいじったりしてみたものの、解決には至らなかった。
そうこうしている折、Doclingというものがあることを知った。
そもそもDoclingとは何者?
Doclingがどのようなものか調べたところ、どうやら以下のようなものらしい。
- ドキュメントの解析と変換に特化したオープンソースのPythonパッケージ
- PDF、DOCX、PPTX、HTML、画像などの多様なドキュメント形式を解析し、MarkdownやJSON形式に変換
- 最先端のAIモデルを活用して、ページレイアウトの解析や表構造の認識など、高度なPDF理解を実現
- OCRサポートしており、スキャンしたPDFや画像の文字からテキスト抽出が可能
- 簡便なコマンドラインインターフェースで実行することも可能
上記の中で、とりわけAIモデルを活用しているという点に魅力を感じた。
ものにもよるが、確かにPDF等のドキュメントでは、人が見れば「ここは折り返しているけど文章が続いているな」「ここは罫線がないけど表の形式だな」のように判断できるが、俯瞰して見たらそれぞれ「複数行のテキスト」「間に空白が空いているだけの文章」のようにも見える訳で、AIを活用するのは効果がありそう。
あとは単純にAIと言うだけで最先端という感じがして良い(?)
試行錯誤したときのPythonコード
コマンドラインインターフェースが使用できるらしいが、今後の研究開発のことも考えPythonコードで書くことにした。
仕様としては、source_pathに格納されているPDFファイル全てに対して、マークダウンに変換してそれぞれ別ファイルとして保存する。
import os
from pathlib import Path
from docling.document_converter import DocumentConverter
from docling.datamodel.base_models import InputFormat
from docling.document_converter import (
DocumentConverter,
PdfFormatOption,
WordFormatOption,
)
from docling.pipeline.simple_pipeline import SimplePipeline
from docling.pipeline.standard_pdf_pipeline import StandardPdfPipeline
from docling.backend.pypdfium2_backend import PyPdfiumDocumentBackend
from docling.datamodel.pipeline_options import (
EasyOcrOptions,
PdfPipelineOptions,
TableFormerMode,
)
def main():
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
# Any of the OCR options can be used:EasyOcrOptions, TesseractOcrOptions, TesseractCliOcrOptions, OcrMacOptions(Mac only), RapidOcrOptions
ocr_options = EasyOcrOptions(lang=["ja"])
# ocr_options = EasyOcrOptions(force_full_page_ocr=True, lang=["ja"])
pipeline_options.ocr_options = ocr_options
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
## for defaults use:
# doc_converter = DocumentConverter()
## to customize use:
doc_converter = (
DocumentConverter( # all of the below is optional, has internal defaults.
allowed_formats=[
InputFormat.PDF,
InputFormat.IMAGE,
InputFormat.DOCX,
InputFormat.HTML,
InputFormat.PPTX,
InputFormat.ASCIIDOC,
#InputFormat.CSV,
InputFormat.MD,
], # whitelist formats, non-matching files are ignored.
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_cls=StandardPdfPipeline, backend=PyPdfiumDocumentBackend, pipeline_options=pipeline_options
),
InputFormat.DOCX: WordFormatOption(
pipeline_cls=SimplePipeline
),
},
)
)
# カレントディレクトリ変更
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# テキスト抽出対象ファイルのパス
source_path = "../dat/source/pdf"
# 抽出したtextを保存するフォルダ
extract_path = "../dat/extract/md"
# ファイルリストをフルパスで取得
full_paths = [os.path.join(source_path, file) for file in os.listdir(source_path) if file.endswith(".pdf")]
# 複数ファイルについて、変換処理を一括実行
conv_results = doc_converter.convert_all(full_paths)
for res in conv_results:
out_path = extract_path
print(
f"Document {res.input.file.name} converted."
f"\nSaved markdown output to: {out_path}"
)
# マークダウンとして出力
with (Path(out_path) / f"{res.input.file.stem}.md").open("w") as fp:
fp.write(res.document.export_to_markdown())
if __name__ == "__main__":
main()
試行錯誤の過程で、文字化けでまったく読めない文章になってしまったり、漢字が繁体字になってしまったりと苦戦しつつも、なんとか安定して出力することに成功。苦戦した際の設定値やコードなどは割愛する。
読み込ませるPDFの内容にもよると思うが、出力結果に主に影響を与えるパラメータは以下。
| パラメータ | 説明 | コメント |
|---|---|---|
| do_ocr | OCR機能を使うかどうか | 使った方が精度が向上したためTrueを設定 |
| force_full_page_ocr | OCRに設定するパラメータ(全ページOCRスキャンを強制) | 指定すると文章が途中で途切れてしまったためOFF(指定なし) |
| lang | OCRに設定するパラメータ(言語) | 今回扱うPDFは日本語でかつ指定しないと文字化けしたので"ja"を指定 |
| do_table_structure | テーブル構造を保存 | OFFにすると、テーブルがあからさまに崩れてしまったためTRUEを指定 |
問題となっていた表まわりについてはそれなりに綺麗にマークダウン化することができた。
【入力PDF】
【出力マークダウン(Docling使用)】
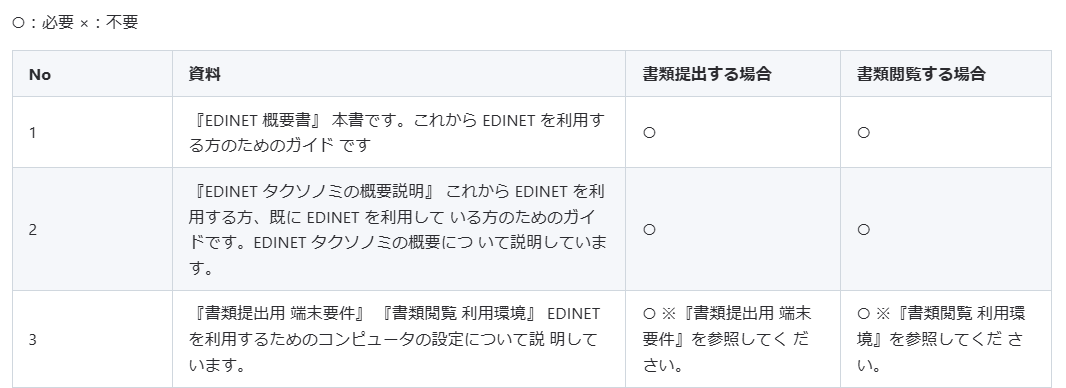
また、以下の通り、表以外の文章についても、問題なくテキスト化できている印象。
細かい点ではあるが、PDF上で改行されている文章が、マークダウン化したあとの文章では一文として扱われている点にも感動している。
※PyMuPDF4LLMの場合は、PDFの見た目の通り、文章の途中に改行ありで出力されていた。
【入力PDF】

【出力マークダウン(Docling使用)】

課題など
【処理性能について】
やはりDoclingで一番ネックになりそうなのは、処理性能だと思われる。
PDFの内容や文章量にもよると思うが、PyMuPDF4LLMでは1ページあたり0.5秒程度なのに対し、Doclingでは1ページあたり10秒程度かかる。
数ページ処理する分には気にならないが、これが100ページ1000ページとなると話は変わってくる。
まだ調査できていないが、スレッド数を上げて処理性能を上げることができるらしいので、どれくらい性能が改善するかや、性能が上がる条件などについて今後調査してみたい。
【実行環境差異】
一部のPDFにおいて、Windows上で直接Pythonを実行したときと、WSL上のPythonから実行したときとで、出力結果が異なるという結果になった。
※前者の方が、よりPDFに近い形で出力された。
本現象が発生する条件や、回避可能かどうかも含めて今後調査してみたい。
おわりに
PyMuPDF4LLMのようなシンプルなライブラリと比べて、設定やチューニング周りで手がかかった印象だが、最終的には前者よりも綺麗にテキスト化できたので、満足なアウトプットができた。
ただし、前述の課題などは残っているため、それらとも向き合って、今後の研究開発にも活かしていきたい。