Pandasの基本的な使い方の一覧をメモしておきます
Pythonを使って機械学習関連の作業を行う上で必ず必要になるPandasですが、度々使い方を忘れてしまうので、頻繁に使う機能の使い方をメモしておきました。今後Pandasを使用して覚えた操作は別の記事として更新していきたいと思います。Pandasを使い始めた方や、ちょこっと操作を調べたい方の参考になれば嬉しいです。
初心者の覚書ですので、内容に誤りのある可能性があります。誤りを発見された場合はご連絡して頂けますと幸いでございます。
動作環境
- python 3.7.4
- pandas 0.24.0
記事で紹介している操作内容
本記事に記載には以下の操作方法が記載してあります。
- Pandasの基本操作
- ライブラリのインポート
- csvファイルを読み込む
- csvファイルに書き出す
- データの型を確認する
- データ数を表示する
- 欠損データの数を確認する
- データの基本統計量を確認する
- カテゴリデータに対してone-hot-encodingを行う
- ラベルとデータを追加する
- ラベルを削除する
- 欠損データを指定値で埋める
- Pandasを便利に使う
- 条件を指定してデータを抽出する
- 条件を指定してデータを変更する ※warningが出ているので改善の必要ありです。
- groupbyでグループに対して処理を実施する
まとめ
Pandasで自分がよく使っている機能をまとめました。ただし、以下については一応動作しているものの、まだモヤっとした理解で使用しているので、別の機会に調べてまとめることにします。
1. Pandasの基本操作
<ライブラリのインポート>
Pandasのライブラリをインポートします。
import pandas as pd
<csvファイルを読み込む>
read_csvメソッドを使用してcsvファイルをDataFrameオブジェクトとして読み込みます。今回は、作業ディレクトリにある"student.csv"というファイルを読み込んでいます。
data = pd.read_csv("student.csv")
display(data.head(5))
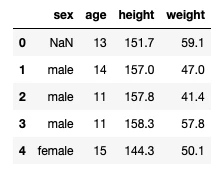
[補足1:ヘッダーの無いcsvを読み込む場合]
csvファイルにヘッダー("sex", "age", "height", "weight")が含まれて無い場合には、1つ目のデータ(NaN, 13, 151.7, 59.1)がヘッダーとして読み込まれてしまうので、header=Noneを指定します。
<csvファイルに書き出す>
DataFrameオブジェクトをcsvファイルに書き出すには、to_csvメソッドを使用します。例では、作業ディレクトリに"student_out.csv"というファイル名で保存しています。
data.to_csv("student_out.csv", index=False)
保存した際にindex(データのラベル)が保存されることを避けるためにindex=Falseを指定します。何の事かわからない場合は、index=Falseが無い状態で生成されたcsvファイルを確認して頂けるとわかると思います。
<データの型を確認する>
DataFrameに含まれるデータの型を確認するには、 DataFrameオブジェクトのdtypes 属性を確認します。
display(data.dtypes)
結果は以下となります。

ラベル毎のデータ型を取得するには以下のようにします。
display(data["age"].dtype )
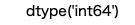
<データ数を表示する>
データ数を表示するにはcountメソッドを使用します。データ数は1000ですが、欠損データはカウントされないので"sex"は1000より小さい値になっています。
display(data.count())

[補足1:ラベル毎のデータ数を取得する]
ラベル毎のデータ数を取得する場合は以下のようにします。
display(data["sex"].count())
<欠損データの数を確認する>
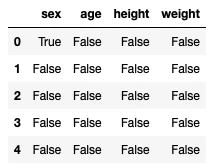
欠損データ数を確認するには、isnullメッソッドとsumメソッドを使用します。
display(data.isnull().sum())

[補足1:isnullメソッドの動作]
公式ドキュメントによると、isnullメソッドはDataFrameオブジェクトのデータのうちNoneとnumpy.NaNをTrue、それ以外をFalseとした、元のDataFrameと同じサイズのDataFrameオブジェクトを返します。
display(data.isnull().head(5))
[補足2:sumメソッドの動作]
sumメソッドは指定した軸(axis)方向の合計値を返します。PythonではTrueは1、Falseは0と扱われるので、合計値がTrueの数(欠損データの数)となります。以下は参考4からの引用となります。引用はPython3.8.1ですが、他のverでも同じだと思います。。。多分。。。確認していませんが。。。
ブール値は二つの定数オブジェクト False および True です。これらは真理値を表すのに使われます (ただし他の値も偽や真とみなされます)。 **数値処理のコンテキスト (例えば算術演算子の引数として使われた場合) では、これらはそれぞれ 0 および 1 と同様に振舞います。**任意の値に対して、真理値と解釈できる場合、組み込み関数 bool() は値をブール値に変換するのに使われます (上述の 真理値判定 の節を参照してください)。
[参考]
- Pandas公式ドキュメント isnull()
- Pandas公式ドキュメント sum()
- note.nkmk.me pandasで特定の条件を満たす要素数をカウント
- Python公式ドキュメント 組み込み型
<データの基本統計量を確認する>
DataFrameに含まれるデータのざっくりとした統計データを眺めるには、describeメソッドを使用します。describeメソッドはNaNは無視して実行されます。
display(data.describe(include="all"))
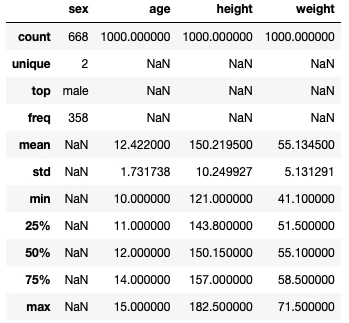
[補足1:数値データ以外も集計する]
デフォルトでは数値データに関してのみ集計されるので、**include="all"**を指定して"sex"に対しても実行しています。また、数値データとそれ以外のデータでは集計される統計量の内容が異なるので注意してください。
<カテゴリデータに対してone-hot-encodingを行う>
one-hot-encodingを実施するにはget_dummiesメソッドを使用します。以下は、"sex"に対してone-hot-encodingを実施した例です。
# one-hot-encodingを実施します。
dummydf_sex = pd.get_dummies(data, columns=["sex"], dummy_na=True)
# オリジナルデータ
display(data.head(5))
# one-hot-encodingデータ
display(dummydf_sex.head(5))
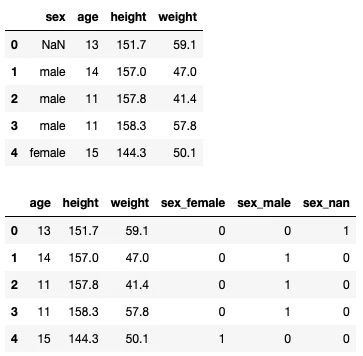
このように、one-hot-encodingを実行すると、"sex"のデータ("male", "female", "Nan")のラベル("sex_male", "sex_female", "sex_nan")が新たに作成されて、1, 0で元のデータが何であったかが示されています。
[補足1:欠損データもラベルとして扱う]
デフォルトでは欠損データ(NaN)は無視されるのですが、「データが欠損している」というのも立派な情報なので、get_dummiesメソッドの引数でdummy_na=Trueを指定して、"NaN"も1つのデータとしてone-hot-encodingを行なっています。
[参考]
<ラベルとデータを追加する>
DataFrameオブジェクトに新しいラベルとデータを追加してみます。例としてBMIのラベルを作成してみましょう。簡単な方法は以下のように、(手順1)データのリストを作成して、(手順2)新しいラベルとして追加する方法です。
# 手順1:BMIのリストを作成します。Pandas操作とは関係ありません。
bmi = [ w * (h / 100)**2 for w, h in zip(data["weight"], data["height"]) ]
# 手順2:BMIのリストを"bmi"ラベルのデータとして追加します。
data["bmi"] = bmi
結果を表示してみましょう。
display(data.head(5))
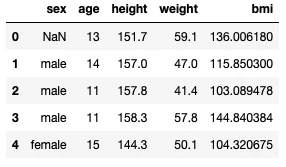
DataFrameに"bmi"のラベルとデータが追加されていることが確認できます。
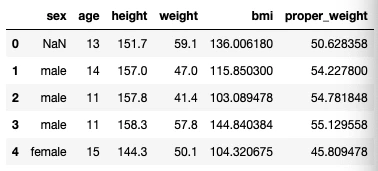
[補足1:assignメソッドを使用する方法]
assignメソッドを使用してもラベルを追加できます。assignメソッドではデータ作成用の関数でデータを作成することもできます。試しに適正体重(proper_weight)のラベルを追加してみましょう。
data = data.assign(proper_weight = lambda x : (x.height / 100.0)**2 * 22)
display(data.head(5))
[参考]
<ラベルを削除する>
ラベルとそこに含まれるデータを削除します。<ラベルとデータを追加する>で追加した"bmi"を削除するには以下のようにします。
# ラベルを削除します
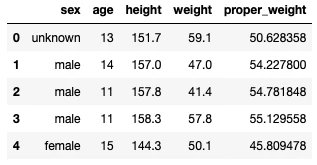
data.drop(columns=["bmi"], inplace=True)
結果を表示してみます。
[補足1:変更を元のDataFrameに反映する]
デフォルトでは、dropメソッドはDataFrameオブジェクトを返して元のDataFrameオブジェクトには変更を加えません。inplace=Trueを指定することで元のDataFrameオブジェクトに変更を反映することができます。
[参考]
<欠損データを指定値で埋める>
欠損データを指定した値で埋めるにはfillnaメソッドを使用します。"sex"の欠損部分を"unknown"で埋めてみましょう。
data.fillna(value={"sex": "unknown"}, inplace=True)
結果を確認してみましょう。
display(data.head(5))
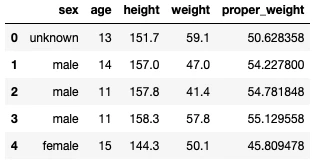
sexの欠損部分に"unknown"が入力されているのが確認できました。
[参考]
2.Pandasを便利に使う
<条件を指定してデータを抽出する>
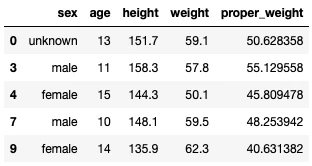
条件を指定して、条件に一致したデータを抽出してみます。例として、体重が適正体重(proper_weight)以上のデータを抽出して新しいDataFrameオブジェクト(data_over)を作成してみましょう。
data_over = data[data.weight > data.proper_weight]
display(data_over.head(5))
[参考]
<条件を指定してデータを変更する>
条件を指定して、条件に一致したデータのみを変更します。例として、身長が150以下のデータの体重を0にしてみましょう。
data_over["weight"][data_over.height <= 150] = 0
display(data_over.head(5))
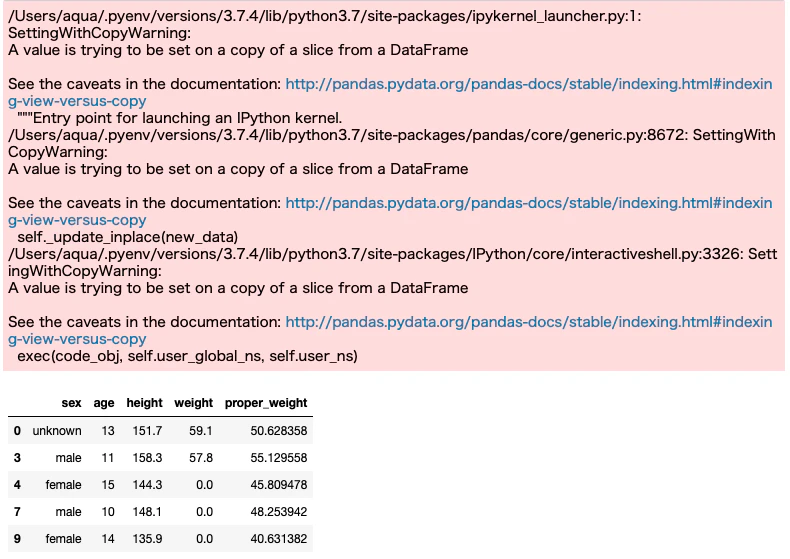
とりあえずやりたいことはできているが、Warningが出てしまっています。これについてサッと調査しましたが完全には理解できなかったので、後日ちゃんと調べて記事にしたいと思います。
<groupbyでグループに対して処理を実施する>
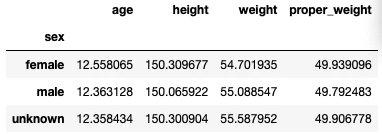
条件に一致するデータをグループとして、グループ単位で処理をしたいときはgroupbyメソッドを使用します。例として、性別ごとの平均値を出力してみましょう。
display(data.groupby("sex").mean())
[参考]