0.はじめに
本記事は2021/5/21時点で動作確認をしてます。仮に時がたって本手法でできなくなる可能性もあるので一応書いておきます。
今回は自然言語処理のとっかかりとしてWindows+Pythonを使用した形態素解析をやったのでその中からMeCabとNEologdの紹介を行う。
※読み方
MeCab:メカブ
NEologd:ネオログディー
- 動作環境
- OS : Windows10 pro(64bit)
- Python : 3.8.3// Miniconda 4.9.1
- MeCab 0.996
- NEologd (mecab-ipadic-neologd)
- WSL (Ubuntu 20.04.1)
1.環境構築
おそらくここが一番苦労するポイントだと思う。ググると色々記事は出てくるが7割はLinuxだったりWindowsでも記事が古かったりでまぁまぁ個人的に苦戦してしまった。。
1-1.MeCab本体を導入
Windows64bitの場合だと下記URLからMeCabをインストールする。紛らわしいので書かないが、公式のダウンロードの場合、32bitしか対応してないので、必ず↓から「mecab-64-0.996.2.exe」をダウンロードし、ダウンロード後はexeをクリックして道なりにインストールする。
次にMeCabにコントロールパネルの環境変数でPathを通しておく。おそらく下のどっちかだと思う。
C:\Program Files\MeCab\bin
C:\Program Files(X86)\MeCab\bin
1-2.MeCabとPythonの連動部の導入
これは簡単で、pip install mecab-python3で導入できてしまう。
1-3.Neologdの導入
MeCabの導入はすでに終わっているが、よりよく形態素解析する為にNEologdを導入させる。
※簡単に言うと最近の単語も認識してくれるMeCab用デジタル辞書がNEologdであると思っていただければいい
しかしこれがかなり面倒くさかった。
今から紹介する方法がWindowsで現時点で一番簡単か?と聞かれると多分違うが、再現性あると思ったので紹介しておく。
参考にしたサイト:mecab-ipadic-NEologdをWindowsで使ってみる。
A.まずはMicrosoft Storeからubuntuをインストールする
Windows Storeから落とせばいい。
ただしここで解説すると長くなるので、別の方の記事を参考として載せておく。
参考:Windows10にUbuntu 20.04 LTSをインストールする
B.次に、UbuntuにMeCabをインストール
※下記命令を1行ずつ入力して実行していく
$ sudo apt-get update
$ sudo apt install mecab
$ sudo apt install libmecab-dev
$ sudo apt install mecab-ipadic-utf8
C.次にNEologdをUbuntuにインストール
$ sudo apt install make
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ cd mecab-ipadic-neologd
$ sudo bin/install-mecab-ipadic-neologd -n -a
なお、一番最後のコマンドの実行著中で下図のようにyes/Noを聞かれるのでyesと打ち込んでEnterする。

これでNEologdの辞書がUbuntu上にインストールできた。
D.次にNEologdをUbuntuからWindowsへ
上でインストールした辞書データは以下の場所に格納されている。

参考サイトではコマンドで移動させていたが、うまくいかないこともあり直接コピペした方が早いと思うので今回はその方法を書く。
まずはUbuntuを起動している状態で、エクスプローラーを開いてアドレスバーに\\wsl$と入力する。
すると、以下のようにUbuntuと出てくると思う。
Ubuntuをクリックしたら、先程の格納してある場所のpath(多分以下のpath)まで移動する。
\\wsl$\Ubuntu\usr\lib\x86_64-linux-gnu\mecab\dic
すると、以下のような辞書データが入っていることが確認できるはず。これをコピーしてCドライブ直下に持ってくる。
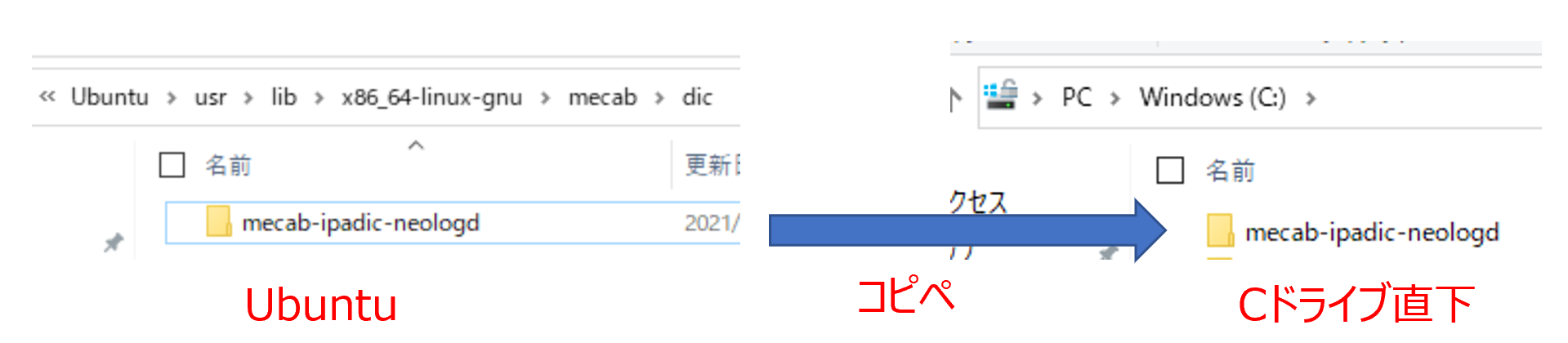
これで終了である。
2.PythonでMeCabを使ってみる
これで形態素解析の準備は整ったので、後は実際にやってみる。
2-1.まずは普通のMeCabでやってみる。
今回はNEologdとの比較もするので、比較的最近の以下の話題を解析してみた。
「日本では呪術廻戦、全米では鬼滅の刃が人気だ」
import MeCab
CONTENT = '日本では呪術廻戦、全米では鬼滅の刃が人気だ'
tagger = MeCab.Tagger() #Taggerクラスのインスタンスを作成
parse = tagger.parse(CONTENT) #parse(解析)をする
print(parse, "\n") #/nで改行して表示
日本 ニッポン ニッポン 日本 名詞-固有名詞-地名-国 3
で デ デ で 助詞-格助詞
は ワ ハ は 助詞-係助詞
呪術 ジュジュツ ジュジュツ 呪術 名詞-普通名詞-一般 1,0
廻 メグル メグル メグル 名詞-固有名詞-人名-名 0
戦 セン セン 戦 接尾辞-名詞的-一般
、 、 補助記号-読点
全米 ゼンベー ゼンベイ 全米 名詞-普通名詞-一般 0
で デ デ で 助詞-格助詞
は ワ ハ は 助詞-係助詞
鬼 オニ オニ 鬼 名詞-普通名詞-一般 2
滅 メツ メツ メツ 記号-一般 1
の ノ ノ の 助詞-格助詞
刃 ハ ハ 刃 名詞-普通名詞-一般 1
が ガ ガ が 助詞-格助詞
人気 ニンキ ニンキ 人気 名詞-普通名詞-一般 0
だ ダ ダ だ 助動詞 助動詞-ダ 終止形-一般
EOS
当然だが、鬼滅の刃や呪術廻戦を認識できない。
一応分かち書き(単語を形態素毎に半角スペースで区切って表示)もやっておく。
"""分かち書き"""
CONTENT = '日本では呪術廻戦、全米では鬼滅の刃が人気だ'
tagger = MeCab.Tagger('-Owakati') #Taggerクラスに-Owakatiを渡すと分かち書きになる
parse = tagger.parse(CONTENT)
print(parse)
日本 で は 呪術 廻 戦 、 全米 で は 鬼 滅 の 刃 が 人気 だ
2-2.MeCab+NEologdでやってみる
先程Windowsに持ってきた辞書のpathを指定するだけで使用できる。
"""MeCab + NEologd"""
CONTENT = '日本では呪術廻戦、全米では鬼滅の刃が人気だ'
tagger = MeCab.Tagger(r'-d "C:\mecab-ipadic-neologd"') #Cドライブ直下にコピペした辞書を指定する。
parse = tagger.parse(CONTENT)
print(parse, "\n")
日本 名詞,固有名詞,地域,国,*,*,日本,ニッポン,ニッポン
で 助詞,格助詞,一般,*,*,*,で,デ,デ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
呪術廻戦 名詞,固有名詞,一般,*,*,*,呪術廻戦,ジュジュツカイセン,ジュジュツカイセン
、 記号,読点,*,*,*,*,、,、,、
全米 名詞,固有名詞,地域,一般,*,*,全米,ゼンベイ,ゼンベイ
で 助詞,格助詞,一般,*,*,*,で,デ,デ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
鬼滅の刃 名詞,固有名詞,一般,*,*,*,鬼滅の刃,キメツノヤイバ,キメツノヤイバ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
人気 名詞,一般,*,*,*,*,人気,ニンキ,ニンキ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
EOS
同様に分かち書きもしてみる。
"""MeCab + NEologd + 分かち書き"""
CONTENT = '日本では呪術廻戦、全米では鬼滅の刃が人気だ'
tagger = MeCab.Tagger(r'-Owakati -d "C:\mecab-ipadic-neologd"') #分かち書きと辞書の指定を同時にやるだけ
parse = tagger.parse(CONTENT)
print(parse)
日本 で は 呪術廻戦 、 全米 で は 鬼滅の刃 が 人気 だ
先程と違って、鬼滅の刃も呪術廻戦も固有名詞として認識してくれていることがわかる。
これがNEologdを導入する効果である。 ※2週に一回程度更新しているNEologd管理者のおかげですが・・
3.おわりに
WindowsでMeCab、NEologdを導入するとなった時に色んなサイトが色んなやり方を書いてあって困惑したので、備忘録として書いてみた。
本記事を参考にして頂くことで形態素解析の取っ掛かりとしてほしいなぁと思って書きました。
私もまだ自然言語に関しては勉強中の身ですのでこれはまだスタート地点なので、一緒に頑張っていきましょう!
それでは今回はここで終わります。