0. はじめに
ツイッターでNLP関連に関して漁ってたらこんな投稿を発見した。
新しい言語モデル?でしかも日本語も対応??これは使ってみるしかないでしょ! ということで、今年最後のアドカレ用の記事投稿ネタとして採用してみました。
★本記事の全コード部分をGoogle Colab(リンク)でも共有しました。ポチポチするだけなので、気軽に動かしてみてください。
- 動作環境
- OS : Windows10 pro
- python: 3.9.6
- transformers: 4.25.1 (>=4.22.0) ※バージョン古いとLukeForSequenceClassificationが使えない
- Pytorch: 1.12.1 (+cu116)
- jupyter notebook(Google Colaboratory)
1. LUKEに関して
1-1. LUKEって何?
本記事は実装がメインですので、詳細解説は公式の方が日本語でわかりやすく解説されている以下youtubeリンクを参照してください(スライドは英語ですが、解説は日本語です)
一応私の認識は...(間違っていたらスイマセン)
・日本人チームが開発した単語とエンティティ(固有表現)の新しい訓練済言語モデル
・独自技術のmasked entity prediction, entity-aware self-attentionを採用
・最近日本語モデルにも対応した
※エンティティはWikipediaのハイパーリンク部分等をアノテーションとしてMASKで隠して学習(masked entity prediction)
※entity-aware self-attentionではself-attention自身が処理しているトークンが単語かエンティティかを識別可能
そして今回はそのLUKEを使用した文章分類を紹介するわけなので、実際にHuggingfaceのコードを調べてみると、2022年現在11種類タスクで使用可能なLUKE専用クラスが使用できることが確認できる。
今回はこの中から文章分類としてLukeForSequenceClassificationのサンプルをお試しする
1-2. LUKE日本語モデルの違いは何か?
さて、LUKEのhuggingfaceで使用可能な事前学習済モデルは複数存在しているので、まずは違いを確認する。
LUKEに関して日本語事前学習済モデルは2022年末現在以下4種類存在している模様
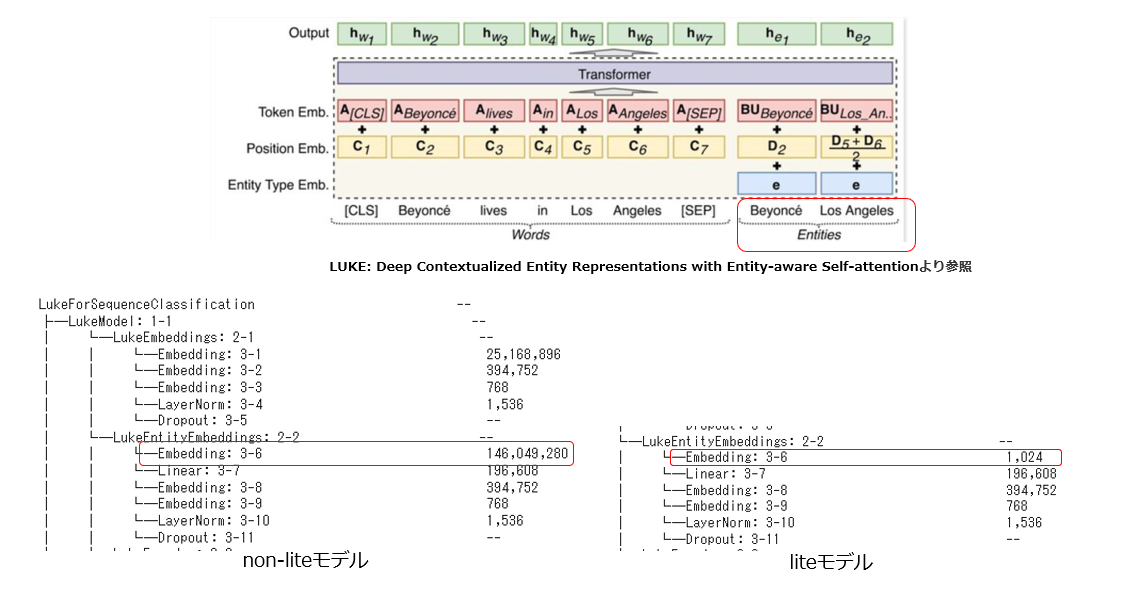
・studio-ousia/luke-japanese-base-lite
・studio-ousia/luke-japanese-base
・studio-ousia/luke-japanese-large-lite
・studio-ousia/luke-japanese-large
それぞれの違いは要するに「base/large/liteか否か」となっている。公式の説明では「単語の入力のみを使うタスクには、lite versionを使用してください」ということらしいので、今回の分類のような単語(文)だけの入力のタスクにはlite版を使用すればいいと思われます。
なお、baseとlargeの違いはモデルの中を見た感じBERTと同様で(Luke)エンコーダーの層の数が12個か24個かの違いみたいです。
※一応torchinfoで見た感じ、liteか否かの違いは下図の通りエンティティ入力用Embeddingの部分にあることがわかる。
2.コード部分
後は淡々とコード部分をパートに分けて説明する。
前述通り、以下Google Colaboratoryでも実行可能にしてあるので必要に応じ参照ください。
2-1.インポート~データ準備まで
今回もlivedoor ニュースコーパスを使用して、ニュースタイトルからどの媒体なのか?を3分類させるサンプルを使用する。
ここら辺は私の過去記事と全く同じなので、細かくは説明しません。詳細はそちらを参照ください
#本記事で使うライブラリ群
import os
import random
import warnings
warnings.simplefilter('ignore')
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, precision_recall_fscore_support
import seaborn as sns
import torch
from torch.utils.data import Dataset
from torchinfo import summary
import transformers
#transformersのバージョンを確認 ※古いとLukeForSequenceClassificationでエラー
print(transformers.__version__)
from transformers import (
AutoTokenizer, Trainer, TrainingArguments,
LukeTokenizer, LukeForSequenceClassification,
pipeline
)
#乱数固定
def seed_everything(seed: int):
"""seed固定"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
SEED = 7
seed_everything(SEED)
4.25.1 ※transformersのバージョンが古すぎないか確認
次にLivedoorニュースコーパスをデータフレーム化する
def get_title_list(path):
"""記事タイトル取得関数"""
title_list = []
filenames = os.listdir(path) #ファイル名称一覧取得
for filename in filenames:
# 1記事ずつファイルの読み込み
with open(path+filename, encoding="utf_8_sig") as f:
title = f.readlines()[2].strip() #各記事テキストの改行2番目に記事タイトルが記載してある
title_list.append(title)
return title_list
# データセットの生成(タイトルとラベル付与)
"""
今回は例として与えられた記事タイトルから
どのニュース媒体記事なのか?(独女通信、ITライフハック、MOVIE ENTERの3種類)
を分類する為のデータセットを作成する
"""
df = pd.DataFrame(columns=['label', 'sentence']) #空データフレーム
#独女通信(ラベル0)
title_list = get_title_list('./text/dokujo-tsushin/')
for title in title_list:
df = df.append({'label':0 , 'sentence':title}, ignore_index=True) #ignore_indexで合体後のindexを連番に
#ITライフハック(ラベル1)
title_list = get_title_list('./text/it-life-hack/')
for title in title_list:
df = df.append({'label':1 , 'sentence':title}, ignore_index=True)
#MOVIE ENTER(ラベル2)
title_list = get_title_list('./text/movie-enter/')
for title in title_list:
df = df.append({'label':2 , 'sentence':title}, ignore_index=True)
# label列をint型の変換する
df['label'] = df['label'].astype(int)
# 全データの順番をシャッフル(+index振り直し)
df = df.sample(frac=1 ,random_state=0).reset_index(drop=True)
次に、train/validation/testにデータを分割する(6:2:2で分割)
#最初の6割をtrain、次の2割をvalid、最後の2割をtestでデータフレームを分割
train, val, test = np.split(df, [int(len(df) * .6), int(len(df) * .8)])
print(train.shape)
print(val.shape)
print(test.shape)
#お試しで1行ずつ表示
display(train.head(1))
display(val.head(1))
display(test.head(1))
(1567, 2)
(523, 2)
(523, 2)
| label | sentence | |
|---|---|---|
| 0 | 1 | 冷房なしでは低温やけどしそうな熱さ! 発熱は他製品と同じMacBook Pro Retina... |
| label | sentence | |
|---|---|---|
| 1567 | 0 | くさったよめがあらわれた!vol.03「いつも私と同じことばかり考えてる君が好き!」 pre... |
| label | sentence | |
|---|---|---|
| 2090 | 0 | みんな知ってる! の「みんな」って誰? |
2-2.モデル指定と確認
LUKEの使い方はhuggingfaceなので楽ちん。今まで同様に指定すればいい。
今回は日本語で使用可能な4モデルからstudio-ousia/luke-japanese-base-liteを使ってみることにする。
MODEL_NAME = "studio-ousia/luke-japanese-base-lite"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
ids = tokenizer.encode(train['sentence'][0])
wakati = tokenizer.convert_ids_to_tokens(ids)
print(train['sentence'][0]) #原文
print(ids) #トークンID
print(wakati) #IDを戻すと?
トークナイザの結果、BERTの時とはやはり中身が違っている模様(SEPとかCLSのトークンではない)
冷房なしでは低温やけどしそうな熱さ! 発熱は他製品と同じMacBook Pro Retinaディスプレイモデル【デジ通】
[0, 29834, 28962, 1456, 27, 30516, 30583, 29880, 215, 17252, 30670, 29859, 29935, 29834, 22261, 29844, 30154, 1066, 1005, 7354, 10012, 10412, 1585, 1649, 25759, 8574, 1774, 30512, 2992, 30005, 30518, 2]
['<s>', '▁', '冷房', 'なし', 'では', '低', '温', 'や', 'けど', 'しそうな', '熱', 'さ', '!', '▁', '発熱', 'は', '他', '製品', 'と同じ', 'Mac', 'Book', '▁Pro', '▁R', 'et', 'ina', 'ディスプレイ', 'モデル', '【', 'デジ', '通', '】', '</s>']
お次はモデルを定義して中を覗いてみる。
なお、今回使用するのはLukeForSequenceClassificationである。
LukeForSequenceClassificationのドキュメントは以下部分を参照のこと
#引数としてはBERTの時と同じでnum_labelsで指定する
model = LukeForSequenceClassification.from_pretrained(MODEL_NAME, num_labels = 3)
# torchinfoで中身を確認(4層まで)
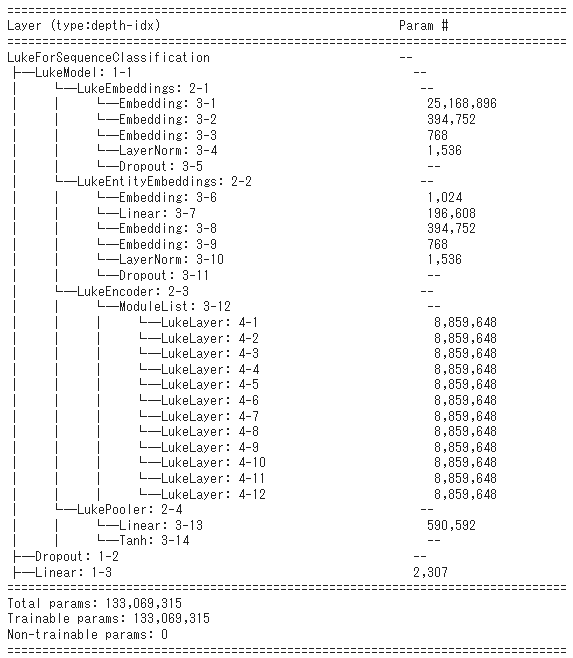
summary(model, depth=4)
torchinfoで見た4階層までのモデル中身は以下の通り
2-3.データセット作成
まずはそれぞれをトークン化して最大トークン長を確認する(512以上だとNGなので)
#train/val/testをトークン化して最大長を確認しておく
text_lengths_list = [len(tokenizer.encode(text)) for text in df["sentence"].to_list()]
train_X = tokenizer(train["sentence"].tolist(), return_tensors='pt', padding="max_length", max_length=max(text_lengths_list), truncation=True)
valid_X = tokenizer(val["sentence"].tolist(), return_tensors='pt', padding="max_length", max_length=max(text_lengths_list), truncation=True)
test_X = tokenizer(test["sentence"].tolist(), return_tensors='pt', padding="max_length", max_length=max(text_lengths_list), truncation=True)
print(f"最大トークン数は{max(text_lengths_list)}です")
print(train_X.keys())
最大トークン数は41です
dict_keys(['input_ids', 'attention_mask'])
次にデータセット化を行う
class MyDataset(Dataset):
"""トークン入力データセット"""
def __init__(self, encodings, labels=None):
self.encodings = encodings
self.labels = labels
def __len__(self):
return len(self.encodings['input_ids'])
def __getitem__(self, index):
input = {key: torch.tensor(val[index]) for key, val in self.encodings.items()}
if self.labels is not None:
input["label"] = torch.tensor(self.labels[index])
return input
#train/valid/testのデータセットをそれぞれ作成する ※testは当然label無し
train_ds = MyDataset(train_X, train["label"].tolist())
valid_ds = MyDataset(valid_X, val["label"].tolist())
test_ds = MyDataset(test_X)
#お試し確認
print(train_ds[0].keys())
print(f"学習データ数は{len(train_ds)}です")
print(tokenizer.decode(train_ds[0]["input_ids"])) #デコードで戻してみる
dict_keys(['input_ids', 'attention_mask', 'label'])
学習データ数は1567です
<s> 冷房なしでは低温やけどしそうな熱さ! 発熱は他製品と同じMacBook Pro Retinaディスプレイモデル【デジ通】</s><pad><pad><pad><pad><pad><pad><pad><pad><pad>
2-4. Trainerで学習
以下記事でも使用しているHuggingfaceを扱う際にPytorch学習部分でDataloader不要かつforループ等を書かなくていい便利な「Trainer」を使って学習させます。
※Trainerの詳細に関しては以下記事をご参考ください
def compute_metrics(pred):
"""メトリクス定義"""
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
#2値分類ならaverage='binary'とする
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'precision': precision,
'recall': recall,
'f1': f1,
}
#ここ弄るともっと精度上がると思います
train_args = TrainingArguments(
output_dir = "./out", #log出力場所
overwrite_output_dir = True, #logを上書きするか
load_best_model_at_end = True, #EarlyStoppingを使用するならTrue
metric_for_best_model = "f1", #EarlyStoppingの判断基準。7-1. compute_metricsのものを指定
save_total_limit = 1, #output_dirに残すチェックポイントの数
save_strategy = "epoch", #いつ保存するか?
evaluation_strategy = "epoch", #いつ評価するか?
logging_strategy = "epoch", #いつLOGに残すか?
label_names = ['labels'], #分類ラベルのkey名称(デフォルトはlabelsなので注意)
lr_scheduler_type = "linear", #学習率の減衰設定(デフォルトlinearなので設定不要)
learning_rate = 5e-5, #学習率(デフォルトは5e-5)
num_train_epochs = 3, #epoch数
per_device_train_batch_size = 16, #学習のバッチサイズ
per_device_eval_batch_size = 12, #バリデーション/テストのバッチサイズ
seed = SEED, #seed
)
#Trainerを定義
trainer = Trainer(
model=model, #モデル
args=train_args, #TrainingArguments
tokenizer=tokenizer, #tokenizer
train_dataset=train_ds, #学習データセット
eval_dataset=valid_ds, #validデータセット
compute_metrics = compute_metrics, #compute_metrics
)
#学習
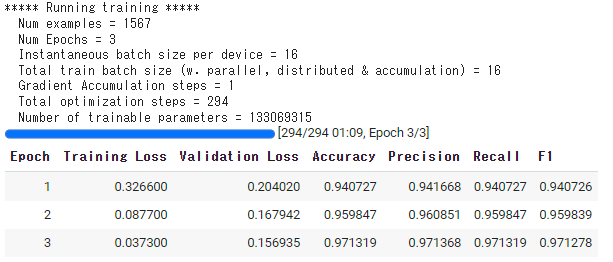
trainer.train()
2-5. 未学習のデータでテスト評価
同じくTrainerで評価を行う
#trainer.predictで評価可能
test_preds = trainer.predict(test_ds)
#元のtestデータフレームにpredカラムを追記する
test['pred'] = np.argmax(test_preds.predictions, axis=1)
#dfをお試し表示
display(test.head(2))
#評価用にそれぞれ計算し、print
precision, recall, f1_score, _ = precision_recall_fscore_support(test['label'], test['pred'], average=None)
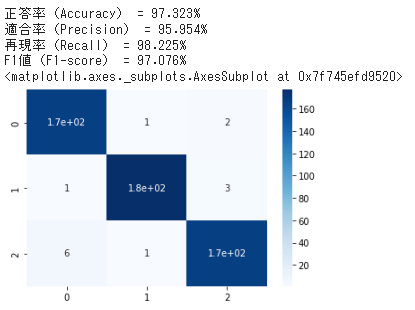
print('正答率(Accuracy) = {:.3f}%'.format(100 * accuracy_score(test['label'], test['pred']))) # 正答率を表示
print('適合率(Precision) = {:.3f}%'.format(100 * precision[0])) # 適合率を表示
print('再現率(Recall) = {:.3f}%'.format(100 * recall[0])) # 再現率を表示
print('F1値(F1-score) = {:.3f}%'.format(100 * f1_score[0])) #F1値を表示
#混同行列
cm = confusion_matrix(test['label'].astype(int), test['pred'])
display(sns.heatmap(cm, annot=True, cmap='Blues'))
↓見ると、適当なパラメータな割になかなか高性能だと思う!
3. おわりに
今回は言語モデルLUKEを使用した日本語ニュース分類を紹介しました。
某日本語NLP系の分類コンペでも上位陣がこのモデルを使用していたそうで、今後ますます利用が増えてくると思いますし、私も今後は使ってみようと思います。
年末ではありますが、この記事が少しでも皆さんの役に立っていただければ幸いです。
(追記)運営さんからリプいただきました!
はじめにで本記事書くきっかけとしてツイート紹介させて頂いた公式運営アカウントさんからも本記事を紹介いただきました🤗
参考