★追記とお知らせ(2022/1/9追記)
本記事大変多くの方に見ていただけてますが、現在「株式投資メモ」から株価データが取得できなくなっていることがわかりました。よって流れだけ参考にしていただけると幸いです。
※日本株のデータ取得に関して追加記事(↓)出しましたのでそちらもどうぞ
0.はじめに
**pythonを投資活用に使う目的で調べたまとめ記事の第3弾(最終回)**です。
今までの総集編として、スクレイピングをしつつDBへ格納する一連の流れを書いていきます。
基本的に以下記事がすべてわかっている前提で記載していきます。(この記事もなるべくコメント多めにしてますが、より細かくは過去記事見てください)
前回までの記事
Pythonで簡単にデータベースを扱う(SQLite3)
PythonでWebスクレイピング①(スクレイピング事前知識)
PythonでWebスクレイピング②(実際に株サイトをスクレイピングする)
- 動作環境
- OS : Windows10 pro
- ブラウザ:Google Chrome
- Python : 3.8.3// Miniconda 4.9.1
- sqlite3:2.6.0
- (管理ツール:DB Browser for SQLite ※すぐに中身を見るときに便利)
1.本記事のゴール
-
株式投資メモから2020年(1/6~12/28)の全上場銘柄の4本値+出来高を取り出す
※このサイトはrobots.txt:Allow:/となっており、スクレイピング許可がされてる - 取り出した情報をデータベース(SQLite)へ格納する
2.個別銘柄データ(2020年の1年分)を取り出すURL,HTMLタグの確認
2-1.まずはどのURLで取得できるか?を確認
株式投資メモのTOPページから例えばトヨタ自動車を銘柄検索すれば、年間推移DBのページに飛ぶことができ、その中から「2020」を選ぶことで2020年のデータが得られる。
また、その際のURLを確認すると/stock/証券コード/確認したい年度になっていることがわかる。
つまり、この証券コードの部分を変えていくことで色々な銘柄のデータに切り替えていくことが出来る。

2-2.次にHTMLのどこのタグに取得したい情報があるか?を確認しに行く
細かい部分は前回の記事で説明済なので、詳しくはそれを確認してほしい。
Chromeの検証機能を使って取得対象を探していくと、table class="stock_table"以下のtheadとtbodyの部分がそうっぽいことがわかる。ただし前回の記事と異なるのは株価がtbody直下にすべて入っておらず、個々のtbody毎に格納されている点である。が、別に大したことはない。

2-3.実験としてトヨタ自動車の2020年の株価データを取得してみる
確認くん:https://www.ugtop.com/spill.shtml
import requests
from bs4 import BeautifulSoup
# スクレイピング対象のURLを入力
url = 'https://kabuoji3.com/stock/7203/2020/'
# 確認くんで調べた自分のユーザーエージェント(現在のブラウザー)をコピペ ※環境に応じて書き直す
headers = {"User-Agent": "Mozilla/*** Chrome/*** Safari/***"}
# Requests ライブラリを使用してWebサイトから情報(HTML)を取得する。
response = requests.get(url, headers = headers)
# 取得したHTMLからBeautifulSoupオブジェクト作成
soup = BeautifulSoup(response.content, "html.parser")
# まずはtheadをfindメソッドでコマンドで検索し、その中のtrをfind_allメソッドですべて抽出
tag_thead_tr = soup.find('thead').find_all('tr')
print(tag_thead_tr)
[<tr>
<th>日付</th>
<th>始値</th>
<th>高値</th>
<th>安値</th>
<th>終値</th>
<th>出来高</th>
<th>終値調整</th>
</tr>]
'''
class="stock_table stock_data_table"直下の各tbody毎に株価データが格納されている
よって、まずはそのテーブルクラスを取得してから中身を取得すればいい。
'''
# テーブルを指定し、findAllで検索して0番目要素(といっても1個しかないが)を取り出す
table = soup.findAll("table", {"class":"stock_table stock_data_table"})[0]
# その中のtrタグを取得する。ただし、最初はスレッドカラムなので省略する(1:の部分) ※tbodyでない理由は後述
tag_tbody_tr = table.findAll("tr")[1:]
# 例として最初だけを表示する
print(tag_tbody_tr [0])
[<tr>
<td>2020-01-06</td>
<td>7599</td>
<td>7626</td>
<td>7530</td>
<td>7565</td>
<td>6672300</td>
<td>7565</td>
</tr>]
株価部分に関しては、実際のHTMLを確認すると下図のようになっており、tbodyでfindAllをすると最初の<tbody>~</tbody>の2020/1/6部分しか取得できない。これは<tbody>を一回書いたら次回からは省略できるというHTMLのルールからきている。よって、今回は前回記事とは違いどの日付にも省略なく記載されている<tr>タグを探す必要があった。

さらに、DB格納時に必要な銘柄名と証券コードも同ページから探して取得できるようにする。
実行結果からわかるように、このページからは証券コード単体を取得することができなかったが、本番では先頭4桁の部分だけ抜き出せばいい。
# ヘッダークラスのbase_box_header内のjpクラス,spanタグに情報が埋め込まれているのが調べるとわかる。
name = soup.findAll("span", {"class":"jp"})[0]
print(name.get_text())
'7203 トヨタ自動車(株)'
3.全銘柄のデータを取り出しつつ、DBへ格納していく
2までで取り出し方がわかったので、これを全銘柄に適応させつつDBに書き出していく。
3-1.DBの構成(スキーマ)を考える
どのようにデータベースとして格納するか?(これをスキーマと呼ぶ)を考えなくてはならない。
今回は単純な例なので、いきなりDBの設計図を表すER図を適当に書くと下のようになる。
なお、ER図作成ツールは簡単なのでdraw.ioを使用した。
参考:ER図の作り方【簡易版】
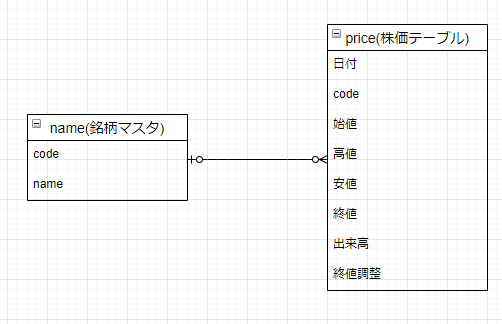
・銘柄マスタは証券コードと銘柄名を格納する(+上場市場がわかればなおいい)
・株価テーブルに、各銘柄のデータを全て入れ込む(codeでどの銘柄か?は識別可能)
・本記事では例としてprice(株価テーブル)の取得を記載する。name(銘柄マスタ)は簡単なのでこの記事を参考に自分でやってみてほしい
・本来は更に「終値調整(株式分割等)」に関しての処理が必要になるが、この記事ではこの部分に関して記載しない
3-2.DBに格納する為に情報を取り出す関数を作成し、一旦Dataframeとして保存させる
ここからのやり方は色々あると思うが、私はpandasが使い慣れているのもあり、一旦pandasで株価テーブルを作成してからsqlにto_sqlで変換させるのがいいと思ったので、今回はそのように記載していく。わざわざpandasにしなくても。。という方はご自身のやり方でやってほしい。
なお、time.sleep(1)の部分が、スクレイピングの負荷対策の部分になっている。もしサイトによって秒数が規定されていたら中身の数字を入れ替えて使用すればいい。
import time
import pandas as pd
def get_brand(code):
"""
証券コードからスクレイピング情報を取得し、Datafrrameにして返す関数
"""
#確認くんで調べた自分のユーザーエージェント(現在のブラウザー)をコピペ ※環境に応じて書き直す
headers = {"User-Agent": "Mozilla/*** Chrome/*** Safari/***"}
#取得する銘柄のURLを取得
url = 'https://kabuoji3.com/stock/' + str(code) + '/2020/'
#株価が存在しなければ例外処理でNoneを返す
try:
#取得したHTMLからBeautifulSoupオブジェクト作成
response = requests.get(url, headers = headers)
soup = BeautifulSoup(response.content, "html.parser")
#証券コードを取得する
code_name = soup.findAll("span", {"class":"jp"})[0]
#ヘッダー(カラム)情報を取得する
tag_thead_tr = soup.find('thead').find_all('tr')
head = [h.text for h in tag_thead_tr[0].find_all('th')]
#株価データを取得し、Dataframe化する
table = soup.findAll("table", {"class":"stock_table stock_data_table"})[0]
tag_tbody_tr = table.findAll("tr")[1:]
data = []
for i in range(len(tag_tbody_tr)):
data.append([d.text for d in tag_tbody_tr[i].find_all('td')])
df = pd.DataFrame(data, columns = head)
#codeカラムをassignでDataframeに新規追加する ※code_nameの最初の4桁までが証券コード
df = df.assign(code=code_name.get_text()[:4])
#デバッグ用。取得できたページを出力する。※本番コードでは不要
print(url)
except (ValueError, IndexError, AttributeError):
return None
return df
def brands_generator(code_range):
"""
証券コードを生成し、取得した情報を結合する関数
"""
#株価を入れる空のデータフレームを新規作成
cols = ['日付', '始値', '高値', '安値', '終値', '出来高', '終値調整', 'code']
df = pd.DataFrame(index=[], columns=cols)
for code in code_range:
#生成した証券コードをスクレイピング関数へ渡す
brand = get_brand(code)
#情報が取得できていれば、情報を結合していく
if brand is not None:
df = pd.concat([df, brand]).reset_index(drop=True)
#1秒間プログラムを停止する(スクレイピング負荷対策)
time.sleep(1)
return df
"""
ここでは例として証券コード1301~1310までを取得することにする。
本番は1301~9999まで取得すればいい(当然時間はかかる)
"""
df = brands_generator(range(1301,1310))
https://kabuoji3.com/stock/1301/2020/
https://kabuoji3.com/stock/1305/2020/
https://kabuoji3.com/stock/1306/2020/
https://kabuoji3.com/stock/1308/2020/
https://kabuoji3.com/stock/1309/2020/
取得できた証券コードのURLが出力結果として出てきていることがわかる。当然1302や1307等は存在しない証券コードなので取得できてなくて正解。これで正しくスクレイピングできていそうなことがわかる。
# 最初の2行だけをサンプル表示する
df.head(2)
取得できたdfの結果をPandasで表示すると、以下のように日付順に取得できている。
自分で追加したcodeカラム部分にも証券コードが格納されており、問題はなさそう。
| |日付 |始値 |高値 |安値 |終値 |出来高 |終値調整 |code
|---|---|---|---|---|---|---|---|---|---|
|0 |2020-01-06 |7599 |7626 |7530 |7565 |6672300 |7565 |1301
|1 |2020-01-07 |7654 |7722 |7619 |7715 |4960700 |7715 |1301
3-3.DBにDataframeの情報を渡して保存する
dataframe形式でデータを取得できたので、最後にDBに変換させる。
import sqlite3
# データベース名.db拡張子で設定
dbname = ('sample.db')
# データベースを作成
db = sqlite3.connect(dbname, isolation_level=None)
# dfをto_sqlでデータベースに変換する。DBのテーブル名はpriceとする
df.to_sql('price', db, if_exists='append', index=None)
# データベースにカーソルオブジェクトを定義
cursor = db.cursor()
# 本当にpriceテーブルが作成されたのか?をsql関数で確認する
sql = """SELECT name FROM sqlite_master WHERE TYPE='table'"""
for t in cursor.execute(sql):
print(t)
('price',)
これできちんとpriceテーブルが作成されていることがわかる。最後にこのデータベースを再度dataframeとして読み込んで、中身が同じになっているか?を確認する
# 作成したデータベースのpriceテーブルを再度pandasで読み出す
df_db = pd.read_sql('SELECT * FROM price', db)
# 先ほど同様に2行だけサンプル表示
df_db.head(2)
当然だが、同じ結果になっている。これでDBの中身も先程スクレイピングで取り出したdataframeと同じになっていることが確認できた。(sql命令でも中身を確認できるが、個人的にpandasにした方が100倍見やすい)
| |日付 |始値 |高値 |安値 |終値 |出来高 |終値調整 |code
|---|---|---|---|---|---|---|---|---|---|
|0 |2020-01-06 |7599 |7626 |7530 |7565 |6672300 |7565 |1301
|1 |2020-01-07 |7654 |7722 |7619 |7715 |4960700 |7715 |1301
# 最後に接続(connect)を閉じる
db.close()
4.最後に
どうだったであろうか?意外と簡単に自作DBへの保存ができたのではないか?
もちろん全証券コードを取得するのは時間がかかるが、例えば今2020年末までをとりあえず取得しておき、2021年分からは毎日DBに格納するようなバッチを作成しておけばDBは自動的に更新できるし、そこまで手間もかからないと思う。
また、今後も投資関連ではないものの機械学習やその他記事を毎週投稿するつもりなので、良かったらモチベ維持の為にもLGTMやストックお願いします!
5.追記(2021/5/30)
本記事多くの方に見ていただけているようで、大変うれしい限りですが、本記事の通りにto_sql命令を書くと無茶苦茶時間かかりますので、下記事もどうぞ参考にしてください。