こんにちは、Psychic VR Lab で Web エンジニアをしている ku6ryo です。今回 Unity の機械学習の推論ライブラリ Barracuda を使って透明人間になる方法をご紹介いたします。
カメラに映る人間をこちらの画像ように消す(うっすら見える)状態にしてみたいと思います。

Barracuda をすでに知っている方、使ったことがある方は Barracuda についての項目を飛ばして読んでください。
コードの内容、機械学習モデルに関して
基本的な部分のコードは IKEP さんのこちらのリポジトリを参考にさせてもらっています(Apache-2.0 License)。使用したモデルもこちらのリポジトリからとってきたものですが、もともとPINTO0309/PINTO_model_zoo で MIT License で公開されているものですので、使用可能と判断しています。こちらの記事のコードは github で公開していますので、この記事と合わせて御覧ください。
Barracuda とは
Unity 上で機械学習の学習済みモデルを実行する事のできるライブラリです。今回は人が写っている画像を、人の領域だけ判定してテクスチャとして出力してくれるモデルを使用しています。Barracuda についてはすでにいろいろな記事や動画があり、参考になるので聞いたことがない方はざっくり概要を知るために調べてみてください。
ニューラルネットで何でもできちゃう!? Unity Barracudaで遊ぼう! - Unityステーション
qiita 上で barracuda の検索結果
人を消す仕組み
Webcam のビデオデータに対して人の写っている領域を判定し、1フレーム前の画像を現在のフレームの人が写っている部分にだけ当て込みます。この仕組からわかるように、写ったことのないものを生成するのではなく、写ったことのあるもので人の領域を埋めているので、入力は連続的な画像でかつ、背景が動いておらず、人間が動いている必要があります。
Unity プロジェクトの作成、Barracuda の導入
今回は Unity 2021.2.2f1 を使用しました。Unity プロジェクトを作成し、こちらの install 方法を参考に、Barracuda を導入します。注意点として、Unity version が 2020 の場合には Packages/manifest.json に直接依存を書き込むか、github の URL で直接追加する必要があります。
Unity シーンのセットアップ
今回は以下のようなシーン内オブジェクトとファイル構成
- Canvas とその中に配置された RawImage (最終的結果が毎フレーム RawImage に書き込まれます)
- スクリプトを貼り付ける空のオブジェクト
- Processor.cs という処理をコントロールするスクリプト
- Preprecess.compute というカメラ画像を機械学習に食わせるための前処理の compute shader。Processor.cs のインジェクション要素
- Segmentation.onnx という Barracuda 上で実行する人の領域を白色で吐き出す機械学習モデル。Processor.cs のインジェクション要素
- Combine.compute という前のフレーム画像と今のフレーム画像を合わせる compute shader。Processor.cs のインジェクション要素
ヒエラルキー
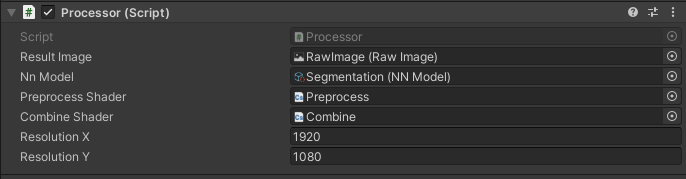
Processor オブジェクトの Processor.cs スクリプト設定
具体的な処理
2つの図で説明します。以下の処理が毎フレームごと(Unity の Update() 関数)に走っていると考えてください。
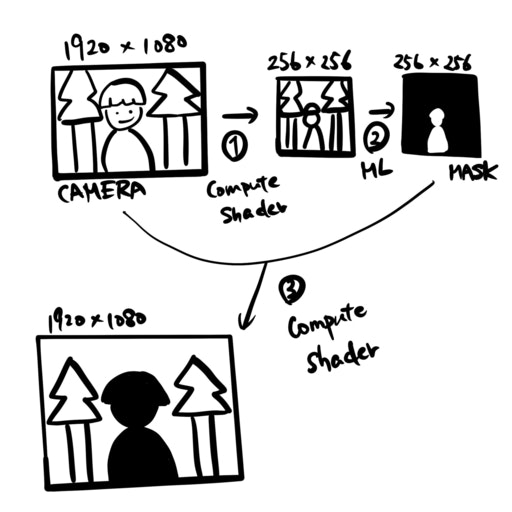
最初の図では、機械学習を使って人の部分を黒塗りすることを考えます。(次の図で黒塗りした部分に背景画像を当てはめることを説明します)
まず、とってきたカメラ画像を①の段階で compute shader を使い、256 x 256 の画像に変換します。(input は 1920 x 1080 でなくてもよいです)次に②の段階で機械学習モデルに通して人間の部分だけ白くなった画像にします(mask とよびます)。③で input と mask をつかい、人間の部分だけ切り取った画像を作成します。
以下が①の preprocess compute shader の内容です。ほぼこちらのリポジトリにあるままです。こちらでやっていることは、入力画像を 256 x 256 のサイズに変更し、また、上下を逆さまにしています。逆さまにする理由は、使用している機械学習モデルが Unity のテクスチャフォーマットと上下逆の情報を入力としてとる仕様のためです。注意するポイントは、最後の方にある Result[offs + 0] = rgb.r; から続く3行で、Compute Buffer は Unity の Compute shader では一次元配列として扱われるため、render texture に書き込むときのような float4 を使うのではなく、RGB を配列に順番に入れ込んでいく操作が必要です。
# pragma kernel Preprocess
// Input image size defined by neural network model.
# define NN_INPUT_SIZE 256
sampler2D Input;
RWStructuredBuffer<float> Result;
[numthreads(8, 8, 1)]
void Preprocess(uint3 id : SV_DispatchThreadID)
{
// Caluculate vertically flipped UV.
float2 uv = float2(0.5 + id.x, NN_INPUT_SIZE - 0.5 - id.y) / NN_INPUT_SIZE;
// Caluculate vertically flipped UV gradients.
float2 duv_dx = float2(1.0 / NN_INPUT_SIZE, 0);
float2 duv_dy = float2(0, -1.0 / NN_INPUT_SIZE);
// Texture sample
float3 rgb = tex2Dgrad(Input, uv, duv_dx, duv_dy).rgb;
// Generate output buffer
uint offs = (id.y * NN_INPUT_SIZE + id.x) * 3;
Result[offs + 0] = rgb.r;
Result[offs + 1] = rgb.g;
Result[offs + 2] = rgb.b;
}
①、②に相当する C# スクリプトです。
public void GenerateSegment(Texture cameraTexture) {
// Convert the camera image to compute buffer.
preprocessShader.SetTexture(0, "Input", cameraTexture);
preprocessShader.SetBuffer(0, "Result", mlInputBuffer);
preprocessShader.Dispatch(0, ML_INPUT_SIZE / 8, ML_INPUT_SIZE / 8, 1);
// Creates a input tesor with the buffer and execute the model.
var inputTensor = new Tensor(1, ML_INPUT_SIZE, ML_INPUT_SIZE, ML_IN_CH, mlInputBuffer);
woker.Execute(inputTensor);
inputTensor.Dispose();
// Copy output to the mask texture.
var shape = new TensorShape(1, ML_INPUT_SIZE, ML_INPUT_SIZE, ML_OUT_CH);
var tmpOutput = RenderTexture.GetTemporary(ML_INPUT_SIZE, ML_INPUT_SIZE, 0, RenderTextureFormat.ARGB32);
var tensor = woker.PeekOutput("activation_10").Reshape(shape);
tensor.ToRenderTexture(tmpOutput);
tensor.Dispose();
Graphics.Blit(tmpOutput, segmentMask);
RenderTexture.ReleaseTemporary(tmpOutput);
}
こちらで preprocess の compute shader にカメラ画像を渡して compute buffer (mlInputBuffer) に結果を格納します。
preprocessShader.SetTexture(0, "Input", cameraTexture);
preprocessShader.SetBuffer(0, "Result", mlInputBuffer);
preprocessShader.Dispatch(0, ML_INPUT_SIZE / 8, ML_INPUT_SIZE / 8, 1);
次に以下のコードで Barracuda でモデルを実行します。
var inputTensor = new Tensor(1, ML_INPUT_SIZE, ML_INPUT_SIZE, ML_IN_CH, mlInputBuffer);
woker.Execute(inputTensor);
inputTensor.Dispose();
最後に、実行結果を RenderTexture にコピーします。
var shape = new TensorShape(1, ML_INPUT_SIZE, ML_INPUT_SIZE, ML_OUT_CH);
var tmpOutput = RenderTexture.GetTemporary(ML_INPUT_SIZE, ML_INPUT_SIZE, 0, RenderTextureFormat.ARGB32);
var tensor = woker.PeekOutput("activation_10").Reshape(shape);
tensor.ToRenderTexture(tmpOutput);
tensor.Dispose();
Graphics.Blit(tmpOutput, segmentMask);
RenderTexture.ReleaseTemporary(tmpOutput);
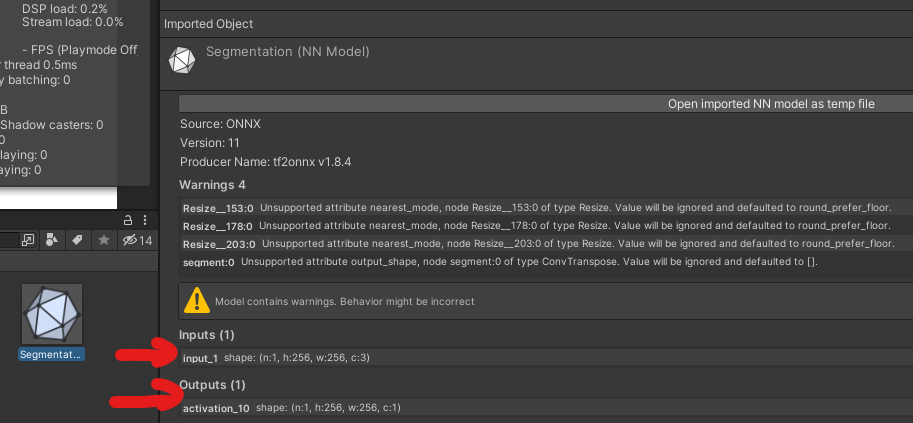
ここで activation_10 という文言が出てきますが、そちらは使用している機械学習のモデルの最終層の名前です。モデルを Inspector で確認すると、Input / Output という欄に入力と出力の名前とデータ形式が書かれています。(最終結果だけでなく、途中の層の結果も取得できるか気になりますね。要調査です。)
③については、処理のイメージをしてもらうために書いていますが、実際には絵とは少し異なる処理をしています。次の画像と合わせて説明します。
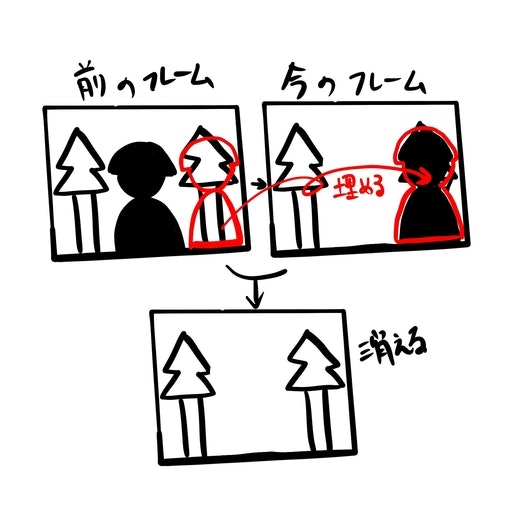
人を消して、背景画像で埋めるために、この画像のようなことをしています。例えば最初のフレームでは背景は人に隠れてみえないので、人の位置に埋める画像がなく、黒くなります。次のフレームで人が動いた場合、次のフレームでは前のフレームで写っていた背景画像で人の領域を埋めることができます。こちらの処理のコードは以下のような形になります。
public void Combine(Texture current, Texture previous, Texture mask, Texture output) {
var kernel = combineShader.FindKernel("CSMain");
combineShader.SetTexture(kernel, "Current", current);
combineShader.SetTexture(kernel, "Previous", previous);
combineShader.SetTexture(kernel, "Output", output);
combineShader.SetTexture(kernel, "Mask", mask);
combineShader.Dispatch(
kernel,
current.width / 8,
current.height / 8,
1
);
}
# pragma kernel CSMain
Texture2D<float4> Current;
Texture2D<float4> Previous;
Texture2D<float4> Mask;
RWTexture2D<float4> Output;
[numthreads(8, 8, 1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
if (Mask[id.xy].x > 0) {
Output[id.xy] = Previous[id.xy];
} else {
Output[id.xy] = Current[id.xy];
}
}
C# のスクリプトは Compute shader を実行しているだけなので深く触れません。Compute shader の内容で登場する要素は以下です。
- Current:今のカメラ画像フレーム
- Previous:前回の結果
- Mask: 人の領域のマスク
- Output: 結果の render texture
肝は if (Mask[id.xy].x > 0) { の部分だけですが、マスクの値が 0 より大きい、つまり人の領域には前回の結果を、それ以外の部分は今のカメラ画像を出力するようにしています。(0 より大きいとは真っ黒でないという意味で、真っ白であるという条件で判定しないのは、機械学習の出す結果が人と背景との境界値で、 0 - 1 の間の曖昧な値をだしており、0 より大きいとしたほうが見た目がきれいな結果となったからです。)
以上が処理の流れとなります。Unity の Start() 関数で処理化処理などを行っていますが解説は割愛させていただきます。詳しくはこちらのリポジトリをご覧ください。
感想など
Barracuda は学習済みモデルさえ手に入れば気軽に使えるもので、コード量も少なくて良いと思いました。しかし、上記の Unity station の動画で触れられているように、ONNX のモデルであればなんでも動くわけでもないのでそこらへんはエンジニアどうして知識を共有していく必要があると感じました。今回は他人の作ったモデルを使用しましたが、自分のトレーニングしたモデルでも挑戦したいなと思っています。