以下の論文の解説(まとめ)になります.
Addressing Function Approximation Error in Actor-Critic Methods
この論文はICML 2018に採択されており,連続行動空間における価値関数の推定に関して興味深い考察を行なっているため,今回紹介させていただきました.この論文で提案しているモデルは,TD3(Twin Delayed DDPG)と呼ばれる手法になります.
記事中の図は,特に記載がない限りすべて論文からの引用です.
記事内容に不備がございましたら,ご指摘頂けると助かります.
概要
この論文は,
- 価値関数の過大評価がActor-Criticの手法でも生じていることを示し,Clipped Double Q-learningと呼ばれる手法によって改善できることを示した
- Delayed Policy Updates,Target Policy Smoothingと組み合わせ,TD3と呼ばれる強化学習アルゴリズムを提案し,MuJoCoベンチマークにおいて既存の大きく上回る性能を出せることを示した
ものになります.
価値の過大評価は,Q-learningにおいて「分散の大きなQ関数の推定値に対してmax操作を行うことで,max Qが一貫して過大評価されてしまう性質」のことを指すことが多く,離散行動空間における強化学習で度々話題となっていました.Actor-Criticにおいても,同様の価値の過大評価が生じているのではないかと考えられており,この論文で深く考察されています.
またTD学習を行う際に,Q関数の推定は誤差を持った次の状態のQ関数を用いて推定されるため, 誤差の蓄積が生じてしまうと考えられます.
この論文では
- まず,価値の過大評価と誤差の蓄積が連続行動空間でのActor-Criticにおいても生じていることを示します.
- 次に,Double DQNが上記の問題に有用ではないことを検証実験により示し,Clipped Double Q-learningによって価値の過大評価が改善されることを示します.
- その後,Delayed Policy Updates,Target Policy Smoothingを用いることで,誤差の蓄積を改善できることを示し,まとめてTD3と呼ばれるアルゴリズムを提案します.
推定価値のバイアス(過大評価)
離散行動空間の場合
離散行動空間におけるQ-learningでは,価値の推定は$y = r + \gamma \max_{a'} Q(s', a')$をターゲットに更新されます.しかし,分散の大きな価値の推定値を用いた際,このターゲットは常に過大評価されてしまいます.
E_{\epsilon}[\max_{a'}(Q(s',a') + \epsilon)] \ge \max_{a'} Q(s', a')
関数近似を用いた強化学習では近似誤差が生じてしまうため,この過大評価は避けられない問題となってしまいます.
連続行動空間の場合
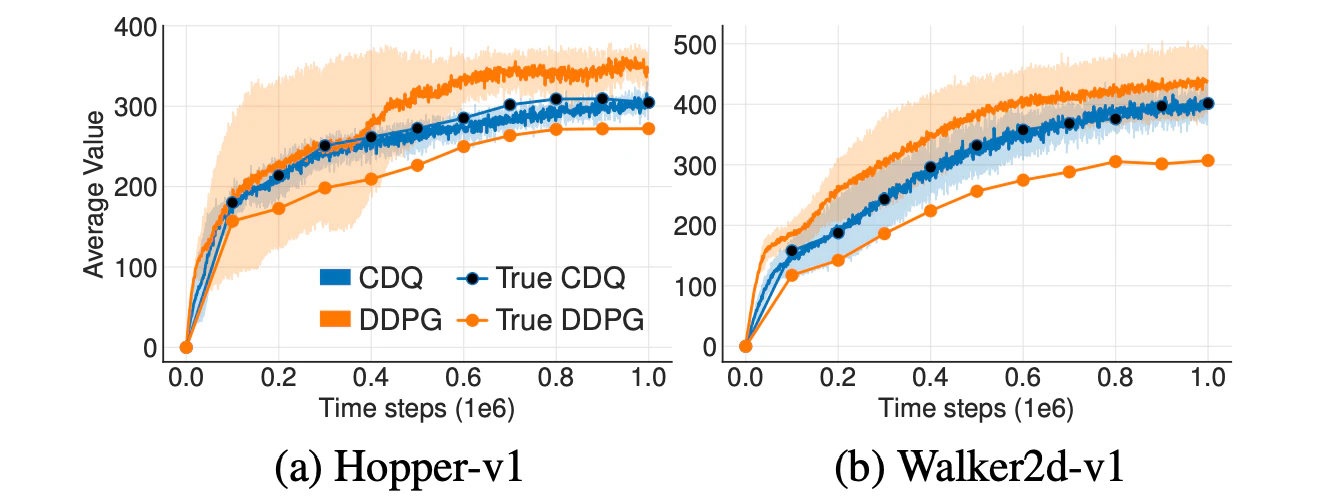
以下では,連続行動空間におけるActor-Criticにおいてもある仮定のもとで,価値の過大評価が生じることを示します.方策は,Deterministic Policy Gradientによって更新されるものとします(仮定1).
まず,価値と方策をそれぞれ$Q_\theta$,$\pi_\phi$と関数近似します.現在の方策パラメータを$\phi$としたときに,近似価値関数$Q_\theta$に基づいて更新されたパラメータを$\phi_{approx}$,仮想的な真の価値関数に基づいて更新されたパラメータを$\phi_{true}$とします(後者は学習中には知ることができない値です).
\phi_{approx} = \phi + \frac{\alpha}{Z_1} E_{s \sim p_\pi} [\nabla_\phi \pi_\phi(s) \nabla_\alpha Q_\theta(s, a)|_{a=\pi_\phi(s)}] \\
\phi_{true} = \phi + \frac{\alpha}{Z_2} E_{s \sim p_\pi} [\nabla_\phi \pi_\phi(s) \nabla_\alpha Q^\pi(s, a)|_{a=\pi_\phi(s)}]
ただし,$Z$は正規化パラメータで,勾配のノルムは$Z$によって正規化されているとします(仮定2).
パラメータ$\phi_{true}$,$\phi_{approx}$によって近似された方策を$\pi_{true}$,$\pi_{approx}$とすると,勾配はQ関数を局所的に最大化させる方向にパラメータを更新させるので,$\alpha \le \epsilon_1 , \epsilon_2$のとき
E[Q_\theta(s, \pi_{approx}(s))] \ge E[Q_\theta(s, \pi_{true}(s))] \\
E[Q^\pi(s, \pi_{true}(s))] \ge E[Q^\pi(s, \pi_{approx}(s))]
となるような十分に小さな$\epsilon_1, \epsilon_2$が存在します.ここで,方策の更新によるバイアスが生じない状況($\pi_{true}$に基づいた推定)で,価値の推定が真の価値の期待値に比べて過大評価されている場合を考えます.(仮定3)
E[Q_\theta(s, \pi_{true}(s))] \ge E[Q^\pi(s, \pi_{true}(s))]
この式は,離散行動空間のQ-learningの価値の過大評価に対応した仮定であり,連続行動空間のActor-Criticにおいても生じていると考えられます.このとき,$\alpha < \min(\epsilon_1,\epsilon_2)$ならば
E[Q_\theta(s, \pi_{approx}(s))] \ge E[Q^\pi(s, \pi_{approx}(s))]
が成り立ち,Actor-Criticでも価値の過大評価が生じていることを示しています.
論文では,MuJoCoのタスクにおいてDDPGを用いたときの価値の推定値の平均と真の価値をプロットしています(上図).ただし,真の価値は割引累積報酬和の1000エピソードでの平均により推定しています.
上図から,DDPG(オレンジ線)を用いた際には,価値の過大評価が実際に生じていることが読み取れます.次の節では,Clipped Double Q-learningと呼ばれるテクニック(青線)によって,価値の過大評価が大幅に緩和されることを示していきます.
Clipped Double Q-learning
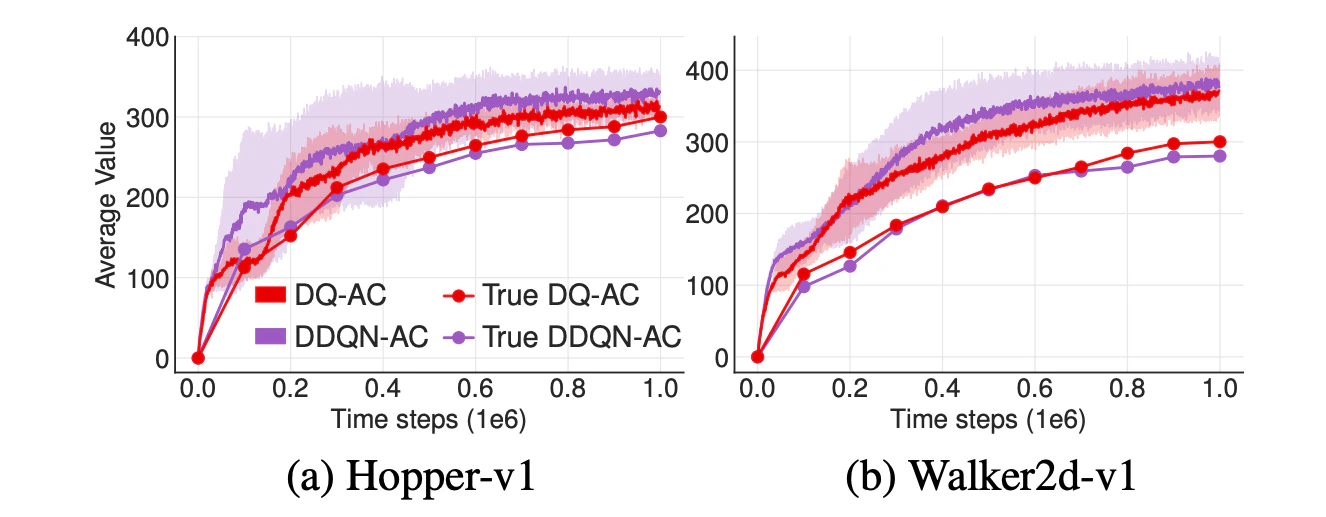
価値の過大評価を解消する手法として,Double Q-learningと呼ばれる,価値の推定を2つ独立して行い,一方のパラメータの更新を他方の価値の推定値を用いて行う手法があります.このDouble Q-learningでは,価値の推定が独立であれば,バイアスを持たない推定となります.
また,離散行動空間でのQ-learningでは,Double DQNと呼ばれる手法が価値の過大評価を緩和するのに非常に有効であることが知られています.Double DQNでは,現在の価値関数のパラメータの更新にターゲットネットワークを用いることで,価値の過大評価が緩和されると期待されます.だたし,$\theta'$はターゲットネットワークのパラメータとします.
y = r + \gamma Q_{\theta'}(s',\pi_{\phi}(s'))
一方で,連続行動空間のActor-CriticではDouble DQNがうまくいかないことが知られています(上図紫線).これはActor-Criticの方策の改善が非常にゆっくりであり,現在の価値とターゲットネットワークが非常に似た値を持ってしまい,独立した推定となっていないためであると考えられます.
また,元のDouble Q-learningを適用することも考えられます(上図赤線).
y_1 = r + \gamma Q_{\theta_2'}(s', \pi_{\phi_1}(s')) \\
y_2 = r + \gamma Q_{\theta_1'}(s', \pi_{\phi_2}(s'))
上図を見ると,Double DQNに比べてDouble Q-learningは価値の過大評価の削減に有効であることが読み取れます.
上記のDouble Q-learningでは,$Q_1$の更新に$Q_1$とは独立した価値の推定値をターゲットに用いることで,方策が更新されていくことによって生じる推定誤差を緩和できると考えられます.一方で,同じリプレイバッファを共有していること,ターゲットとして互いのネットワークを利用していることから,2つの価値関数は完全には独立でないと考えられます.その結果として,$Q_{\theta_2}(s, \pi_{\phi_1}(s)) > Q_{\theta_1}(s, \pi_{\phi_1}(s))$となるような状態$s$が存在すると考えられます.
この問題を解決するために,論文では,Double Q-learningによる価値の推定値$Q_{\theta_2}(s, \pi_{\phi_1}(s))$の上界をバイアスを持った価値の推定値$Q_{\theta_1}(s, \pi_{\phi_1}(s))$で抑え込むことを提案しています.これは以下のClipped Double Q-learningに帰結されます.
y_1 = r + \gamma \min_{i=1,2}Q_{\theta_i'}(s',\pi_{\phi_1}(s')) \\
y_2 = r + \gamma Q_{\theta_2'}(s', \pi_{\phi_1}(s'))
ただし,Double Q-learningと異なり,方策パラメータは1つ$\phi_1$しか用いていません.この手法では,$Q_{\theta_2} > Q_{\theta_1}$のときは,通常のActor-Criticと同様の更新を行い,$Q_{\theta_1} > Q_{\theta_2}$ではDouble Q-learningによって過大評価の緩和が行われます.よって,Double Q-learningより価値の過大評価が生じることがないことを保証しつつ,バイアスを持った推定値により上界を押さえ込むことで,過大評価がより緩和されることが期待されます(より詳しい解説は,論文の付録を参照ください).
本記事の1番最初の図の青線では,Clipped Double Q-learningによる価値の推定バイアスを示しています.その図から,Clipped Double Q-learningを用いることで,価値の過大評価が大きく緩和されていることが読み取れます.
推定価値の分散
誤差の蓄積
関数近似を用いた強化学習では,ベルマン方程式に基づいた価値関数の更新式において,誤差$\delta$が必ず生じてしまいます.
Q_\theta(s, a) = r + \gamma E[Q_\theta(s',a')] - \delta
逐次的な更新によってこの誤差が蓄積していくことは,以下のように示せます.
Q_\theta(s_t, a_t) = r_t + \gamma E[Q_\theta(s_{t+1},a_{t+1})] - \delta_t \\
= r_t + \gamma E[r_{t+1} + \gamma E[Q_\theta(s_{t+2},a_{t+2})] - \delta_{t+1}] - \delta_t \\
= E_{s_i \sim p_\pi, a_i \sim \pi}[\sum_{i=t}^T \gamma^{i-t}(r_i - \delta_i)]
上記のように,価値の推定が将来の報酬と推定誤差で表されるとき,価値推定の分散は報酬と推定誤差の分散に比例して大きくなります.そのため,割引率$\gamma$が大きくなるにつれ,価値推定の分散は急激に大きくなってしまいます.
Delayed Policy Updates
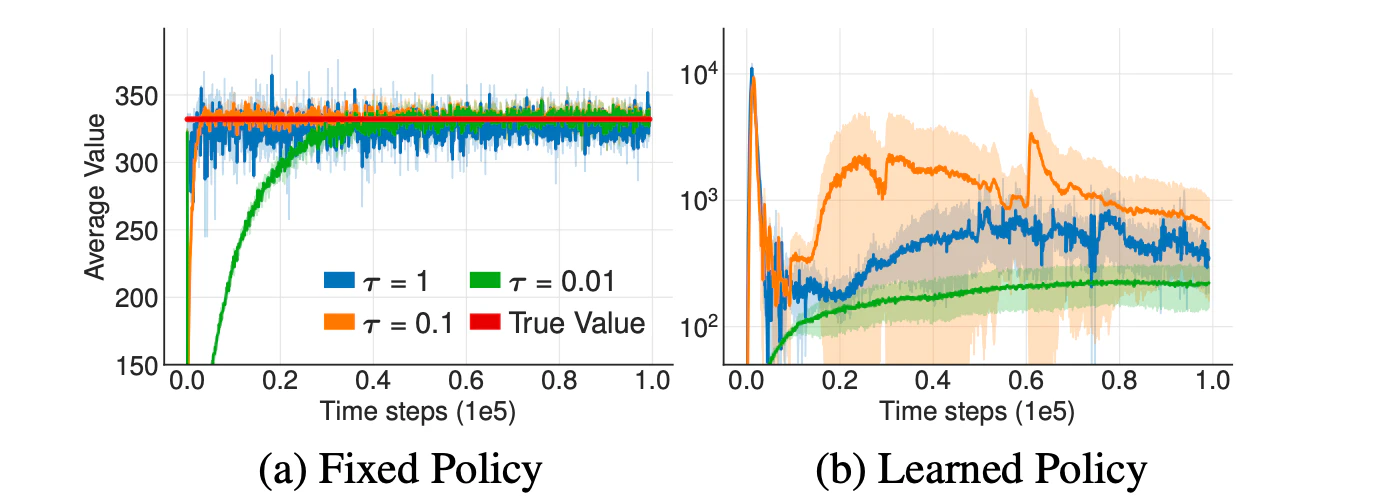
ターゲットネットワークを用いることは,強化学習を安定化させる有効な手段として幅広く利用されています.
論文では,方策を固定した場合(図左段)と方策を学習している場合(図右段)において,ターゲットネットワークを用いた場合($\tau=1$に対応,青線)と用いていない場合(緑・オレンジ線)の価値関数の学習の推移を検証しています(左側はCriticのみを学習している).
この図から,方策を固定した場合にはターゲットネットワークの有無にかかわらず,最終的に同じような値に収束していることがわかります.一方で,方策を学習している場合には,ターゲットネットワークをよりゆっくり更新させていく(緑線)ことで,より安定した価値関数の学習を行えることがわかります.
ターゲットネットワークを用いていない場合の結果から,分散の大きな価値関数を用いて方策を学習することで,学習が非常に不安定になることが示唆されます.すなわち,不安定な方策を用いて価値関数を更新することで価値関数の過大評価が生じ,それによって方策の学習が不安定になる,といった負のスパイラルが生じていると考えられます.
価値関数の更新ステップにおいて安定した値を持つターゲットネットワークを用いることで,複数ステップの価値関数の更新を安定して行うことができ,価値関数の推定誤差を緩和できると期待されます.そこで「ターゲットネットワークを用いて価値関数を複数回更新し,価値の推定誤差を緩和してから方策の更新を行う」ことが妥当だと考えられます.論文では,Delayed Policy Updatesとしてこのテクニックを提案しています.
Target Policy Smoothing
DDPGのような決定的方策はQ関数の局所的な外れ値に敏感であることが指摘されています.よって,DDPGはQ関数の推定誤差が生じた際,ターゲットの分散が大きくなってしまうという問題が生じます.
論文では,Q関数の推定を行動空間の微小な領域における期待値により計算することで,ターゲットを平滑化することを提案しています.ターゲットの平滑化によって,局所的な外れ値にも安定して学習できると期待されます.
y = r + E_\epsilon[Q_{\theta'}(s', \pi_{\theta'}(s') + \epsilon)]
論文では,上記の期待値を行動の各次元にクリップしたノイズを加えることで近似を行う,Target Policy Smoothingを提案しています.
y = r + \gamma Q_{\theta'}(s', \pi_{\theta'}(s') + \epsilon) \\\epsilon \sim \rm{clip}(N(0, \sigma), -c, c)
アルゴリズムまとめ
Clipped Double Q-learning,Delayed Policy Updates,Target Policy Smoothingの3つのテクニックを全て取り入れて,Twin Delayed Deep Deterministic policy gradient(TD3)と呼ばれるアルゴリズムを提案しています.
このアルゴリズムでは,各ステップでCriticを更新します.
y = r + \gamma \min_{i=1,2} Q_{\theta'_i}(s', \pi_{\phi'_i}(s') + \epsilon) \\\epsilon \sim \rm{clip}(N(0, \sigma), -c, c)
また,dステップに1回,Q関数を最大化するようにPolicyを更新します(ここら辺はDDPGと同じ).
また,TD3の実装で主に利用されているハイパーパラメータは以下のようになります.
- Target Policy Smoothing : $\rm{clip}(N(0, 0.2), -0.5, 0.5)$
- Delayed Policy Updates : 2ステップに1回($d=2$)
- Actor,Criticのネットワーク : (400, 300)ユニットの隠れ層,ReLU
検証
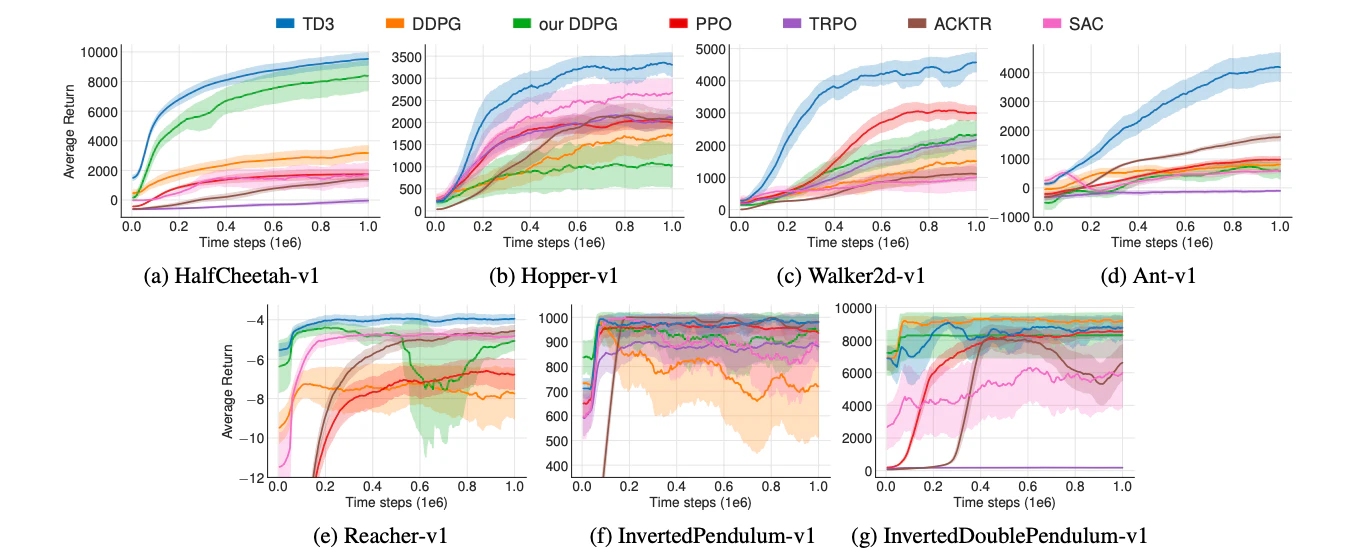
MuJoCoのタスクで,今回提案したTD3やDDPG,PPO等と検証しています.
検証結果より,TD3はほとんどの環境において,他のアルゴリズムを上回る性能を出していることが読み取れます.
また論文ではablation studyを行っており,提案した3つのテクニックのうち1つでも取り除くと,性能が落ちてしまうことを検証しています.
結論
この論文では,
- 価値関数の過大評価がActor-Criticの手法でも生じていることを示し,Clipped Double Q-learningと呼ばれる手法によって改善できること
- Delayed Policy Updates,Target Policy Smoothingと組み合わせ,TD3と呼ばれる強化学習アルゴリズムを提案し,MuJoCoベンチマークにおいて既存の大きく上回る性能を出せること
を示しました.