この記事は,以下の論文の解説です.
Reinforcement Learning from Imperfect Demonstrations (2018)
記事内容では,強化学習の基礎的な知識を前提としています.
また,記事中の図は全て論文からの引用です.
不備がございましたら,ご指摘頂けると幸いです.
概要
この論文は,「(不完全な)デモンストレーションとシミュレーションの両方から学習可能な強化学習の手法を提案した」論文になります.
強化学習では,しばしば大量のシミュレーションを必要とするため,デモンストレーションを用いて学習を効率化しようという研究が存在します.自らのシミュレーションのみでは報酬を獲得することができないような複雑なタスクでは,特にデモンストレーションの利用は重要だと考えられます.
そのうちの多くの手法は,強化学習を行う前に教師あり学習として,デモンストレーションを模倣するように初期方策を学習します.しかし,各行動の価値を推定しているのではなく,単にデモンストレーションを模倣することを目的とするため,デモンストレーションが不完全の場合にはうまくいかないという課題が生じます.
このように,教師あり学習と強化学習という異なる目的関数を併用することでデモンストレーションとシミュレーションの両方から学習することは可能なのですが,この論文では,デモンストレーションとシミュレーションを単一の目的関数で学習することを提案しています.
この論文で提案する Normalized Actor-Critic(NAC) は,
- デモンストレーションとシミュレーションの両方から,単一の目的関数で学習可能である
- デモンストレーションの学習も教師あり学習ではなく強化学習で行うため,不完全なデモンストレーションにもロバストである
という特徴を持ちます.
Normalized Actor-Critic (NAC)
強化学習では,過去に集めたデータから学習可能な,off-policyと呼ばれる類の手法が存在します.しかし,デモンストレーションのみから学習を行うと,off-policyの手法では学習に失敗してしまうことが知られています.これは,Q関数が良い行動データのみから学習された場合,他の行動が良いのか悪いのかわからないことが原因であると指摘されています.
以下では,デモンストレーションに含まれない行動の価値を抑制するように強化学習を行うことで,単一の目的関数を用いつつ,デモンストレーションでの学習を安定化させる方法を説明していきます.
Max-Entoropy RL
まず,提案手法(NAC)がベースにしているMax-Entoropy RLについて,簡単に復習していきます.詳しいことは,Haarnojaさんの論文を参照してください.
通常の強化学習では,(割引した)将来的な報酬を最大化するように,方策$\pi_{std}$を学習します.
\pi_{std} = arg\max_{\pi} \sum_t \gamma^t \mathop{\mathbb{E}}_{s_t,a_t \sim \pi} [R_t]
一方,Max-Entoropy RLでは,(割引した)将来的な方策のエントロピーも一緒に最大化します.このエントロピー項によって,探索が促進されるなどのメリットがあります.
\pi_{sac} = arg\max_{\pi} \sum_t \gamma^t \mathop{\mathbb{E}}_{s_t,a_t \sim \pi} [R_t + \alpha H(\pi(\cdot|s_t))]
このエントロピー項付きの目的関数を最大化するためには,状態価値$V$と状態行動価値$Q$を少し修正します.
\begin{align}
Q_{\pi}(s,a) &= R_0 + \mathop{\mathbb{E}}_{s_t,a_t \sim \pi} \sum_{t=1}^{\infty} \gamma^t (R_t + \alpha H(\pi(\cdot|s_t))) \\
V_{\pi}(s) &= \mathop{\mathbb{E}}_{s_t,a_t \sim \pi} \sum_{t=0}^{\infty} \gamma^t (R_t + \alpha H(\pi(\cdot|s_t)))
\end{align}
これらの価値関数をsoft V関数,soft Q関数と呼びます.最適方策 $\pi^{*}$,最適soft Q関数 $Q^{*}(s,a)$,最適soft V関数 $V^{*}(s)$ の間には,以下の関係があることがわかっています.
\begin{align}
V^*(s) &= \alpha \log \sum_a \exp (Q^*(s,a)/\alpha) \\
\pi^*(a|s) &= \exp((Q^*(s,a) - V^*(s))/\alpha)
\end{align}
また,soft Q関数の勾配は以下のようになります(Soft Q-Learning).ただし,$\hat Q(s,a) = R(s,a) + \gamma V(s')$ は推定のターゲットです.$V(s')$は上の最適soft Q関数と最適soft V関数の関係から計算します.この式は,単に(soft)TD誤差を微分することで得られます.
\nabla_{\theta} Q_{\theta}(s,a) (Q_{\theta}(s,a) - \hat Q(s,a))
また,方策の勾配は以下のようになります(Soft Policy Gradient).ただし,ベースライン$b(s_t)$は任意の状態依存関数です.
\mathop{\mathbb{E}} [\sum_{t=0}^{\infty} \nabla_\theta \log \pi_\theta(\hat Q_\pi - b(s_t)) + \alpha \nabla_\theta H(\pi_\theta(\cdot|s_t))]
提案手法
提案手法であるNACでは,Soft Q-Learning,Soft Policy Gradientをベースに学習を行います.ただし,NACではsoft Q関数 $Q(s, a)$ をニューラルネットワーク(重み: $\theta$ )で関数近似し,soft V関数 $V_Q(s)$ と方策 $\pi_Q$ はsoft Q関数を用いて表現します.これらの関係は,最適方策,最適soft価値関数の関係と等価です.
\begin{align}
V_Q(s) &= \alpha \log \sum_a \exp(Q(s,a)/\alpha) \\
\pi_Q(a|s) &= \exp ((Q(s,a) - V_Q(s)) / \alpha)
\end{align}
Soft Policy Gradientの勾配のベースライン$b(s_t)$として,soft V関数を用いることで,方策勾配を以下のように導くことができます(論文の付録に導出があります).また,Q関数の勾配は通常通り計算します.
\begin{align}
\nabla_\theta J_{PG} &= \mathop{\mathbb{E}}_{s, a \sim \pi_Q} [(\nabla_\theta Q(s,a) - \nabla_\theta V_Q(s)) (Q(s,a) - \hat Q)] \\
\nabla_\theta J_V &= \mathop{\mathbb{E}}_{s} [\nabla_\theta \frac{1}{2}(V_Q(s) - \hat V(s))^2]
\end{align}
ただし,ターゲット$\hat Q(s,a)$,$\hat V(s)$ は以下のように求めることができます.
\begin{align}
\hat Q(s,a) &= R(s,a) + \gamma V_Q(s') \\
\hat V(s) &= \mathop{\mathbb{E}}_{a \sim \pi_Q} [R(s,a) + \gamma V_Q(s')] + \alpha H(\pi_Q(\cdot|s))
\end{align}
soft Q関数の学習は,デモンストレーションとシミュレーションの両方に対して,同一の勾配 $\nabla_\theta J_{PG} + \nabla_\theta J_{V}$ によって行われます.これらの勾配は,方策勾配の$-\nabla_\theta V_Q(s)$の項以外は通常のMax-Entoropy RLと同様になっています.直感的に,この項はデータに存在しない行動の価値が上昇するのを防ぐ働きをしていると考えることができます.これにより,不完全なデモンストレーションと自らのシミュレーションの両方から,同じ目的関数を用いて学習することができます.
その他,NACは本来on-policyの手法なのでImportance Samplingが必要なのですが,効果が観測できなかったため,NACではImportance Samplingは行っていません.この原因としては,Importance Samplingによって,勾配の分散が大きくなってしまうからだと指摘しています.
まとめると,アルゴリズムは以下のようになります.

検証
以下のいくつかの項目に関して,検証を行なっていきます.
- NACは,デモンストレーションを活用できるのか
- NACは,不完全なデモンストレーションにもロバストなのか
- NACは,少ないデモンストレーションからうまく学習できるのか
比較対象としては,DQfD(論文)やBehaviour Cloning,Q-Learning,soft Q-Learning,PCL(論文)などを用います.
シミュレーション環境としては,
-
Toy Minecraft

- Grid Worldのカスタム版
- エージェントは緑部分を歩くことができ,左からスタートし,ハートをゴールとする
- 入力は$(x,y)$座標
- 出力は{Up, Down, Left, Right}
-
Torcs

- レーシングゲーム
- 入力は$84\times 84$のグレイスケール画像
- 出力は{left, no-op, right}と{up, no-op, down}の直積集合(9次元)
Toy Minecraft
上図のように,ゴールに到達するには2つの道があります.将来の報酬は割り引いているので,短い方の道の方が好ましいです.まず,あえて長い方の道を選択したデモンストレーションを用意します.
デモンストレーションから学習するフェーズでは,NACとDQfDは長い方の道を学習していました,これは,デモンストレーションには長い方の道のデータしかないため,短い方の道を学習する術がなく妥当な結果だと考えられます.その後,自らシミュレーションを行い追加学習するフェーズでは,DQfDは短い方の道を学習できていないのに対し,NACでは短い方の道を学習することができていました.これは,DQfDはimitation lossを用いているため,元の解から大きく離れることができないからだと考えられます.
Learned agent's demonstrations(Torcs)
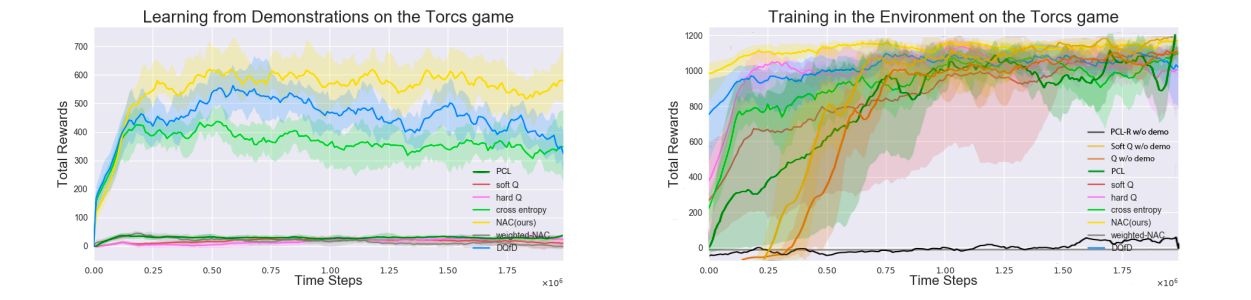
まず,学習済みのQ-Learningのエージェントのデモンストレーションを用います.デモンストレーションが決定的になりすぎないように,行動に$0.01$の確率でランダムに行動します.
上図では,デモンストレーションでの学習(左)とシミュレーションでの学習(右)の両方において,NACが最も効率よく学習できていることがわかります.DQfDも同様の性能を示しています.Behaviour Cloning(CEM)は,デモンストレーションではうまく学習できていますが,シミュレーションでは性能が落ちてしまっています.全ての手法において,最終的に学習することはできていますが,NACとDQfDはデモンストレーションでの学習を生かし,比較的高いパフォーマンスから学習することができています.
Human demonstrations(Torcs)
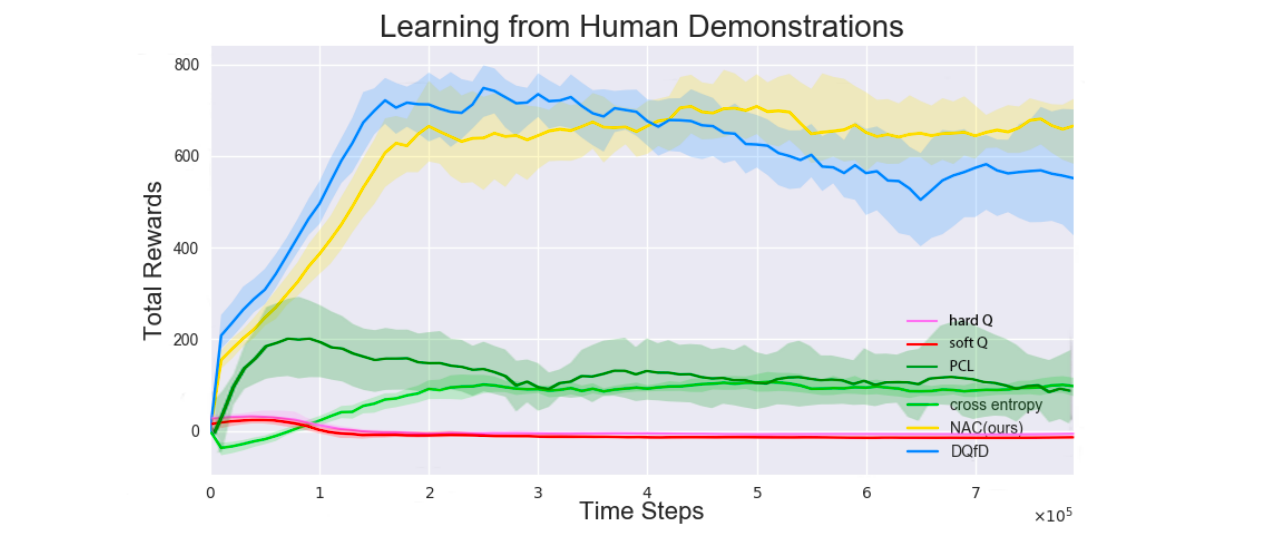
また,人間によるデモンストレーションでは,学習済みエージェントに比べて多様な行動を選択していると考えられます.これは試行による差と,個人による差の2つ影響があり,エージェントによるデモンストレーションの場合に比べ,難しい問題設定であると考えられます.ここでは,Torcsのゲームを3人の素人にそれぞれ3時間ずつプレイしてもらい,デモンストレーションを集めました(約$150k$サンプル,ただし,このうち$4.5k$サンプルはベルマン誤差を観測するために利用.)
上図から,学習初期はDQfDはNACより良い性能を示しているものの,徐々にNACが上回る結果となったことがわかります.また,Behaviour Clonengは学習に失敗していることがわかります.
Imperfect demonstrations(Torcs)

不完全なデモンストレーションを作成するため,学習済みのエージェントの行動を特定の確率(30%)で最悪の行動$arg\min_a Q(s,a)$に置き換えます.
上図から,Behaviour Cloningは不完全なデモンストレーションに影響され,うまく学習できていないのに対し,NACでは学習できていることがわかります.これは,模倣しているのではなく,強化学習により行動の価値を推定していることが要因だと考えられます.
Small demonstration(Torcs)

ここでは,$10k, 150k, 300k$のデモンストレーションから学習させました.
上図は$10k$での結果しか示していません(他は論文付録を参照してください)が,$150k$より多い,十分なデモンストレーションがある場合にはNACは他の手法よりも性能が良く,少ない場合($10k$)でも,教師あり学習を行なっている他の手法と同等の性能を示していることがわかります.
まとめ
この論文では,デモンストレーションと自らのシミュレーションの両方から学習することのできる強化学習の手法,**Noemalized Actor-Critic(NAC)**を提案しました.NACでは,デモンストレーションとシミュレーションの両方の学習において,単一の目的関数を用いており,デモンストレーションに関しても,模倣学習ではなく強化学習を用いています.
検証実験により,NACは不完全なデモンストレーションにもロバストで,その後のシミュレーションによる追加学習の良い初期方策を見つけることができることを示しました.