以下の論文の解説(まとめ)になります.
Soft Actor-Critic for Discrete Action Settings
この論文は,Imperial College Londonの方が2019年10月にarxivで公開した論文です.
連続行動空間での強化学習において,サンプル効率と学習の安定性を大きく改善した手法Soft Actor-Critic(SAC)を,離散行動空間での強化学習に適用した手法SAC-Discreteを提案しています.SACを離散行動空間に落とし込むことは度々Stack Overflow等で議論されていて注目度が高かったため,今回紹介させていただきました.
SACのアルゴリズムを知らない方は,先にそちらの学習をお勧めします.(本記事は,SACの詳細を知っている方を想定しています.)
また,PyTorchでの再現実装をgithubに載せています.
元論文
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
参考
記事中の図は,特に記載がない限りすべて論文からの引用です.
記事内容に不備がございましたら,ご指摘頂けると助かります.
概要
この論文は,連続行動空間でのmodel-freeの強化学習において人気な手法Soft Actor-Critic(SAC)を,離散行動空間に適用した手法SAC-Discreteを提案しています.
Soft Actor-Critic(SAC)
簡単に,SACのアルゴリズムの概要を振り返りたいと思います.以下の定式化は,連続行動空間上での手法を提案した,SACの元論文(Haarnoja et al. (2019))と同一のものですが,連続・離散行動空間のどちらでも成り立つことに注意してください.
概要
SACは,TRPOやPPOなどの課題=サンプル効率と,DDPGやTD3の課題=学習の安定性をそれぞれ
- off-policyの学習による高いサンプル効率
- 方策のエントロピー最大化項を加えて,よりdiverseな探索による学習の安定化
により改善しました.
SACの目的関数は,以下のようにMax-Entropy項を含んだ期待収益になります.
\sum_{t=0}^T \mathop{\mathbb{E}}_{(s_t, a_t)\sim \tau_\pi}[\gamma^t(r(s_t, a_t) + \alpha \mathcal H(\pi(\cdot|s_t)))]
ここで,$\alpha$はエントロピー項の重み係数,$H(\pi(\cdot|s_t)) = - \log \pi(\cdot|s_t)$は方策のエントロピーです.
上記の目的関数を最大化することは,最適方策のsoft Q関数が最大となるような行動を選択し続ける方策をとることと等価です.ただし,ある方策$\pi$のsoft Q関数: $Q(s_t, a_t)$は,soft価値関数: $V(s_t)$ と報酬関数: $r(s_t,a_t)$ により定義される(soft)ベルマンオペレータ: $\mathcal T^\pi$ を繰り返し適用した極限値として定義されます.
\begin{align}
T^{\pi} Q(s_t, a_t)
&= r(s_t, a_t)
+ \gamma \mathop{\mathbb{E}}_{s_{t+1}\sim p}[V(s_{t+1})] \\
V(s_t)
&= \mathop{\mathbb{E}}_{a_t \sim \pi} [Q(s_t, a_t) - \alpha \log \pi(a_t | s_t)]
\end{align}
SACでは,soft Q関数の推定と方策の更新を繰り返すことで目的関数の最大化を行います.ただし,soft Q関数と方策をそれぞれパラメータ$\theta$,$\phi$で関数近似します.また,エントロピー係数$\alpha$の最適化のアルゴリズムも提案していて,アルゴリズム全体のハイパーパラメータを削減したことも一つの大きな寄与です.
soft Q関数の推定
soft Q関数の推定では,以下の誤差関数を最小化します.
J_Q(\theta) = \mathop{\mathbb{E}}_{(s_t, a_t) \sim D}[\frac{1}{2}\left( Q_{\theta}(s_t, a_t) - (r(s_t, a_t) + \gamma \mathop{\mathbb{E}}_{s_{t+1} \sim p}[V_{\bar\theta}(s_{t+1})]) \right)^2]
これは,soft Q関数のTD誤差を表していて,$\bar \theta$はターゲットネットワークのパラメータ,$D$はリプレイバッファを表しています.このTD誤差を最小化することで,soft Q関数の推定が正確なものになります.
方策の更新
また,方策の更新では,以下の目的関数を最小化することで状態$s_t$において一番soft Q関数の大きい行動$a_t \sim \pi_\phi$を選択するような方策を獲得できます.
J_\pi (\phi) = \mathop{\mathbb{E}}_{s_t \sim D} [\mathop{\mathbb{E}}_{a_t \sim \pi_\phi}[
\alpha \log(\pi_\phi(a_t|s_t)) - Q_\theta(s_t, a_t))
]]
ただし,連続行動空間では確率的方策を陽に記述することができないため,一般的に分布からのサンプルの勾配を逆伝搬することができません.そこで,確率分布を特定のパラメータで表現し(e.g. 平均・分散でガウス分布をパラメトライズする),re-parametrization trickを用いて勾配を計算するテクニックを用います.すなわち,確率性を持つ部分 $\epsilon_t$ をモデルと切り離し,確率的な行動のサンプリングを,以下のように(状態に関して)決定的に計算できるようにします.
a_t = f_\phi (\epsilon_t; s_t)
例えば,ニューラルネットワークがガウス分布の平均$\mu$と標準偏差$\sigma$を出力したとき,
a_t \sim \mathcal N (\mu, \sigma^2)
のようにすると,ネットワークに勾配情報を逆伝搬することはできませんが,
a_t = \mu + \sigma\epsilon_t \\
\epsilon_t \sim \mathcal N(0, I)
とすることで,逆伝搬できるようになります.
エントロピー係数の最適化
SACでは,soft Q関数の推定と方策の更新以外にも,エントロピー係数$\alpha$の自動最適化やClipped Double-Qなどのテクニックも用いています.ここでは,$\alpha$の最適化のみについて説明します.
エントロピー係数$\alpha$の最適化では,以下の目的関数を最小化します(導出は解説記事を参照ください).
J(\alpha) = \mathop{\mathbb{E}}_{s_t \sim D, a_t \sim \pi_\phi} [-\alpha (\log\pi_\phi(a_t|s_t) + \bar H)]
ただし,$\hat H$はターゲットエントロピーで,方策の期待エントロピーが$\bar H$に近づくように$\alpha$を更新をします.
SAC-Discrete
以下では,連続行動空間を想定して定式化されたSACを,離散行動空間に適用するために修正を行なっていきます.ここで加える修正の全ては「$\pi(a_t|s_t)$は,連続行動空間では確率密度を表していたが,離散行動空間では確率となる.」ことに由来します.
SACの修正点
この論文では,以下の5つの修正を行なっています.
-
関数近似したsoft Q関数の入出力の形式を変える.
- $Q: S \times A \to \mathbb R$ から $Q: S \to\mathbb R^{|A|}$とする.
- 離散行動空間では,行動次元$|A|$が有限なので後者の定式化が可能.
- 学習の効率化が期待されると共に,期待値が直接計算可能になる.(修正3,4,5)
-
確率分布(e.g. ガウス分布)のパラメータを出力していたものを,確率分布そのものを出力にする.
- (ガウス分布の場合) $\pi : S \to \mathbb R^{2|A|}$ から $\pi \to [0, 1]^{|A|}$ とする.
- $\pi(a_t|s_t)$は確率密度ではなく確率なので,後者の定式化が可能.
- ネットワークの出力にSoftmaxをつけることで実現.
-
soft価値関数の計算(soft Q関数の期待値計算)を,サンプリングではなく直接計算する.
- $V(s_t):= \pi(\cdot|s_t)^T [Q(s_t) − \alpha \log(\pi(\cdot|s_t))]$
- soft Q関数のターゲットの推定の分散が緩和される.
-
同様に,エントロピーの期待値計算を,サンプリングではなく直接計算する.
- $J(\alpha) = \pi(\cdot|s_t)^T [-\alpha(\log\pi_\phi(\cdot|s_t) + \bar H)]$
- 推定の分散が緩和される.
-
$\pi(\cdot|s_t)$が分布そのものを表しているので,re-parametrization trickが必要ない.
- $J_\pi (\phi) = \mathop{\mathbb{E}}_{s_t \sim D}[ \pi_\phi(\cdot|s_t)^T [\alpha \log (\pi_\phi (\cdot|s_t)) - Q_\theta(s_t, a_t)]]$
- より簡潔なモデルが実現.
アルゴリズムまとめ
アルゴリズムの主な流れを以下に示します.ただし,$\lambda$は学習率,$\tau$はターゲットネットワークの平滑化係数です.
- ネットワークのパラメータ$Q_{\theta_1}$,$Q_{\theta_2}$,$\pi_{\phi}$をそれぞれ初期化する.
- ターゲットネットワーク$Q_{\bar \theta_1}$,$Q_{\bar \theta_2}$をそれぞれ初期化(単にコピー)する.
- 事前に決めた環境ステップ数だけ繰り返し
- 各ステップで,行動 $a_t \sim \pi_{\phi}(\cdot|s_t)$ を選択し,遷移をリプレイバッファ$D$に保存する.
- 環境ステップあたりの勾配ステップ数だけ繰り返し
- soft Q関数の推定の更新: $\qquad;;\theta_i \leftarrow \theta_i − \lambda_Q \nabla_{\theta_i} J(\theta_i);;(i=1,2)$
- 方策の更新: $\qquad \qquad \qquad ;;\phi \leftarrow \phi − \lambda_{\pi} \nabla_{\phi} J_{\pi}(\phi)$
- エントロピー係数の更新: $\qquad;;\alpha \leftarrow \alpha − \lambda \nabla_{\alpha} J(\alpha)$
- ターゲットネットワークの更新: $;;\bar \theta_i ← \tau \theta_i + (1 − \tau)\bar \theta_i;; (i=1,2)$
検証
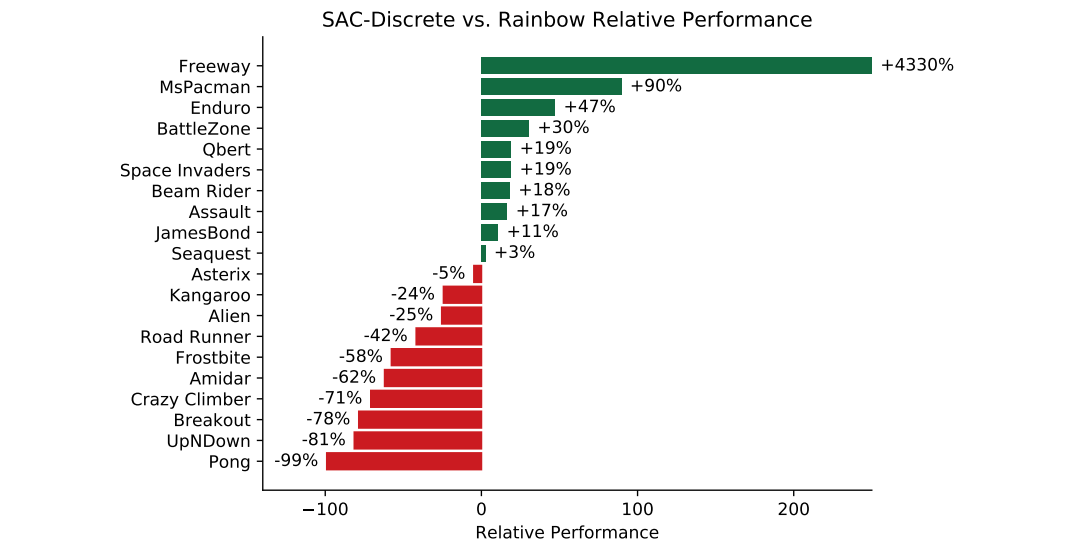
この論文では,既存のmodel-freeアルゴリズムの中で特にサンプル効率に優れたRainbow(Hessel et al. (2018))と,Atariの49ゲームのうち20ゲームで比較検証しています.上図は,10万ステップでの性能の5シード平均をRainbowに対するSAC-Discreteの相対評価で表しています.ハイパーパラメータやネットワークの構造など,設定の詳細は論文付録を参照ください.
検証結果から,SAC-DiscreteはRainbowと平均的に同等の性能であることが読み取れます.また,相対的な得意・不得意がありそうな感じがします.また,SAC-Discreteに関してはハイパラチューニングをしておらず,もっと性能が上がる可能性はある,とのことでした.
結論
この論文では,SAC-Discreteと呼ばれる,Soft Actor-Criticを離散行動空間に落とし込んだアルゴリズムを提案しました.また,検証実験によりRainbowと同等の性能であることを示しました.
僕が読んだのは公開直後のバージョンなので,今後定量的な検証実験が追加されるのを期待しています.