こんにちは,Nakai[Twitter]といいます.
今回は研究でBoTNet[論文][解説記事]を用いる機会があったので,実装方法をシェアできればと思います.
また,個人的に引っかかったMulti Head Self-Attention(MHSA)についてもまとめてあります.
間違い,ご質問等ございましたらぜひお気軽にコメントやTwitterまでDMしていただければと思います.
Transformarの理解に重要になってくる$query,key,value$についても触れていくつもりです.この記事が読んでくださった方のなにかの参考になれば幸いです.
構成
今回の記事は,
- MHSAの内容理解
- BoTNetの実装
の2部構成です.
論文全体の解説記事ではないので,Ablation studyや結果などは論文または解説記事を参照してください.
また,対象として基本的なResNetの構造の知識,実装の方では(Pytorchを用いた)画像認識プログラムの知識を持っている方としています.
BoTNet
BoTNetはBottleneck Transformer Networkの略で,その名の通りResNetのBottleneck部分にself-attentionを使ったMHSAを用いています.
以下がBoTNetに用いられているBottleneck Transformerです.(左は通常のResNet Bottleneck)
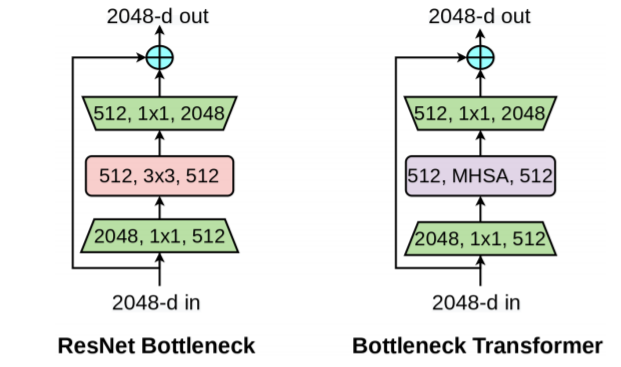
違いはただ一つ,$3\times 3Convolution$がMHSAに置き換わっています.
また,構造自体もResNetから置き換えただけなので,見慣れた形になっています.
以下がその図です.左がResNet50,右がBoTNet50です.
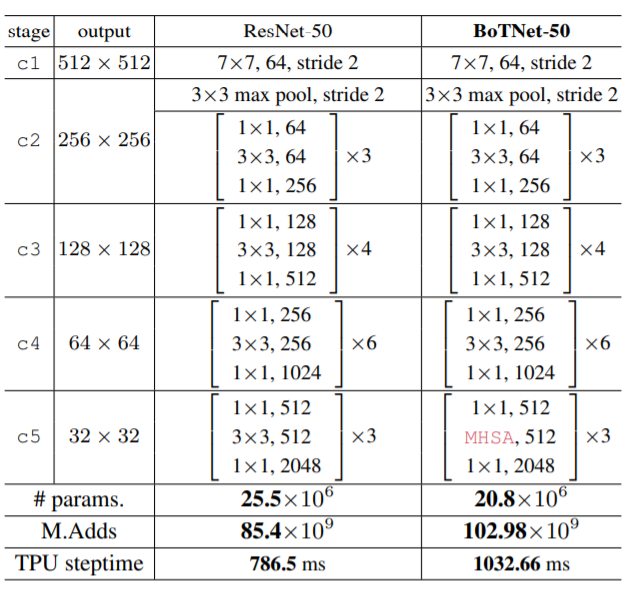
BoTNetに用いられるMHSAは,一度の処理で入力特徴の高さおよび幅の積の回数分の計算を必要とします.
つまり,例えば入力が$200\times 200$だと$40,000$回,後述するHeadの数が4(default)だと計$160,000$回以上の計算を必要とするため,計算コストが非常に高いです.そのため,BoTNetでは特徴マップのサイズの小さいResNetの最後のc5(Pytorch公式のResNet50ならlayer4)のみMHSAを用いています.
MHSA
それでは本題の1つ目,BoTNetの肝であるMHSAについてです.
まずは構造の概要図を示します.
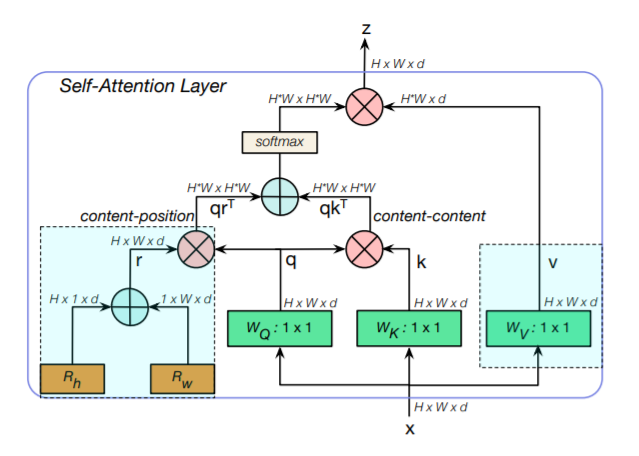
Headの数の分だけ,これが並列に繋がります.
順番に見ていくと...
Query,Key,Valueの生成
右下の以下の部分が$Query,Key,Value$を構成する部分です.
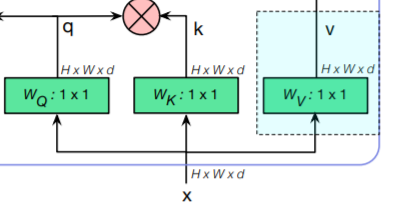
入力$x$から,Attentionにおける基本要素である$q : Query, k:Key, v:Value$を構成します.
Attentionは出力特徴の下地となる$V$,Attentionの元になる$Q$,その$Q$の中から適切なAttentionを呼び起こす,あるいは生成するための$K$を用いて
Attention = (QK^T)V
と定式化できます.
詳しくは補足に回しますが,Transformerやself-attentionの記事には大方解説されているのではと思います.
位置エンコーディング
左下の以下の部分が,入力特徴のattentionを生成するための位置情報を司る,位置エンコーディング$r$になります.
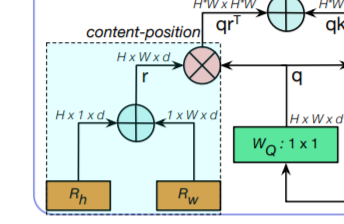
$R_h, R_w$はそれぞれ
R_h =
\begin{pmatrix}
h_1\\
h_2\\
\vdots \\
h_H
\end{pmatrix}
,
R_w =
\begin{pmatrix}
w_1 & w_2 & \cdots w_W
\end{pmatrix}
が$d$次元分重なったものであり,そのelement wise sumをとった$r$は
r =
\begin{pmatrix}
h_1+w_1 & h_1+w_2 & \cdots & h_1+w_W\\
h_2+w_1 & h_2+w_2 & \cdots & h_2+w_W\\
\vdots & \vdots & & \vdots\\
h_H+w_1 & h_H+w_2 & \cdots & h_H+w_W
\end{pmatrix}
とかけます.これにより,位置情報を取得します.
Attention mapの完成
以下の部分で,これまで生成した位置エンコーディング$r,q,k$からAttention mapを作成します.
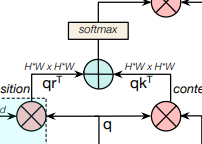
入力のみから得られた$qk^T$,位置エンコーディングと$q$から得られる$qr^T$の2つのelement wise sumをとり,softmaxに通してAttention mapの完成です.
MHSAのまとめ
あらためてMHSAの全体像を見てみます.
MHSAの流れをまとめると
- 入力$x$から,それぞれ役割の異なる$q,k,v$を生成
- $H\times 1 \times d$および$1\times W\times d$のTensorから位置エンコーディング$r$の生成
- $q,k,r$をつかって$qk^T$および$qr^T$の生成
- Attention mapを$qr^T + qk^T$として生成
- 生成したAttention mapと$v$をかけ合わせ,出力とする.
なお,この処理はHeadの数だけ行われ,最終的にそれぞれのHeadから得られた$z$をconcatします.
BoTNetの実装
おそらく最も簡単なPytorch実装はこちらでしょう.(ちなみに,公式実装はTensorFlowです)
READMEのBotNetという項目にかかれているとおりに実装すれば,簡単に実行できます.
ただし,以下の引数は変える必要があるかもしれません.
layer = BottleStack(
dim = 256, #BottleStackへの最初の入力次元
fmap_size = 56, # 入力時の特徴マップのサイズ
dim_out = 2048, #layer4の出力次元,
proj_factor = 4, #projection factor : Bottleneckのconv1で入力次元をどこまで削減するか
downsample = True, #strideを2にするか1にするか,画像サイズが小さいときはFalseにするといい
heads = 4, #headの数
dim_head = 128, #headの次元,
rel_pos_emb = True, #位置エンコーディングの生成方法,
activation = nn.ReLU()
)
fmap_sizeに関しては,正確にわからなければ,一度実行してみてError文からサイズを確認すると良いと思います.
また,ご自身で作ったのResNet構造に組み込みたいという方はbottleneck-transformer-pytorchフォルダ内のbottoleneck_transformer_pytorch.pyを参照してみると良いかと思います.
bottoleneck_transformer_pytorch.pyの中身については,アインシュタインの縮約記法というあまり見ない実装の仕方をしていますが,そこそこシンプルに書かれています.勉強にもなるので,最初は自分の作ったResNetの中に組み込み,中身を詳しくいじるために自分で書き直してみるのが良いでしょう.
まとめ
いかがだったでしょうか.今回は最近流行り(自然言語ではすでに流れが去っているようですが)のSelf-Attentionを組み込んだBoTNetを紹介しました.
$q,k,v$などあまり馴染みのない概念が出てくるので最初こそ少し戸惑いましたが,そこを乗り越えてしまえばおそらく畳み込みより簡単なのではないでしょうか.
今後とも画像認識,趣味程度に自然言語処理に手を出していこうと思っていますので,よろしければLGTMおよびTwitterフォローよろしくおねがいします.
補足:q,k,vの意味について
Attentionの理解の肝になる$query,key,value$について,MHSAではルートの異なる3つの入力のような書き方をしていますが,本来の自然言語における意味を少し書ければと思います.
そもそも
$$Attention = (QK^T)V$$
という式はAttention Is All You Needという2017年のTransformerが初めて世に出た論文で,Attentionを定式化するときに用いられた考え方です.
人間は文章や映像を見てそれを認識しようとするとき,入力のみで判断しようとするわけではありません.与えられた入力と,記憶や経験などの過去の情報をもとに判断します.
この過去の情報に当たる部分が$query$です.
しかし,この$query$全てを入力に適応してしまえば,訳の分からないことになります.$query$を使うと言っても,適切な$query$だけで十分です.そのため,どの$query$を使うかを入力によって決定します.そのために用いるのが,入力から生成される$key$になります.$key$は文字通り,適切な$query$を呼び起こすための鍵となるのです.類似度を用いて$query$を呼び起こすので,式は$QK^T$となります.(内積を取ると,Cos類似度が出てきます.$Q$と$K$が近ければ近いほど大きな値を取る式です)
そして,最後に$value$です.これは入力そのままです.強いて言うなら$QK^T$に合わせるように多少サイズをいじったりします.この$value$に,先程呼び起こされた$query$である$QK^T$をかけ合わせて,Attenitonの完成です.
よって式は,
$$Attention = (QK^T)V$$
となります.
正確に書くと,
$$Attention(x) = (Q_{\theta}K^T_x)V_x$$
あるいは今回の場合
$$Attention(x) = (Q_xR_{\theta}^T + Q_xK^T_x)V_x$$
となるかと思います.ここで,$x,\theta$はそれぞれ入力とモデルの持つパラメータです.
図でまとめると,以下のような感じです.
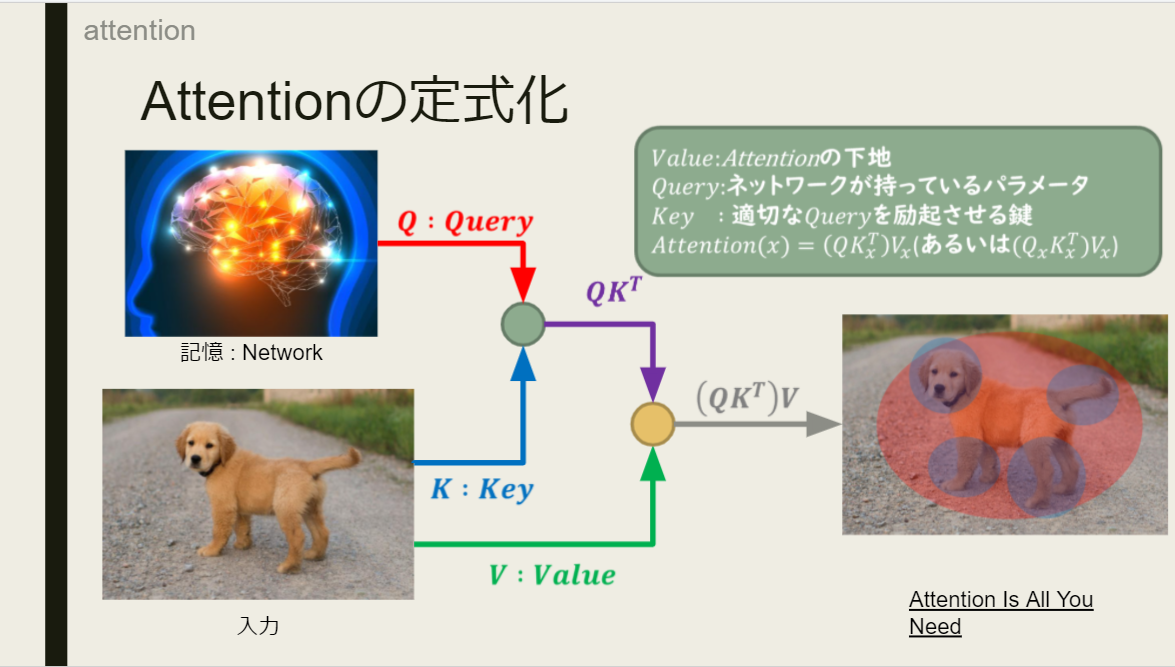
(自分で作ったスライドから引用しています)
余談
個人的には上で実装したコード,紹介しといてなんですが少し疑ってます.
それは,BottleStackの引数dimについてと,
model = nn.Sequential(
*backbone[:5],
についてです.論文の構造の通り,ResNetの最終ブロックにMHSAを配置するのであれば,dim=1024になるはずですし,同じ理由で*backbone[:5] -> *backbone[:7]になるのではないかと,実装しながら思っていました.
なので,プライベートで使う以外で利用を考えていらっしゃいましたら,一度しっかり中身を見ることをおすすめします.