現時点で、Databricks SQL(Redash)にはヒストグラムを描画するモードがありません。そこで、SQLでヒストグラムを描画する方法を見ていきます。
サンプルデータ
サンプルのデータとしてこちらの記事でも使っている、かつ、Databricksのサンプルデータセットに含まれるDiamondsデータを使って、priceカラムのヒストグラムを描く方法を具体的に見ていきます。
SELECT * FROM diamonds limit 10;
(結果)
+---+-----+---------+-----+-------+-----+-----+-----+----+----+----+
|_c0|carat| cut|color|clarity|depth|table|price| x| y| z|
+---+-----+---------+-----+-------+-----+-----+-----+----+----+----+
| 1| 0.23| Ideal| E| SI2| 61.5| 55.0| 326|3.95|3.98|2.43|
| 2| 0.21| Premium| E| SI1| 59.8| 61.0| 326|3.89|3.84|2.31|
| 3| 0.23| Good| E| VS1| 56.9| 65.0| 327|4.05|4.07|2.31|
| 4| 0.29| Premium| I| VS2| 62.4| 58.0| 334| 4.2|4.23|2.63|
| 5| 0.31| Good| J| SI2| 63.3| 58.0| 335|4.34|4.35|2.75|
| 6| 0.24|Very Good| J| VVS2| 62.8| 57.0| 336|3.94|3.96|2.48|
| 7| 0.24|Very Good| I| VVS1| 62.3| 57.0| 336|3.95|3.98|2.47|
| 8| 0.26|Very Good| H| SI1| 61.9| 55.0| 337|4.07|4.11|2.53|
| 9| 0.22| Fair| E| VS2| 65.1| 61.0| 337|3.87|3.78|2.49|
| 10| 0.23|Very Good| H| VS1| 59.4| 61.0| 338| 4.0|4.05|2.39|
+---+-----+---------+-----+-------+-----+-----+-----+----+----+----+
結論
以下のクエリでヒストグラムが描画できます。
他のテーブルでこのクエリを使用する場合に、クエリの中で変更する部分は以下の通りです。
diamondsprice
WITH const AS (
SELECT
round(
3.49 * stddev(price) / pow(count(1), 0.33),
0
) AS bin_width
FROM
diamonds
)
SELECT
floor(d.price / const.bin_width) * const.bin_width AS price_range,
count(1) AS count
FROM
const,
diamonds d
GROUP BY
price_range
ORDER BY
price_range
(結果)
+-----------+-----+
|price_range|count|
+-----------+-----+
| 0.0| 126|
| 382.0| 8618|
| 764.0| 8226|
| 1146.0| 3040|
| 1528.0| 3489|
| 1910.0| 2548|
| 2292.0| 2494|
| 2674.0| 2042|
| 3056.0| 1656|
| 3438.0| 1581|
| 3820.0| 1707|
| 4202.0| 1871|
| 4584.0| 1683|
| 4966.0| 1438|
| 5348.0| 1153|
| 5730.0| 1000|
| 6112.0| 922|
| 6494.0| 855|
| 6876.0| 688|
| 7258.0| 666|
+-----------+-----+
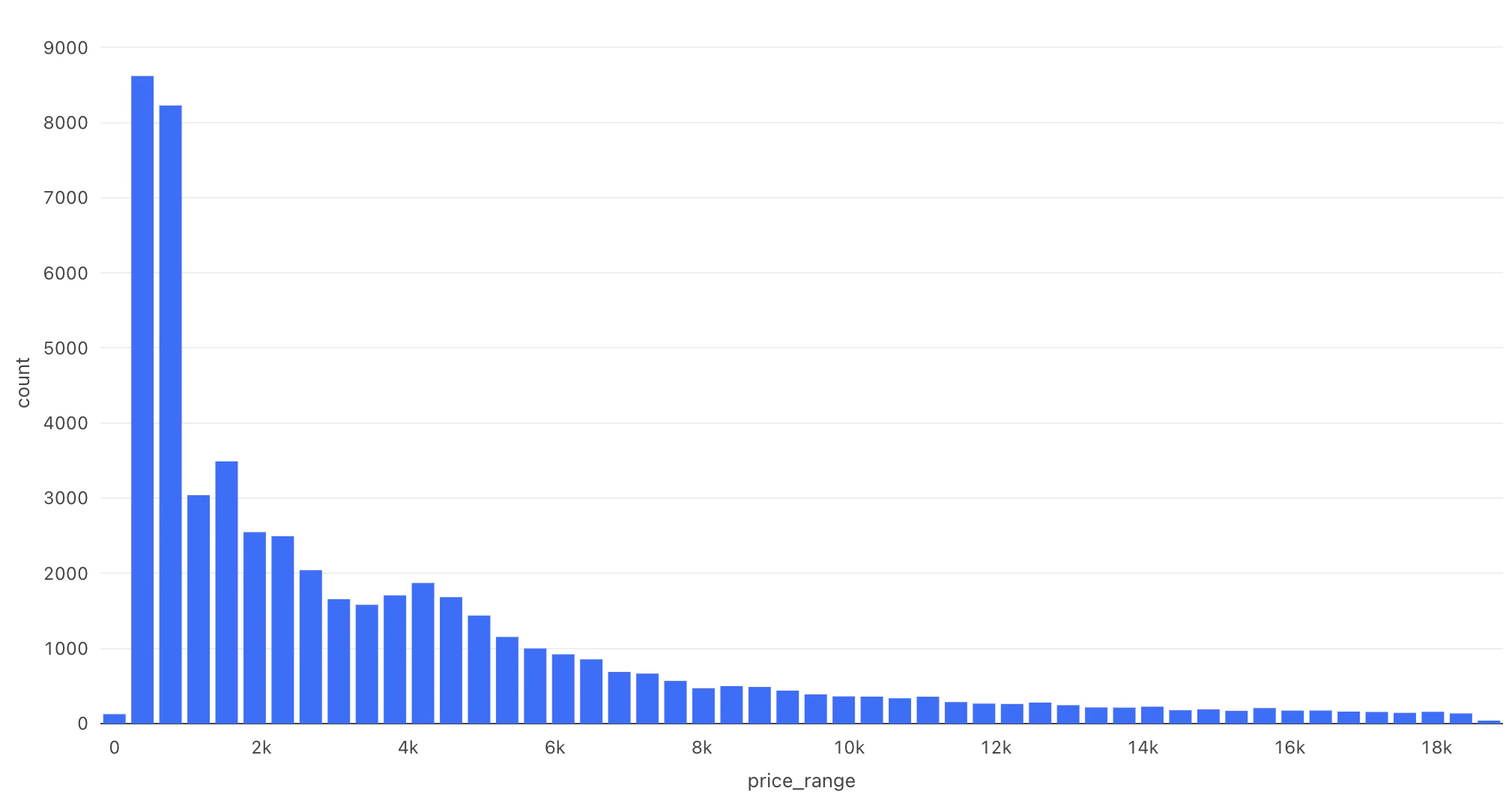
以下、上記の結論のクエリを組み立てていく過程・詳細を見ていきます。
Bin幅を決めて、値を丸める
ヒストグラムは、ある値の範囲内にいくつのデータ数があるのかを示すグラフです。この値の幅をBin幅と言います。そして適切なBin幅は、そのデータの値の大きさと範囲によって変わってきます。
ここでは元データからのpriceの値からとりあえずBin幅=100くらいでやってみましょう。
(このあと、データのサンプル数と対象の値の分布から最適なBin幅を計算する方法を取り込みます。)
まずは、priceの値をBin幅100ごとに丸めます。
-- Bin幅で丸める(`price`カラムも理解のため出しておくが実質不要)
SELECT price, floor( price / 100 ) * 100 AS price_range FROM diamonds
(結果)
+-----+-----------+
|price|price_range|
+-----+-----------+
| 326| 300|
| 326| 300|
| 327| 300|
| 334| 300|
| 335| 300|
| 336| 300|
....
丸めた値ごとに集計する
GROUP BY price_rangeでそれぞれのカウントを集計する。
SELECT
floor( price / 100 ) * 100 AS price_range,
count(1) AS count
FROM diamonds
GROUP BY price_range
ORDER BY price_range
(結果)
+-----------+-----+
|price_range|count|
+-----------+-----+
| 300| 247|
| 400| 1482|
| 500| 2380|
| 600| 2828|
| 700| 2846|
| 800| 2544|
| 900| 2172|
| 1000| 1857|
...
試しにプロットする
このBin幅で描画をしてみます。適当に決めたBin幅ですが、結果的に良いものになったようです。

ただし、この方法だと、対象データを変更する度に、データの値を眺めて、ヒストグラムのBin幅を決める必要があり、手間がかかります。実は、Bin幅の決め方はある程度定式化されていますので、それを取り込んでみましょう。
Bin幅を自動で決める
Bin幅の決め方はさまざまな方法がありますが、その中でも有名なものに「Scottの選択」というものがあります。今回はこれを使ってみます。
Bin_{width} = \frac{3.49 \sigma}{\sqrt[3]{N}}
ここで、$\sigma$ はヒストグラムの対象データの標準偏差、$N$はデータ数になります。これをSQLで書くと以下のようになります。
SELECT 3.49 * stddev(price) / pow(count(1), 0.33) AS bin_width
FROM diamonds
(結果)
+-----------------+
| bin_width|
+-----------------+
|382.1261206268962|
+-----------------+
これでも良いのですが、ヒストグラム結果を評価・理解しやすくするために、Bin幅は整数の方が良いでしょう。丸めます。
SELECT round( 3.49 * stddev(price) / pow(count(1), 0.33), 0) AS bin_width
FROM diamonds
(結果)
+---------+
|bin_width|
+---------+
| 382.0|
+---------+
以上で、全ての値、クエリが整いました。
一つのSQLにまとめる
最後に、今までのクエリをまとめます。WITH句を使って、Bin幅を算出しておき、それを後段のクエリで使います。
(既出、記事冒頭の「結論のクエリ」に同じ)
WITH const AS (
SELECT
round(
3.49 * stddev(price) / pow(count(1), 0.33),
0
) AS bin_width
FROM
diamonds
)
SELECT
floor(d.price / const.bin_width) * const.bin_width AS price_range,
count(1) AS count
FROM
const,
diamonds d
GROUP BY
price_range
ORDER BY
price_range