この記事は以下のウェビナーのダイジェスト版になります。より詳しくは以下のウェビナー(オンデマンド)を参照ください。
ウェビナー概要
ビッグデータのための分散処理フレームワークであるApache Sparkは今や大量ログデータ解析にとどまらず、Deep Learningを含む機械学習からSQLクエリエンジンとしてデータウェアハウス用途など様々な場面で活用されています。今回のセッションでは、Apache Sparkが誕生して現在に至るまでの流れ、何ができるのかの全体像・どこで使えるのかの具体例を実際のコードを交えて説明いたします。”Spark”は耳にしたことあるけど、どこから始めていいかわからない、何がそんなにいいのかわからない、などの疑問にお答えします。
対象
- Sparkの名前だけは聞いたことがあり、詳細を知りたい方
- OSS Sparkとの違いを知りたい方
- OSS Pandasとの違いを知りたい方
TL;TD (目次)
Sparkをはじめるにあたって、よく聞かれる質問を通して、全体像をつかんでいきます。
- Sparkはどうやって生まれたのですか? 👉 Hadoop/Map Reduceの弱点補完で生まれた。
- Sparkは何に使えるのか? 👉 大量ログ解析、ELT、機械学習、ストリーミング、など多種多様。
- Map/Reduceで書かないといけないのか? 👉 Dataframeが使える。
- 開発するのに使える言語は? 👉 Python, Scala, Java, SQL, R。
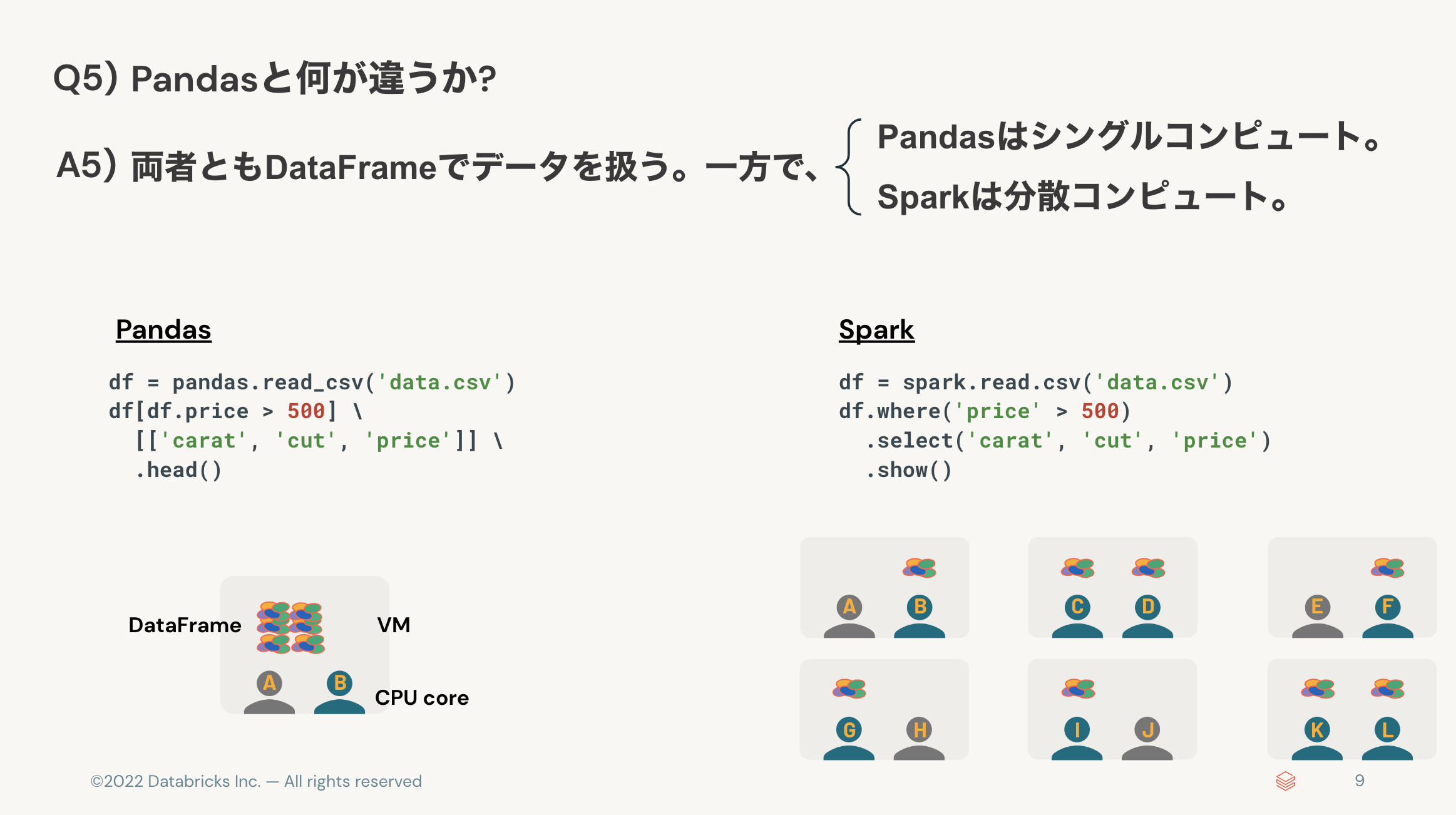
- Pandasと何が違うか? 👉 Pandasはシングルコンピュート、Sparkは分散コンピュート。
- Spark/Databricksとデータウェアハウス(DWH)の関係? 👉 DWHとしても使われている。
- 今あるPythonコードを全て書き換えないといけないのか? 👉 いいえ、UDFでコード資産を活かせる。
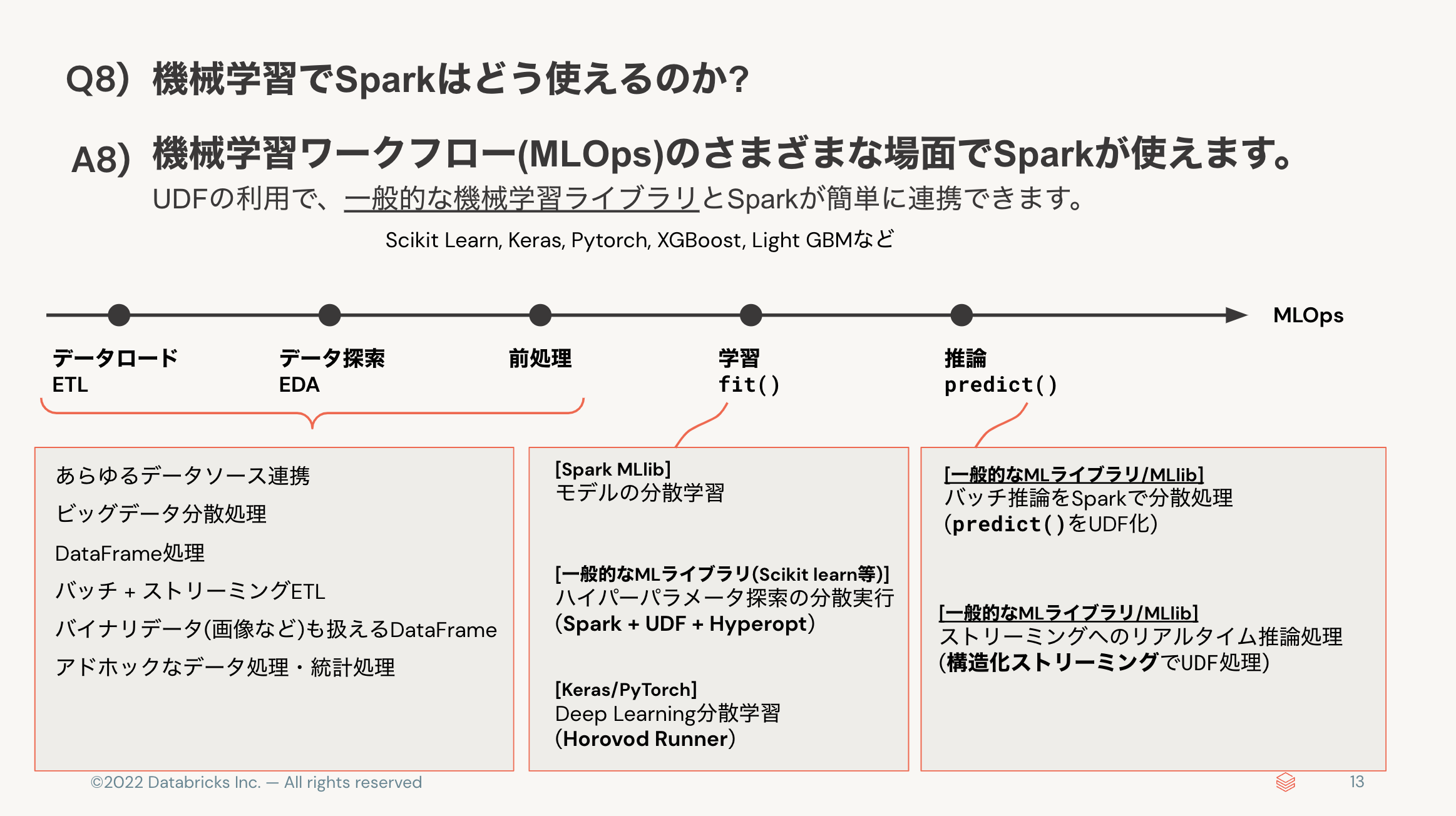
- 機械学習でSparkはどう使えるのか? 👉 前処理、モデル学習、推論をSparkで高速化できる。
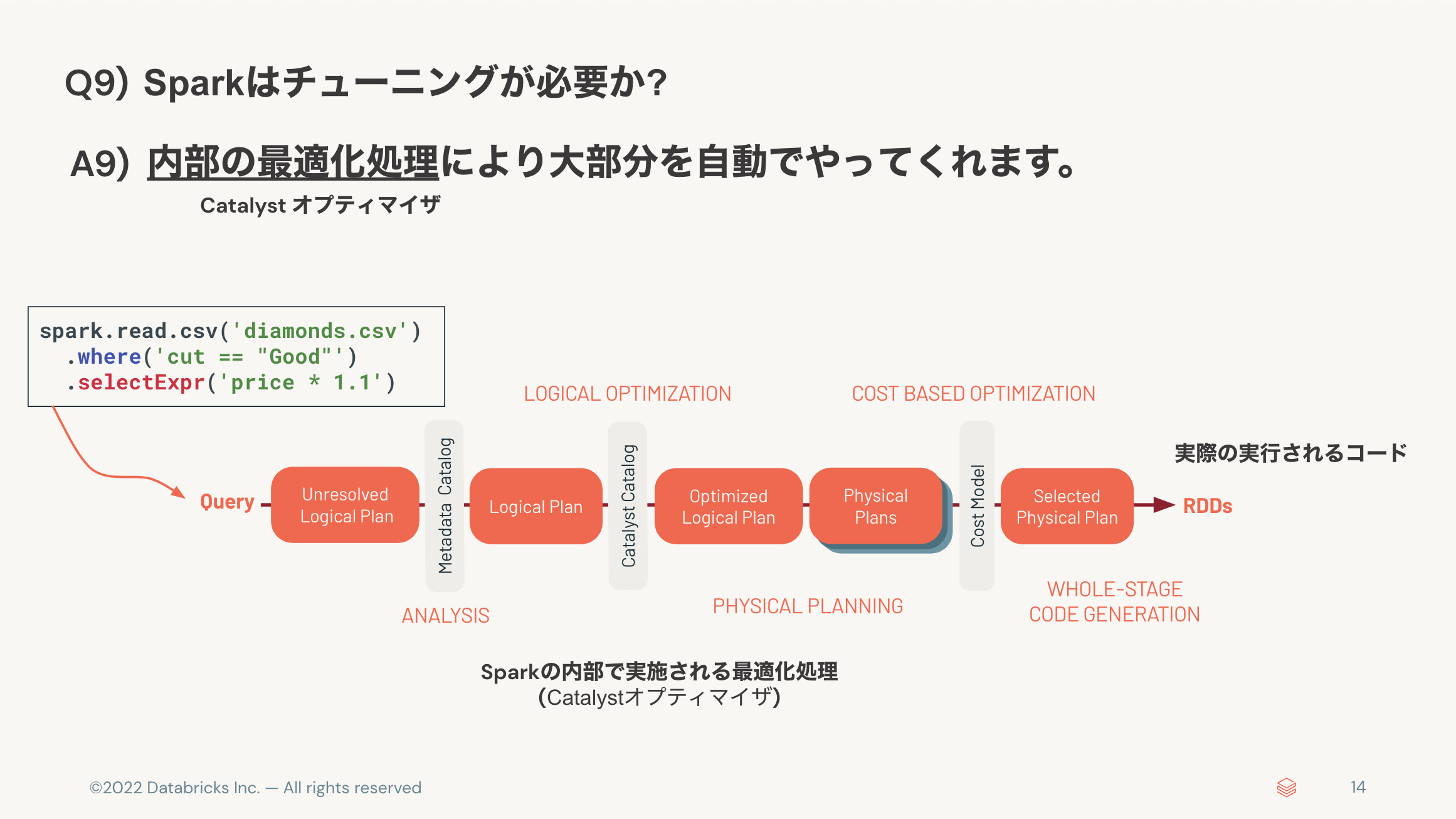
- Sparkはチューニングが必要か? 👉 大部分を自動でやってくれる。
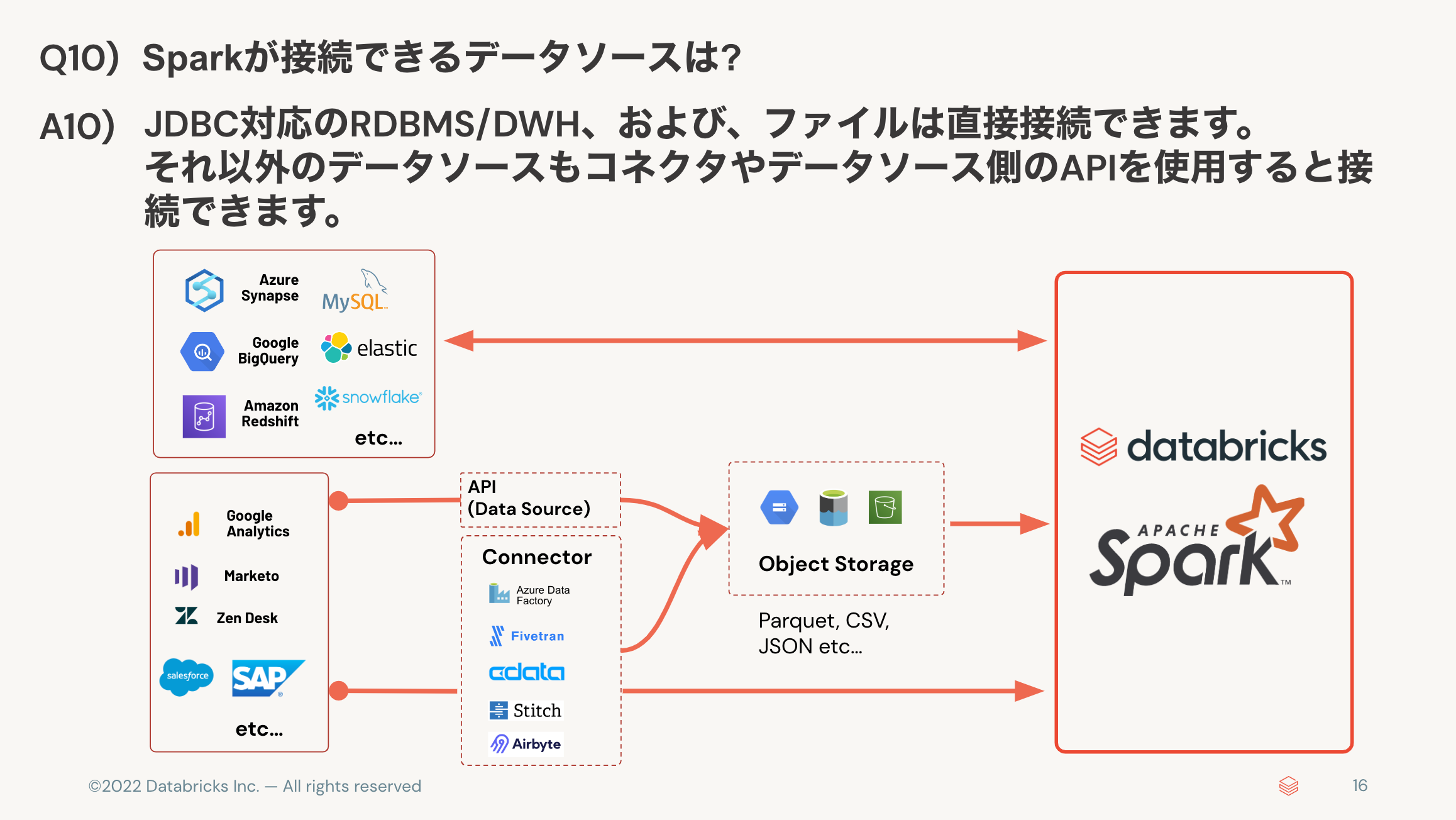
- Sparkが接続できるデータソースは? 👉 JDBC、ファイルは直結。それ以外はコネクタで接続。
- Sparkはバッチ処理のみ? 👉 ストリーミング処理もカバーできる。
- Sparkの環境構築はそうすればよいのか? 👉 クラウドサービスがおすすめ。
- クラウドのSparkサービスを使うと何が嬉しいのか? 👉 スケーラビリティ・弾性をフルに享受。
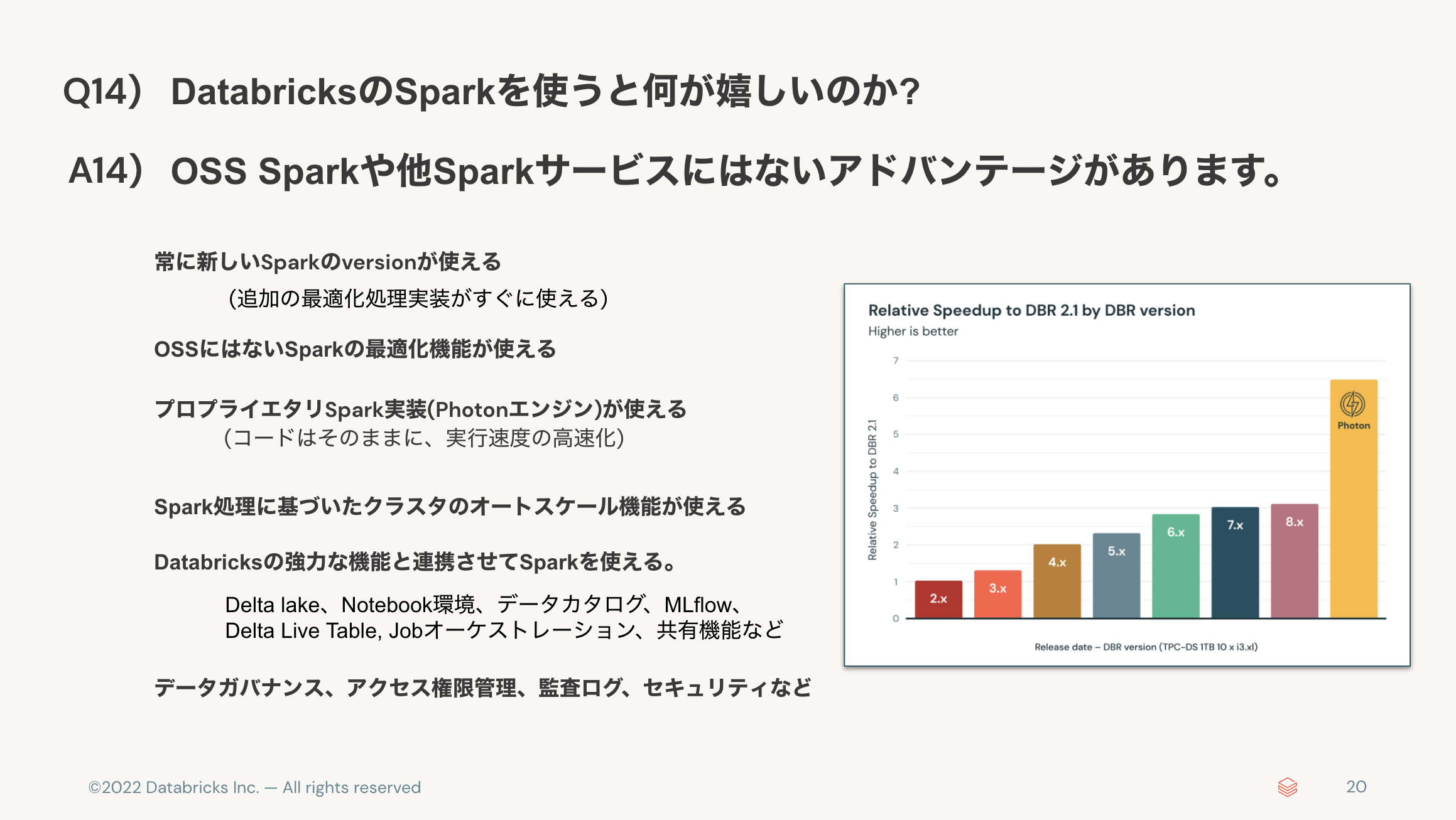
- DatabricksのSparkを使うと何が嬉しいのか? 👉 最適化されたマネージドなSpark環境。
- Sparkのドキュメントはどこを見れば良いですか? 👉 オープンソースなので、パブリックに膨大なドキュメント。
Q1) Sparkはどうやって生まれたのですか?

Q2) ビッグデータ処理の文脈でよく出てくるけど、Sparkは何に使えるのか?

Q3) Hadoopの置き換えか? Map/Reduceで書かないといけないのか?

Q4) 開発するのに使える言語は?

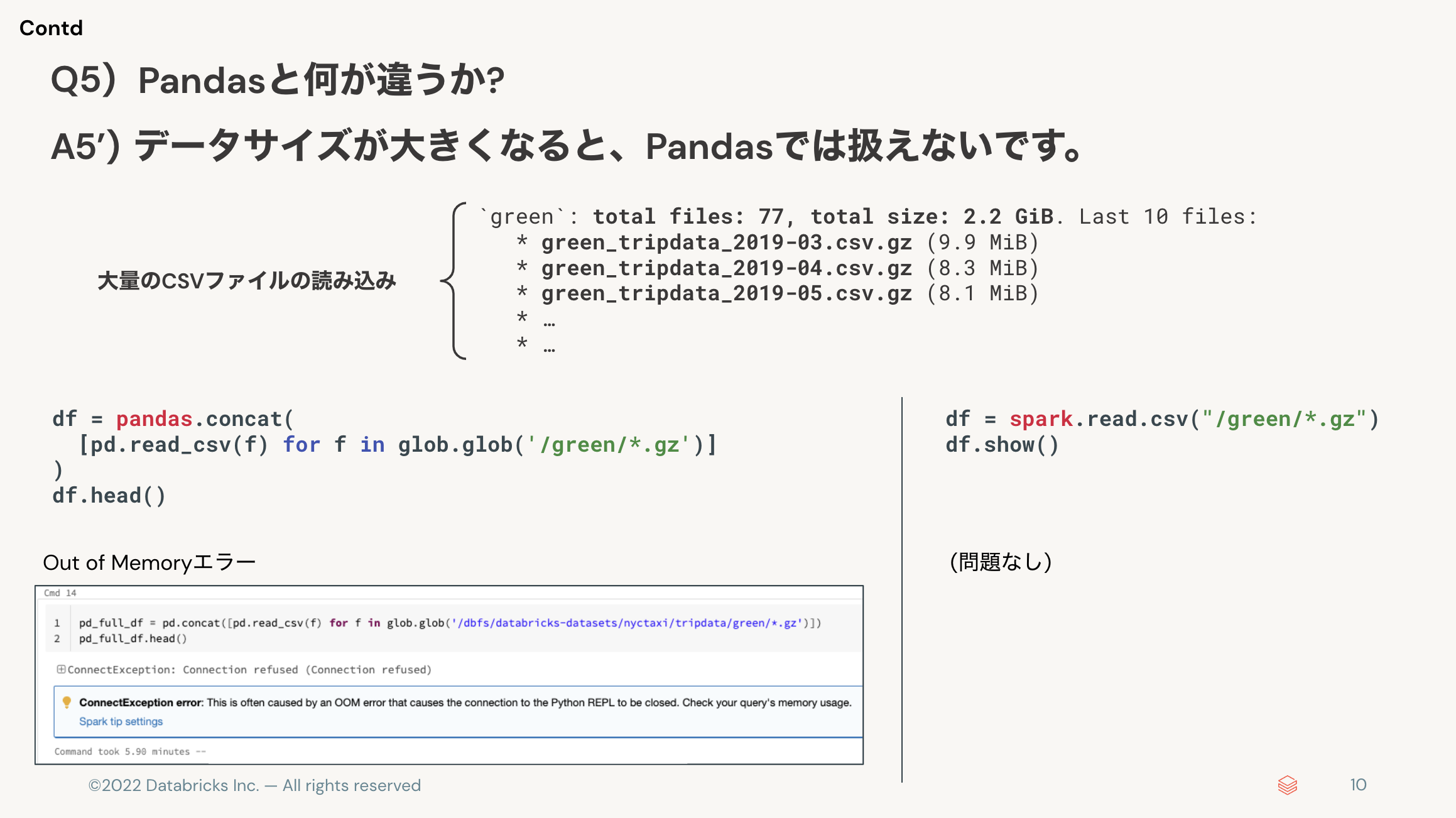
Q5) Pandasと何が違うか?
Q6) 最近、Spark/Databricksがデータウェアハウス(DWH)の文脈で出てくるけど、どういうことですか?

Q7) Sparkを使うには、今あるPythonコードを全て書き換えないといけないのか?

Q8)機械学習でSparkはどう使えるのか?
Q9) Sparkはチューニングが必要か?

Q10) Sparkが接続できるデータソースは?
Q11) Sparkはバッチ処理のみ?

Q12) Sparkを試してみたい。環境構築はどうすればよいのか?

Q13) クラウドのSparkサービスを使うと何が嬉しいのか?

Q14) DatabricksのSparkを使うと何が嬉しいのか?
Q15) Sparkのドキュメントはどこを見れば良いですか?

まとめ

