Supershipグループ Advent Calendar 2022の24日目の記事になります。
今年の4月に新卒入社してから、社内の有志でチームを作り(会社非公式)、Kaggleコンペに取り組みました。
| 参加コンペ | 期間 | 順位(/参加チーム数)(Top N%) |
|---|---|---|
| H&M Personalized Fashion Recommendations | 2/7 ~ 5/9 | 229位 (/2952チーム) (Top 8%) 🥉 |
| Google Smartphone Decimeter Challenge 2022 | 5/2 ~ 7/29 | 95位 (/ 571チーム) (Top 17%) 🥉 |
| Feedback Prize - English Language Learning | 8/30 ~ 11/29 | 95位 (/2,654チーム) (Top 6%) 🥉 |
ここからは、参加したコンペそれぞれの振り返りです。
最後まで読んでいただけると幸いですmm
①H&M Personalized Fashion Recommendations
有名なファストファッションブランドのH&M主催のレコメンド系のコンペです。
「ある期間で、客がどの商品を購入するのかを予測せよ」とシンプルなお題ですが、客数が約130万人で商品数が約10万点あるため、客一人一人に対して全商品をそれぞれ「買う場合は1、買わない場合は0」みたいなモデルを作るのは現実的ではありません。
このような場合、ある客に対して、「商品を買うとしたら、この中のどれかだろう」といった具合で、「候補」を生成しながらモデルを作る「ランキング学習」が上位陣に共通した解法でした。
解法
人気商品Top Nをそのまま予測として使うルールベースの手法の精度を超えるような、ランキングモデルを作成できませんでした。
開催期間の最後1ヶ月ほどから参加したこともあり、
- 人気商品Top N
- 色違いの商品
- よく一緒に買われている商品
などのような思いつく限りのルールベースの予測と、公開されていたディープラーニング系の手法の出力とアンサンブルしました。
結果&反省
銅メダルは取れました。
が、以下のような理由でほとんど書くことがありません。
- メダルは取れたけど、公開ノートブックを少し改造しただけなので、達成感がない
- コンペ参加中に記録をとっていないので、何を考えていたか思い出せない
ということで、、これ以降のコンペでは
- せっかくコンペに参加しているのだから、オリジナルの手法を1つでも良いので見つける
- コンペ参加中の作戦会議では、簡単な資料(スライドとか)を用意して議論
を心がけようとチームで決めました。
②Google Smartphone Decimeter Challenge 2022
車に搭載されたスマートフォンの正確な緯度経度を推定するコンペです。(通常スマートフォンの位置情報は3~5mほどの誤差があるそうです。)
スマートフォンを精度良く位置情報を測れる装置と一緒に車に乗せて、高速道路や都市部の道路など、いろいろな道路を走行し、スマートフォンの緯度経度から装置の計測した緯度経度を予測します。
配布されたデータは、人工衛星の細かな状態であったりと、生ログに近く、人工衛星を使った位置推定の仕組みに関するドメイン知識がとても重要でした。
解法
こちらのコンペには3ヶ月間フルに参加しました。
チーム内で、位置情報の仕組みや、過去に開催した同様のコンペの解法について調べ、公開されていたノートブックを改良しスコアを上げていく方向で戦っていくことにしました。
データ探索をしていく中で、正解データとなる装置から計測した緯度経度に道路から大きく外れたものがあり、このようなある種「質の悪い正解データ」がスコアを悪くしているのではないかという仮説が生まれました。
この「質の悪い正解データ」を定量的に定義するために、OSMnxを使って取得したオープンな地図データを使い、正解データのマッチング度の指標を作りました。
下記の図は横軸が正解データのマッチング度、縦軸がカルマンフィルターを用いた予測のスコアの散布図です。
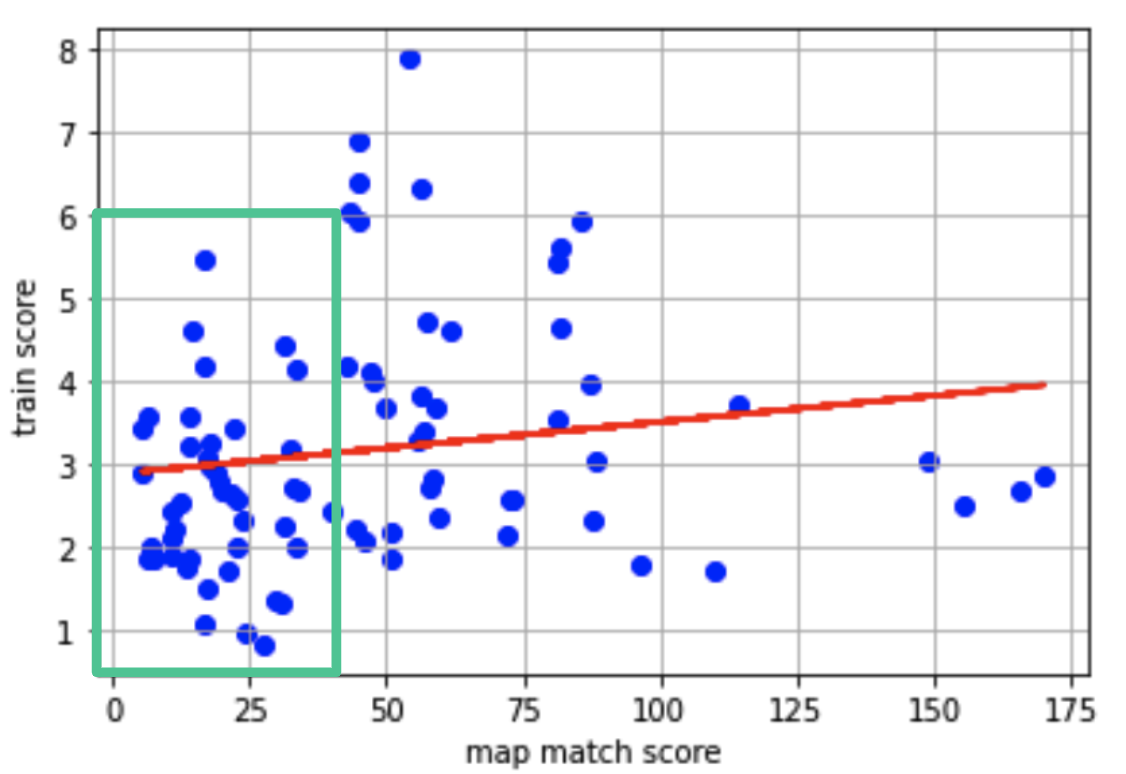
回帰直線(赤線)は緩やかな右肩上がりであり、「正解データの質が悪ければ、学習が難しい」とは強くは言えないものの、「運営としては、質の悪い正解データを予測するモデルより、質の良い正解データを予測するモデルが成果物として欲しいであろうから、質の良い正解データで最終順位(Leader Board)を測るのではないか」という予想を立て、緑枠の部分のみを学習に使いました。
結果&反省
結果としては、暫定順位(Public Leaderboard)では銀圏に入ったものの、最終順位(Public Leaderboard)では銅圏まで落ちてしまいました。(いわゆるShake Down)
敗因としては、上位陣が使っていたRTKLIBという位置情報データの解析を行うためのライブラリを使っていなかったことと思われ、自己流の解法に固執し、ほとんど調べていませんでした。
ドメイン知識がとても重要なコンペであったため、少し調べて分かった気になった後でも、素直に(面倒くさがらずに)新しいことを調べる気概が必要だったと反省しています。
③Feedback Prize - English Language Learning
過去に行われたFeedback系のコンペの第三弾として「Feedback3」と呼ばれていたコンペです。
英語学習者(English Language Learners)の書いたエッセイに対してつけられた、適切な語句を使っているか(Vocabulary)などの評価を予測します。
解法
約3,000あるエッセイには同じテーマについて書いてあるものがあったため、テーマごとにエッセイの書きやすさがあり、評価も変わってくるのではないかと考えました。(「あなたの好きなスポーツについて」と「民主主義について」であれば、前者のテーマの方が書きやすそう)
そこで過去の同様のコンペであるFeedback1で使われている、tf-idfとUMAPを使ったテーマ分類を試してみました。
下記の図のように、Feedback1ではとても綺麗にテーマごとに分類されていますが、今回のFeedback3では綺麗に分類ができませんでした。
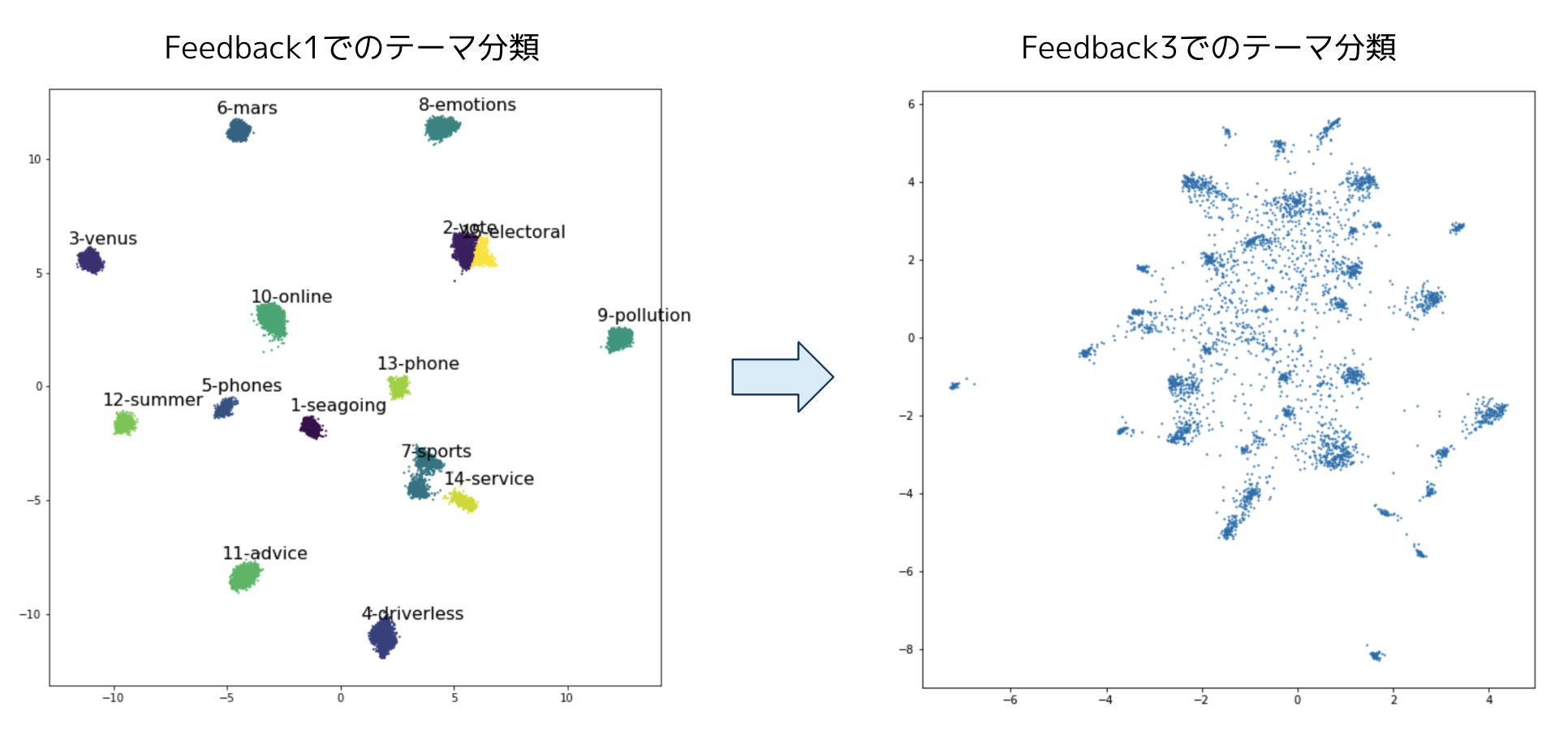
気になって、Feedback1とFeedback3の違いについて調べていると以下のことがわかりました。
- Feedback1は英語ネイティブが書いたエッセイを使っていること(私たちでいう国語の小論文)
- (前述した通り)Feedback3は英語学習者(つまりネイティブでない)が書いたエッセイを使っているが、Feedback1のエッセイが一部混じっていること
- ネイティブが書いたFeedback1のエッセイの評価と、それ以外のエッセイの評価を見比べても、差異は無い
評価の差異はないものの、テーマ分類が綺麗にできなかったことを踏まえて、「ネイティブの書いたエッセイ(Feedback1のエッセイ)と非ネイティブの書いたエッセイ(Feedback3のエッセイ)には、潜在的な違いがあるため、学習の際に工夫が必要」と予想しました。
具体的には、公開されていたノートブックでは、学習データを分割(KFold)する際に、すべての分割で評価指標の分布が等しくなるようにしていましたが(StratifiedKFold)、ここに「Feedback1のエッセイか否か」を追加しました。
(つまり、全ての分割で評価指標+「Feedback1のエッセイか否か」の分布を等しくしました。)
上述した通り、公開ノートブックを書き換えて提出したところ、少しだけスコアが伸びたので、(主催者としてなぜFeedback1のエッセイを混ぜたのかはわかりませんが)「testデータにも配布されたデータと同じ割合でネイティブの書いたエッセイが含まれているのでは」という仮説を立てました。
この仮説に基づいて、色々なモデルを上記の「Feedback1のエッセイか否か」を踏まえた学習を行い、アンサンブルして最終的な提出をしました。
結果
蓋を開けてみると、暫定順位と最終順位で結果が全然違う大波乱なコンペでした。(最終順位で2位の人は、暫定順位で455位)
結果は銅メダルを獲得し、暫定順位->最終順位で219位->149位であったので、大波乱のコンペを上手く乗りこなせた感はあります。
また、過去参加した2つのコンペ同様に銅メダルですが、132位が銀メダルボーダーだったので、銀メダルまであと一息のところまで来れました。
さいごに
最後まで読んでいただきありがとうございます。
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
是非ともよろしくお願いします。