最近、Haskellの勉強のために「関数プログラミング実践入門」を読んでいる。
高階関数のところまでいったけど僕の頭がクソ雑魚だから例題が全然理解出来なかった…。
順番に読み解いていって理解しようと思う。
問題
本書のp.186では
*Main> segments "ABC"
["A","AB","ABC","B","BC","C"]
このように引数の部分文字列のリストが取り出せる関数、segmentsを扱っている。
この実装は以下のようになるそうだ。
segments :: [a] -> [[a]]
segments = foldr (++) [] . scanr (\a b -> [a] : map (a:) b) []
一見簡単そうに見えるが何をやっているのだろうか? わからない。
map関数とその使い方
まず、
map (a:) b
について考えてみよう。map関数のことは本で学んだ。試しにmap関数の型を調べよう。
REPL上でこうすれば型がわかる。
*Main> :t map
map :: (a -> b) -> [a] -> [b]
map関数は関数とリストを引数にとって、リストの要素それぞれに関数を適用した結果をリストに並べて返す関数だ。
リストの先頭への追加
(:)というのは何だ?これも本で学んだ。リストの先頭に要素を追加する関数だ。だから
*Main> 1 : [2,3,4]
[1,2,3,4]
となる。
mapを使う
さて、mapの第2引数はリストでなければならない。更にそのリストの要素はリストでなければ、:によるリストへの追加操作が行えない。ということは、mapと組み合わせて使うには以下のようにすればよい。
*Main> map (1:) [[2,3,4], [5,6]]
[[1,2,3,4], [1,5,6]]
わかった。
ラムダ関数
じゃあこれはなんだ。
(\a b -> [a] : map (a:) b)
これは知っている。ラムダ関数だ。aとbを引数に取って[a] : map (a:) bを返す名前が無い関数だ。
[a] : map (a:) bというのはmapから帰ってくるリストの先頭に、aをリストで包んだ[a]を追加する操作になる。
ということは、
*Main> (\a b -> [a] : map (a:) b) 1 [[2,3,4], [5,6]]
[[1],[1,2,3,4],[1,5,6]]
こうなる。これはさっきmap (1:) [[2,3,4], [5,6]]とした結果の先頭に[1]を追加したものだ。
わかった。
畳み込みscanr, foldr
次に
scanr (\a b -> [a] : map (a:) b) []
これについて考えよう。まず、scanrの型を調べてみる。
*Main> :t scanr
scanr :: (a -> b -> b) -> b -> [a] -> [b]
「2引数を取る関数」、「値」、「リスト」の3つの引数を取り、リストを返す関数だ。このとき、
scanr f b [a_1, ..., a_n]
は
[f a_1 (f a_2 f(...))..., ... , f a_{n-2} (f a_{n-1} (f b a_n)), f a_{n-1} (f b a_n), f b a_n, b]
という感じのリストを返す。
こういった計算を畳み込み(fold)というらしい。図で表すとこんな感じ。
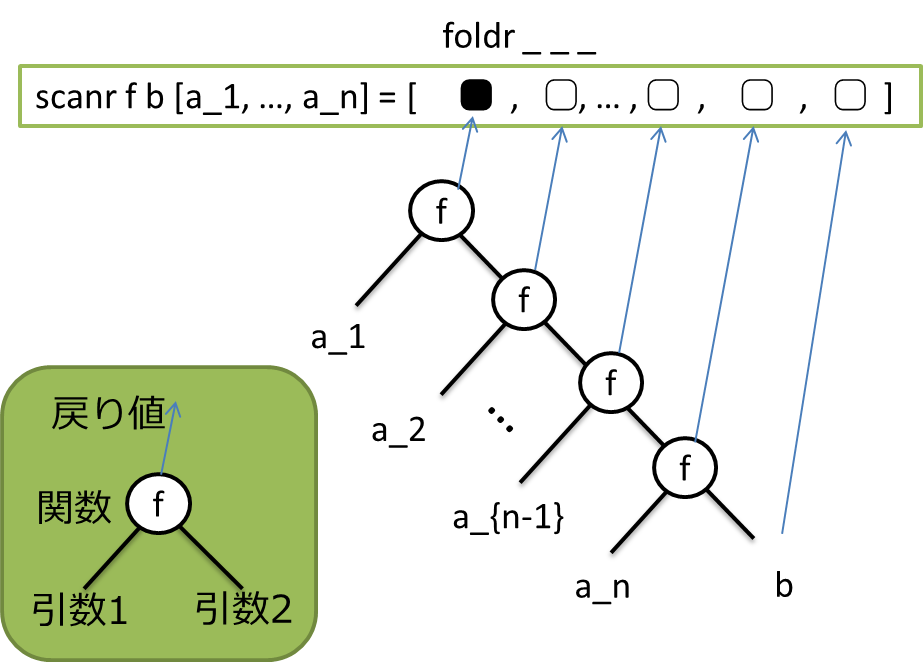
bは初期値で、その後リストの中身を順番にfに適用していく。初期値bや、リストの右のほうにある値(a_nとか)には何重にもfが作用することがわかる。
ちなみに、scanr f b [a_1, ..., a_n]の結果リストの先頭要素だけ返す関数がfoldrである。
scanrについてはわかった。そうすると、下の結果もわかりそうだ。
scanr (\a b -> [a] : map (a:) b) [] "ABC"
いや、ちょっと待った。引数がリストじゃなくて文字列に見える。scanrの第3引数はリストのはずだったのに、困ってしまう。
でも大丈夫。"ABC"の型を見てみよう。
*Main> :t "ABC"
[Char]
なるほど。文字列とは文字のリストだったか。つまり"ABC" = ['A', 'B', 'C']ってこと。わかった。
じゃあscanr (\a b -> [a] : map (a:) b) [] "ABC"で得られるリストの最後尾から逆順に考えていこう。計算?の過程は以下になる。
[]
['C'] : map 'C': [] = ['C'] : [] = [['C']] = ["C"]
['B'] : map 'B': [['C']] = ['B'] : [['B', 'C']] = [['B'], ['B', 'C']] = ["B", "BC"]
['A'] : map 'A': [['B'], ['B', 'C']] = ['A'] : [['A', 'B'], ['A', 'B', 'C']] = [['A'], ['A', 'B'], ['A', 'B', 'C']] = ["A", "AB", "ABC"]
ということで、
*Main> scanr (\a b -> [a] : map (a:) b) [] "ABC"
[["A", "AB", "ABC"], ["B", "BC"], ["C"], []]
となることがわかった。
部分適用
ちなみに、segments関数では
scanr (\a b -> [a] : map (a:) b) []
となっていて、scanrの引数が2個しかない。これは3つうちの2つの引数を部分適用することで、引数が1つの関数を新たに生み出しているのだ。Haskellの関数はカリー化されているからこういうことができる。これは後の関数の合成のために一役買っている。
関数の合成
さて、最初のsegmentsの実装を見直そう。
segments :: [a] -> [[a]]
segments = foldr (++) [] . scanr (\a b -> [a] : map (a:) b) []
まだ触ってないところでまず気になるのが、.ドットだ。これは関数の合成を表す。
f、gが関数のとき、f . gは\x -> f( g x )と同じということらしい。
だから、segments = \x -> foldr (++) [] ( scanr (\a b -> [a] : map (a:) b) [] x )と考えればいい。
(++)は2つのリストを結合する関数だ。foldr (++) [] [リスト]は[]を初期値として順番にリストの中のリストを結合していった最終結果を返す。
だから、
*Main> foldr (++) [] . scanr (\a b -> [a] : map (a:) b) [] "ABC"
["A","AB","ABC","B","BC","C"]
となるのだ。
これでsegmentsの実装の意味がはっきりとわかった。
おわりに
慣れればすぐに読み解けるようになるのだろうか?僕はとてもそうは思わない。でも頑張りますから。