思いつきにまかせて作りました。
こんな感じのtsvがあるとして
id name age
1 ksss 30
2 foo 29
3 bar 30
ActiveRecordっぽくデータを取れます。(書き込みはまだ作ってないけど需要があれば)
require 'active_tsv'
class User < ActiveTsv::Base
self.table_path = "data/users.tsv"
end
User.all
=> #<ActiveTsv::Relation [#<User id: "1", name: "ksss", age: "30">, #<User id: "2", name: "foo", age: "29">, #<User id: "3", name: "bar", age: "30">]>
User.all.to_a
=> [#<User id: "1", name: "ksss", age: "30">, #<User id: "2", name: "foo", age: "29">, #<User id: "3", name: "bar", age: "30">]
User.first
# => #<User id: "1", name: "ksss", age: "30">
User.last
# => #<User id: "3", name: "bar", age: "30">
User.where(age: 30).each do |user|
user.name #=> "ksss", "bar"
end
User.where(age: 30).to_a
# => [#<User id: "1", name: "ksss", age: "30">, #<User id: "3", name: "bar", age: "30">]
User.where(age: 30).last
# => #<User id: "3", name: "bar", age: "30">
User.where(age: 30).where(name: "ksss").first
# => #<User id: "1", name: "ksss", age: "30">
User.where.not(name: "ksss").first
# => #<User id: "2", name: "foo", age: "29">
User.group(:age).count
# => {"30"=>2, "29"=>1}
User.order(:name).to_a
# => [#<User id: "3", name: "bar", age: "30">, #<User id: "2", name: "foo", age: "29">, #<User id: "1", name: "ksss", age: "30">]
User.order(name: :desc).to_a
=> [#<User id: "1", name: "ksss", age: "30">, #<User id: "2", name: "foo", age: "29">, #<User id: "3", name: "bar", age: "30">]
ActiveTsv::Baseのclass間でhas_manyやbelongs_toによる関連付けも可能です。
class User < ActiveTsv::Base
self.table_path = "data/users.tsv"
has_many :nicknames
end
class Nickname < ActiveTsv::Base
self.table_path = "data/nicknames.tsv"
belongs_to :user
end
User.first.nicknames
# => #<ActiveTsv::Relation [#<Nickname id: "1", user_id: "1", nickname: "yuki">, #<Nickname id: "2", user_id: "1", nickname: "kuri">, #<Nickname id: "3", user_id: "1", nickname: "k">]>
Nickname.last.user
# => #<User id: "2", name: "foo", age: "29">
もちろんCSVファイルも対応可能です。
require 'active_csv'
class User < ActiveCsv::Base
self.table_path = "data/users.csv"
end
User.first
# <User id: "1", name: "ksss", age: "30">
つくってからactive_csv gemの存在に気がついたのですが、コードもgithubにあがっておらず、中のコードもどうにも古いもののようで、エイヤとactive_tsvをリリースしてしまいました。
mysql-cliからselect結果を標準出力に出すとtsvでテーブルの内容が保存されるので、なんとか使いみちがあるんじゃないかと模索中です。
良いアイデアや使いみち、PR等お待ちしております。
追記
作ってから気がついたのですが、active_hashというgemがすでにあり、こちらを使っても同等のものが実現できそうです。
require 'active_hash'
require 'csv'
module ActiveTsv
class Base < ActiveFile::Base
SEPARATER = "\t"
extend ActiveFile::HashAndArrayFiles
class << self
def load_file
raw_data
end
def extension
"tsv"
end
private
def load_path(path)
data = []
CSV.open(path, col_sep: self::SEPARATER) do |csv|
keys = csv.gets.map(&:to_sym)
while line = csv.gets
data << keys.zip(line).to_h
end
end
data
end
end
end
end
class User < ActiveTsv::Base
# data/users.tsvを読む
set_root_path "data"
set_filename "users"
end
p User.where(age: "30")
# => [
# #<User:0x007fba2b12fa60 @attributes={:id=>"1", :name=>"ksss", :age=>"30"}>,
# #<User:0x007fba2b12ecc8 @attributes={:id=>"3", :name=>"bar", :age=>"30"}>
# ]
違いは、
- 機能はactive_hashの方が豊富
- active_hashはwhereの返り値が
RelationではなくArray - active_hashでは
where.notができない - active_tsvの方が圧倒的に高速
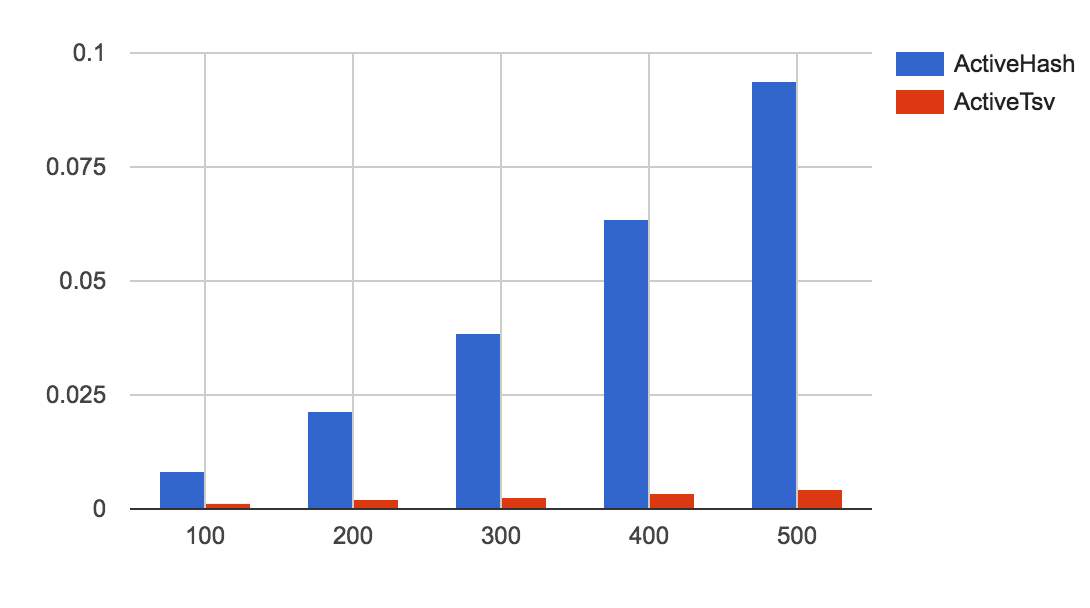
ベンチマークを取ってみると、active_tsvのほうがはるかに高速であることがわかりました。
ベンチマークは、klass.all.each{}の処理を回して比較したもので、縦軸が秒で横軸がレコード数になっています。
レコード数が増えるほどに、処理速度の差は顕著になるようです。
直感的には、全てメモリに持つactive_hashの方が高速そうなので意外でした。
予想としては、レコードのHashのArrayをもつ仕様がTSV/CSVに合わないか、write用の処理がオーバーヘッドになっているのかもしれません。