本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
※ミートアップ実施時の動画は↓こちら。
はじめに
2025年、生成AI技術の進化とともに、RAGだけでなく、AIエージェントを活用したアプリケーション開発に着手する企業が着実に増加しています。これに伴い、AIエージェント開発のエコシステムも多様化し、本当に使える生成AIアプリケーションのより実践的なアーキテクチャやフレームワークを模索する時代へと突入しました。そのような背景をうけ、本セミナーでは、今注目を集めるGoogle社の新技術「Agent2Agent(A2A)」を中心に、AIエージェント開発の最前線とAIエージェントの将来像についてご紹介します 。
もっとも、これからAIエージェントの開発に取り組もうとする初学者にとって、いきなりA2Aの仕組みやユースケースを解説されても 「なぜ重要なのか」「従来と何が違うのか」 が腹落ちしにくいかもしれません。そこで本記事では、まずは基本的な要素技術として
- AIエージェント
- MCP(Model Context Protocol)
- マルチエージェント
など、押さえておきたい前提知識を整理します。その上で、A2Aがこれらの流れをどのように統合し、AIエージェントシステムの将来像をどのように描いているのかを、サンプルコードを交えながらご紹介していきます。
※前提知識は不要なので本題が知りたいですという方は こちら。
AIエージェント
現在進行形で進化している「AIエージェント」に定義というものは特に存在しないように思いますが、様々な実装をみているとそこには共通点が存在することがわかります。それはユーザーの指示に基づいて、「どのような処理を、どのような順序で実行するか」を自ら計画し、そして実際に実行し、その結果を返す自律的なプログラムだという点です。

たとえば「自社の人気商品の売上を分析して、マーケティング施策や在庫の最適化を行いたい」とAIに話しかけると、AIが自律的にSNSで人気商品を調査し、その結果を分析、さらに社内のSCMと連携して在庫の過不足を調整してくれる――そんなイメージです。
こうした処理を実行するにあたって、AIエージェントはSNSへのアクセス、データ分析プログラムの実行、社内SCMシステムの操作など、さまざまな外部サービスの連携が必要になります。
この 「連携」 を実現する方法にはいくつかの実装手段があり、その中でも昨今デファクトになりつつある技術が、MCP(Model Context Protocol) です。
※AIエージェントそのものについては以前のセミナーで実施しましたので下記記事を併せてご参照ください。
MCP(Model Context Protocol
MCPは、2024年11月にAnthropic社からリリースされました。これは、LLM(Model)が応答テキストを生成する際に必要となるヒント(Context)を取得するための仕組み(Protocol) であり、その目的にちなんで「Model Context Protocol」と名付けられています。
下図のように、AIエージェントが外部サービスからヒント(Context)、つまり外部情報を取得するために連携する部分──まさにこの仕組みにあたるのがMCPです。

ChatGPTやGeminiなど出来上がったサービスのみを利用している方には想像しにくいかもしれませんが、LLM単体では「与えられたテキストに基づいたテキストの生成」しかできず、ウェブ検索を実行したり、SNSを検索したりということはできません。
LLMは過去のデータを学習した機械学習の予測モデルのため現在のデータ(リアルタイムのデータ)に関する応答はできません。LLM単体では今何時なのかですら答えることはできないんです。
現在のバージョンのChatGPTやGeminiなどがリアルタイムにウェブ検索を実行してくれるのは、LLM以外にそのようなプログラムが追加で実装されているからです。
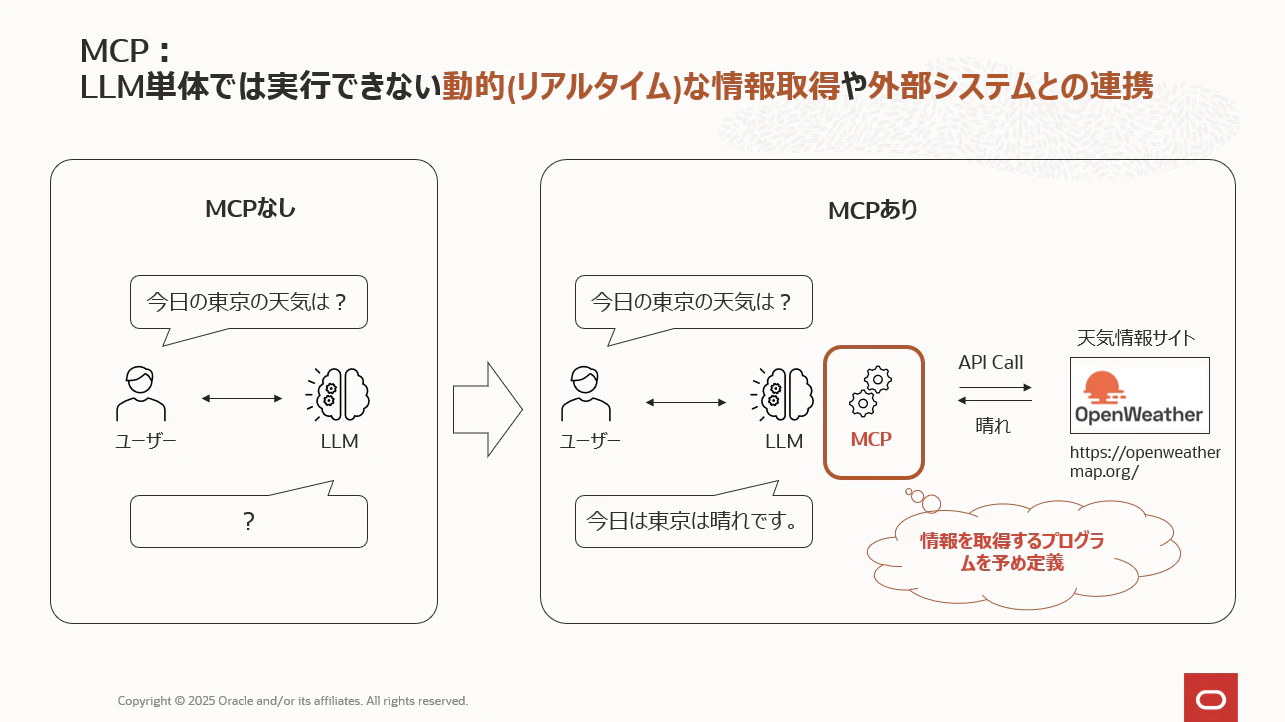
例えば上図のように、今日の天気予報というリアルタイムの情報を含んだテキストを生成したい場合、OpenWeatherなど天気情報を提供しているサービスに都度アクセスし、天気情報を取得する実装が必要になります。(上図の赤枠の部分)このように、LLMと「LLMの外の世界」を連携させるプログラムを開発できる仕組みがMCPです。
LLM単体では実行できない 「動的(リアルタイム)な情報取得」や「外部システムとの連携」 も可能になり、生成AIアプリの適用範囲を大幅に拡張することができる極めて重要な仕組みとなります。
そして、ここでいう 「LLMの外の世界」 とは例えば以下のようなものです。

-
インターネットに公開されているサービスとの連携
毎日私達が利用するようなインターネット上で公開されている様々なサービスはAPIでアクセスできるようになっているものが多いのでそれらを利用してMCPを作るパターン -
社内システムとの連携
現状、ユースケースとして挙げられるケースは少ないように思いますが、今後生成AIアプリの適用範囲が広がれば財務、人事、生産、調達、販売システムなどをMCPで連携するパターン -
業務アプリ、ユーザー開発アプリとの連携
社内システムと近しいケースですが、RDB、NoSQL、DWH、データレイク、ETL、BIツールなどとMCPで連携するパターン
このように沢山のサービスと連携することで、より便利で汎用的なアプリケーションになることはおわかりになると思います。また、API CallだけでなくスクレイピングやOSコマンドなど様々なタイプの処理を MCPとして定義できますから、 事実上、連携できないものありません。
このようにMCP携えたエージェントを実装すると非常に有用ななサービスが開発できるわけですが、そのエージェントを更に複数個組み合わせるアーキテクチャがマルチエージェントです。
マルチエージェント
マルチ・エージェントとはその名の通り、上述したエージェントを複数構成する手法で、現在、各ベンダーがリリースしているAIエージェント開発のクラウドサービスやOSSライブラリの中核的な技術です。
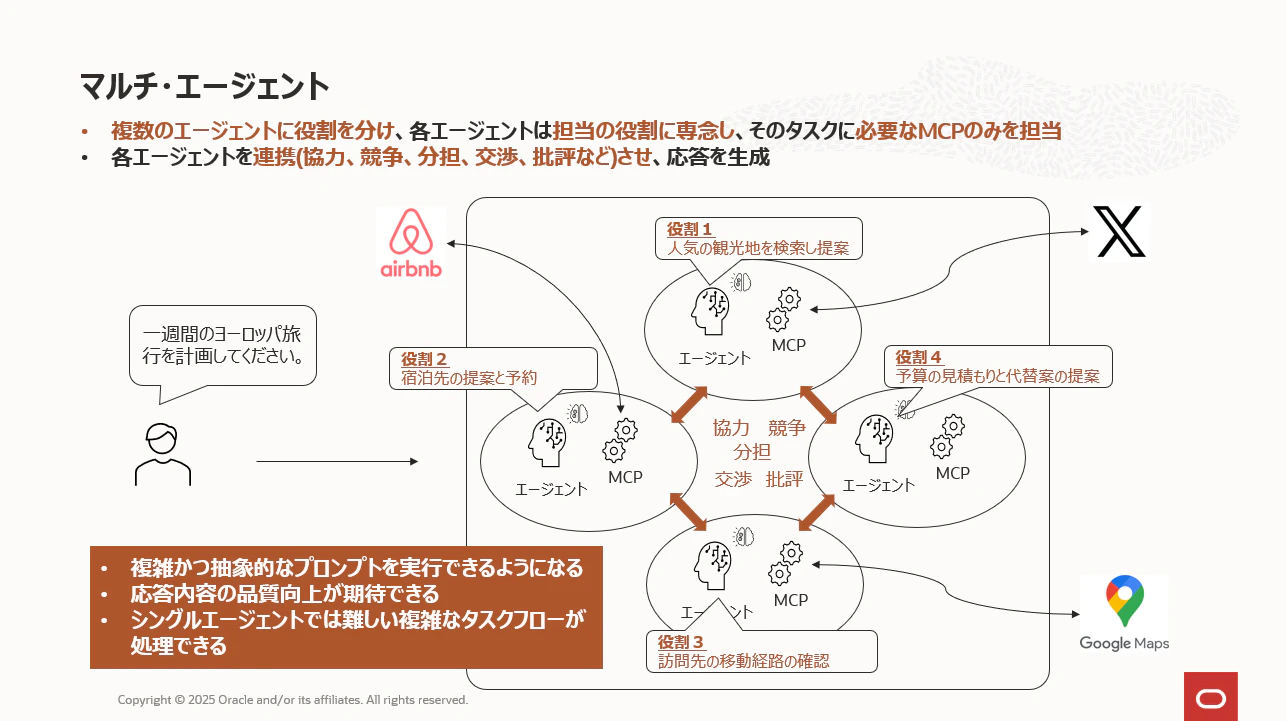
おさえておきたいポイントとしては下記3つです。
①複数のエージェントに役割を分ける
複数のエージェントに役割を分けて、各エージェントにはその役割だけに専念させることでLLMの推論ミスの可能性を減らします。 例えば、上の図では「一週間のヨーロッパ旅行を計画してください。」というプロンプトに対して、下記4つの役割に細分化し、この役割を4つの各エージェントに割り当てています。
- エージェント1の役割=「人気の観光地を検索して提案する」
- エージェント2の役割=「宿泊先の提案と予約」
- エージェント3の役割=「訪問先への移動経路の提案」
- エージェント4の役割=「予算の見積もりと代替案の提案」
②各エージェントにはその役割に応じたMCPだけを担当させる
同様に、各エージェントにはその役割に関係するMCPのみを関連付けることにより、MCPの選択やその実行順序の推論ミスを軽減します。 上図の例では各エージェントの役割に沿った以下のようなfunction callingを割り当てます。
エージェント1に割り当てるMCP = 「Xで人気の観光地を検索する処理」
エージェント2に割り当てるMCP = 「airbnbで宿泊先を検索、提案、予約する処理」
エージェント3に割り当てるMCP = 「Google Mapで訪問先の移動経路を検索する処理」
エージェント4に割り当てるMCP = 「移動先、宿泊費、食費など旅行に必要な費用を計算し、予算内でなければ再度他のエージェントに代替を提案させる処理」
③各エージェントの連携方法
そしてマルチ・エージェントにおいて、この複数のエージェントをどのように連携させるか? という点が最も重要な設計ポイントになります。 例えば、複雑なプロンプトのタスクを分割して 「分担」 させたり、同じ役割を持たせて一番良い結果を選べるよう 「協力」 させたり、エージェント同士を 「競争や交渉」 をさせたり、あるエージェントの提案内容を 「批判」 させたりといった具合です。 上図の場合、おおよそ下記のような連携関係だということができます。
- エージェント1によって観光地が提案され、その観光地の近くの宿泊先をエージェント2が提案、予約するというシナリオのため 「分担」に近い連携と言えます。
- エージェント1、とエージェント2の提案内容によりエージェント3が移動経路を検索するというシナリオのためこ-
- ちらも 「分担」 に近い連携と言えます。
- エージェント1、とエージェント2、エージェント3の提案内容により旅行にかかる費用が決まり、その費用が予算内でなければやり直しさせるというシナリオのため、「批評」 に近い連携と言えます。
このようにして、入力プロンプトの内容から必要とされる複雑なタスクフローを実行したり、またその結果の精度を更に向上させることができるようになる仕組みがマルチエージェントです。
AIエージェントの要素技術の主だった考え方は上述したような内容になりますが、これをゼロから自分で開発するのはなかなか骨が折れる作業ということになるので当然、様々なプロバイダーからAIエージェント開発用の製品やOSSライブラリ、さらには開発済のエージェントがリリースされており、既に広範なエコシステムが形成されている状況です。
AIエージェントのエコシステム
現在、AIエージェントを開発するためのエコシステム(特にマルチエージェントにフォーカスした製品)は本当に様々なものがリリースされていますが、その中でも主にOSSを中心とした著名なフレームワークを下表にご紹介します。
マルチエージェント開発用のフレームワーク(OSS)
| 名称 | 開発元 | 製品概要 |
|---|---|---|
| LangGraph | LangChain Inc. | LLMフレームワークで著名なLangChainの姉妹ライブラリとなり、マルチエージェントシステムの構築にフォーカスしたOSS。LangChainの幅広いエコシステムとの連携が可能で様々なプロバイダのLLMが利用可能。 |
| Autogen | Microsoft Research | マルチエージェントシステムの構築にフォーカスしたOSSライブラリ。グループチャットなどAIエージェント同士の対話やタスク分担を自動化するためのライブラリが特徴的。OpenAI以外の様々なモデルが利用可能かつ、LangChain、Dockerなどその他のライブラリとの連携も可能。 |
| OpenAI Agents SDK | OpenAI | OpenAI公式のエージェント開発用SDK。function callingやtool呼び出しをシンプルに統合でき、外部APIやデータソースと連携したエージェントアプリケーションを迅速に構築可能。OpenAIのモデル群との親和性が高い。 |
| Agent Development Kit | Agent2Agentとの併用により高度なマルチエージェントシステムを構築可能。Googleの生成AIエコシステムやVertex AIとの連携を前提とし、A2Aプロトコルを活用したエージェント協調の実装を支援。 | |
| Dify | Dify.ai(Community主導) | ノーコード/ローコードでAIアプリを開発できるOSSプラットフォーム。マルチエージェント構成をGUIベースで設計可能で、外部APIやDBとの統合も容易。OSSながら商用利用にも適している。 |
| Llama Stack | Meta | Meta公式の「Llamaモデルを中心に据えたOSSエコシステム」。単なるモデル提供にとどまらず、推論、ファインチューニング、デプロイ、マルチエージェント構成までを一貫して支援する仕組みを提供。利用可能モデルはMeta製Llamaに限定される。 |
AutogenおよびLangGraphのマルチエージェントについては過去の下記記事で扱いましたので併せてご参照ください。
また、既に開発済のAIエージェントを提供する企業もあります。SIer、ソフトウェアベンダー、クラウドベンダー、その他サービス提供企業など、さまざまなプレイヤーがすでに自社サービス向けに開発したAIエージェントを提供しており、その一例が下表になります。
開発済のエージェントサービス
| 企業名 | 製品名 / サービス | 概要 |
|---|---|---|
| ServiceNow | ServiceNow AI Platform(AI Agent Fabric / AI Control Tower / Now Assist) | ServiceNowのAI基盤。AI Agent Fabric により社内外のエージェントを統合、AI Control Tower でガバナンス・監視、Now Assist による生成AIアシスタントで業務効率化を実現。 |
| Salesforce | Agentforce(Salesforce AI Platform) | Salesforceの生成AIエージェント基盤。ローコード・プロコード両対応のカスタムエージェント構築、Command Center による可視化と運用管理、MCP対応による相互運用性、100以上の業界用アクションを迅速に利用可能。 |
| Oracle | NetSuite / Fusion Applications | Oracleのクラウド型ERP・HCM・CRMに統合されたAIエージェントを提供。業務プロセスの自動化や意思決定支援を実現。 |
| SAP | Joule(SAP AI Copilot) | SAPのビジネスアプリケーションに統合されたAIコパイロット。ERP・サプライチェーン・HR業務を自然言語で支援。 |
| Accenture | AI Refinery™ for Industry | 12業界向けのAIエージェントソリューション。NVIDIA AI Enterpriseとの連携で、導入期間を数週間から数日に短縮するマルチエージェントネットワーク。 |
| NTT DATA | Smart AI Agent™ Ecosystem | 産業特化型ソリューションを備え、RPAボットをインテリジェントエージェント化する特許プラグイン・各種インフラ・マーケットプレイス・マネージドサービスを統合したエンタープライズ向けの包括AIエージェントエコシステム。 |
今後このような市場動向はさらに加速し、当然ながら非IT企業含め多数の企業がAIエージェントを開発しリリースすることになるでしょう。
AIエージェントの将来 - 様々なベンダーが提供するエージェントが繋がる世界
こうなると、これら各社のAIエージェントや自社開発のAIエージェントを単独で利用するだけではなく、各社の複数AIエージェントを連携させて、さらに便利なサービスを開発したいというニーズが当然ながら生まれてきます。
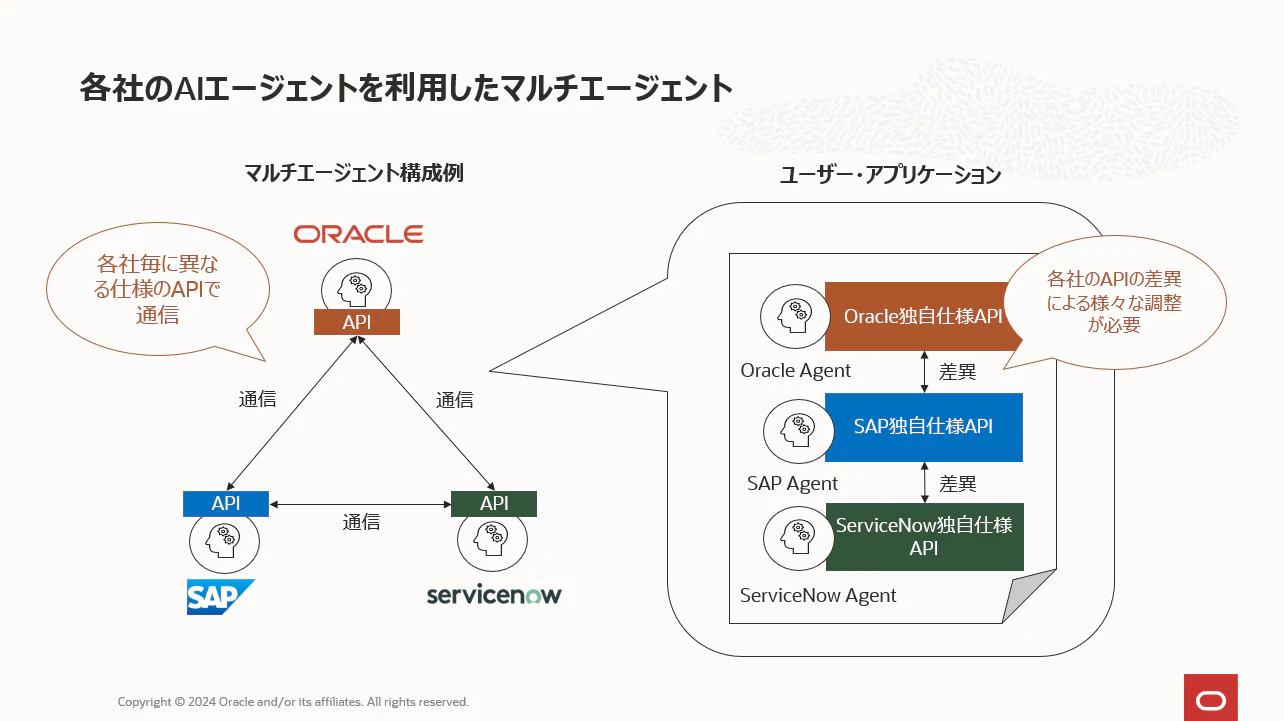
たとえば、Oracle NetSuiteのAIエージェントと、SAP S/4HANAのAIエージェントを連携させて、サプライチェーン管理から財務会計までの業務データを統合的に扱い、需要予測に基づく自動発注や在庫最適化を実現するマルチエージェント型の生成AIアプリケーションを構築したい、というイメージです。
しかしその際には、各社が提供するAIエージェントごとに異なるAPI仕様に対応して開発を進めなければならず、膨大な工数が発生することは避けられません。OracleのAIエージェントと通信する際はOracle独自仕様のAPIを使って開発することとなり、これはその他の企業のAPIも同様です。
当然ですが、各社がリリースするAPIは自社製品に最適化したものになりますから、各社のAIエージェントに接続しメッセージを送受信する方法は各社で全て異なるわけです。 そして、マルチエージェントの世界ではこれら各社の異なるAPIを使って書いたコードが連携するように歯車を合わせなければいけないという工数のかかるコーディング作業が待ち構えています。これから世界中のユーザーがAIエージェントを開発してゆく中で、このような状況は確実にAI市場の発展を阻害することになります。
そこでこの課題を解決するために、各社のAIエージェントとの通信方法を標準化し、誰が開発しても共通の手順でエージェントとの通信をできることを目的として開発されたのが Agent2Agent (A2A) です。
インターネットをはじめとしたさまざまな技術は、独自仕様から、標準化されることで広く受け入れられ、世界中が繋がるようになったわけで、これはAIエージェントにおいてもごく自然な流れと言えます。
※ここでいう、マルチエージェントとは単一のフレームワークで開発されたマルチエージェントではなく、各社の複数AIエージェントを連携させるヘテロジニアスなマルチエージェントを指しています。単一のフレームワークで開発するマルチエージェントは、そのフレームワーク内の共通プロトコルで簡単に連携します。
Agent2Agentの特徴
Agent2Agent(A2A)ライブラリはGoogle社により、AIエージェント間通信の標準化を実現するためのプロトコルとして、2025年4月に開催されたGoogle Cloud Nextで発表されました。様々な特徴を持つライブラリですが、特にお伝えしたい点は下記3つです。
①ヘテロジニアスなマルチエージェント
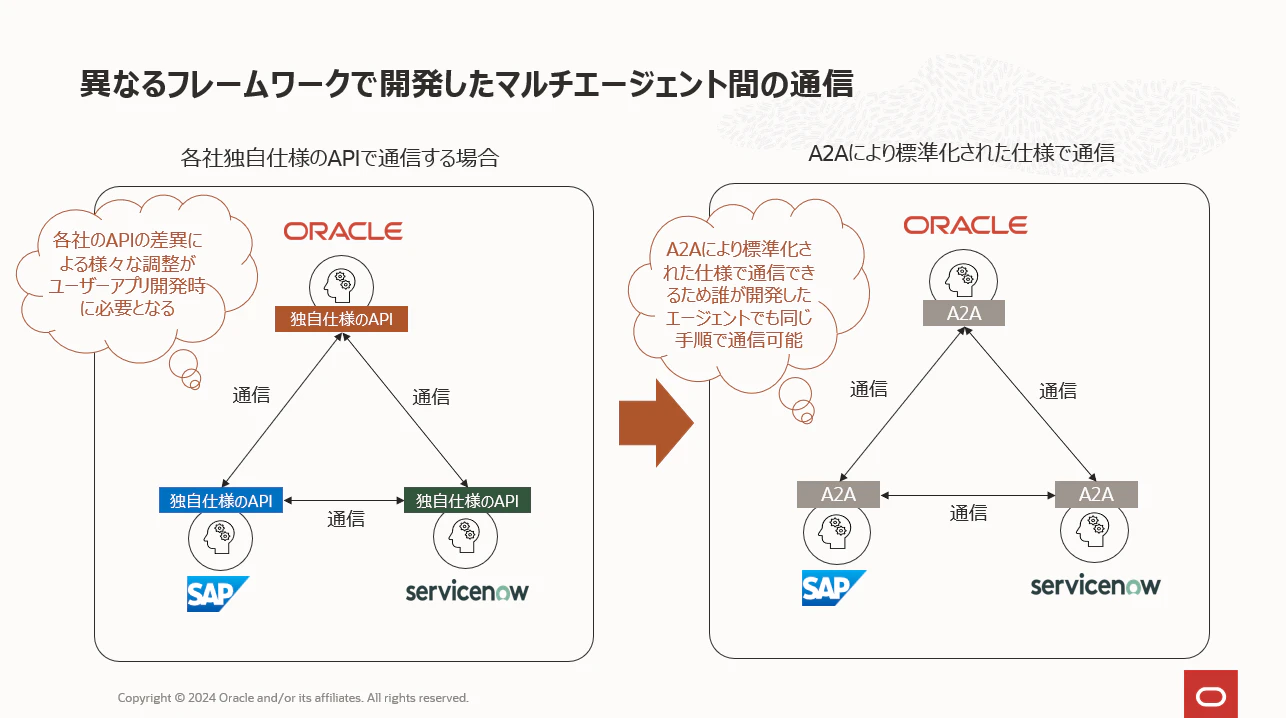
A2Aでは異なるベンダーやフレームワークで作られたエージェントを標準化された方式で相互運用することができるように作られています。これがA2Aの最大の、そして最も重要な特徴となります。 今後、世界中のあらゆる企業がエージェントをリリースすることになりますが、A2Aに準拠しているエージェントであれば、A2Aの決められた手順により連携できることが保証されているため、あらゆるエージェントを簡単に組み合わせてマルチエージェントの便利なサービスを開発することができるようになります。
LangGraph, AutoGenなど著名なフレームワークは相互運用できるように作られています。ですが、これは両者が両者のAPIに合わせて実装しているだけで、「業界標準」のプロトコルにより、示しを併せずとも通信ができている状況ではありません。
②標準化されたオープンプロトコル
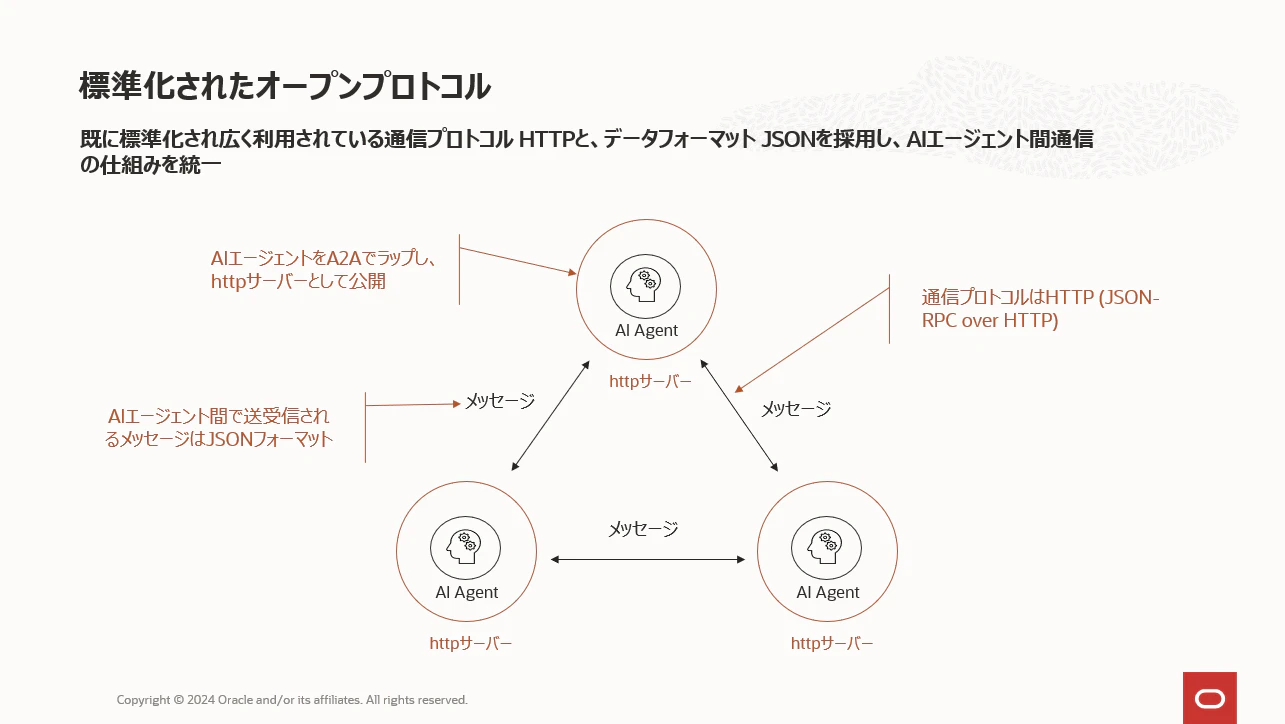
各社のAIエージェントは独自仕様のAPIやSDKで動作しており、そのままでは相互通信できません。そこでA2AではAIエージェントをラップしてHTTPサーバーとして公開し、共通のインターフェースを提供します。 エージェント同士がやり取りするメッセージの通信プロトコルにHTTPを、そしてデータ交換形式JSON-RPCを採用しています。つまりA2Aは、新しい規格を作るのではなく、すでに標準化されている既存の標準技術を活用することで、異なる仕様で開発されたAIエージェント同士の相互運用を可能にするライブラリということになります。
③業界標準化のためのアライアンス

A2Aは50社以上のパートナー企業と共同で発表されました。 このように多くの企業がA2Aをベースに各社のサービスのAIエージェントを開発していく方針をとっているということになり、今後もこのアライアンスの参加企業は増えていくことになると思います。つまり、A2Aで生成AIアプリケーションを開発するということは、これらの企業がリリースするA2A準拠のAIエージェントを簡単に自社のサービスに組み込むことができるということを意味します。
ライブラリのリリースと同時に既にエコシステムも出来上がっているという状況で、技術面とビジネス面の両方を揃えてスキのないアナウンスという印象です。
今後、A2Aが広く受け入れられれば、その標準化のメリットにより、AIエージェントの提供とその利用は急激に加速することが考えられ、世の中を便利にする素晴らしいサービスが沢山生まれることだと思います。
最近発表されたA2A対応のエージェントだと、Oracle AI Database Agentがあります。是非お試しください。
A2Aのしくみ
ここからA2Aの具体的な仕組みについてご紹介します。まず、ライブラリ構成です。A2Aはあくまでエージェント間通信のためのライブラリであり、A2Aにはエージェントそのものを定義するためのクラスや関数はありません。
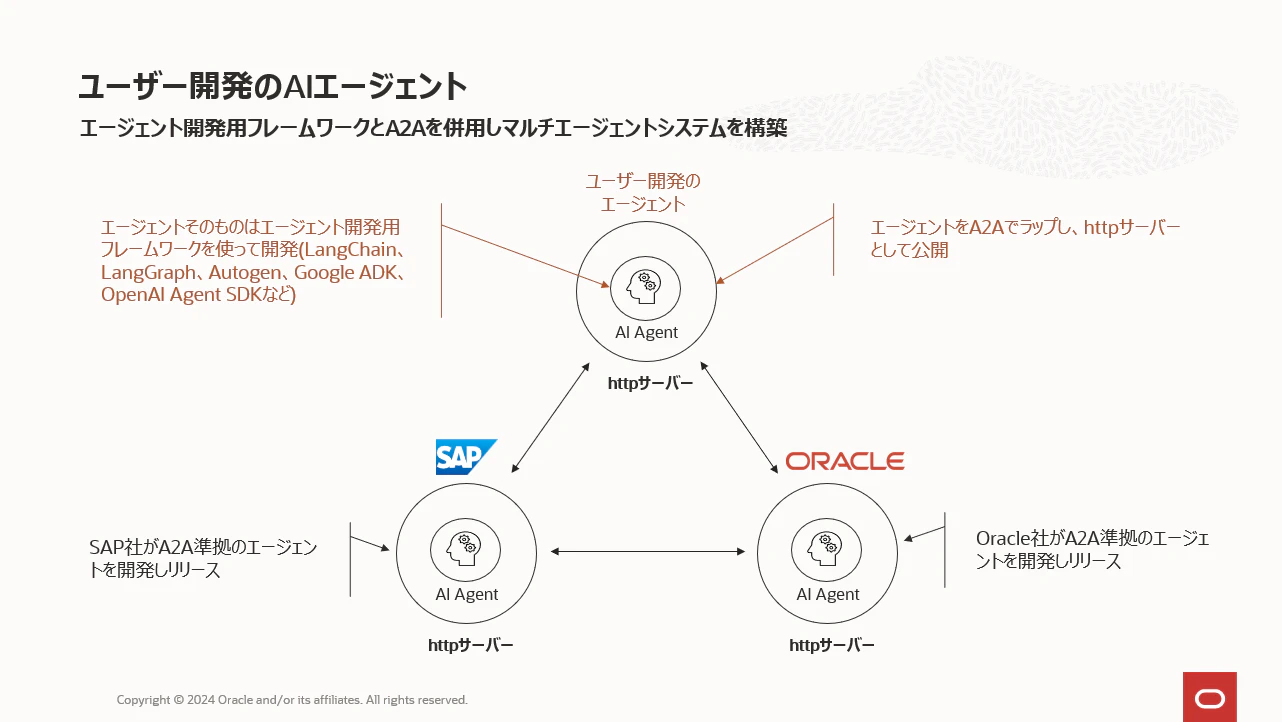
サービス提供企業がリリースしているエージェントは既に開発済みのエージェントとうことになりますが、ユーザー自身がエージェントを開発する場合はAgent Development Kit(google)、やその他上述したようなマルチエージェント開発用のOSSや製品で実装することになります。
A2Aはクライアント・サーバー型のアーキテクチャ
A2Aを使ったマルチエージェントシステムでは、エージェント側がサーバーとなり、入力プロンプトをサーバーに送受信するクライアントの2つのコンポーネントを開発する必要があります。

繰り返しになりますが、サービス提供企業がリリースしているエージェントだけを使う場合はクライアント側のみを開発し、ユーザー自身のエージェントを追加する場合はクライアントとサーバーの両方を開発するということになります。
A2Aのプログラミングモデル
ここから、サーバー側のコードとクライアント側のコードでどのようなコードを実装するかの概要を説明します。少し長い説明になりますが、このあたりをちゃんと理解しておくと後でご紹介するサンプルコードがすんなりと頭に入ってくると思います。

まず、上図右側のサーバーのコードからです。
-
Agent
A2Aはあくまでエージェント間通信のためのライブラリであり、Agentは作れません。なので、Agent自体は上述したようなエージェント定義用のフレームワーク(LangGraph、Autogenなど)でエージェントを定義する必要があります。もしくはフレームワークを使わずにすっぴんのPythonでエージェントを自作しても大丈夫です。MCPを定義する場合も従来通り、Agentに定義します。 -
AgentExecutor
次に、AgentExecutor は定義されたエージェントを A2A の実行オブジェクトとしてラップします。これにより、各フレームワーク固有のエージェントが返す結果を A2A 標準のイベント形式に変換し、他のエージェントに伝達できるようになります。言い換えると、AgentExecutor は異なるフレームワークで開発されたエージェントの独自仕様をA2Aの共通仕様に変換するラッパーのような存在です。これによりあらゆるエージェントがA2Aのエコシステムに参加できます。AgentExecutorはAgentをラップしていますので、Agentそのものだと言えます。 -
AgentSkill
AgentSkill は、エージェントが持つ「機能」や「行動可能なタスク」が何なのかを定義します。例えば「顧客データの検索」「注文処理」「在庫管理」といった業務スキルを表現できます。これにより、他のエージェントはそのスキルを参照して「どのエージェントに、どのタスクを依頼できるのか」を判断できます。 -
AgentCard
AgentCard はエージェントの属性や基本情報を記述したメタデータです。エージェントの名前、利用可能なスキル一覧、エージェントにメッセージを送受信するためのエンドポイント(URL)などが含まれます。これにより、他のエージェントは相手のプロフィールを確認し、どのような能力や役割を持つかを理解できます。 -
uvicorn
uvicornはA2Aのオブジェクトではなくpythonアプリケーションを実行できるウェブサーバーのライブラリです。上述した、Agent、AgentExecutor、、AgentSkill、AgentCardなどの処理を纏めてhttpサーバーとして公開する役割を持ちます。
次に、クライアントコードの概要です。
-
A2AClient
uvicornで公開されているエージェント(A2A化されたサーバー)に対するクライアントであることを定義します。これには通信先のエージェントのURLが入りますので、クライアントのプログラムはどのエージェントに接続すべきかがここでわかるようになっています。 -
http client
ここまで説明してきた通り、エージェントのサーバーはhttpサーバーですから、それに対するhttp clientを定義します。 -
AgentCardResolver
クライアントは、接続したエージェントはどのようなことができるのか?を知る必要があります。そのためには、サーバー側のAgentCard(AgentSkill含む)を取得する必要があり、その処理のためにAgentCardResolverを定義します。 -
メッセージの送受信と各エージェント間の連携ロジック
各エージェント間のメッセージ送受信の仕組みを定義します。これにはメッセージの送受信という基本的な処理とともに、エージェント間の連携ロジックも含まれます。例えば、シンプルに特定のエージェントにのみメッセージを送信るケース、全てのエージェントにブロードキャストするケース、入力プロンプトの内容から、どのエージェントをどのような順序で実行するかをLLMに推論させるケース、などなどです。
仮に AgentExecutor(=Agentそのもの) をビジネスマンに例えると、AgentSkill はそのビジネスマンが持つ資格や専門知識、AgentCard はそれらを記した名刺にあたります。
クライアントは「顧客」、クライアントとサーバーの通信は「ミーティング」 と考えることができます。顧客はミーティングの場で相対する複数のビジネスマンがどのような役割や能力を持っているのかを知る必要があり、そのために名刺交換を行います。この「名刺交換」にあたるのが AgentCardResolverです。
そして、一つのプロジェクトを進めるために顧客と複数のビジネスマンが連携して仕事を進める様子は、まさに マルチエージェントシステムのイメージに重ねることができます。
各オブジェクトの詳細な説明は本家のマニュアルをご参照ください。
https://a2a-protocol.org/latest/tutorials/python/1-introduction/
サンプル実装
以下のサンプルコードでは、旅行する際に必要になる様々な情報を4つの専門家エージェントが教えてくれるというシナリオのシンプルななマルチエージェントのコードです。ポイントとしてはA2Aの最大のメリットである「ヘテロジニアスなエージェント間の通信の標準化」です。そのため4つのエージェントはそれぞれ異なったフレームワークで定義しています。
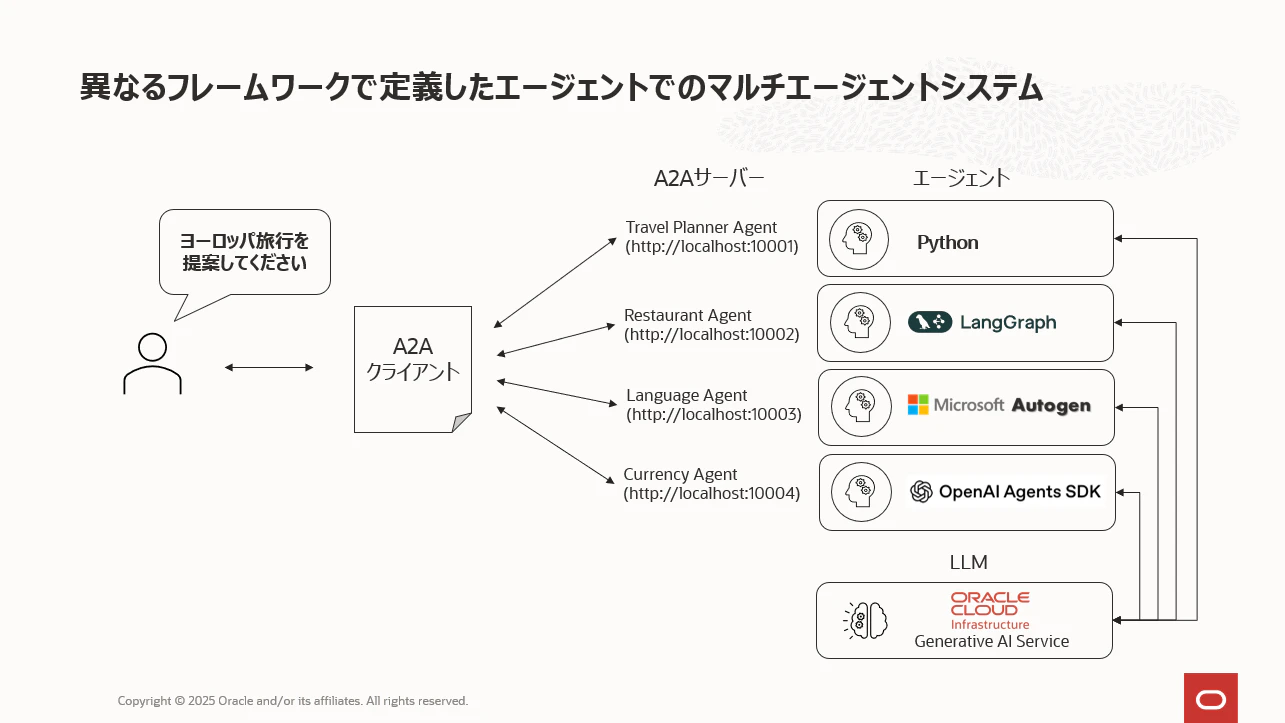
各エージェントの役割としては以下のようなものです。
- Travel Planner Agent : 観光名所、宿泊施設、旅費を提案
- Language Agent : 訪問国での公用語に関する情報を提供
- Restaurant Agent : 訪問先でのお勧めのレストランの情報を提供
- Currency Agent : 訪問国での通貨と為替レートの情報を提供
そして、LLMにはOracle CloudのGenerative AI Serviceを利用しています。
以下のサンプルコードでは、分かりやすさを優先させるためにあえてTool(MCP)を使わないエージェントを定義しています。本来ツールを使わないエージェントを定義することはあまりしませんが、本記事ではそこは本質ではなく、あくまでも「異なるフレームワークで開発されたエージェントがA2Aによって繋がる様子」にフォーカスしたサンプルコードとしてとらえてください。また、MCPについてこちらの記事でも紹介していますのでご興味ある方はご参照ください。
Pythonで作ったシンプルなエージェント(一つ目のエージェント)
一つ目のエージェントである Travel Planner Agentを定義しています。つまりサーバー側のコードです。コードブロック単位でなるべく説明をコメントに入れていますがポイントとしては以下の通り。
- コードとしては、「Agentの定義」、「AgentExecutoの定義」、「main関数の定義」の3部構成にしています。
- Agent定義のパートは、A2AではなくそれぞれのフレームワークでAgentを定義するコードになります。(上述したように、A2AにはAgentを定義する関数ありません。)
- AgentExecutor定義のパートでは、既に定義したAgentをA2Aでラップしています。これにより各フレームワークで作られたオブジェクトがA2Aのオブジェクトに変換され、A2Aの標準化されたイベント(メッセージの送受信やタスクステイタスの保持など)をハンドリングすることができるようになります。
- main関数定義のパートではAgentSkill、AgentCard、A2Aのイベントハンドラを定義し、ここまで定義したAgentExecutor(Agent含む)をASGIアプリケーションとして纏めてuvicornでhttpserverとして公開しています
- これによりAgentがhttp server化された状態となります
- (重要なポイント)Agentの定義パート以外の「AgentExecutoの定義」、「main関数の定義」のコードはこの後定義する全てのエージェントで共通のコードです。異なるのはクラスの名前だけです。A2Aによって標準化されているためこのようなことが可能になります。
サーバー側のコード
######################################################################
# Travel Planner Agentの定義
# フレームワークを使わず定義したパターン
# Agent定義のブロックではA2Aライブラリは使わない
######################################################################
# Agentの定義なのでA2Aのライブラリは入らない
import sys
from collections.abc import AsyncGenerator
from typing import Any
# OCI Generative AIのLLMをLangChainで定義(LangChainはLLMの定義のみに利用)
from langchain_community.chat_models.oci_generative_ai import ChatOCIGenAI
#エージェントの定義
class TravelPlannerAgent:
"""travel planner Agent"""
def __init__(self):
try:
# 利用するLLMを定義
self.model = ChatOCIGenAI(
model_id="cohere.command-a-03-2025",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id="ocid1.compartment.oc1..aaaaaaaa4azic6bxxxxxxx",
model_kwargs={"temperature": 0.7,"max_tokens": 500,},
)
# システムプロンプトの定義
self.system_prompt = (
"あなたは、旅行計画、目的地情報、そして旅行のおすすめを専門とする、旅行アシスタントのエキスパートです。"
"ユーザーが入力した内容に応じて下記の3点について端的に情報を提供してください。"
"1. お勧めの観光名所"
"2. お勧めのホテル"
"3. おおよその旅費"
)
except Exception as e:
print(f'Error initializing the model: {e!s}')
sys.exit()
# クライアント <-> LLMの間のメッセージの送受信を定義
async def stream(self, query: str) -> AsyncGenerator[dict[str, Any], None]:
try:
# LLMへ入力するシステムプロンプト(system_prompt)とユーザープロンプト(query)を指定
messages = [
SystemMessage(content=self.system_prompt),
HumanMessage(content=query),
]
# LLMからの出力を受け取る処理を定義
async for chunk in self.model.astream(messages):
if hasattr(chunk, "content") and chunk.content:
yield {"content": chunk.content, "done": False}
yield {"content": "", "done": True}
except Exception as e:
print(f'error: {e!s}')
yield {
"content": f"処理中にエラーが発生しました: {e}",
"done": True,
}
######################################################################
# AgentExecutorの定義
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from typing import override
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.events import EventQueue
from a2a.types import (
TaskArtifactUpdateEvent,
TaskState,
TaskStatus,
TaskStatusUpdateEvent,
)
from a2a.utils import new_text_artifact
class TravelPlannerAgentExecutor(AgentExecutor):
"""travel planner AgentExecutor"""
def __init__(self):
# 定義済のエージェントをインスタンス化
self.agent = TravelPlannerAgent()
@override
# A2A の AgentExecutor が「入力を受け取り、エージェントに処理させ、
# その結果をイベントとして返す」処理を定義
async def execute(
self,
context: RequestContext,
event_queue: EventQueue,
) -> None:
# クライアントからのユーザー入力を取得
query = context.get_user_input()
if not context.message:
raise Exception('No message provided')
# ユーザー入力を LLMに渡して応答を逐次生成する非同期ジェネレータを定義
async for event in self.agent.stream(query):
# A2A内で「タスクの途中経過や部分結果」を表現するためのイベントを定義
message = TaskArtifactUpdateEvent(
context_id=context.context_id, #どの会話やリクエストの文脈かを示すID
task_id=context.task_id, #同じ文脈内での 処理単位のID
# タスクの結果や途中生成物を A2A イベントに渡すためにラップする
artifact=new_text_artifact(
name='current_result',
text=event['content'],
),
)
# A2A内で処理するためのartifact(テキスト形式のオブジェクト)を作成
await event_queue.enqueue_event(message)
if event['done']:
break
# A2Aフレームワーク内で「タスクの状態が変わったこと」を通知するためのイベントを定義
# TaskState.pending → タスクが作成された直後、まだ開始していない状態
# TaskState.in_progress → タスクが実行中の状態
# TaskState.completed → タスクが完了した状態
# TaskState.failed → エラーでタスクが完了できなかった状態
status = TaskStatusUpdateEvent(
context_id=context.context_id,
task_id=context.task_id,
status=TaskStatus(state=TaskState.completed),
final=True,
)
await event_queue.enqueue_event(status)
@override
async def cancel(
self, context: RequestContext, event_queue: EventQueue
) -> None:
raise Exception('cancel not supported')
######################################################################
# 定義済のオブジェクトを全て纏めてASGIアプリケーションとして
# uvicornでhttpサーバー化
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
import uvicorn
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import (
AgentCapabilities,
AgentCard,
AgentSkill,
)
if __name__ == '__main__':
# AgentSkillの定義
skill = AgentSkill(
id='travel_planner',
name='travel planner agent',
description='travel planner',
tags=['travel planner'],
examples=['hello', 'nice to meet you!'],
)
# AgentCardの定義
agent_card = AgentCard(
name='travel planner Agent',
description='travel planner',
url='http://localhost:10001/',
version='1.0.0',
default_input_modes=['text'],
default_output_modes=['text'],
capabilities=AgentCapabilities(streaming=True),
skills=[skill], # AgentSkillを指定
)
# 他エージェントからからのメッセージをAgentExecutorに送受信するイベントハンドラを定義
request_handler = DefaultRequestHandler(
# 定義済のAgentExecutorを指定
agent_executor=TravelPlannerAgentExecutor(),
task_store=InMemoryTaskStore(),
)
# # 定義済のAgentCard、イベントハンドラをASGIアプリケーションとして定義
server = A2AStarletteApplication(
agent_card=agent_card, http_handler=request_handler
)
# 定義済のASGIアプリケーションをuvicornで起動
uvicorn.run(server.build(), host='0.0.0.0', port=10001)
ASGI(Asynchronous Server Gateway Interface):非同期サーバーゲートウェイインターフェース
PythonのWebサーバとWebアプリケーションが通信するためのインタフェース仕様
次にクライアント側のコードです。ポイントは以下の通り。
- サーバー化されたAgentのURLめがけて入力プロンプトを送信するagent_queryユーザー定義関数を作っています。(その前段のget_response_textはAgentの出力から応答テキストだけを取り出す単なるヘルパー関数)
- Agentのhttp server(URL)に接続するためにA2AClientでhttp clientを定義し、get_client_from_agent_card_urlでサーバー側のAgentCardを取得することで、そのAgentのskill(何ができるAgentなのか)をクライアント側が知ることができます。
- send_message_payloadでペイロード(送信するメッセージのデータセット)を定義、メッセージを送信する前に、一旦それをリクエストオブジェクトとして定義します
- そして肝心のメッセージを送受信する関数がsend_message_streamingです。
- (重要なポイント)クライアント側のこのコードはこの後定義する全てのエージェントで共通のコードです。異なるのはクラスの名前だけです。A2Aによって標準化されているためこのようなことが可能になります。
クライアント側のコード
# A2Aで標準化されているため全てのエージェントで共通のコード
from uuid import uuid4
import httpx
from a2a.client import A2AClient
from a2a.types import MessageSendParams, SendStreamingMessageRequest
from typing import List, Dict
# A2AのStreamingMessageから応答テキスト部分のみを抽出するヘルパー関数を定義
def get_response_text(chunk):
data = chunk.model_dump(mode="json", exclude_none=True)
result = data.get("result", {})
artifact = result.get("artifact")
if artifact and "parts" in artifact:
parts = artifact["parts"]
if parts and "text" in parts[0]:
return parts[0]["text"]
return ""
# エージェントにメッセージを送受信する関数を定義
async def agent_query(user_input: str, agent_url: str):
async with httpx.AsyncClient() as httpx_client:
# 指定のエージェントにhttp接続し、AgentCardを取得するA2AClientを定義
agent = await A2AClient.get_client_from_agent_card_url(httpx_client, agent_url)
# 送信するメッセージのペイロードを定義
send_message_payload = {
"message": {
"role": "user",
"parts": [{"type": "text", "text": user_input}],
"messageId": uuid4().hex,
},
}
# メッセージを送信するためのリクエストオブジェクトを定義
streaming_request = SendStreamingMessageRequest(
id=uuid4().hex,
params=MessageSendParams(**send_message_payload),
)
# リクエストオブジェクトを送信し、応答テキストを取得する定義
response_text = ""
async for chunk in agent.send_message_streaming(streaming_request):
chunk_text = get_response_text(chunk)
if chunk_text:
response_text += chunk_text
print(chunk_text, end="", flush=True)
print("\n--- 処理終了 ---\n")
return response_text
このクライアントを以下のように実行してみます。
# AgentのURLを定義
agent_url = "http://localhost:10001"
# クライアントのagent_query関数を実行
response = await agent_query("ウズベキスタンへの一泊の旅行を計画してください。", agent_url)
すると実行結果がこちら。
ウズベキスタンへの1泊旅行は、歴史と文化を凝縮して体験できるプランがおすすめです。以下に、**サマルカンド**を目的地としたプランをご提案します。
### 1. **お勧めの観光名所**
- **レギスタン広場**:青いタイル装飾が美しいイスラム建築の象徴。夜間のライトアップも必見。
- **ビビ・ハヌム・モスク**:ティムール帝国時代の巨大なモスク。青空に映えるドームが特徴。
- **グーリ・アミール廟**:ティムール皇帝の霊廟。内部の装飾と歴史的価値が高い。
- **シャーヒズィンダ街**:青のモスクや廟が連なる「死者の街」。写真映えする景観。
### 2. **お勧めのホテル**
- **ホテル・プレジデント・サマルカンド**(4つ星):レギスタン広場から徒歩圏内。モダンな設備と伝統的なデザインが融合。
- **マルコポーロ・サマルカンド**(3つ星):コストパフォーマンスが良く、観光地にアクセスしやすい。
### 3. **おおよその旅費**
- **航空券**:タシケントからサマルカンドまでの国内線(約1時間)で片道**$50~$100**。
- **宿泊費**:1泊**$50~$150**(ホテルにより変動)。
- **食事・交通費**:1日**$30~$50**(現地料理やタクシー利用含む)。
- **合計**:**$130~$300**(航空券+宿泊+現地費用)。
**ポイント**:時間有効活用のため、早朝にタシケント発のフライトで移動し、翌日夕方に帰るスケジュールが理想的です。
--- 処理終了 ---
上記は一つのエージェントをA2Aでサーバー化し、クライアントで呼び出すという非常にシンプルなコードですが、以降3つの異なるフレームワークで作るエージェントを追加する際も、このコードの構造は全く同じという点がポイントです。繰り返しになりますが、これはA2Aで標準化されているがゆえに実現する状況だということです。
移行、この調子で、様々なフレームワークを使ってエージェントを増産してみます。
LangGraphで作ったエージェントを更に追加(二つ目のエージェント)
次はLangGraphで作ったエージェントを追加します。ポイントはここまで説明した内容と基本同じです。追加点としては下記の通り。
- 一つ目と異なりこのAgentはLangGraphで作られていますのでAgent定義のパートはLangGraphのコードになっています。(LangGraphでAgentを作るときのお決まりの関数 create_react_agentを使っています。)
- 「AgentExecutoの定義」、「main関数の定義」のパートは一つ目と全く同じです。
サーバー側のコード
######################################################################
# Language Agentの定義
# LangGraph を使ってAgentを定義したパターン
# Agent定義のブロックではA2Aライブラリは使わない
######################################################################
import asyncio
from collections.abc import AsyncGenerator
from typing import Any, Dict
from langchain_community.chat_models import ChatOCIGenAI
# LangGraphのReAct Agentを定義する関数をimport
from langgraph.prebuilt import create_react_agent
from langchain.schema import AIMessage
class LanguageAgent:
"""Language Agent (LangGraph ReAct Agent)"""
def __init__(self):
# 利用するLLMを定義
self.model = ChatOCIGenAI(
model_id="cohere.command-a-03-2025",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id="ocid1.compartment.oc1..aaaaaaaa4azic6bpxxxxxxxx",
model_kwargs={"temperature": 0.7, "max_tokens": 200},
)
# システムプロンプトの定義
self.system_prompt = (
"あなたはユーザーの入力にある訪問地での公用語に関する情報を提供するアシスタントです。"
"ユーザーの入力文章の中にある国もしくは訪問地での公用語に関する情報を提供してください。"
)
# LangGraphのReActエージェントを初期化して保持
self.react_agent = create_react_agent(
self.model,
tools=[], # 今回はツールなし
prompt=self.system_prompt,
)
# クライアント <-> LLMの間のメッセージの送受信を定義
async def stream(self, query: str) -> AsyncGenerator[Dict[str, Any], None]:
try:
# LLMへユーザープロンプトを入力
react_response = await self.react_agent.ainvoke({
"messages": [
{"role": "user", "content": query}
]
})
# LLMの出力から、応答文章だけを抽出
response_text = None
for msg in react_response["messages"]:
if isinstance(msg, AIMessage):
response_text = msg.content
break
yield {"content": response_text, "done": True}
except Exception as e:
print(f'error: {e!s}')
yield {
"content": f"処理中にエラーが発生しました: {e}",
"done": True
}
######################################################################
# AgentExecutorの定義
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from typing import override
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.events import EventQueue
from a2a.types import (
TaskArtifactUpdateEvent,
TaskState,
TaskStatus,
TaskStatusUpdateEvent,
)
from a2a.utils import new_text_artifact
class LanguageAgentExecutor(AgentExecutor):
"""Language AgentExecutor"""
def __init__(self):
self.agent = LanguageAgent()
@override
async def execute(
self,
context: RequestContext,
event_queue: EventQueue,
) -> None:
query = context.get_user_input()
if not context.message:
raise Exception('No message provided')
async for event in self.agent.stream(query):
message = TaskArtifactUpdateEvent(
context_id=context.context_id,
task_id=context.task_id,
artifact=new_text_artifact(
name='current_result',
text=event['content'],
),
)
await event_queue.enqueue_event(message)
if event['done']:
break
status = TaskStatusUpdateEvent(
context_id=context.context_id,
task_id=context.task_id,
status=TaskStatus(state=TaskState.completed),
final=True,
)
await event_queue.enqueue_event(status)
@override
async def cancel(
self, context: RequestContext, event_queue: EventQueue
) -> None:
raise Exception('cancel not supported')
######################################################################
# 定義済のオブジェクトを全て纏めてASGIアプリケーションとして
# uvicornでhttpサーバー化
# # A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import (
AgentCapabilities,
AgentCard,
AgentSkill,
)
if __name__ == '__main__':
skill = AgentSkill(
id='language',
name='language agent',
description='language information provider',
tags=['language'],
examples=['TM', 'APPL'],
)
agent_card = AgentCard(
name='language Agent',
description='language information provider',
url='http://localhost:10002/',
version='1.0.0',
default_input_modes=['text'],
default_output_modes=['text'],
capabilities=AgentCapabilities(streaming=True),
skills=[skill],
)
request_handler = DefaultRequestHandler(
agent_executor=LanguageAgentExecutor(),
task_store=InMemoryTaskStore(),
)
server = A2AStarletteApplication(
agent_card=agent_card, http_handler=request_handler
)
import uvicorn
uvicorn.run(server.build(), host='0.0.0.0', port=10002)
クライアント側のコード
クライアント側のコードは一つ目のエージェントと全く同じです。(繰り返しになりますがこれはA2Aの標準化ライブラリのおかげということになります。)
コード実行時に下記のようにAgentのURLを2つ目のものに変更すればそのまま動作します。
# AgentのURLを定義
agent_url = "http://localhost:10002"
# クライアントのagent_query関数を実行
response = await agent_query("ウズベキスタンへの一泊の旅行を計画してください。", agent_url)
Autogenで作ったエージェントを更に追加(三つ目のエージェント)
次はAutogenで作ったエージェントを追加します。ポイントはここまで説明した内容と基本同じです。追加点としては下記の通り。
- 一つ目と異なりこのAgentはAutogenで作られていますのでAgent定義のパートはAutogenのコードになっています。(AutogenでAgentを作るときのお決まりの関数UserProxyAgentやAssistantAgentを使っています。多少、Autogenの特徴的なコードになっています。)
- また、OCI ADSというライブラリでOCI Generaitive AIをLangChainのカスタムLLMとして定義し、それをAutogenに認識させるという手順を踏んでいます。少しライブラリをスタックしていますが、AutogenがダイレクトにサポートしいるLLMを使う場場合はもっとシンプルな定義になります。
- 「AgentExecutoの定義」、「main関数の定義」のパートは一つ目と全く同じです。
######################################################################
# Restaurant Agentの定義
# AutoGen を使ってAgentを定義したパターン
# Agent定義のブロックではA2Aライブラリは使わない
######################################################################
import sys
from typing import Any, AsyncGenerator
import ads
# OCI Generative AI ServiceのLLMをLangChainのカスタムLLMとして定義するために ADSをimport
# これにより、AutogenからOCI Generative AI ServiceのLLMを認識できる状態にする
from ads.llm.autogen.v02 import LangChainModelClient, register_custom_client
from langchain_community.chat_models.oci_generative_ai import ChatOCIGenAI
# AutogenのAgentを定義する関数をimport
from autogen import UserProxyAgent, AssistantAgent, GroupChat, GroupChatManager
class RestaurantAgent:
"""Restaurant Agent(Autogen)"""
def __init__(self):
# LangChainのカスタムLLMを定義
register_custom_client(LangChainModelClient)
# LangChainのカスタムLLMにOCI Generative AI ServiceのLLMを定義
# これにより AutoGenからOCI Generative AI ServiceのLLMが利用可能になる
config_list_custom = [
{
"model_client_cls": "LangChainModelClient",
"langchain_cls": "langchain_community.chat_models.oci_generative_ai.ChatOCIGenAI",
"client_params": {
"model_id": "cohere.command-r-08-2024",
"compartment_id": "ocid1.compartment.oc1..aaaaaaaa4azic6bp7obsfxxxxx",
"model_kwargs": {
"temperature": 0,
"max_tokens": 4000,
},
"service_endpoint": "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
"auth_type": "API_KEY",
"auth_profile": "DEFAULT",
},
}
]
self.llm_config = {
"seed": 0,
"config_list": config_list_custom,
"temperature": 0,
}
# Autogen の User Agent
self.user_agent = UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
code_execution_config={"use_docker": False},
)
# AutogenのRestaurant Agent
self.restaurant_agent = AssistantAgent(
name="restaurant_agent",
llm_config=self.llm_config,
description="あなたは有名なレストランを提案できるアシスタントです。",
system_message="入力されたユーザープロンプト内にある訪問地の著名なレストランを一つだけ提案してください。",
)
agents = [self.user_agent, self.restaurant_agent]
# AutogenのGroupChat(User Agent と Restaurant Agent)を定義
self.group_chat = GroupChat(
agents=agents,
messages=[],
max_round=2,
speaker_selection_method="round_robin",
)
# GroupChat Manager(複数のエージェントとユーザー間の会話を 調整・管理するコンポーネント)を定義
self.chat_manager = GroupChatManager(
groupchat=self.group_chat,
llm_config=self.llm_config,
code_execution_config=False,
)
# クライアント <-> LLMの間のメッセージの送受信を定義
async def stream(self, query: str) -> AsyncGenerator[dict[str, Any], None]:
try:
response = self.user_agent.initiate_chat(
self.chat_manager, message=query
)
summary = getattr(response, "summary", None)
if summary:
yield {"content": summary, "done": False}
yield {"content": "", "done": True}
except Exception as e:
print(f"error:{e!s}")
yield {
"content": f"処理中にエラーが発生しました: {e}",
"done": True,
}
######################################################################
# AgentExecutorの定義
# フレームワークで作ったエージェントをA2Aのエージェントに変換
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from typing import override
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.events import EventQueue
from a2a.types import (
TaskArtifactUpdateEvent,
TaskState,
TaskStatus,
TaskStatusUpdateEvent,
)
from a2a.utils import new_text_artifact
class RestaurantAgentExecutor(AgentExecutor):
"""Restaurant AgentExecutor Example."""
def __init__(self):
self.agent = RestaurantAgent()
@override
async def execute(
self,
context: RequestContext,
event_queue: EventQueue,
) -> None:
query = context.get_user_input()
if not context.message:
raise Exception('No message provided')
async for event in self.agent.stream(query):
message = TaskArtifactUpdateEvent(
context_id=context.context_id, # type: ignore
task_id=context.task_id, # type: ignore
artifact=new_text_artifact(
name='current_result',
text=event['content'],
),
)
await event_queue.enqueue_event(message)
if event['done']:
break
status = TaskStatusUpdateEvent(
context_id=context.context_id, # type: ignore
task_id=context.task_id, # type: ignore
status=TaskStatus(state=TaskState.completed),
final=True,
)
await event_queue.enqueue_event(status)
@override
async def cancel(
self, context: RequestContext, event_queue: EventQueue
) -> None:
raise Exception('cancel not supported')
######################################################################
# 定義済のオブジェクトを全て纏めてASGIアプリケーションとして
# uvicornでhttpサーバー化
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import (
AgentCapabilities,
AgentCard,
AgentSkill,
)
if __name__ == '__main__':
skill = AgentSkill(
id='restaurant',
name='restaurant agent',
description='restaurant information provider',
tags=['restaurant'],
examples=['TM', 'APPL'],
)
agent_card = AgentCard(
name='restaurant Agent',
description='restaurant information provider',
url='http://localhost:10003/',
version='1.0.0',
default_input_modes=['text'],
default_output_modes=['text'],
capabilities=AgentCapabilities(streaming=True),
skills=[skill],
)
request_handler = DefaultRequestHandler(
agent_executor=RestaurantAgentExecutor(),
task_store=InMemoryTaskStore(),
)
server = A2AStarletteApplication(
agent_card=agent_card, http_handler=request_handler
)
import uvicorn
uvicorn.run(server.build(), host='0.0.0.0', port=10003)
クライアント側のコード
クライアント側のコードは一つ目のエージェントと全く同じです。(繰り返しになりますがこれはA2Aの標準化ライブラリのおかげということになります。)
コード実行時に下記のようにAgentのURLを3つ目のものに変更すればそのまま動作します。
# AgentのURLを定義
agent_url = "http://localhost:10003"
# クライアントのagent_query関数を実行
response = await agent_query("ウズベキスタンへの一泊の旅行を計画してください。", agent_url)
OpenAI Agents SDK で作ったエージェントを更に追加(四つ目のエージェント)
次はOpenAI Agents SDKで作ったエージェントを追加します。ポイントはここまで説明した内容と基本同じです。追加点としては下記の通り。
- 一つ目と異なりこのAgentはOpenAI Agents SDKで作られていますのでAgent定義のパートはOpenAI Agents SDKのコードになっています。(OpenAI Agents SDKでAgentを作るときのお決まりの関数Agentを使っています。)
- また、LiteLLMでOCI Generaitive AIをラップし、それをOpenAI Agents SDKに認識させるという手順を踏んでいます。OpenAI Agents SDKがダイレクトにサポートしいるLLMを使う場場合はもっとシンプルな定義になります。
- 「AgentExecutoの定義」、「main関数の定義」のパートは一つ目と全く同じです。
######################################################################
# CurrencyAgent Agentの定義
# OpenAI Agents SDK を使ってAgentを定義したパターン
# Agent定義のブロックではA2Aライブラリは使わない
######################################################################
import oci
from collections.abc import AsyncGenerator
from typing import Any
# OCI Generative AI ServiceのLLMをLiteLLMでラップする
# これにより、OpenAI Agents SDKからOCI Generative AI ServiceのLLMを認識できる状態にする
from agents.extensions.models.litellm_model import LitellmModel
from agents.model_settings import ModelSettings
# OpenAI Agents SDKのAgentを定義、実行する関数をimport
from agents import Agent, Runner
class CurrencyAgent:
"""Currency Agent(OpenAI Agents SDK)"""
def __init__(self):
# ~/.oci/config からデフォルトプロファイルを読み込み
config = oci.config.from_file("~/.oci/config", "DEFAULT")
# OCI 認証情報の定義
oci_user = config["user"]
oci_fingerprint = config["fingerprint"]
oci_tenancy = config["tenancy"]
oci_region = config["region"]
# ローカルの秘密鍵を定義
with open(config["key_file"], "r") as f:
oci_key = f.read()
# OCIのコンパートメントIDを定義
oci_compartment_id = "ocid1.compartment.oc1..aaaaaaaa4azic6bp7obsfusyxxxxx"
# 認証情報をOpenAI Agents SDKで認識できるように定義
model_settings = ModelSettings(
extra_args={
"oci_user": oci_user,
"oci_fingerprint": oci_fingerprint,
"oci_tenancy": oci_tenancy,
"oci_region": oci_region,
"oci_key": oci_key,
"oci_compartment_id": oci_compartment_id
}
)
# OpenAI Agents SDKでエージェントを定義
self.agent = Agent(
name="Currency Agent",
instructions=(
"ユーザーの入力内容に基づいて下記の2点のみの情報を提供してください。\n"
"1. その国の通貨\n"
"2. 日本円との為替換算レート"
),
model=LitellmModel(model="oci/xai.grok-4"),
model_settings=model_settings,
)
# クライアント <-> LLMの間のメッセージの送受信を定義
async def stream(self, query: str) -> AsyncGenerator[dict[str, Any], None]:
try:
# LLMにユーザープロンプトを入力
runner = Runner()
run_result = await runner.run(self.agent, query)
# Run結果の各アイテムを非同期で逐次処理
for item in run_result.new_items:
raw_item = item.raw_item
if hasattr(raw_item, "content"):
for content in raw_item.content:
if hasattr(content, "text") and content.text:
yield {"content": content.text, "done": False}
# 最後に完了シグナル
yield {"content": "", "done": True}
except Exception as e:
print(f'error: {e!s}')
yield {
"content": f"処理中にエラーが発生しました: {e}",
"done": True,
}
######################################################################
# AgentExecutorの定義
# フレームワークで作ったエージェントをA2Aのエージェントに変換
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from typing import override
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.events import EventQueue
from a2a.types import (
TaskArtifactUpdateEvent,
TaskState,
TaskStatus,
TaskStatusUpdateEvent,
)
from a2a.utils import new_text_artifact
class CurrencyAgentExecutor(AgentExecutor):
"""Currency AgentExecutor Example."""
def __init__(self):
self.agent = CurrencyAgent()
@override
async def execute(
self,
context: RequestContext,
event_queue: EventQueue,
) -> None:
query = context.get_user_input()
if not context.message:
raise Exception('No message provided')
async for event in self.agent.stream(query):
message = TaskArtifactUpdateEvent(
context_id=context.context_id, # type: ignore
task_id=context.task_id, # type: ignore
artifact=new_text_artifact(
name='current_result',
text=event['content'],
),
)
await event_queue.enqueue_event(message)
if event['done']:
break
status = TaskStatusUpdateEvent(
context_id=context.context_id, # type: ignore
task_id=context.task_id, # type: ignore
status=TaskStatus(state=TaskState.completed),
final=True,
)
await event_queue.enqueue_event(status)
@override
async def cancel(
self, context: RequestContext, event_queue: EventQueue
) -> None:
raise Exception('cancel not supported')
######################################################################
# 定義済のオブジェクトを全て纏めてASGIアプリケーションとして
# uvicornでhttpサーバー化
# A2Aで標準化されているため全てのエージェントで共通のコード
######################################################################
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import (
AgentCapabilities,
AgentCard,
AgentSkill,
)
if __name__ == '__main__':
skill = AgentSkill(
id='currency',
name='currency agent',
description='currency information provider',
tags=['currency'],
examples=['USD', 'JPY 146'],
)
agent_card = AgentCard(
name='currency Agent',
description='currency information provider',
url='http://localhost:10004/',
version='1.0.0',
default_input_modes=['text'],
default_output_modes=['text'],
capabilities=AgentCapabilities(streaming=True),
skills=[skill],
)
request_handler = DefaultRequestHandler(
agent_executor=CurrencyAgentExecutor(),
task_store=InMemoryTaskStore(),
)
server = A2AStarletteApplication(
agent_card=agent_card, http_handler=request_handler
)
import uvicorn
uvicorn.run(server.build(), host='0.0.0.0', port=10004)
クライアント側のコード
クライアント側のコードは一つ目のエージェントと全く同じです。(繰り返しになりますがこれはA2Aの標準化ライブラリのおかげということになります。)
コード実行時に下記のようにAgentのURLを3つ目のものに変更すればそのまま動作します。
# AgentのURLを定義
agent_url = "http://localhost:10004"
# クライアントのagent_query関数を実行
response = await agent_query("ウズベキスタンへの一泊の旅行を計画してください。", agent_url)
以上、異なるフレームワークを使った4つのエージェントをA2Aで定義ました。ここまでで、4つのエージェントを稼働させ、クライアントコードでそれぞれ個別にアクセスできたことを確認することができました。
ですが、やりたいことは、このように様々なエージェントが世界中でリリースされ、それらをマルチエージェントシステムとして動作させたいということでした。なのでここからクライアント側のコードに、この4つのエージェントをマルチエージェントとして動作させるロジックを組み込みます。
クライアント側コードにマルチエージェントのロジックを追加して実行
複数のエージェントを連動させるやり方には様々な手法がありますが、
- 今回はシンプルにエージェントを順番に動作させて、いわゆるマルチステップワークフローのシンプルなロジックにしています。
- マルチステップワークフローとは前のエージェントの出力の内容に応じて次のエージェントの出力が決まるという処理です。
- メッセージを送受信する処理自体はこれまでと同様(send_message_streaming関数で実行)の手順です。(つまり、シングルだろうがマルチだろうがここは同じ手順で実装できるということです。A2AやGoogleのAgent Development Kitを使うともっと便利な便利な関数があるので様々なマルチエージェントの処理が簡単に実装できると思います。)
- その際、各エージェントの出力はブラックボード(共有メモリ)で全てのエージェントに共有されるようにしています。
特に業務アプリケーションでマルチエージェントを構成する場合に、最も堅実でよく検討される方法がマルチステップワークフローだと思います。
クライアント側のコード(マルチエージェントのロジックを追加)
# A2Aで標準化されているため全てのエージェントで共通のコード
from uuid import uuid4
import httpx
# A2Aのクライアントを定義するクラスA2AClientをimport
from a2a.client import A2AClient
# クライアントからサーバーへメッセージを送受信するクラスをimport
from a2a.types import MessageSendParams, SendStreamingMessageRequest
from typing import List, Dict
# A2AのStreamingMessageから応答テキスト部分のみを抽出するヘルパー関数を定義
def get_response_text(chunk):
data = chunk.model_dump(mode='json', exclude_none=True)
result = data.get("result", {})
artifact = result.get("artifact")
if artifact and "parts" in artifact:
parts = artifact["parts"]
if parts and "text" in parts[0]:
return parts[0]["text"]
return ""
# 各エージェントの応答テキストをブラックボード(共有メモリ)に記録し、エージェント間で共有
async def blackboard_agents(user_input: str, agent_urls: List[str]):
async with httpx.AsyncClient() as httpx_client:
agents = [
# 指定のエージェントにhttp接続し、AgentCardを取得するA2AClientを定義
await A2AClient.get_client_from_agent_card_url(httpx_client, url)
for url in agent_urls
]
# ブラックボードを定義
blackboard: Dict[str, str] = {}
for i, agent in enumerate(agents, 1):
agent_name = f"Agent{i}"
print(f"\n--- {agent_name} の処理 ---\n")
# ブラックボードの内容をまとめて入力にする
board_text = "\n".join([f"{k}: {v}" for k, v in blackboard.items()])
prompt = f"共有メモリの内容:\n{board_text}\n\nユーザー入力:\n{user_input}"
send_message_payload = {
"message": {
"role": "user",
"parts": [{"type": "text", "text": prompt}],
"messageId": uuid4().hex,
},
}
# メッセージを送信するためのリクエストオブジェクトを定義
streaming_request = SendStreamingMessageRequest(
id=uuid4().hex,
params=MessageSendParams(**send_message_payload),
)
# リクエストオブジェクトを送信し、応答テキストを取得する定義
response_text = ""
async for chunk in agents[i-1].send_message_streaming(streaming_request):
chunk_text = get_response_text(chunk)
if chunk_text:
response_text += chunk_text
print(chunk_text, end="", flush=True)
# エージェントの応答テキストをブラックボードに書き込む
blackboard[agent_name] = response_text
print("\n--- 処理終了 ---\n")
return blackboard
下記のように4つ全てのエージェントを追加して連動させて実行してみます。
agent_urls = [
"http://localhost:10001",
"http://localhost:10002",
"http://localhost:10003",
"http://localhost:10004",
]
blackboard = await blackboard_agents("ウズベキスタンへの一泊の旅行を計画してください。", agent_urls)
実行結果がこちら。
--- Agent1 の処理 ---
**ウズベキスタン一泊旅行の提案**
**1. お勧めの観光名所**
- **レギスタン広場(サマルカンド)**:イスラム建築の象徴である3つのマドラサ(神学校)が並ぶ世界遺産。夜間のライトアップが特に美しい。
- **グーリ・アミール廟(サマルカンド)**:ティムール帝国の創始者ティムールの霊廟。青色タイルとドームが特徴。
- **ビビ・ハナム・モスク(タシケント)**:中央アジア最大級のモスク。ウズベキスタンの現代と伝統が融合した景観。
**2. お勧めのホテル**
- **ホテル・サマルカンド(サマルカンド)**:レギスタン広場至近の4つ星ホテル。伝統的なデザインとモダンな設備を兼備。
- **ハイアット・リージェンシー・タシケント(タシケント)**:首都中心部の高級ホテル。一泊旅行なら移動時間を節約できる。
**3. おおよその旅費**
- **航空券**:日本からの直行便(タシケント)で往復約10~15万円。
- **宿泊費**:4つ星ホテルで1泊約1.5~3万円。
- **食事・交通費**:1日あたり約5,000~1万円(現地移動はタクシーや地下鉄利用)。
- **合計目安**:**約15~20万円**(航空券込み)。
**※注意**:一泊では移動時間が厳しいため、タシケントに絞るか、サマルカンドに直行する便を利用するのが現実的です。
--- Agent2 の処理 ---
ウズベキスタンの公用語は**ウズベク語**です。ただし、ロシア語も広く使用されており、特にビジネスや行政の場面でよく使われています。また、観光地では英語が通じる場合もありますが、基本的なウズベク語やロシア語のフレーズを覚えておくと便利です。
一泊の旅行では、タシケントやサマルカンドに絞るのが現実的です。どちらの都市でも、上記の観光名所やホテルがおすすめです。
--- Agent3 の処理 ---
ウズベキスタンへの一泊旅行を計画するなら、サマルカンドの「ホテル・サマルカンド」がおすすめです。レギスタン広場に近く、伝統的なデザインとモダンな設備を兼ね備えた4つ星ホテルで、ウズベキスタンの歴史と文化を体感できるでしょう。
--- Agent4 の処理 ---
1. その国の通貨: ウズベキスタン・スム (UZS)
2. 日本円との為替換算レート: 1 UZS ≈ 0.012 JPY (2023年10月時点の目安、変動します)
--- 処理終了 ---
全ての各エージェントが自分の役目を果たしつつ、他のエージェントと連動して、結果を出力していることがわかります。
マルチステップワーフロー以外に、Host Agent型、Supervised Agent型、Orchestrator Agent型などと呼ばれる方式があります。これらの構成では、追加のエージェントを定義し、そのエージェントが入力プロンプトに応じて、どのエージェントをどのような順序で実行するかを決めるという処理フローとなり、いかにもAIを使ったクールなアーキテクチャという印象が強いマルチエージェントのアプリケーションになります。が、業務アプリの場合、実はあまりお勧めではありません。なぜなら、このエージェントの選択と実行順序はLLMの推論によって決まり、100回実行すれば100回間違いなく正しい結果になるという保証はありません。 業務アプリケーションの場合はたいてい処理フローは決まっているケースが多いですから、そういう場合に限っては、そこを敢えてLLMの推論に頼るよりも自分でちゃんとロジックをおこした方がいいと思います。LLMは便利なデータ処理エンジンやワークフローエンジンとしても使えますが、推論ミスの可能性を考慮すると、使わないくていいのであれば使わないに越したことはありません。
さいごに
このサンプルコードは「Hello World」のように非常にシンプルなものですが、A2Aの最大のメリットである以下の3点を確認が確認できたと思います。
- 4つの異なるフレームワークで作った4つのエージェントをマルチエージェントとして連携動作していることがわかります
- エージェントをサーバー化する処理がA2Aによって標準化されているため4つの異なるフレームワークを使っていても、全て同じ手順で実装できています
- クライアントから、この異なるフレームワークで作った4つのエージェントにアクセスする際も、全く同じクライアントコードでアクセスできていることがわかります
つまり、A2Aによって異なるフレームワークで作られたエージェント間の通信が完全に標準化されているということになり、開発者はフレームワークの違いを意識することなく、複数のエージェントを容易に統合・拡張できる環境が手に入る、ということです。
これにより、複雑なマルチエージェントシステムでも運用・保守がシンプルになり、迅速なプロトタイピングや本番運用への展開が可能になります。