本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
本記事は下記記事の補足記事となります。
※セミナー実施時の動画は以下。
実装の概要
LangChainを使ったマルチモーダルRAGのリファレンス実装概説です。プライベートなデータ(架空の企業の製品概要資料)を埋め込みモデルCLIPでベクトル化し、ベクトルデータベースChromaにロードします。
このRAGの環境で、LangChainのプレイグラウンドからプロンプトを入力し、GPT4にとって未知の情報をベクトルデータベース内のデータと組み合わせてうまくテキスト生成できるか、を試してみます。
構成図は以下の通り。
- MLLM : GPT4-V
- 画像データ埋め込みモデル:CLIP
- ベクトルデータベース:Chroma
- オーケストレーションツール:LangChain
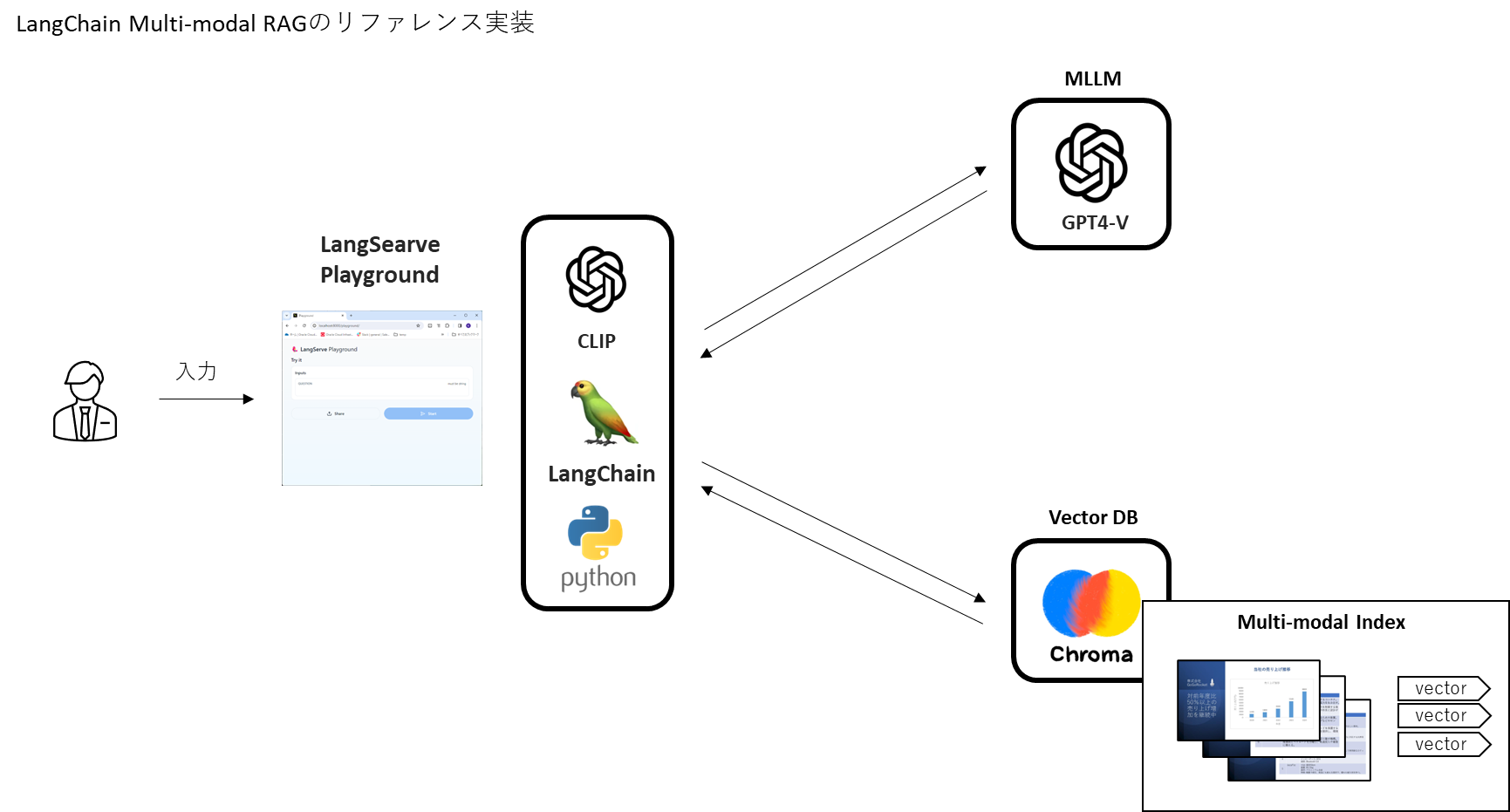
この構成を作るべく下記設定を行います。
設定
python仮想環境の作成とライブラリのインストール
まず、langchainのリポジトリをクローンします。このサンプルコードはpythonの仮想化機能であるpoetryで動作させることになるのでその設定を行います。
pip install --upgrade pip
git clone https://github.com/langchain-ai/langchain.git
cd ./langchain/templates/rag-chroma-multi-modal
pip install poetry
poetry install
これでこのリファレンス実装を稼働させるためのコアライブラリがバージョン一貫性を保った状態でpoetryの仮想環境にインストールされました。更に追加で下記ライブラリをインストールします。
pip install open_clip_torch torch
pip install langchain_experimental
pip install langchain_community
pip install -U langchain-cli
pip install chromadb
pip install pydantic==1.10.13
pip install pypdfium2
この状態でLangChain、CLIP、Chroma(ベクトルデータベース)がセットアップされています。
データの埋め込み処理とベクトルデータベースへのロード
環境がセットアップされた状態なので、実際にRAGの対象となるドキュメントデータをベクトルデータベースにロードします。
ドキュメントデータ
langchain/templates/rag-chroma-multi-modal/docs のディレクトリにサンプルデータとして「DDOG_Q3_earnings_deck.pdf」というPDFファイルがあります。下記のような30ページ程度のプレゼンテーション資料です。
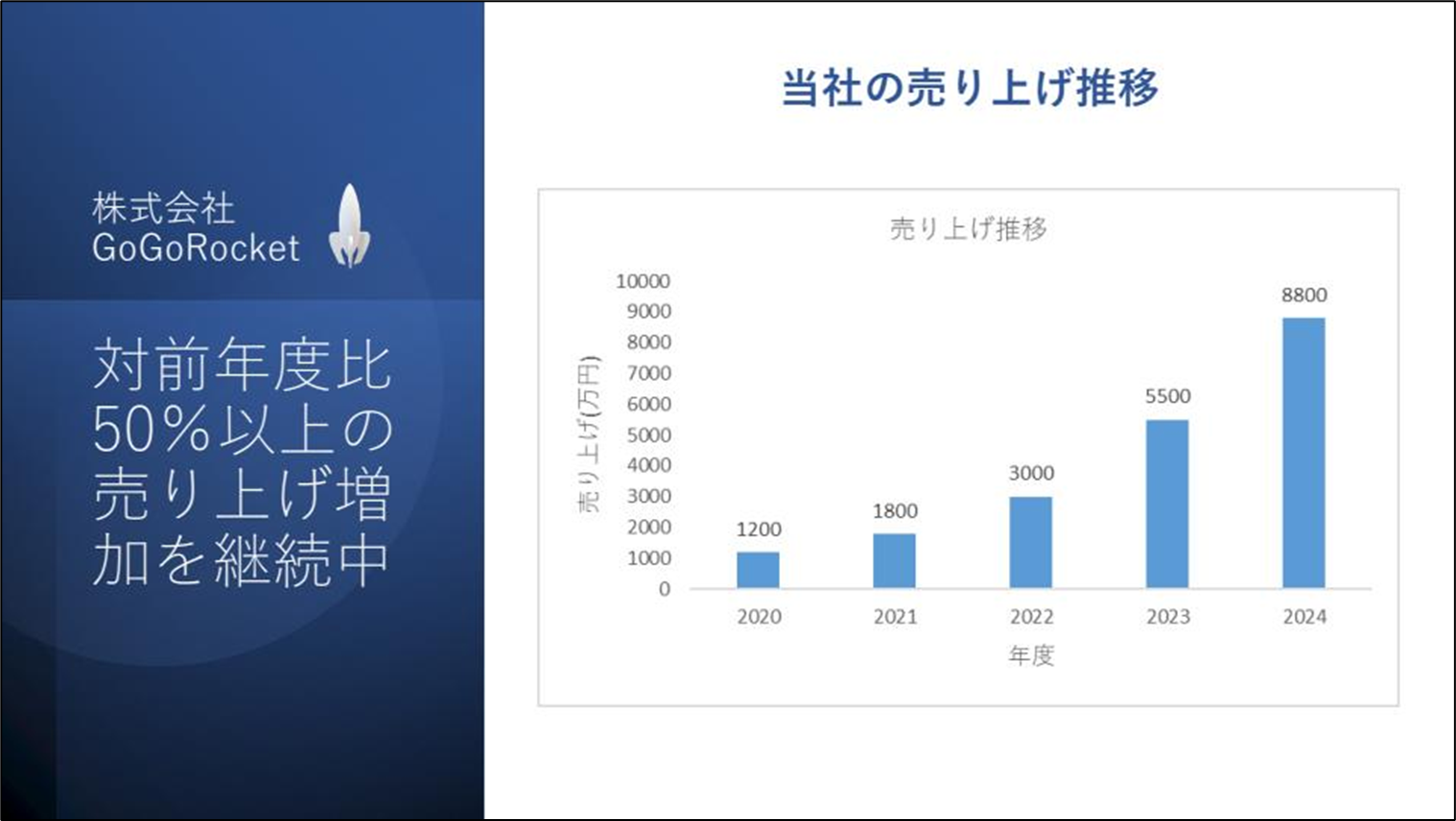
これをそのまま使ってもいいですが、今回は以下のような日本語の資料を作ってみたので置き換えてみたいと思います。架空の会社のプレゼンテーション資料のイメージで3ページのPDFです。


埋め込みとデータのロード
ドキュメントローダーでPDFファイルを読み込み、画像ファイル(jpg)に変換し、CLIPで埋め込み処理をし、生成したベクトルデータをChromaにロードします。この処理は同じpoetryのプロジェクトディレクトリにある ingest.py が全て実行してくれます。
下記のようにingest.pyを実行し、chromaにこのデータをベクトルデータとしてロードします。
python ingest.py
数分経過後処理が完了します。
参考までに、このpython スクリプトでは下記のような処理を行っています。
- PDFファイルをドキュメントローダーに取り込み、一ページ毎に区切る
- PDFをJPEGファイルに変換(このデータの場合はこの時点で3つのJPEGファイルが出来上がっています。)
- このJEPEGファイルをCLIPで埋め込み
- ベクトルデータベースにロードしインデックス作成
プレイグラウンドのサービスを起動
LangChainにはLangServeというプレイグランドの機能があります。このサービスを起動するために以下の設定を行います。
まず、poetryのプロジェクトディレクトリに下記を記載した server.py というファイルを作成します。
from rag_chroma_multi_modal import chain as rag_chroma_multi_modal_chain
add_routes(app, rag_chroma_multi_modal_chain, path="/rag-chroma-multi-modal")
OpenAIのAPIキーを環境変数で設定し、poetryの仮想環境から下記コマンドでLangServe Playgroundのサービスを起動します。
export OPENAI_API_KEY=xxxxxx
poetry shell
langchain serve
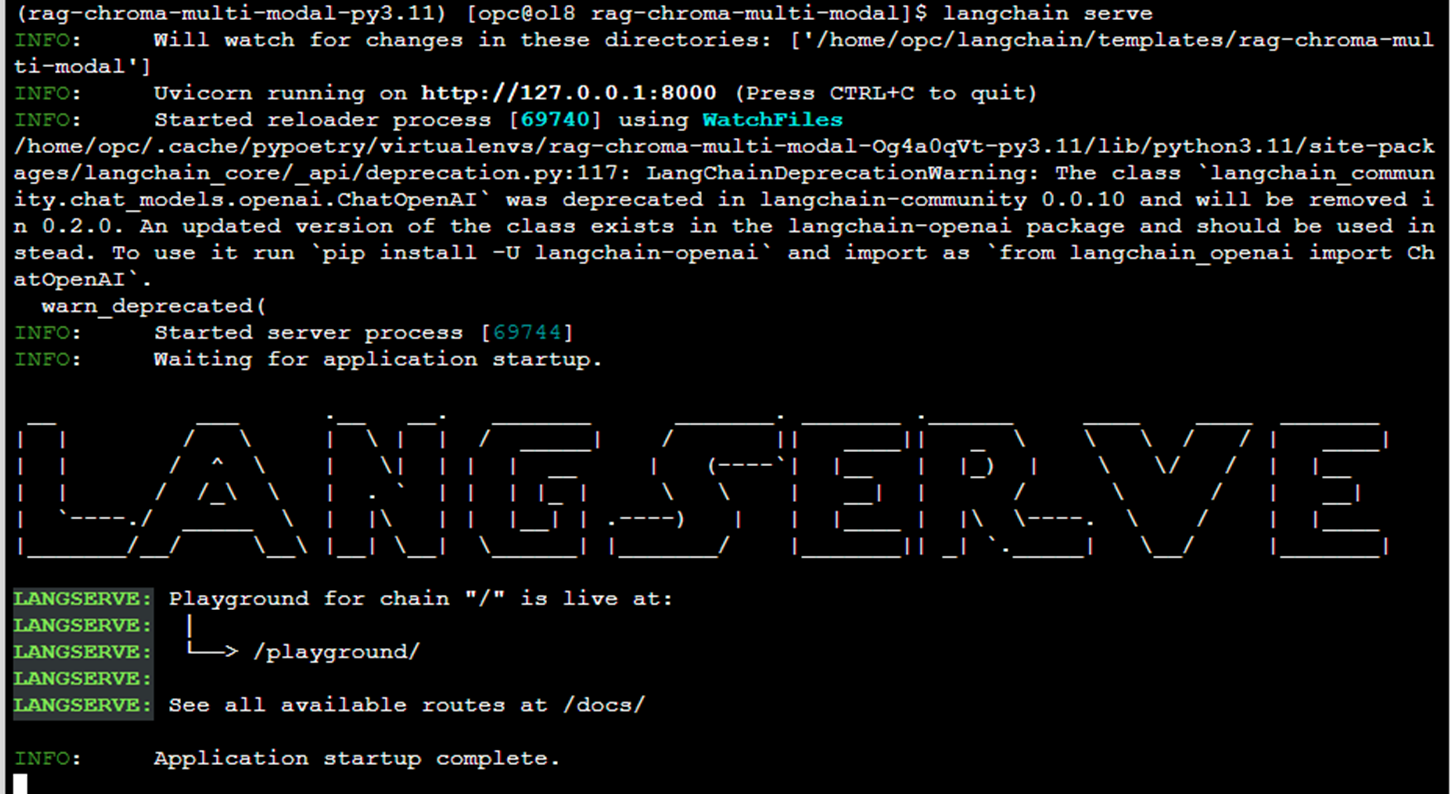
下図のようにエラーなくLANGSERVEのテキストアートが表示されればサービス起動成功です。
ブラウザからプレイグラウンド(http://localhost:8000)にアクセスすると下図のようにLangServe Playgroundが表示されます。(リモートのインスタンスでサービスを起動している場合はポートフォワーディングなどしてください。)
質問を入力してみる
プレイグラウンドの画面から質問を入力してみます。ベクトルデータベースに入っているデータがないと答えられない質問をいくつかしてみます。
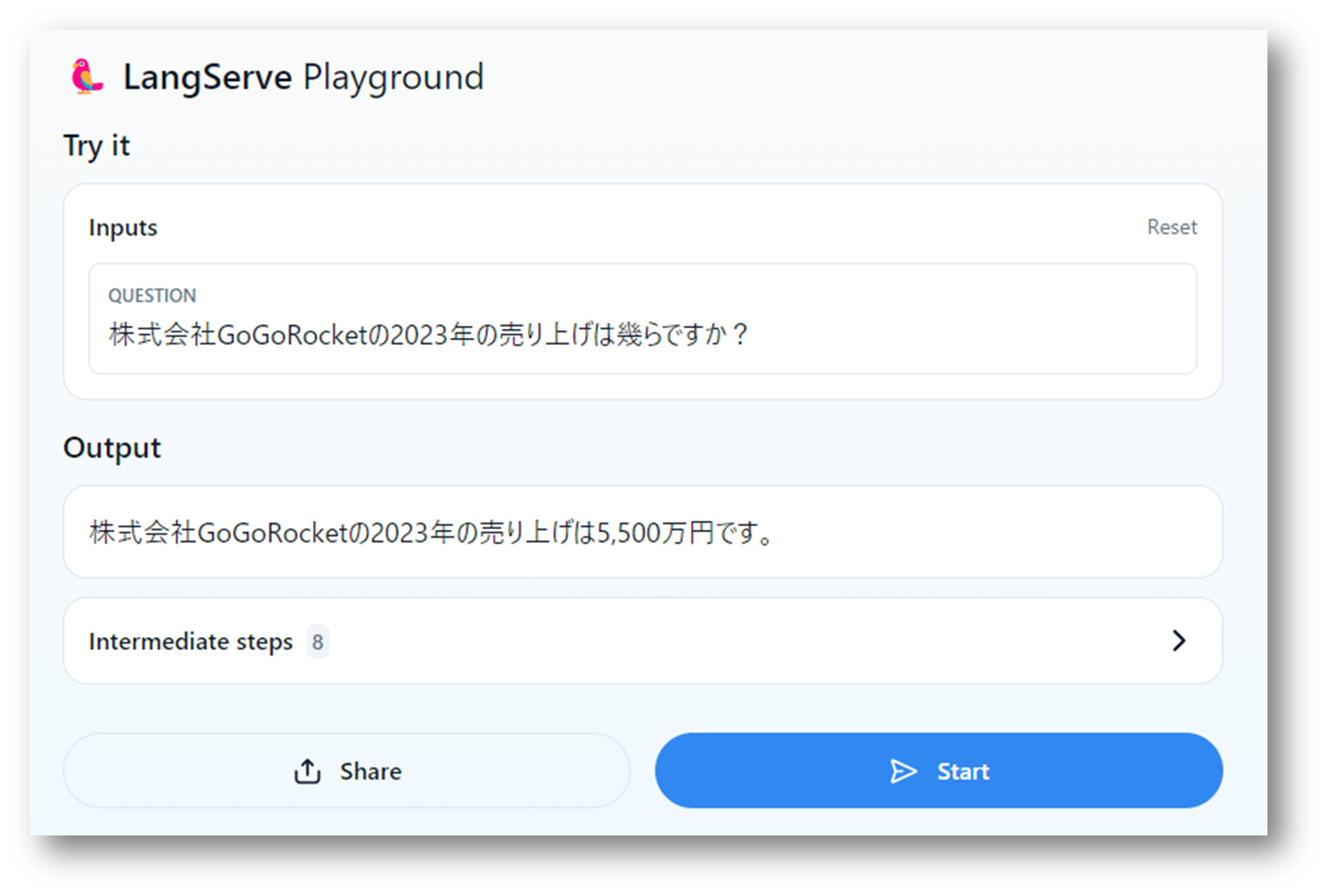
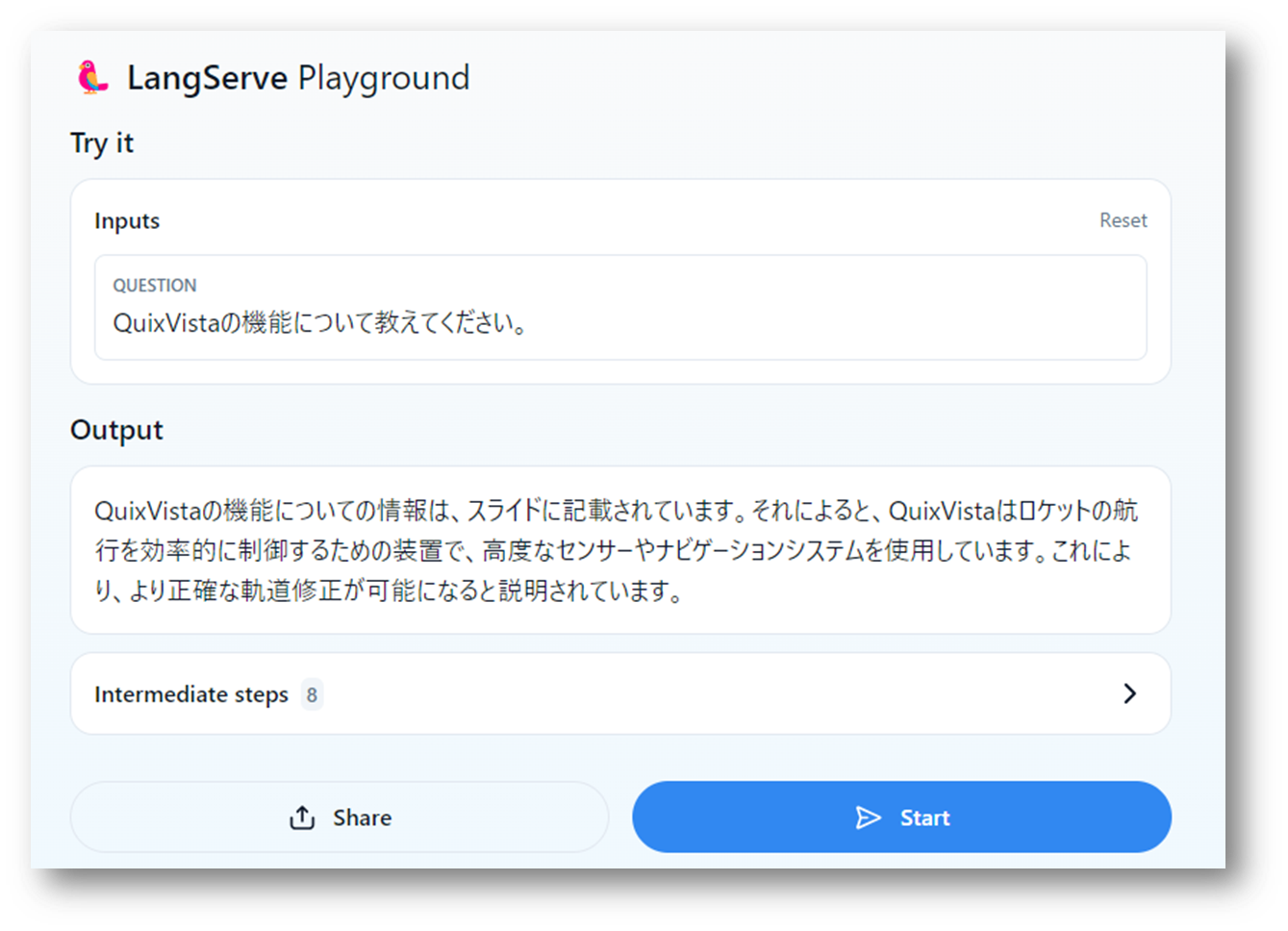
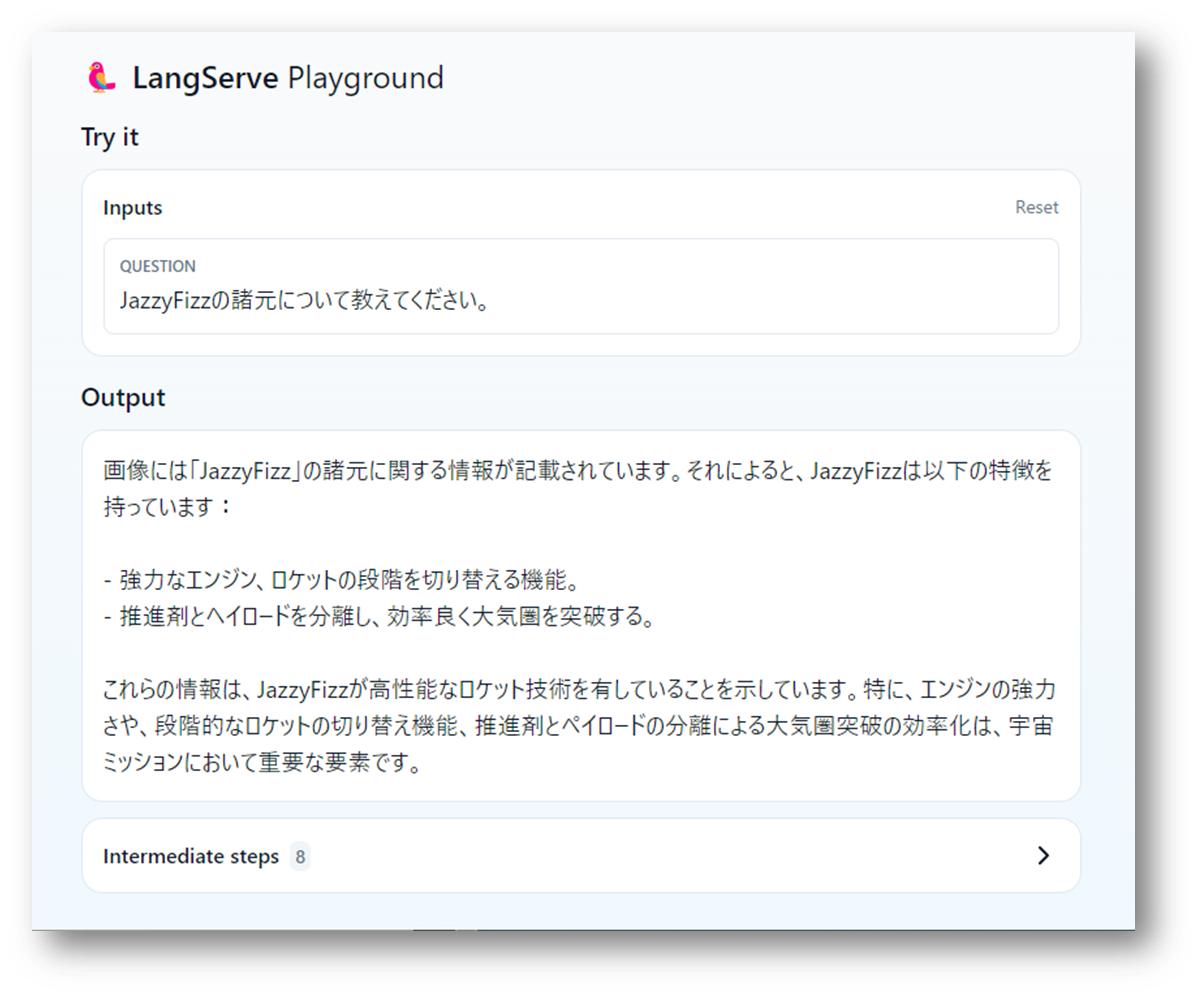
MLLMで応答できない質問については、ベクトルデータベースの情報をもとに、テキスト生成をしていることが確認できました。
大規模言語モデル関連のその他の記事