本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
本記事は下記記事の補足記事となります。
GPT4 Turbo with Vision
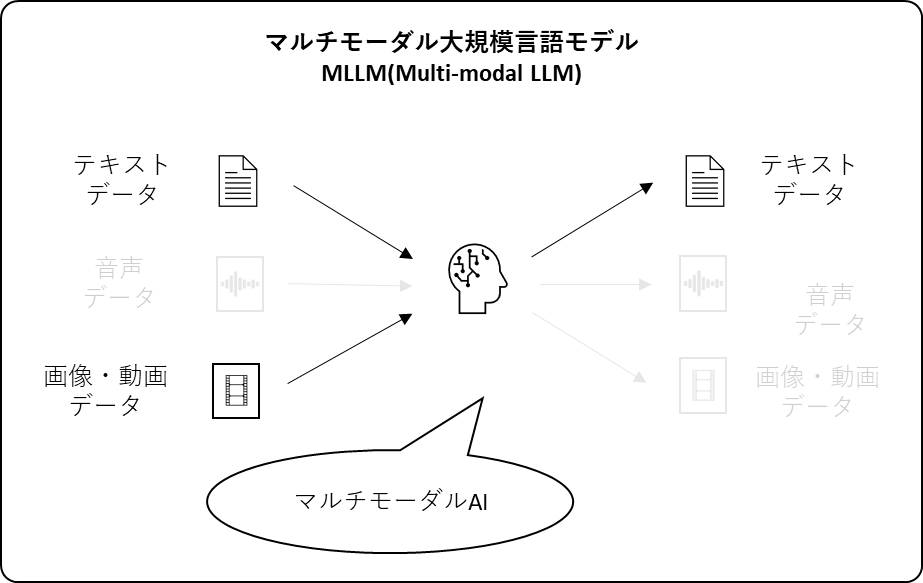
OpenAIの新しいマルチモーダル大規模言語モデル GPT4-Vを様々な画像データとプロンプトで試してみる。マルチモーダルAIとしては、下図の通り、
- 入力:テキストデータ、画像データ
- 出力:テキストデータ
となるパターンで、使っているモデルはGPT4 Turbo with Vision(gpt-4-vision-preview)。
画像キャプション
入力画像:風景画
入力テキスト:画像の説明(画像データのキャプション)を求めるテキスト

from openai import OpenAI
# openai clientの定義
client = OpenAI()
response = client.chat.completions.create(
# Muti-modal LLM を定義
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
# 入力プロンプトとなるテキストデータ
{"type": "text", "text": "この画像には何が描かれていますか?"},
{
"type": "image_url",
# 入力プロンプトとなる画像データ
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
出力結果:かなり正確に描写できていることが分かる。

著名な物体(絵画)の名称の特定
入力画像:著名な絵画
入力テキスト:絵画の名前を求めるテキスト

response7 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像の絵画の名前はなんですか?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/0/08/Leonardo_da_Vinci_%281452-1519%29_-_The_Last_Supper_%281495-1498%29.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response7.choices[0])
出力結果:問題なく正解。

画像データ内の物体の位置を特定
入力画像:3DのCG画像
入力テキスト:指定の物体の位置を求めるテキスト

response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "画像内の球体の配置と割り振られている番号を教えてください。"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/4/4d/SolidShapes.png",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
出力結果:問題なく正解

著名な物体の特定
入力画像:都市の画像
入力テキスト:画像内での物体(建物)の配置と、建物の名称の特定を求めるテキスト

response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像の中で一番高い建物の配置とその建物の名前を教えてください。"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/b/b2/Skyscrapers_Shinjuku_2007_rev.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response2.choices[0])
出力結果:正確に特定できていることが分かる。

Face Detection
入力画像:人物の集合写真
入力テキスト:画像内の顔認識と人数のカウントを求めるテキスト

response5 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像には何人の人物が映っていますか?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/f/f7/Fumio_Kishida_Cabinet_20211004.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response5.choices[0])
出力結果:問題なく正解

性別の特定
入力画像:人物の集合写真
入力テキスト:性別の識別と人数のカウントを求めるテキスト
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像に女性は何人いますか?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/f/f7/Fumio_Kishida_Cabinet_20211004.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response6.choices[0])
出力結果:惜しいが、不正解。

画像データ内の個人の特定
入力画像:著名人物の画像
入力テキスト:人物の特定を求めるテキスト

response4 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像の人物は誰ですか?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/6/6f/Fumio_Kishida_20211005.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response4.choices[0])
出力結果:仕様としてサポートしていない模様。

画像データ内の物体の計算
入力画像:紙幣の画像
入力テキスト:画像内での物体の把握とそれに基づいた計算結果を求めるテキスト

# 画像データに移っているものの計算
response3 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像のお金は合計で幾らになりますか?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/6/64/USDnotes.png",
},
},
],
}
],
max_tokens=300,
)
print(response3.choices[0])
出力結果:問題なく正解

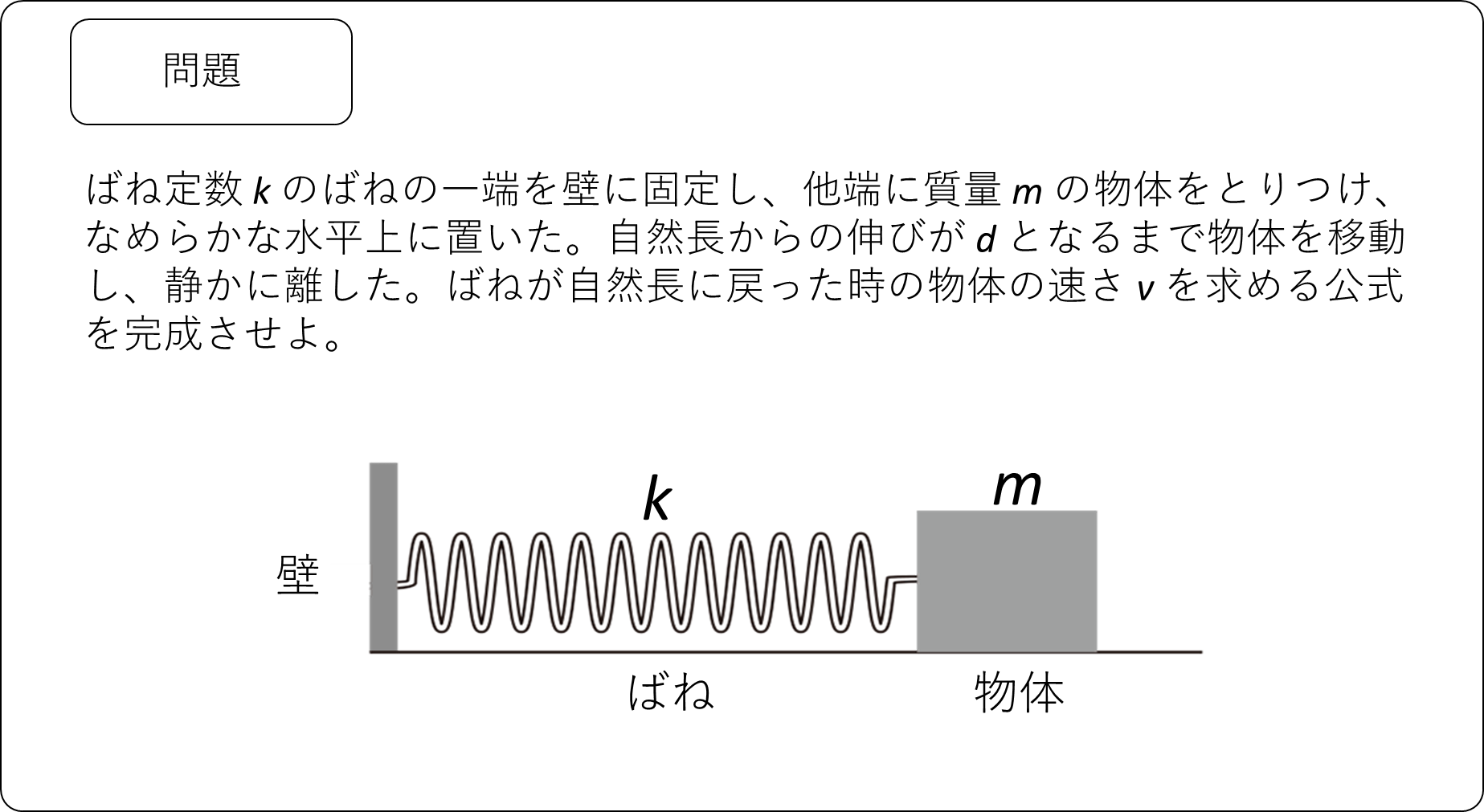
図と文章の問題の解法
入力画像:図と文章から構成される物理の問題
入力テキスト:問題の答えを求めるテキスト
response2 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "画像の中の問題を解いてください。"},
{
"type": "image_url",
"image_url": {
"url": "https://camo.qiitausercontent.com/6dc0c520b307dea35ce543dee8856ddf213f8975/68747470733a2f2f71696974612d696d6167652d73746f72652e73332e61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f302f3130393236302f65653665373536642d313661612d623638632d353730622d3661663533393861623062662e706e67",
},
},
],
}
],
max_tokens=1000,
)
print(response2.choices[0])
出力結果:正解

※出力では「v は ( \sqrt{\frac{k}{m}} d ) で与えられます。」となっており、これは下記の数式となり正解している。
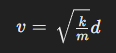
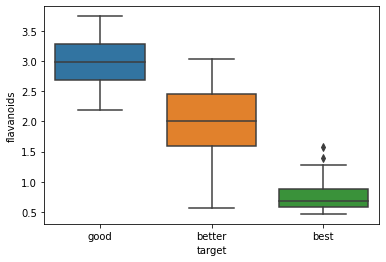
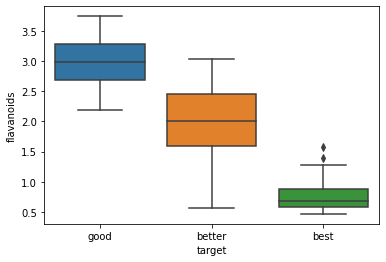
チャートの説明
入力画像:箱ひげ図の画像
入力テキスト:仮定の条件と、それに沿ったチャートの説明を求めるテキスト
response8 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像はワインの品質データを分析したボックスプロットです。この図を説明してください。"},
{
"type": "image_url",
"image_url": {
"url": "https://camo.qiitausercontent.com/e57f96c124065c58ec4059fb31aff4f8f423ec30/68747470733a2f2f71696974612d696d6167652d73746f72652e73332e61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f302f3130393236302f66336534373662642d323135372d643031662d313062342d3230373165663666383666622e706e67",
},
},
],
}
],
max_tokens=600,
)
print(response8.choices[0])
チャートの分析
入力画像:箱ひげ図の画像
入力テキスト:仮定の条件と、機械学習の分類問題として解きやすいかどうかの説明を求めるテキスト
response8 = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像はワインの品質データを分析したボックスプロットです。この図から分類問題として解きやすいかどうかを説明してください。"},
{
"type": "image_url",
"image_url": {
"url": "https://camo.qiitausercontent.com/e57f96c124065c58ec4059fb31aff4f8f423ec30/68747470733a2f2f71696974612d696d6167652d73746f72652e73332e61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f302f3130393236302f66336534373662642d323135372d643031662d313062342d3230373165663666383666622e706e67",
},
},
],
}
],
max_tokens=600,
)
print(response8.choices[0])
出力結果:正確に判断されている。特に「best」は他の2つのカテゴリと被りがほとんどありません。これは「best」のワインを分類する際に高い精度が得られることを示唆しています。」というくだり。

text-to-speechによる音声出力
OpenAIのモデルtts-1(text-to-speech)を使ったテキストデータから音声データへの変換
text = response.choices[0].message.content
response = client.audio.speech.create(
model='tts-1',
voice='alloy',
input=text
)
response.stream_to_file('./speech.mp3')
大規模言語モデル関連のその他の記事