※本記事はOracleの下記Meetup「Oracle Big Data Jam Session」で実施予定の内容です。
※本ハンズオンの内容は事前に下記セットアップが完了していることを前提にしていますのでご参加いただける方々は必ず下記ガイドの手順を実行ください。
※本記事のセミナー内容は以下の動画でも公開しておりますのでよろしければご参照ください。
本記事の対象者
本記事では下記のような方を対象にしています。
- これから機械学習を利用した開発をしていきたい方
- 機械学習のトレンド技術を知りたい方
- なるべく初歩的な内容から学習したい方
AutoMLライブラリのアプローチ
前回のハンズオンセミナーではAutoMLにより、機械学習のワークフローの中で何が自動化されるのかをはじめに説明しました。Auto Sklearnだけではなく、現在人気のAutoMLのライブラリの自動化対象は酷似しています。実際に、いくつかのライブラリを実際に使ってみると、その酷似の構造が見て取れます。
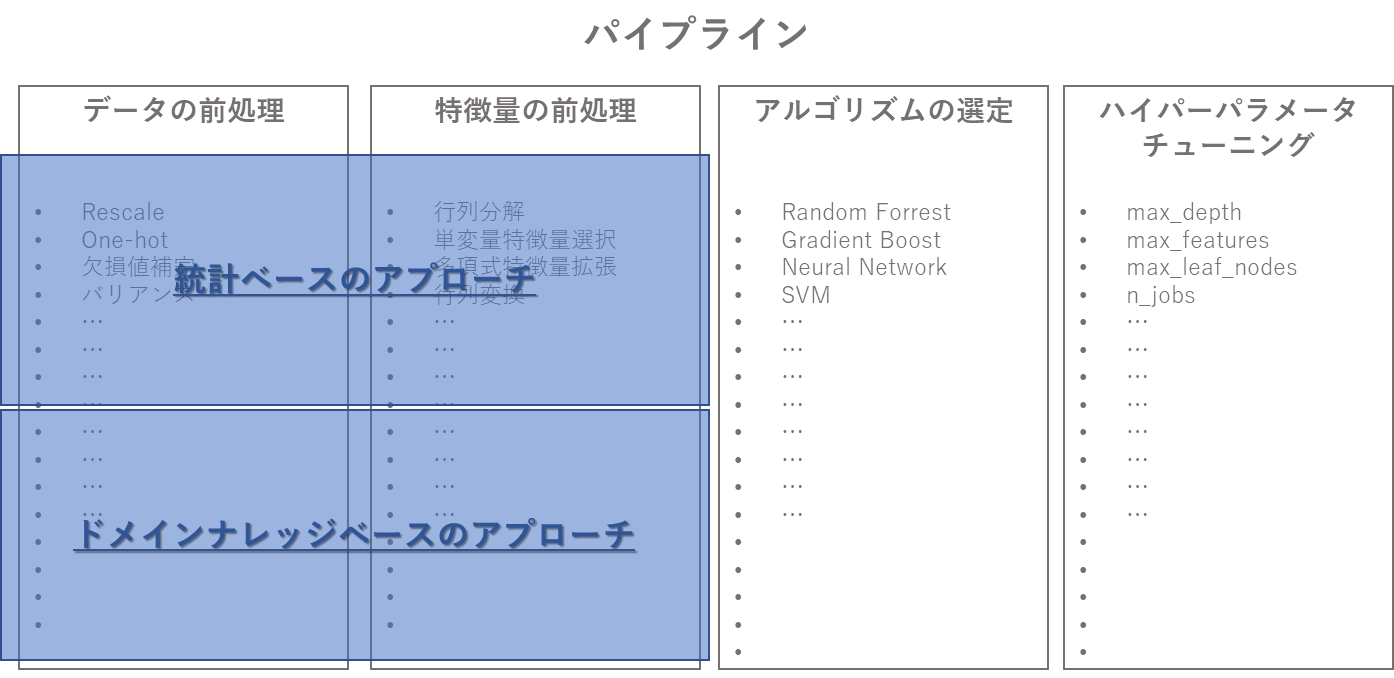
どのライブラリも自動化のターゲットを「データの前処理」、「特徴量の前処理」、「アルゴリズムの選定」、「ハイパーパラメータの選定」の4つのカテゴリ(この組み合わせをパイプラインと呼ぶ)に絞っている点は皆同じです。
そして、これら前処理の手法は大きく「統計ベースのアプローチ」と「ドメインナレッジベースのアプローチ」に分かれます。統計ベースのアプローチは学習データの内容によって、おおよそ定型的なものがありますので、ライブラリとして実装しやすく、現在主流のAutoMLライブラリはこのアプローチを完全自動で処理してくれます。
本来、これらの統計ベースのアプローチは難解な統計知識をもってコードを書く部分ですので、これは大幅な工数の削減ということになりますし、実際、予測モデルの精度にも大きく影響します。
一方、ドメインナレッジベースのアプローチとは、業務知識であったり、特定分野の専門家が経験上知っている事象などの知識をベースに処理を実行することになり、これは分析シナリオによって千差万別となるため、当然ライブラリに実装することが難しく人間が対処しなくてはいけない領域です。
一部の業種に特化したアプリケーションやSaaSサービスではこの部分が多少自動化されていることはありますが、オープンソースのAutoMLライブラリはまだまだ統計アプローチベースの自動化が主流です。
このように大抵のAutoMLライブラリは同じような自動化なのに、なぜ、次から次へと新しいAutoMLライブラリがリリースされるのでしょうか。その違いは何なのかが気になりますよね。
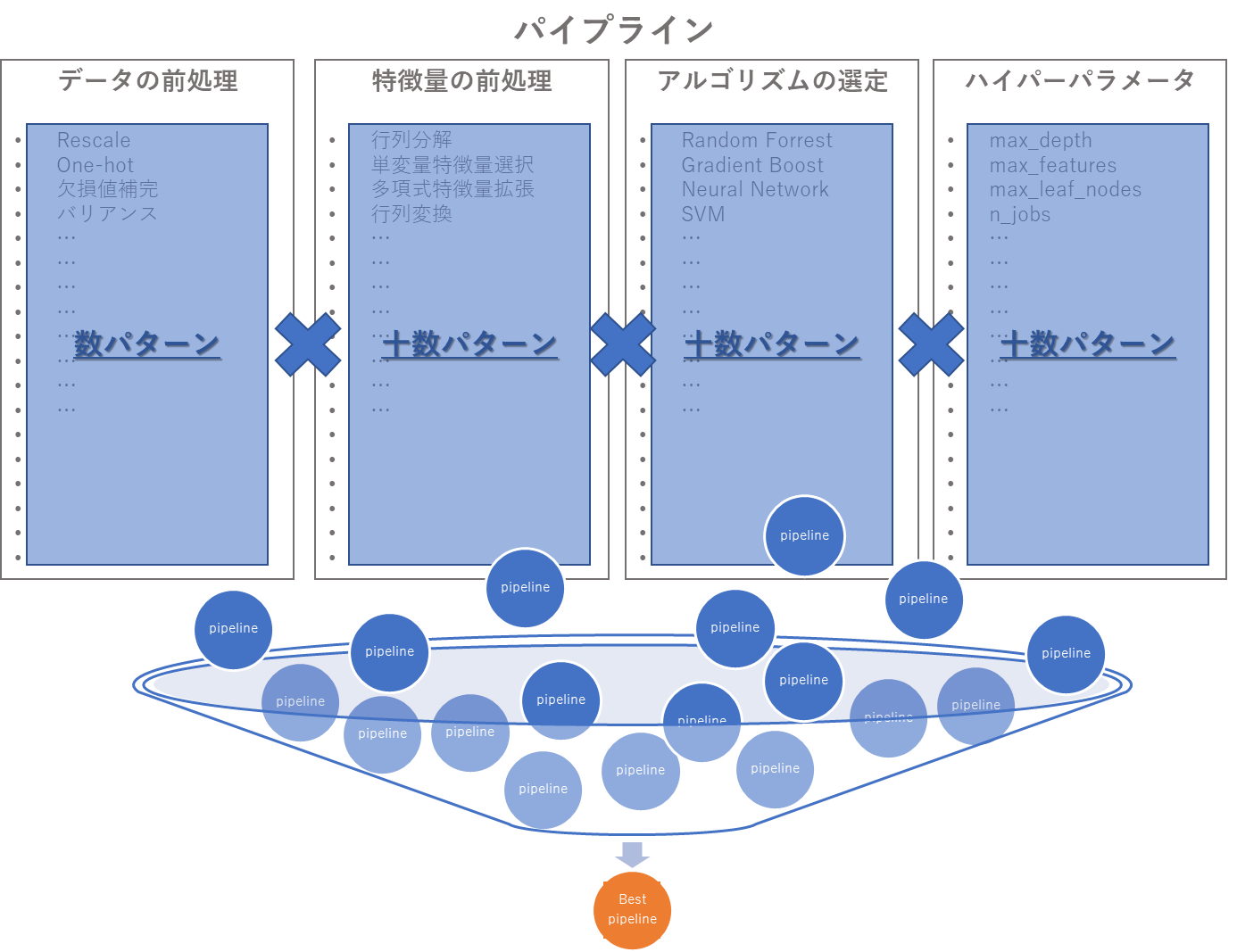
「ベストな予測モデルを作る」という作業は、モデルの精度が一番高くなる「パイプライン」を見つけるということです。つまり、「データの前処理」、「特徴量の前処理」、「アルゴリズムの選定」、「ハイパーパラメータの選定」の組み合わせを全て計算し、そこから一番精度メトリックの値がよいパイプラインを選別すれば、論理的にはそれがベストなモデルということになります。
つまり、機械学習の中で、現在のあらゆるAutoMLライブラリがフォーカスしている点は、「いかに沢山のパターンのパイプラインを生成し、その中から、いかに効率的にベストなパイプラインを見つけるか」ということになります。「たくさんの宝くじを買えば、当たりのくじを引く確率が高くなるから」という理屈です。
この命題に対し、現在人気のAutoMLライブラリはそれぞれ実にユニークな手法を実装しています。例えば、前回ご紹介した Auto Sklearnではベイジアン最適化とメタ学習と呼ばれる古来からある手法を組み合わせてこの命題に対処しています。古典機械学習の大御所であるscikit-learnの名を冠するだけあって、まさに正統派という印象です。(※前回記事と、説明の動画を下記に掲載してありますので、ご興味のある方は参照されてください。)
そして、今回ご紹介するTPOTは「遺伝的アルゴリズム」と呼ばれる手法でこの大命題に対処しています。
遺伝的アルゴリズム・遺伝的プログラミング
遺伝的アルゴリズム(GA : Genetic Algorithms)は、解探索手法の分野の先駆者であるミシガン大学教授の John Henry Holland(ジョン・ヘンリー・ホランド)氏により提唱された手法です。本手法はその呼称通り、生物の進化の過程で見られる「遺伝子の変化」に着想を得、それを模倣する形で構築されたアルゴリズムです。
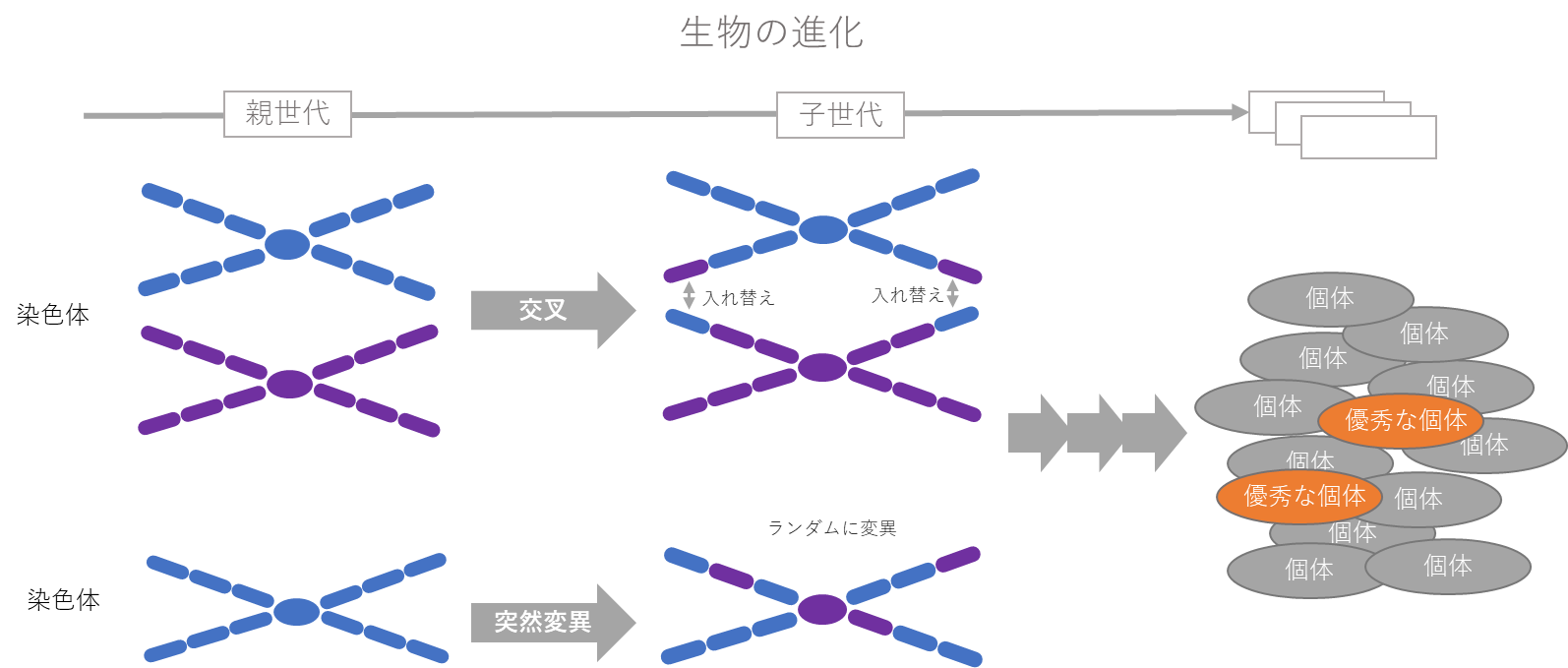
生物の進化の過程では、ペアの染色体の一部が入れ替わったり(交叉)、染色体の一部が変異(突然変異)することが起き、これが何世代にもわたり、繰り返されうちに、優秀な個体に進化してゆくという理論が進化論というものだそうです。生物学ではこの「優秀な個体」とは、「環境に適応して進化した個体」ということになりますが、機械学習に応用した場合は、「より精度の高いパイプライン」ということになります。
そして、この遺伝的アルゴリズムを応用した遺伝的プログラミングと呼ばれる考え方があります。これも至ってシンプルです。
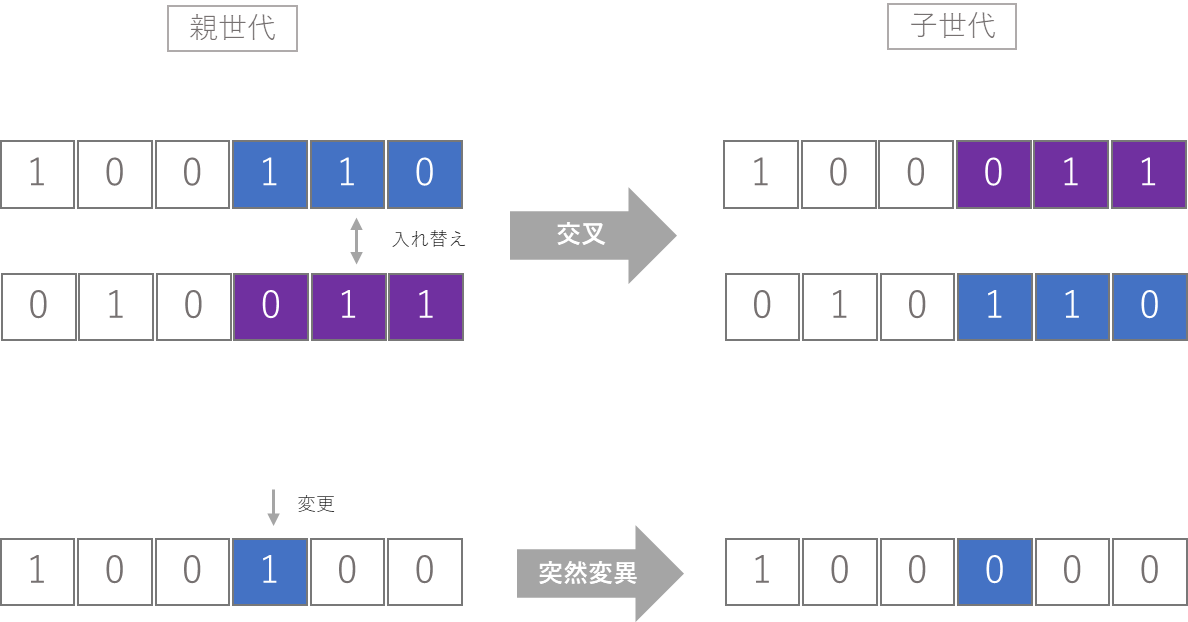
上図のように、遺伝的アルゴリズムの「交叉」や「突然変異」の構造を模倣するように、元のデータの一部を入れ替えたり(交叉に相当)、一部を変更(突然変異に相当)するだけです。
この遺伝的プログラミングがTPOTでどのように使われているかを理解するには、先に、TPOTのパイプライン構造の特殊性を理解する必要があります。
TPOTのパイプライン
下図はTPOTの開発サイトから拝借したパイプライン図に上述した各フローをおぼろげに投影したものです。
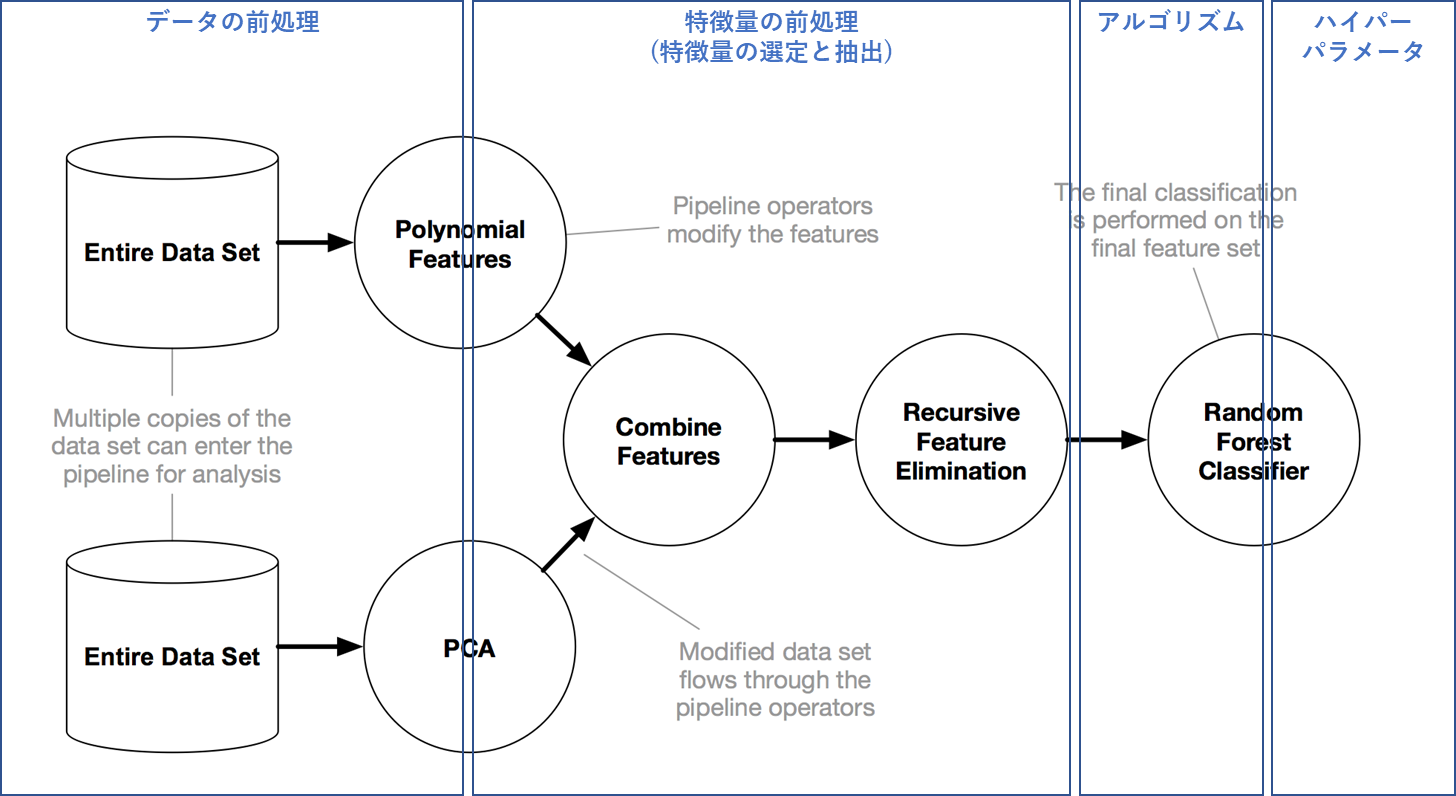
An example TPOT pipeline
出展 : http://epistasislab.github.io/tpot/
この図は、TPOTが大量に生成するパイプラインのパターンの一例です。(なぜ一例かというと、上述したように機械学習ではベストなパイプラインを見つけるために、大量のパイプラインを作るからです。このような構図のパイプラインを多数生成します。)
この一例を説明すると、
- 一番左の円筒形がデータセットとなり、円の部分はパイプラインの中で行っている各処理でTPOTではこれをオペレーターと呼んでいます。
- 元のデータセットのコピーを複数作成し、上段ではPolynomial Features(多項式特徴量抽出処理)と呼ばれる特徴量の前処理を実行し、特徴量を新たに抽出(特徴量を増やす)しています。
- そして、下段では複製したデータセットをPCA(主成分分析)にかけ、こちらも特徴量の抽出を行っています。
- 次にこの二つの前処理で抽出された特徴量を結合し、作成された特徴量から不要な特徴量を削除し(ラッパー法)、学習にかける最終的な特徴量のデータセットを作ります。
- 最後に、アルゴリズム(この例ではRandom Forrest)を学習させ最終的な分類の予測モデルを作っています。
ここで出てくる、Polynomial Features(多項式特徴量抽出処理)やPCA(主成分分析)というキーワードは本記事では大して重要ではありません。そこ詳しく!という方は上述したAuto sklearnの記事に簡単ではありますが説明していますのでご参照ください。ここで大事なことは、このTPOTが作るパイプラインの特殊性です。TPOTのパイプラインの非常に特徴的な点は、この図のように木構造のパイプラインになっていることです。TPOT以外の一般的なパイプラインは各オペレータを直列的に組み合わせて作りますが、TPOTではこのような木構造パイプラインの探索が可能でることが大きな特徴であり、精度が高いといわれる所以でもあります。
複数の前処理を木構造に組み合わせるという仕組みにより、よりバラエティに富んだ多数のパターンのパイプラインを扱えるようになりますから、その中には、より良いパイプラインが眠っている可能性が高くなるというわけです。(単純な直列タイプよりも、多くのパターンのパイプラインを生成できるということです。)
このような複雑なパイプラインを多数作るということは、上述した可能性を広げると同時に、パイプラインの探索空間も大幅に広げてしまうことになります。(上述した宝くじの例になぞらえると、たくさん買えば買うほど当たりくじを引く確率はあがるが、お金がかかるという感じです。)そのため、実際の学習時には、パイプラインの処理時間に上限を設定したり、パイプラインの構造を固定したりと、いろいろなパラメータを設定することができるようになっています。
TPOTにおける遺伝的プログラミングの適用
TPOTではこのような多数の複雑なパイプラインをどのように作り出すと思いますか?そこで出てくるのが、まさに遺伝的アルゴリズムです。遺伝的アルゴリズムの「交叉」や「突然変異」の考え方をこのパイプライン内のオペレーターの組み合わせに応用し、バラエティに富んだパイプラインを多数作り上げます。
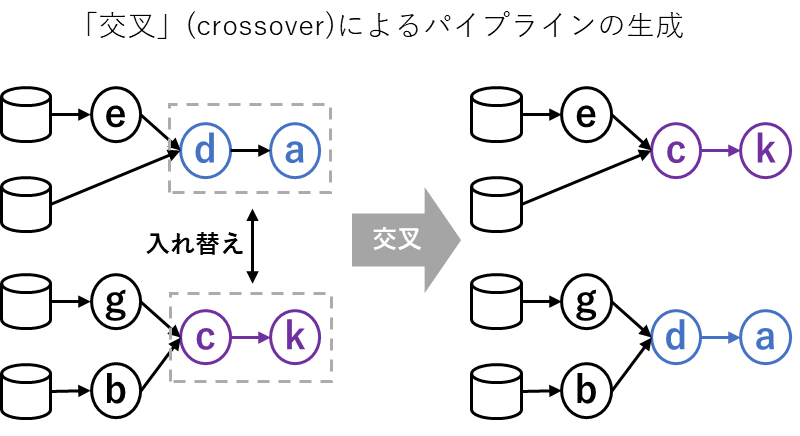
「交叉」の場合は上図のように、元となるパイプラインの一部を入れ替えた新しいパイプランを作り出します。
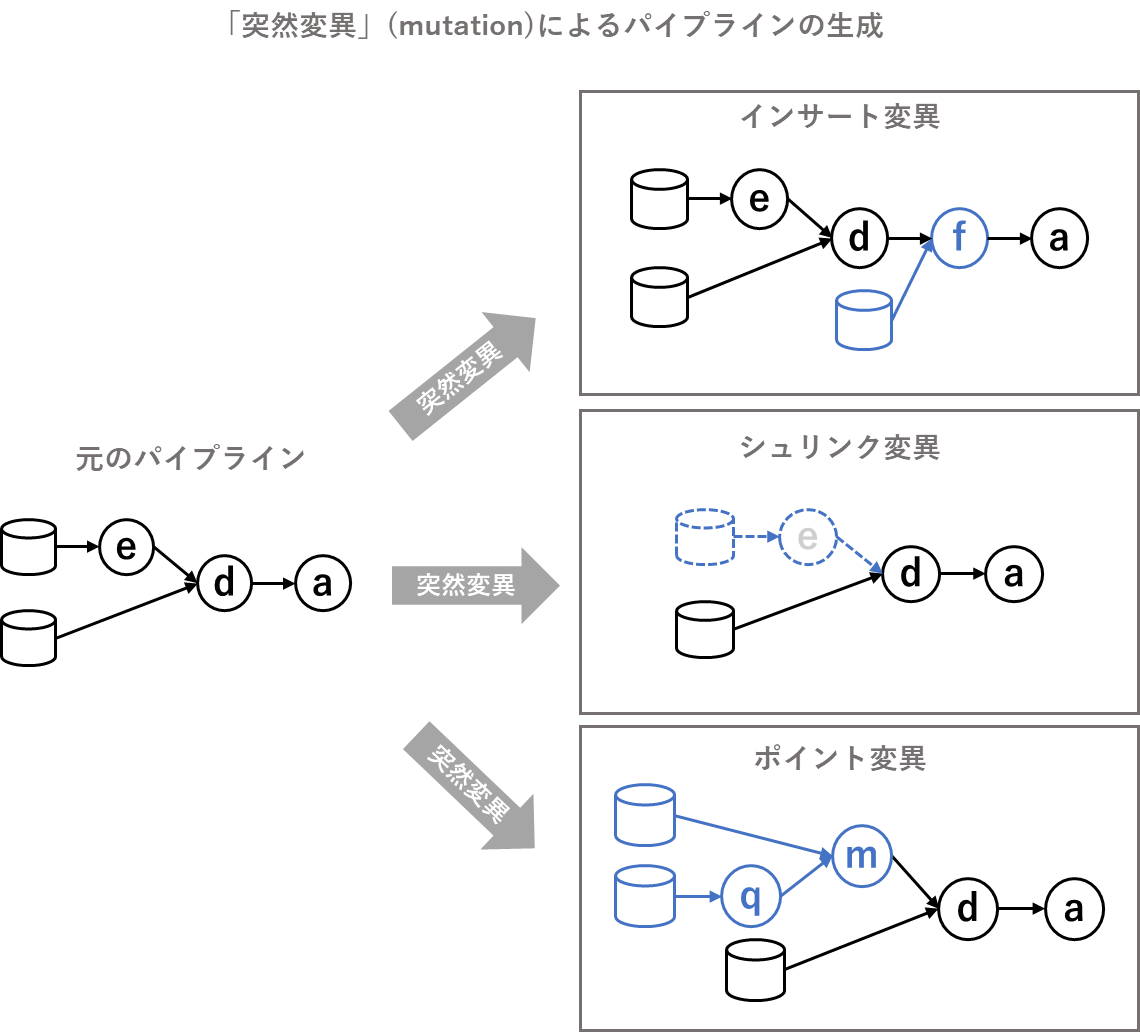
「突然変異」には主に「インサート変異」、「ポイント変異」、「シュリンク変異」という3つのパターンがあります。
- 「インサート変異」は元のパイプランの任意の部分にランダムな別パターンのパイプラインを入れ込み、新しいパイプラインを作り出します。
- 「シュリンク変異」は元のパイプラインの一部を削除し、新しいパイプラインを作り出します。
- 「ポイント変異」は元のパイプラインの一部を、ランダムな別パターンのパイプラインに入れ替え、新しいパイプラインを作り出します。
これら「交叉(crossover)」、「インサート変異(Insert Mutation)」、「ポイント変異(Point Mutation)」、「シュリンク変異(Shrink Mutation」がTPOTでどのように使われているかを、全体の処理フローの観点から見ていきましょう。
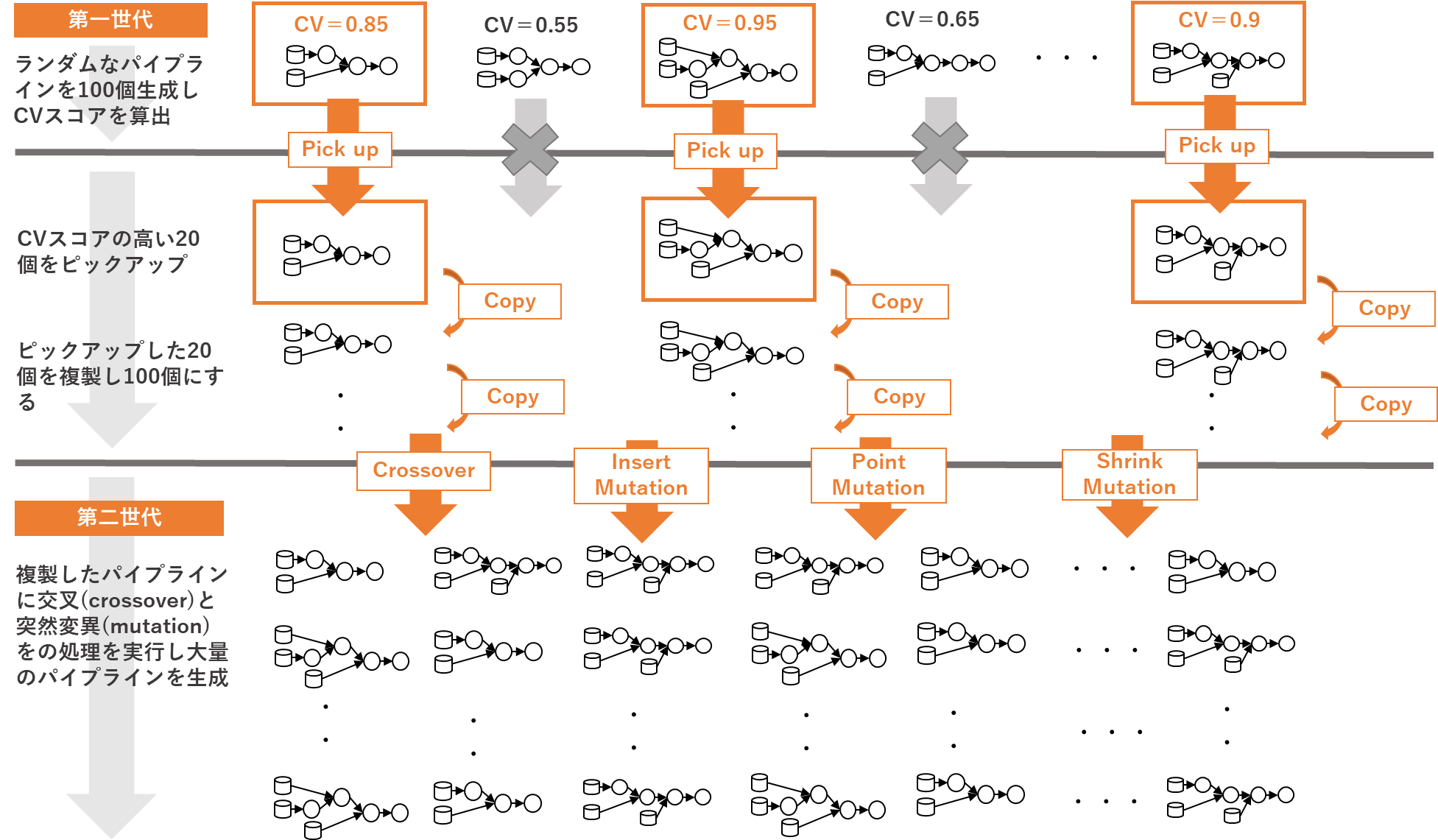
-
TPOTでは、まずランダムにオペレータを組み合わせた100パターンの第一世代となるパイプラインを生成し、各パイプラインの交差検定(cross validation)スコアを計算します。
-
次に、この100個の中から、CVスコアの高いパイプラインを20個ピックアップし、更に、その20個を複製し再び100個のパイプラインにします。つまり、100個の中から、第一世代レベルで優秀な個体(パイプライン)を20個選抜し、複製した状態ということです。
-
次に、この100個のパイプラインに「交叉(crossover)」、「インサート変異(Insert Mutation)」、「ポイント変異(Point Mutation)」、「シュリンク変異(Shrink Mutation」の処理を施し、第二世代となる100個のパイプラインを新たに生成します。
-
次に、この第二世代の100個のパイプラインからCVスコアの高い20個を選抜し、次の世代のパイプラインを生成するということを100世代にまで繰り返します。
世代が進むたびに、精度が向上した多数のパイプラインから更にCVスコアの高いものを選抜する、ということを強制的に100世代繰り返すわけですから、最後に選ばれるパイプラインはあまたの競合を勝ち抜いてきた選りすぐりというわけです。
この図にある、世代数やパイプライン数はTPOTのデフォルト値を示しており、TPOTの学習器を定義する際に、パラメータで設定変更ができます。
交差検定(cross validation)とは、モデルの汎化性能を評価する手法です。ここではざっくりと「そのパイプラインがどの程度良いものなのかを計算する手法」と考えていただいて概ね問題ありません。詳細に知りたい方は下記のwikipediaをご参照ください。
wikipedia : 交差検定
https://ja.wikipedia.org/wiki/%E4%BA%A4%E5%B7%AE%E6%A4%9C%E8%A8%BC
そして、ここまで概説した処理を、TPOT は実質下記の2行で実行してれくれるとうシンプルさが非常にうれしいところです。まさにAutomated Machine Learningですね。
# 学習器の定義
tpot_model = TPOTClassifier()
# 学習処理の実行
tpot_model.fit(X_train, y_train)
サンプルコード
# 必要なライブラリのインポート
from tpot import TPOTClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
import numpy as np
import pandas as pd
# データのロード、説明変数、目的変数の定義
data_cancer = load_breast_cancer(as_frame=True)
X = data_cancer.data
y = data_cancer.target
# 各変数の確認
X
y
# 目的変数のデータの偏りを確認
print(np.count_nonzero(y == 1))
print(np.count_nonzero(y == 0))
# ロードしたデータを学習用と評価用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=42)
# 分割されたデータのレコード数を確認
print(len(X_train))
print(len(X_test))
# TPOTの分類器と、パラメータを定義
# scorering : Cross Validationに使う指標
# generation : 世代数
# population_size : 各世代で生成するパイプライン数
# verbosity : 学習中のステイタスの表示(0 - 3までの4段階で数値が大きいほど詳細)
# n_jobs : 学習処理の並列度(-1の指定により、全てのコアを利用する)
model_tpot = TPOTClassifier(scoring='f1',
generations=3,
population_size=50,
verbosity=2,
n_jobs=-1)
# 学習処理の実行
model_tpot.fit(X_train, y_train)
# 最終的に採用されたベストなパイプラインの確認
model_tpot.fitted_pipeline_
# 学習途中のパイプラインの確認
model_tpot.evaluated_individuals_
# 構築したモデルを評価用データで評価(メトリックはf1スコア)
y_pred = model_tpot.predict(X_test)
f1_score(y_true=y_test, y_pred=y_pred)
# 評価データの予測結果と正解ラベルを確認
pd.DataFrame(data={'y_pred':y_pred,'y_test':y_test})
# 混同マトリクス
confusion_matrix(y_pred=y_pred,y_true=y_test)
さいごに
多数の個体に、何世代にも渡って「交叉」、「突然変異」が加わり、厳しい自然淘汰の中で、環境に適応した優秀な個体に進化するという進化論のしくみを忠実に再現した非常に興味深いライブラリだと思います。このようなユニークな仕組みをもったTPOTは、精度も高く、コーディングもかなりシンプルなことから、以前から大変な人気のAutoMLライブラリです。ですが、いかにライブラリが優れていたとしても、機械学習で最も重要なものはデータです。こんな素晴らしいツールでも、学習データが分析シナリオに沿っていなければ宝の持ち腐れだということを改めて認識させてくれるライブラリだと感じます。