本記事では下記ハンズオンセミナーで利用するオラクルの機械学習サービス Data Science Service の初期セットアップについてご紹介します。ご参加いただく方は事前のセットアップをよろしくお願いいたします。
本ハンズオンセミナーにご登録いただいた皆様には、すでにフリートライアルのご案内が届いていると思いますのでそちらの内容にそってアカウントを作成ください。
オラクル・クラウドへのログイン
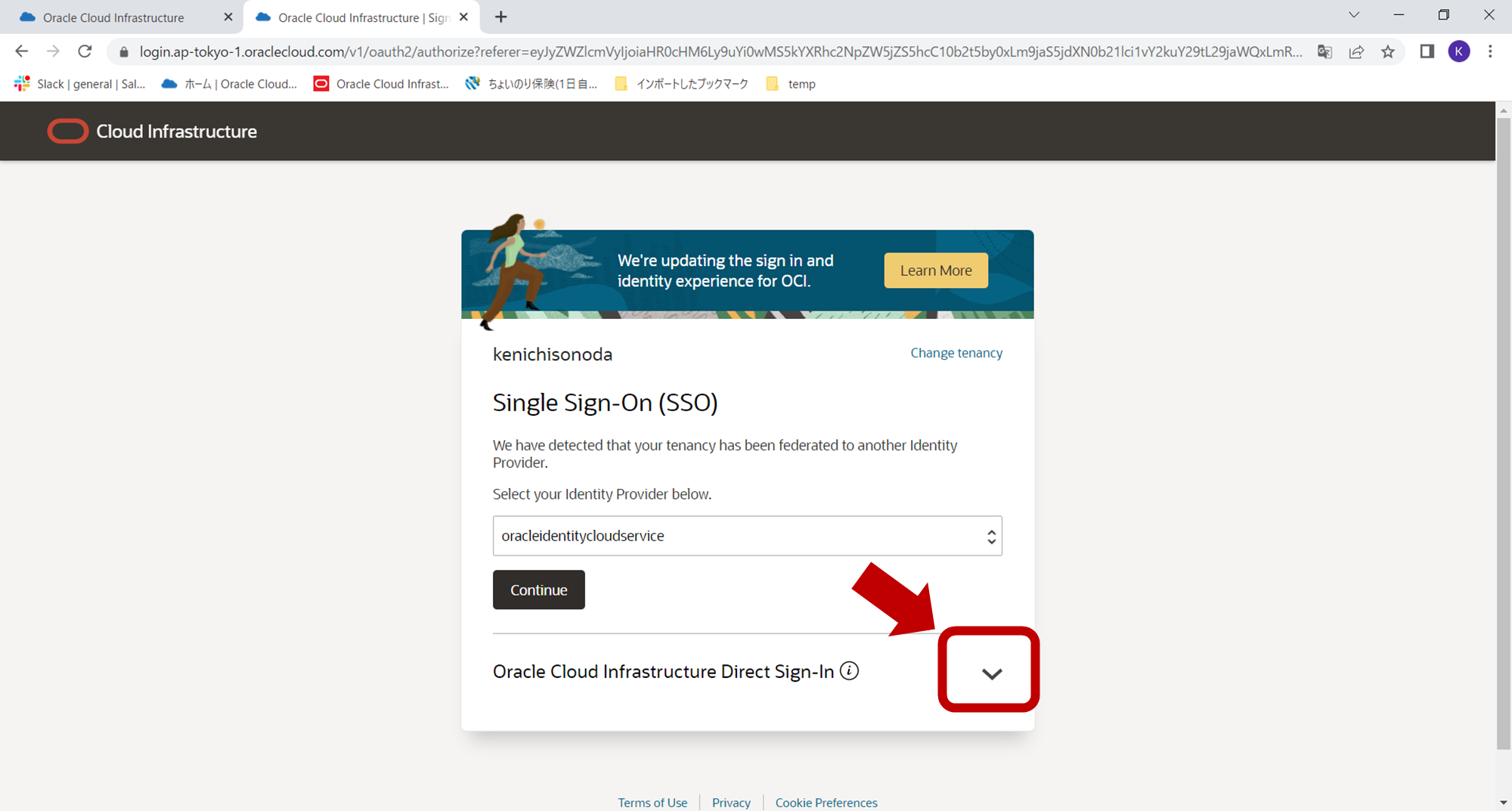
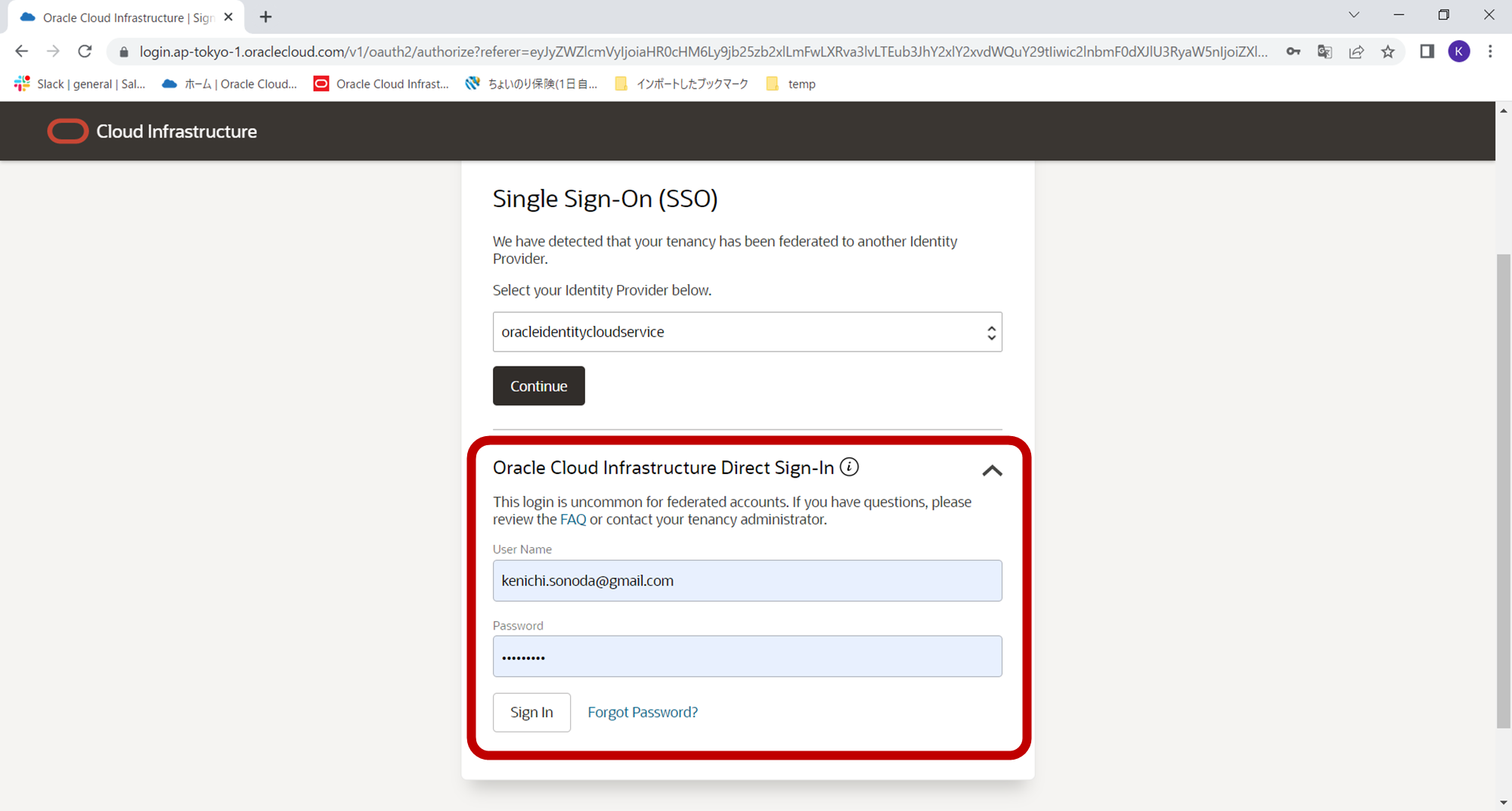
アカウント作成後、オラクルクラウドにログインする際には、下記のようにテナント名を入力後、「Oracle Cloud Infrastructure Direct Sign-Inのほうからログインをお願いいたします。
作成したアカウントでオラクルクラウドにログインすると下記のトップページが表示されます。
日本語がいいという方は右上の地球儀のマークをクリックして、メニューから日本語を選択してください。
下記のように日本語表記になります。
コンパートメントの作成
オラクルクラウドには、契約したテナントの中を、複数の環境に分割するためのコンパートメントと呼んでいる機能があります。例えば、2つのコンパートメントを作ると、コンパートメントAはコンパートメントBの設定や性能の影響を受けない全く別の環境となります。このコンパートメントの機能を使って、テナントの中に複数の環境(例えば、開発用にコンパートメントA、本番用にコンパートメントB)を作り、便利に運用してゆくことができます。デフォルトではルートコンパートメントが一つある状態ですので、追加でもう一つコンパートメントを作り、それをハンズオン環境としたいと思います。
トップ画面左上のメニューボタンをクリックします。
ここにオラクルクラウドのすべてのサービスがカテゴリに分けられてリストされており、ここから「アイデンティティとセキュリティ」を選択し、このカテゴリの中から「コンパートメント」をクリックします。
コンパートメントの画面に遷移しますので、そこから「コンパートメントの作成」ボタンをクリックします。
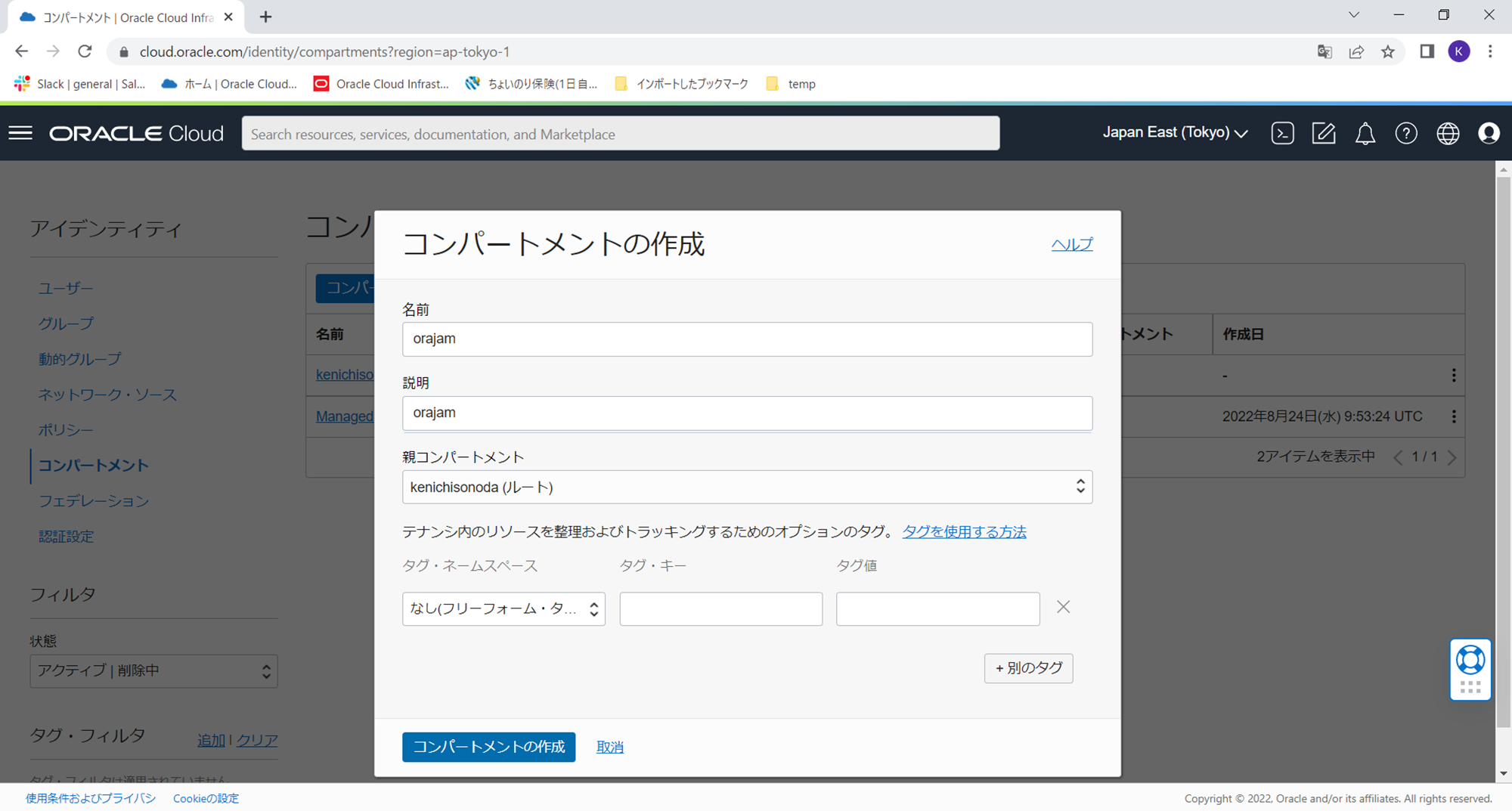
コンパートメントの作成画面に必要事項を入力し、「コンパートメントの作成」ボタンをクリックします。
- 名前:任意ですが、本ハンズオンセッションではorajamと入れていただけるとよいかと思います。
- 説明:任意ですが、本ハンズオンセッションではorajamと入れていただけるとよいかと思います。
- 親コンパートメント:ルート
これでコンパートメント作成は完了です。作成したコンパートメントがリストにあることを確認します。
Data Science Serviceのインスタンス作成
作成したコンパートメントに、Data Science Serviceのインスタンスを作成します。Data Science Serviceでは最初にプロジェクトと呼んでいる論理的なエンティティを作成します。これは文字通り、プロジェクト単位でData Science Serviceでの設定を纏めておく器のようなものです。
先ほどと同じように、トップ画面の左上のメニューボタンをクリックします。
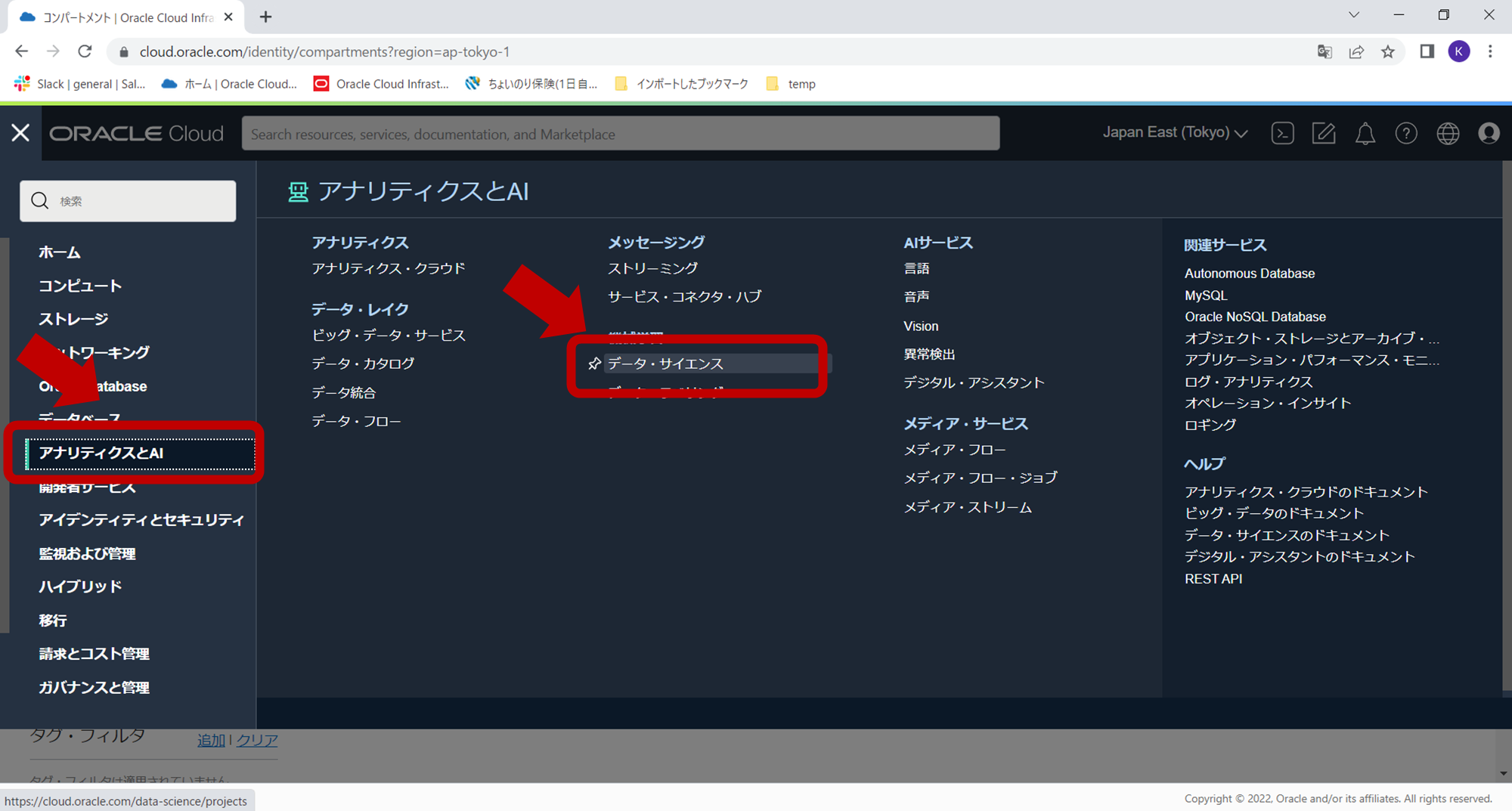
サービスのカテゴリから「アナリティクスとAI」をクリックし、「データ・サイエンス」をクリックします。
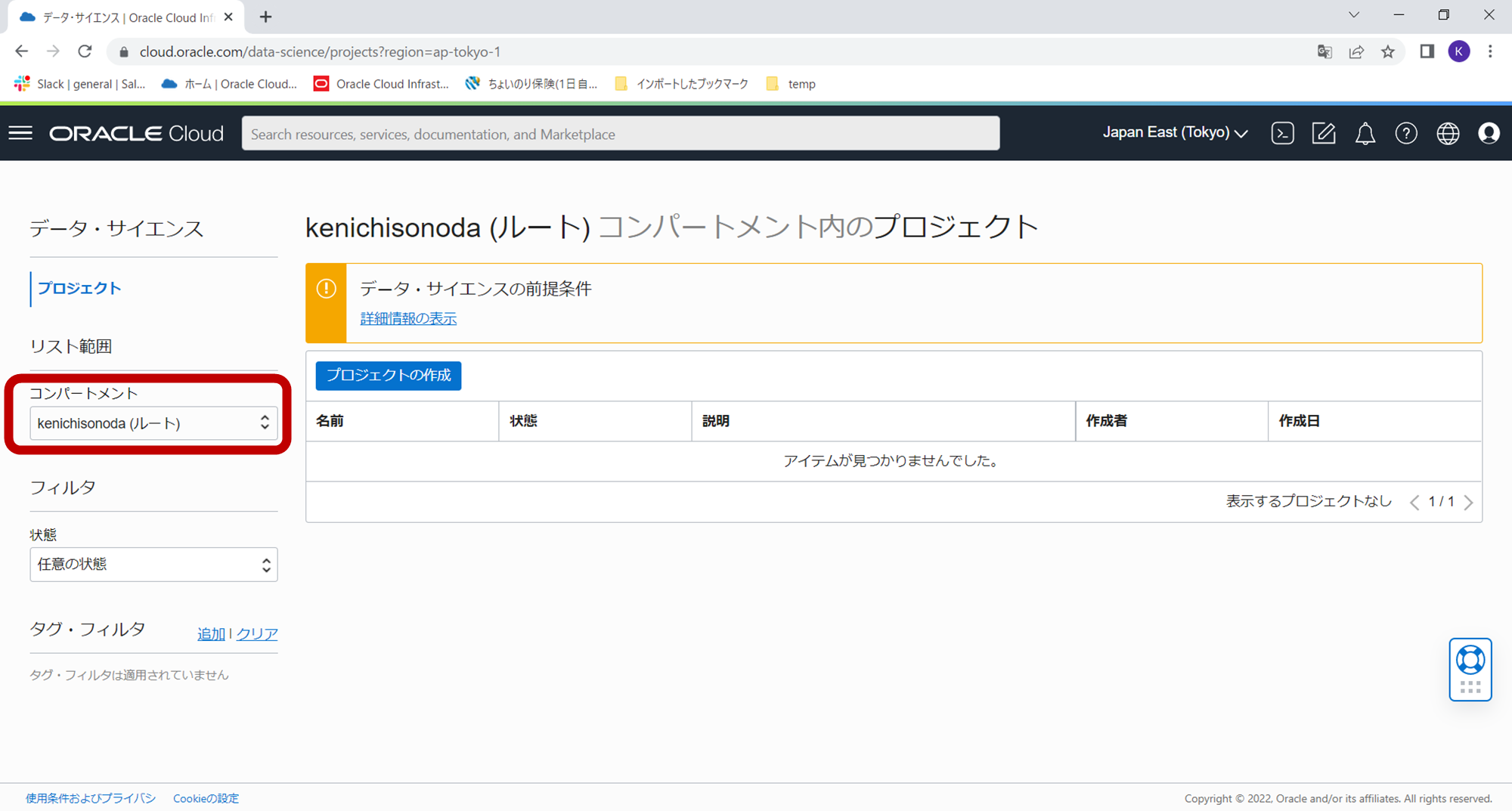
下記のようにData Science Serviceのトップ画面に遷移しますので、Data Scienceをプロビジョニングします。プロビジョニング先は作成済のコンパートメント(今回はorajam)です。左側の「コンパートメント」のプルダウン部分をクリックしてください。
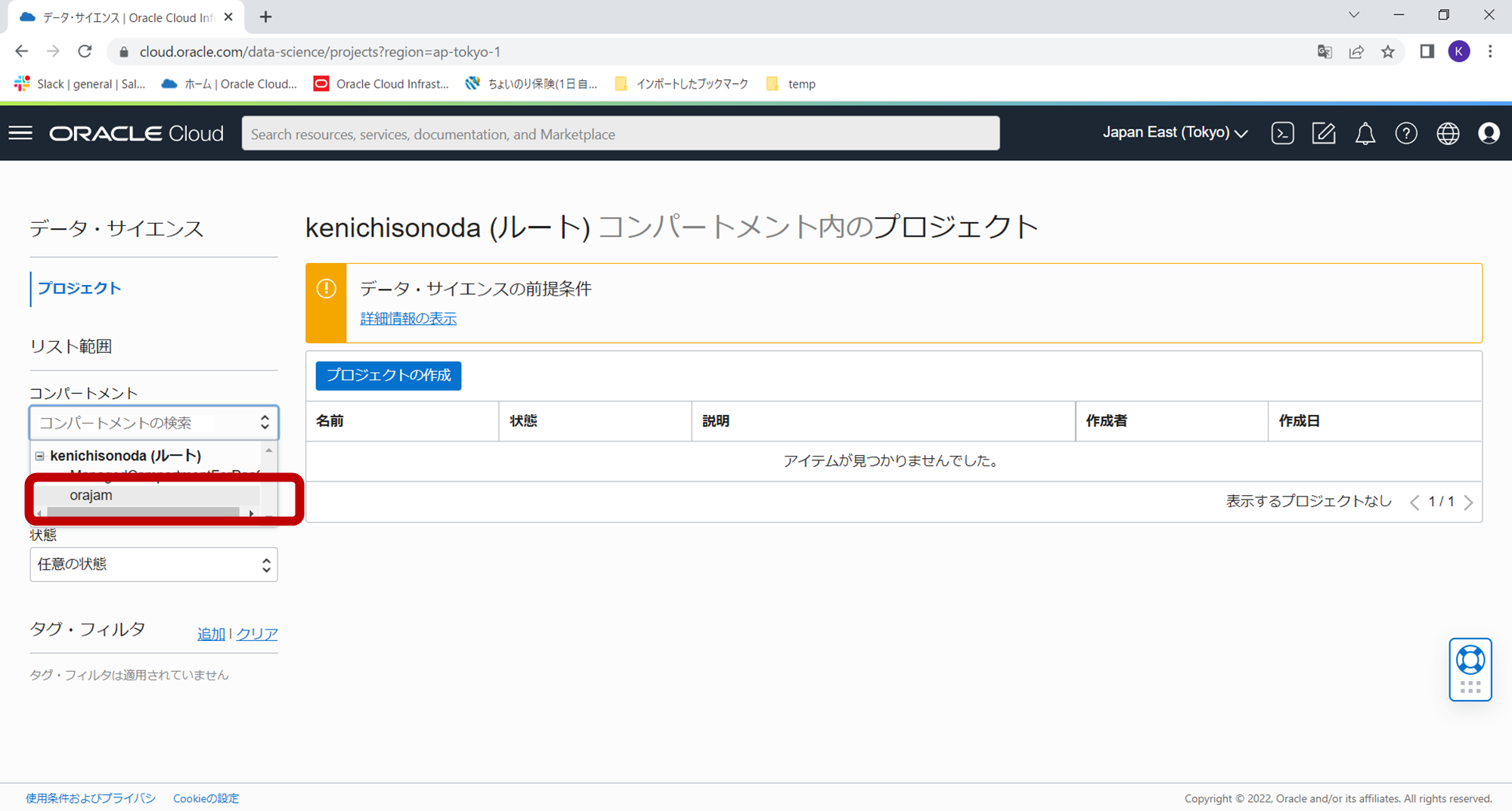
下記のようにプルダウンから作成済のコンパートメントをクリックし、選択します。
コンパートメントが設定できたことを確認し、「プロジェクト作成」ボタンをクリックします。
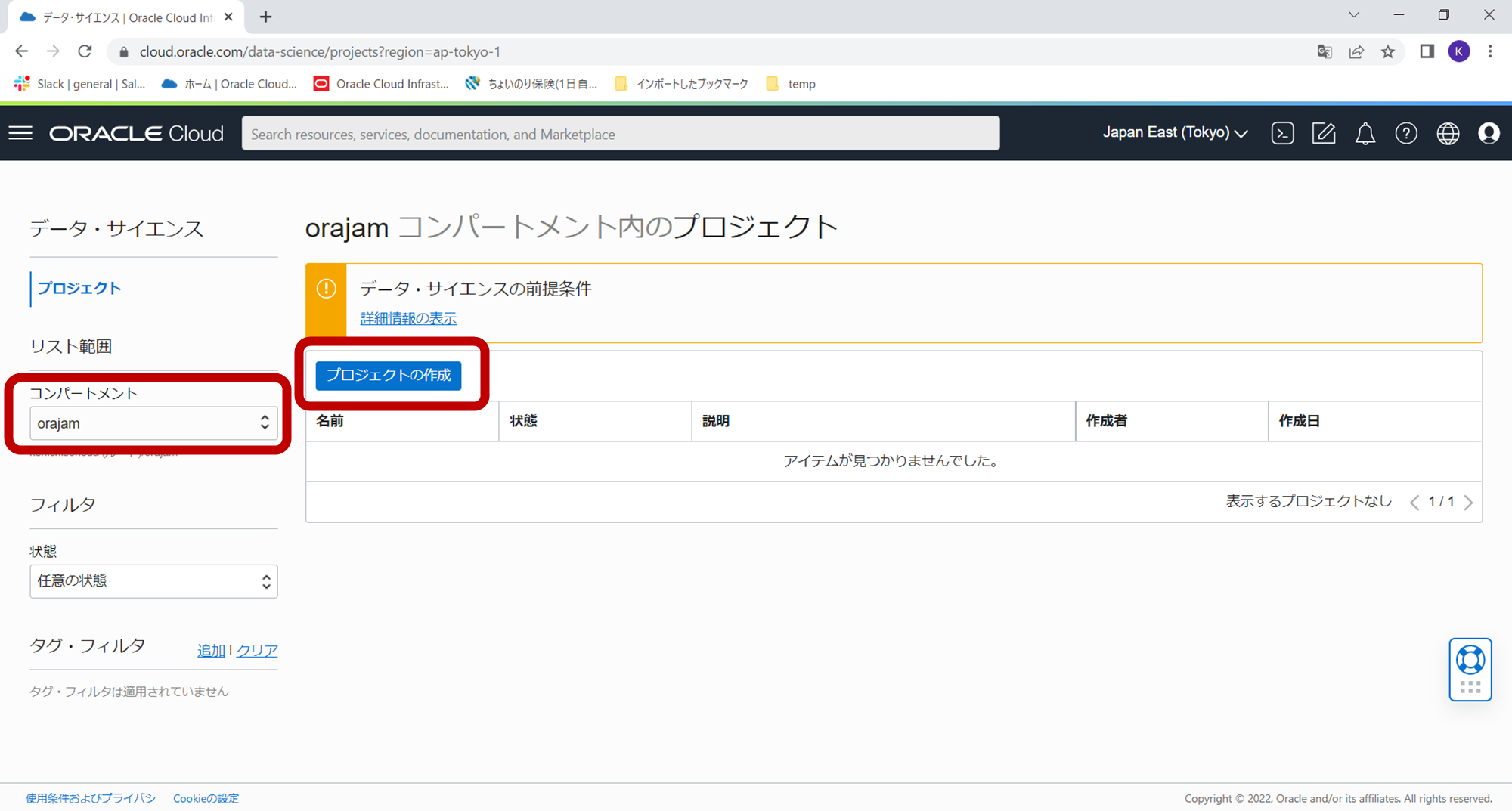
プロジェクトの作成ウィザードが表示されますので、必要な情報を入力して作成ボタンをクリックします。
- コンパートメント:作成済の任意のコンパートメント(今回の場合はorajam)
- 名前:任意(今回の場合はhandson01)
- 説明:任意
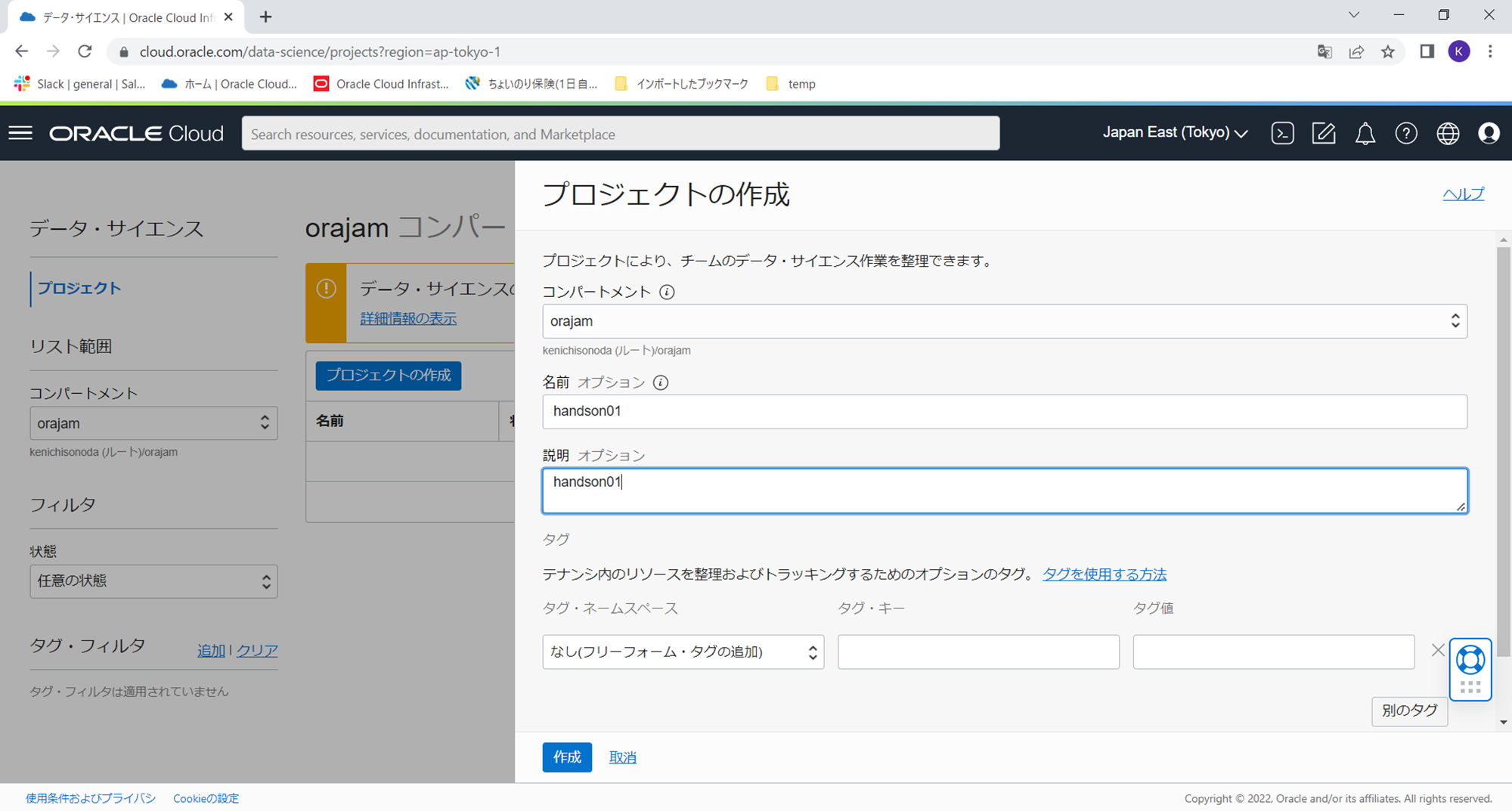
次に、作成したプロジェクトの中にノートブック・セッションを作ります。このノートブック・セッションは機械学習開発環境のためのコンピューティングリソースそのものとなります。作成したプロジェクトのトップ画面の「ノートブック・セッションの作成」ボタンをクリックします。
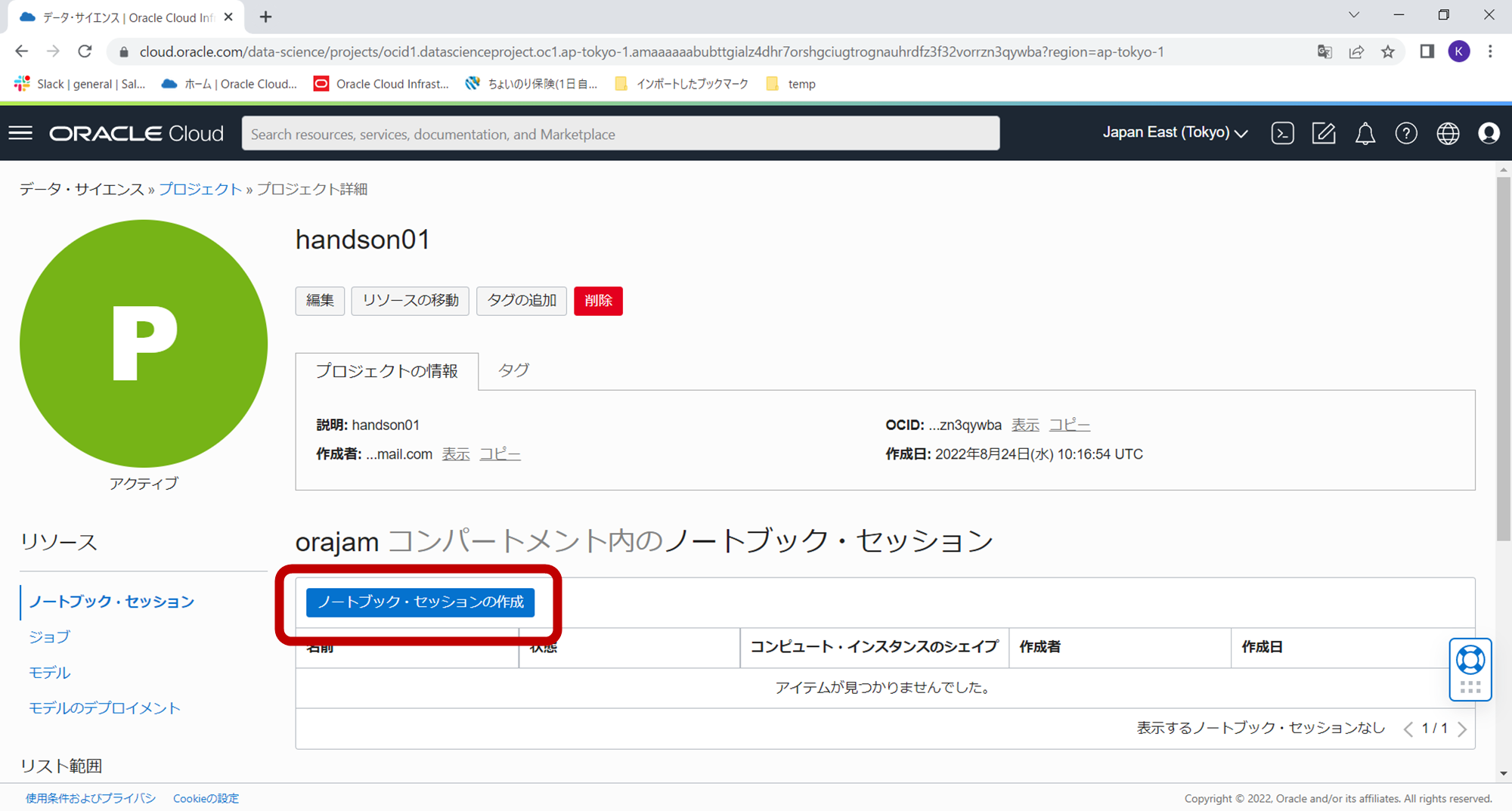
必要な情報を入力します。とりあえずは下記の項目だけを入力し、その他の項目はデフォルト値で作成ボタンをクリックします。
- コンパートメント:作成済のコンパートメント(今回の場合orajam)
- 名前:任意の名前(今回の場合dev01)
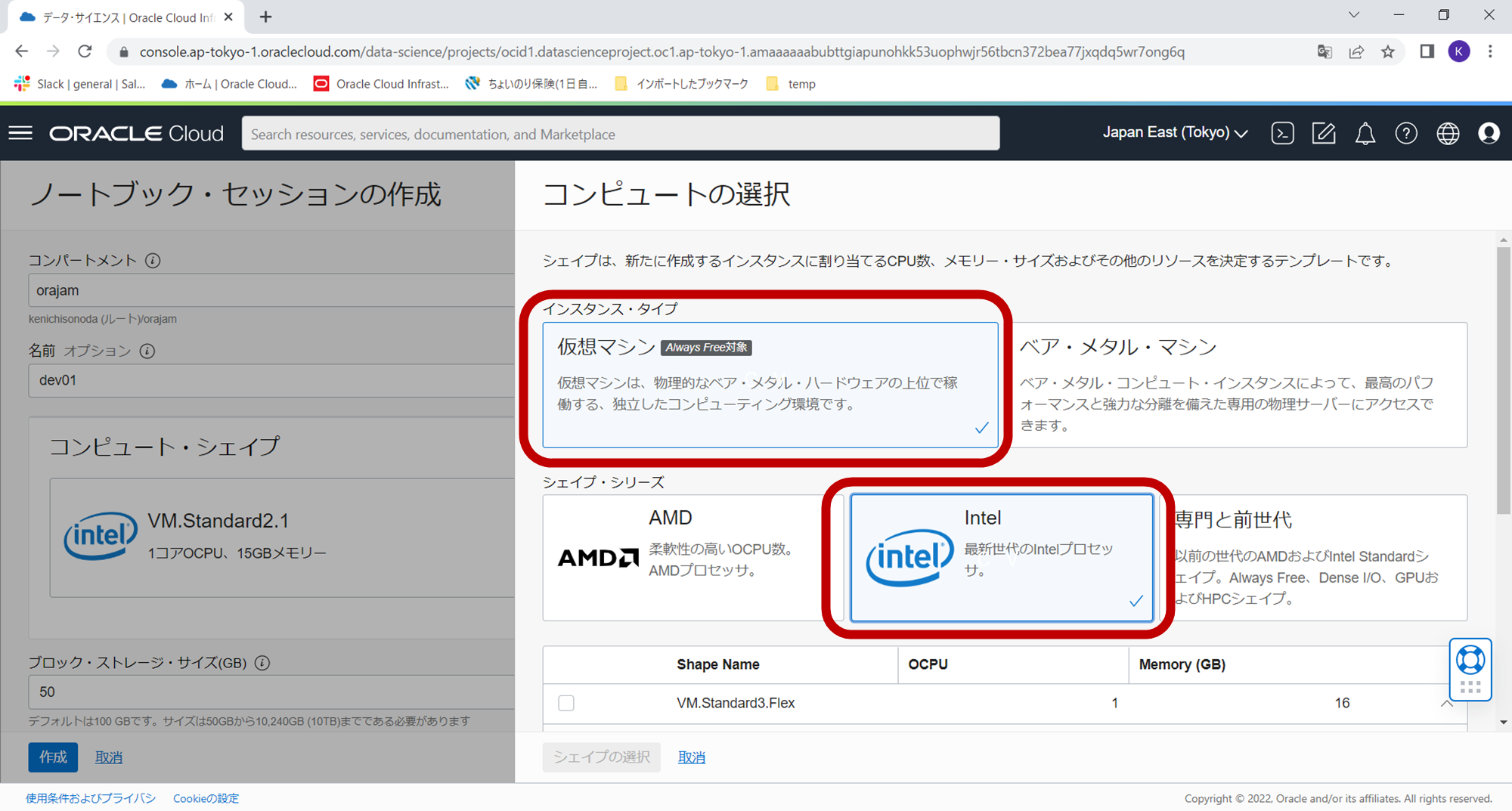
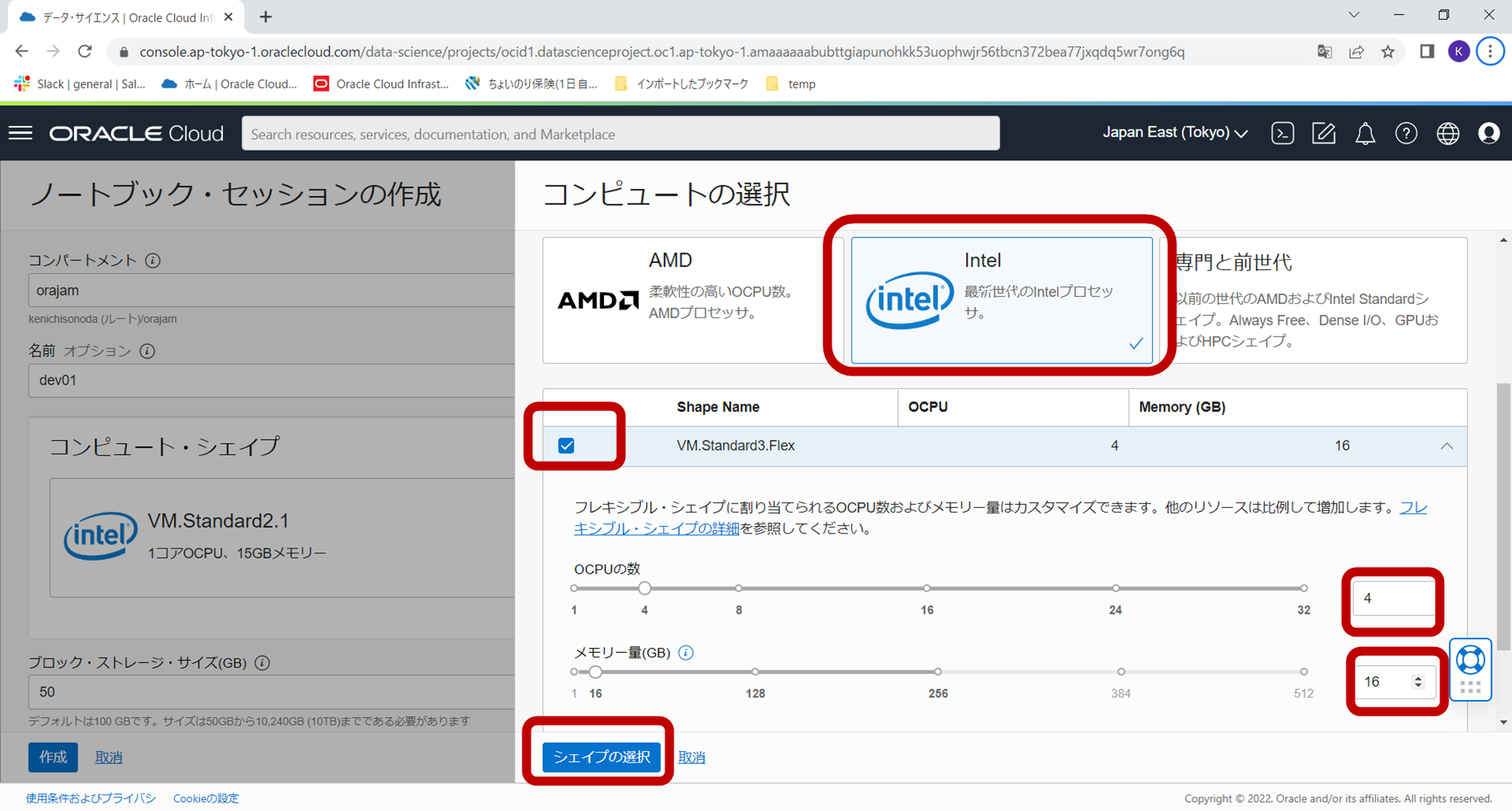
- コンピュートシェイプ:選択ボタンをクリックし、ウィザード内で、仮想マシン、Intel、VM.Standard3.Flex(8コア、32GBメモリを入力)を選択 (※下記の図では4コア、16GBメモリとなっていますが今回は処理が重いので倍のリソースで実行します。)
- ブロックストレージサイズ:50
- ネットワーキングリソース:デフォルト・ネットワーキング
作成ボタンを押してから5分くらいでノートブック・セッションが作成されインスタンスが起動し、下記のような画面に遷移します。
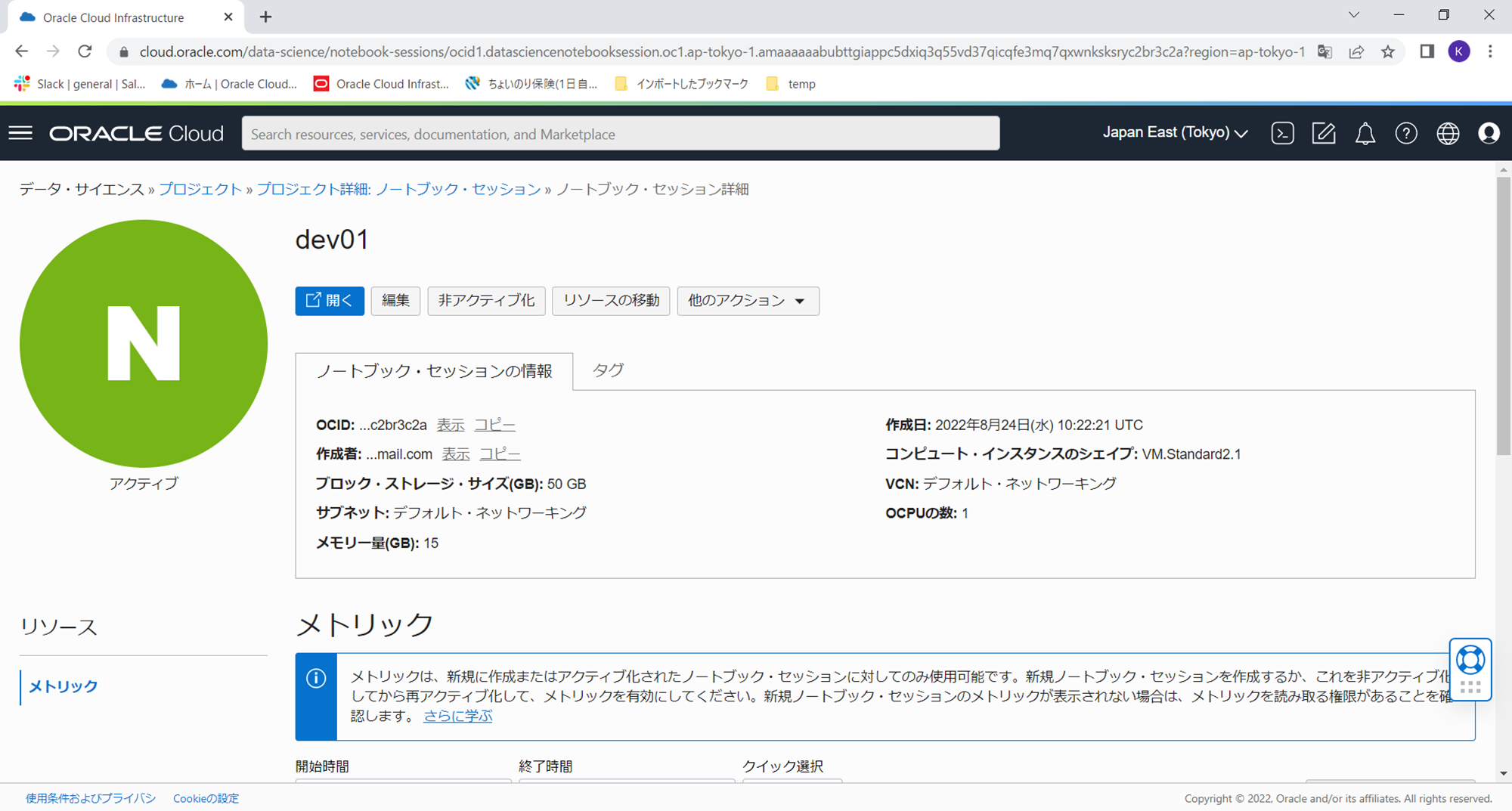
作成したノートブックセッションの「開く」ボタンをクリックします。
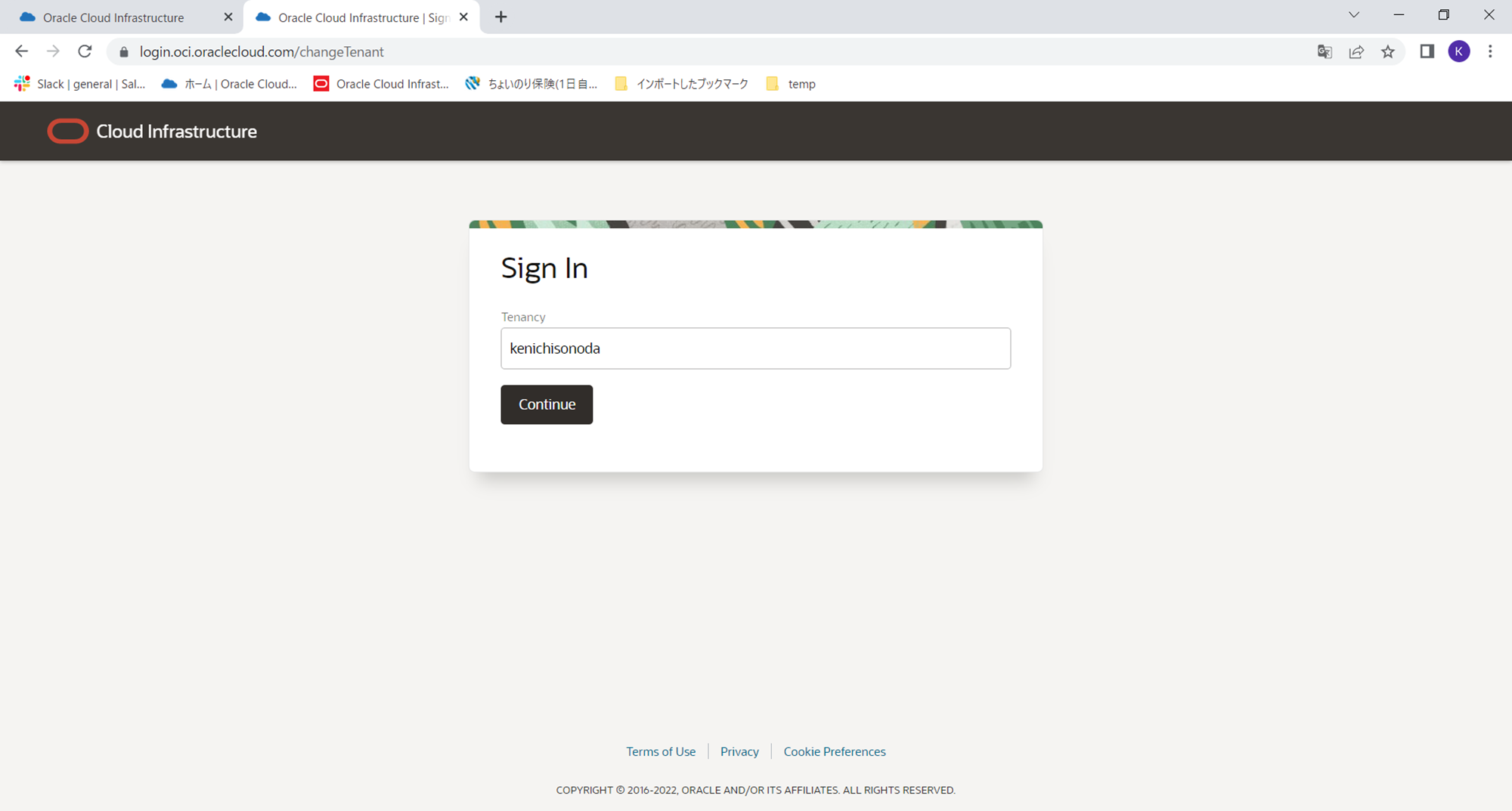
サインインの画面が表示されますのでテナント名を入力し、continueボタンをクリックします。
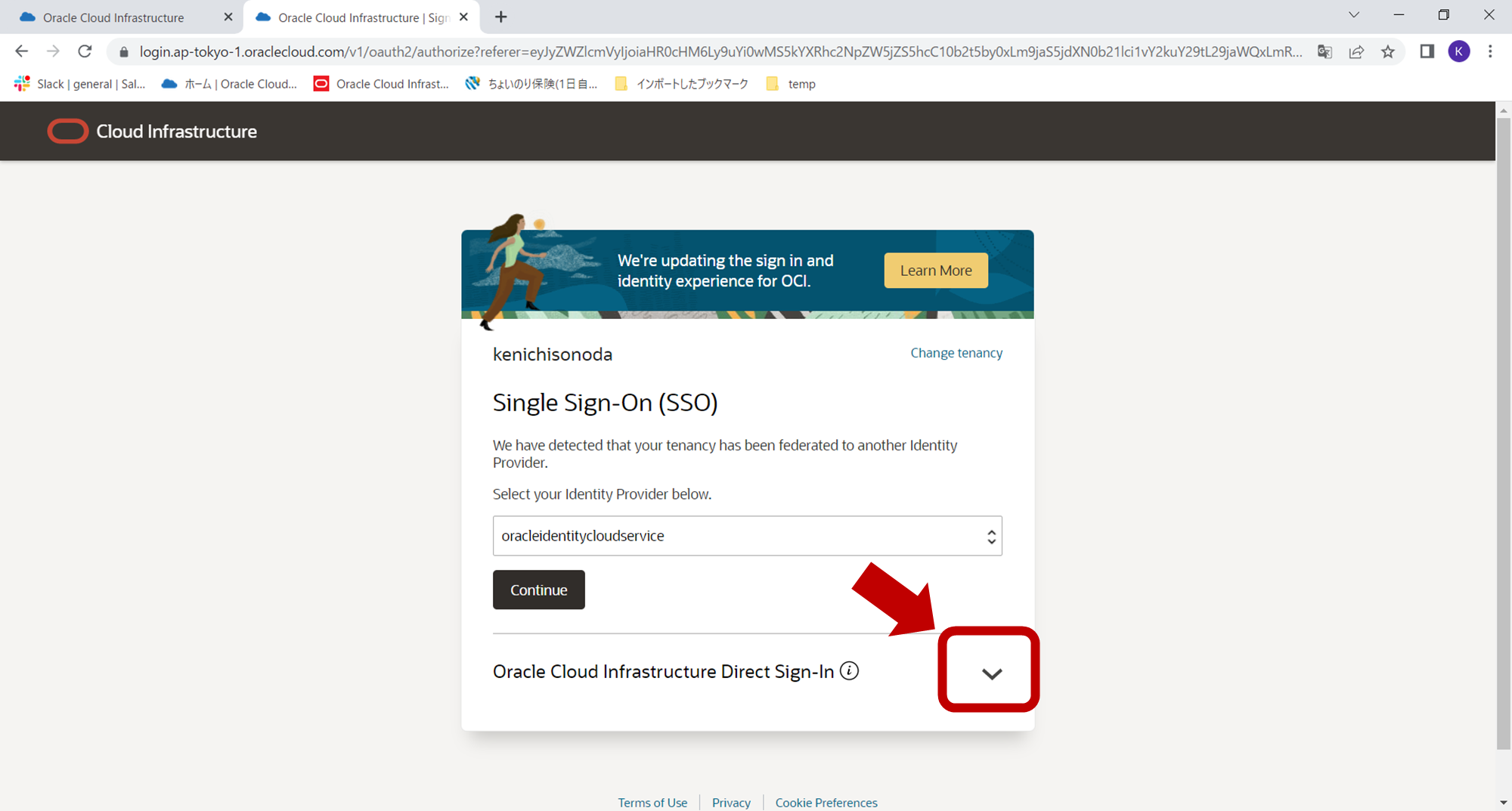
次の画面で右下の下矢印のマークをクリックします
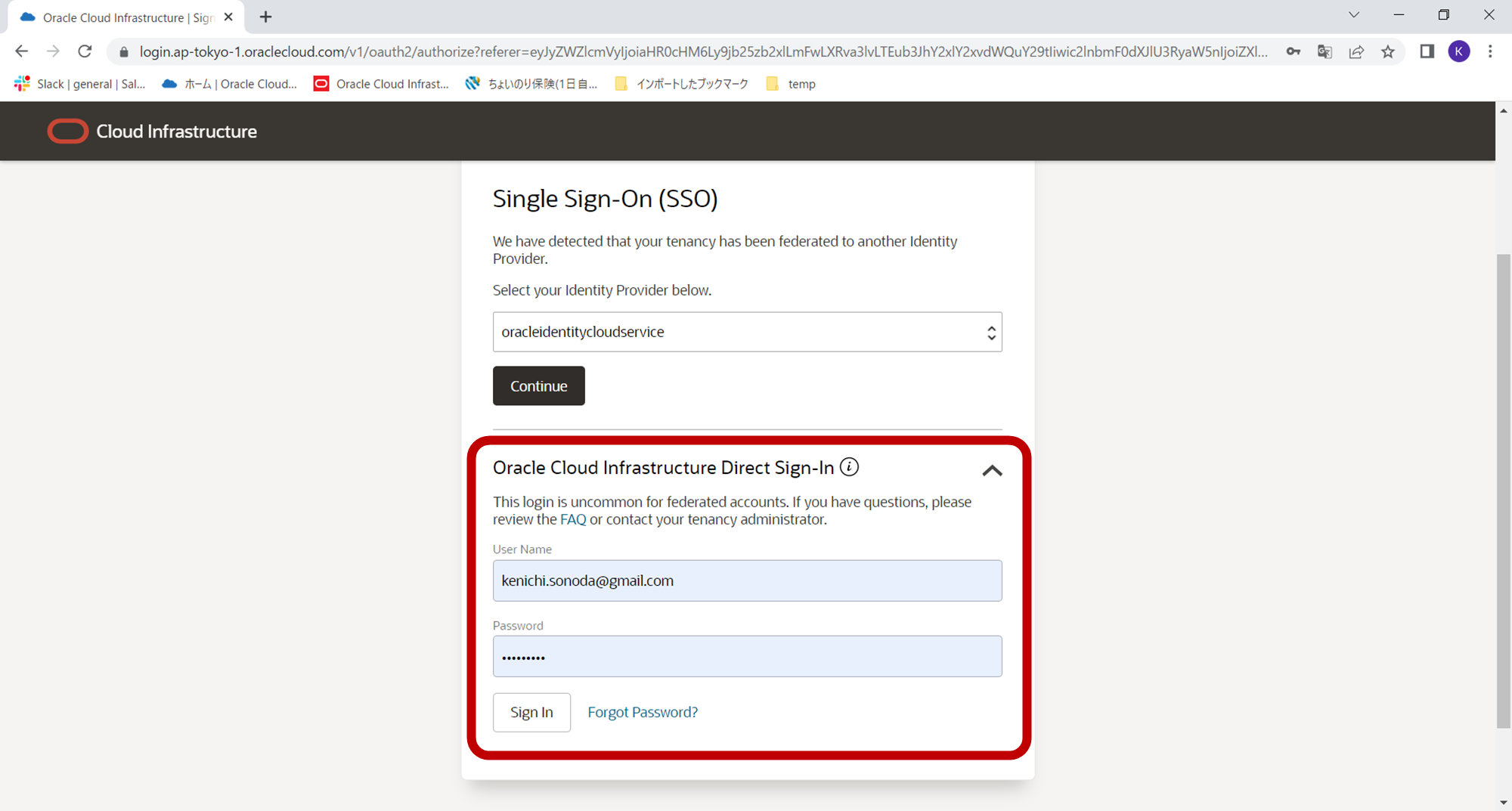
Oracle Cloud Infrastructure Direct Sign-Inのほうにアカウント名とパスワードを入力しSign-Inボタンをクリックします。
下記のようにJupyter Notebookのトップ画面が表示されましたらログイン成功です。
#conda仮想環境の作成
ここまでの作業でPythonの環境はもうできています。このPython環境の中にConda仮想環境を一つ作り、本ハンズオン専用の環境にします。
ノートブックセッションのトップ画面のLauncherのタブを下方向にスクロールします。
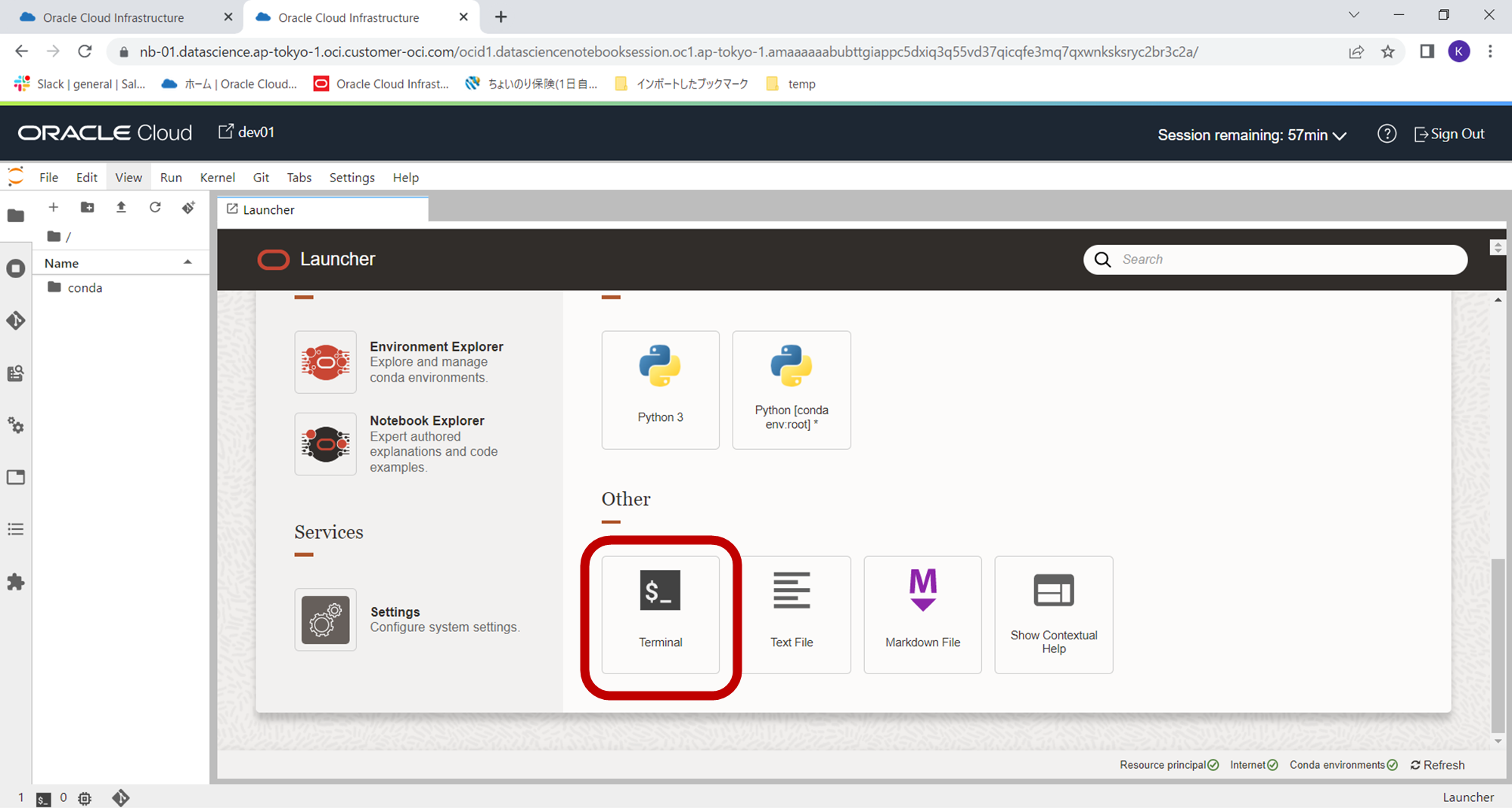
Terminalのアイコンをクリックし、Terminalの画面に移動します。
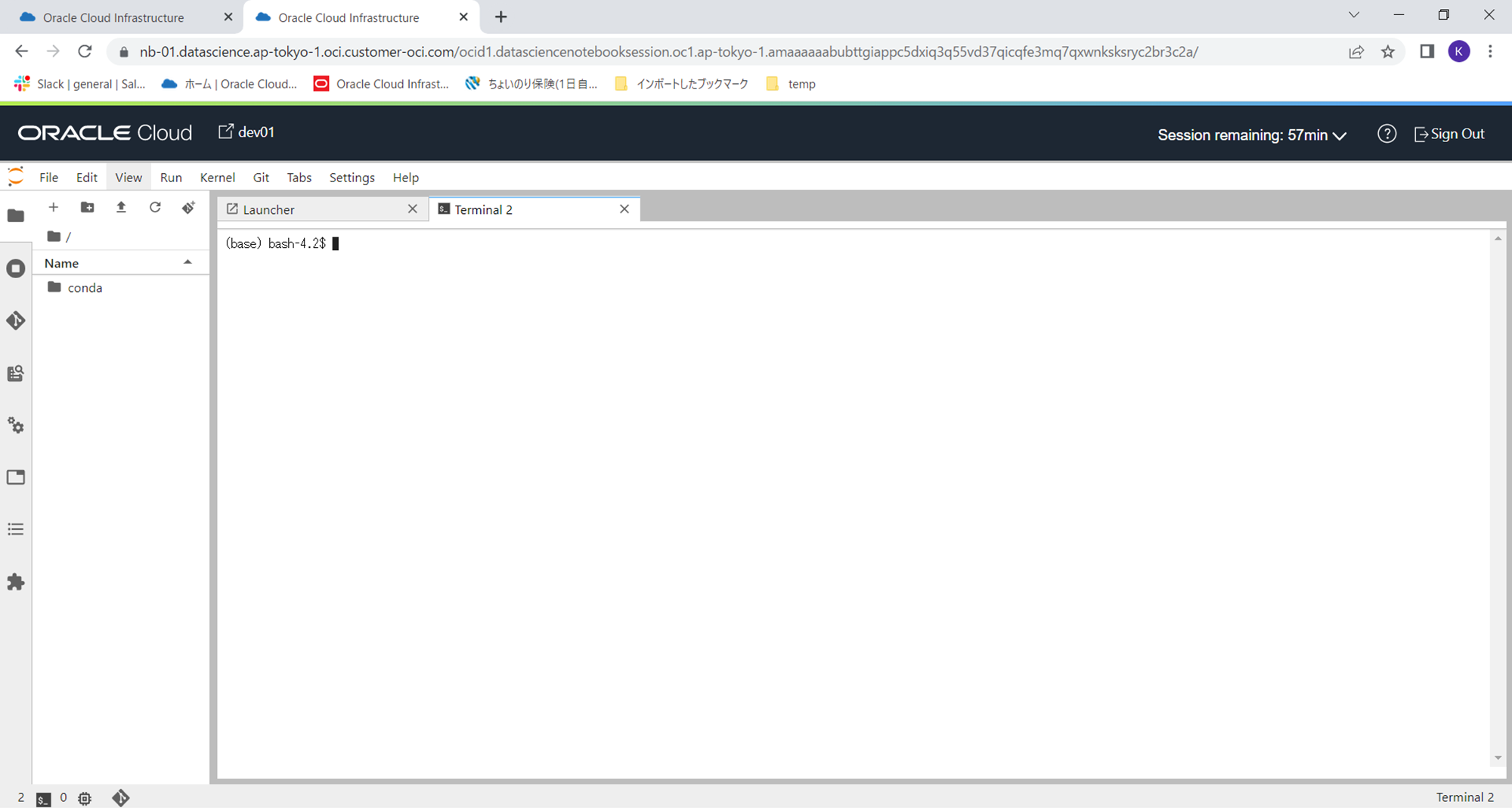
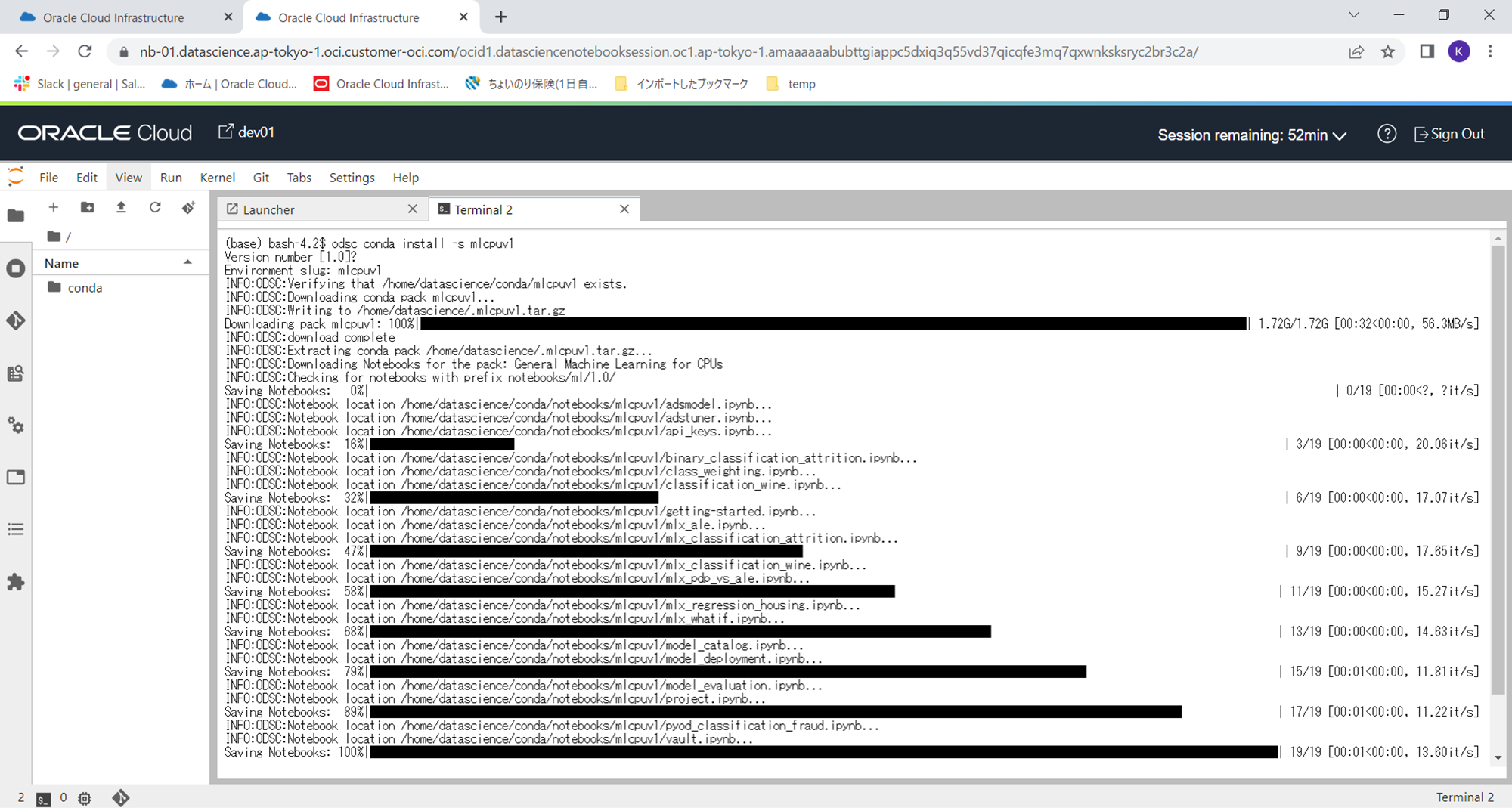
このターミナルで下記コマンドを実行し、このPython環境にconda仮想環境を作成します。このターミナルはCtrl+c、Ctrl+vでコピー、ペーストできますので、下記のコマンドをそのままターミナルにペーストしてコマンドを実行してください。
仮想環境の作成コマンド
odsc conda install -s mlcpuv1
※もし何らかの理由で仮想環境を作り直したいときは下記コマンドでいったん削除してから再作成してください。問題なくConda仮想環境が作成できた場合は下記コマンドは実行しないで次のステップへ進んでください。
仮想環境の削除コマンド
odsc conda delete -s mlcpuv1
作成コマンドの処理が終われば、仮想環境作成完了です。
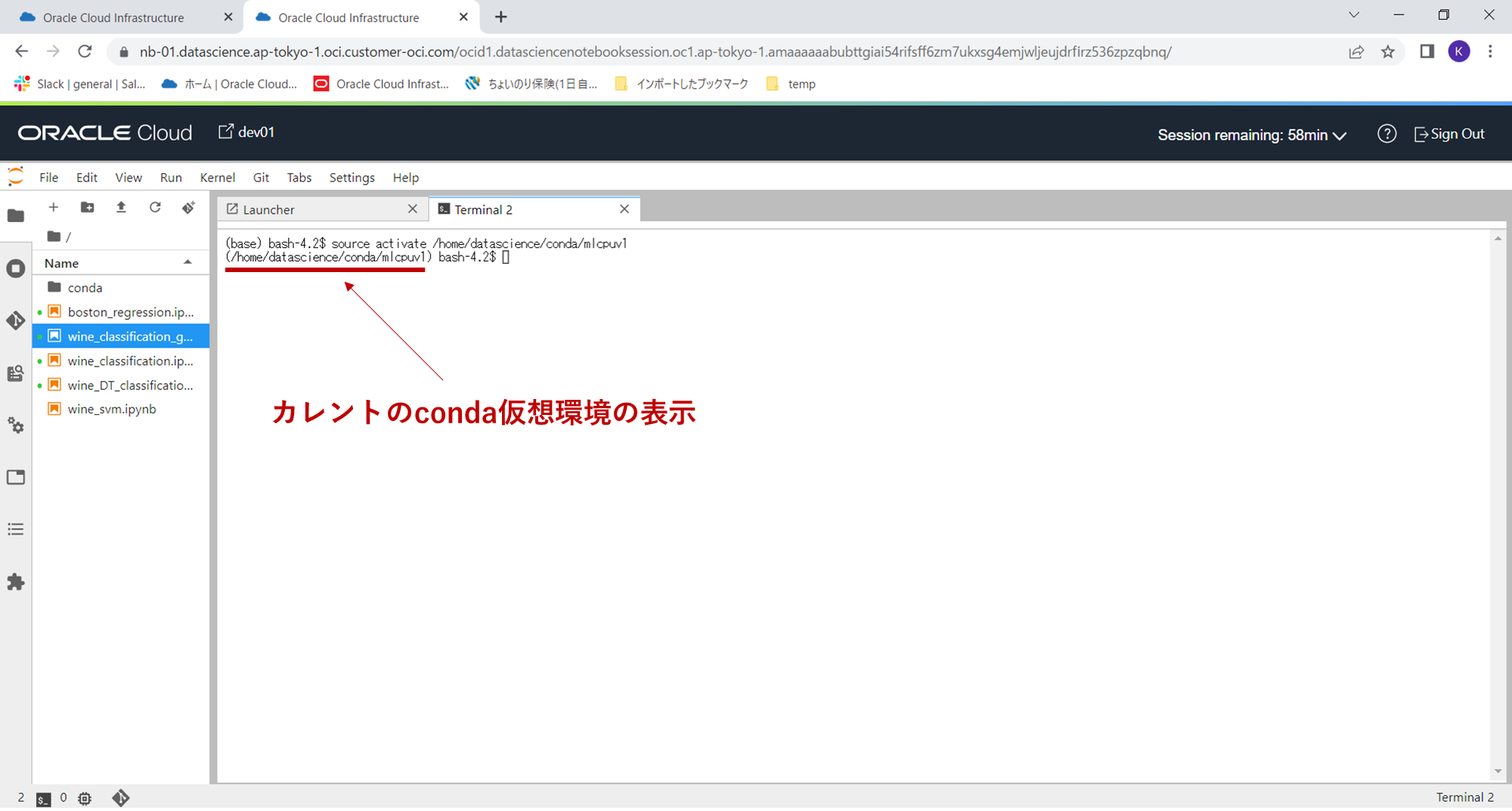
次に、下記コマンドで作成した、仮想環境mlcpuv1に移動します。移動したあとは、コマンドプロンプトのコマンドラインに常にカレントの仮想環境が表示されますので、今後の作業は間違った環境に設定をしないように、この部分を常に意識しながら設定作業を行います。
source activate /home/datascience/conda/mlcpuv1
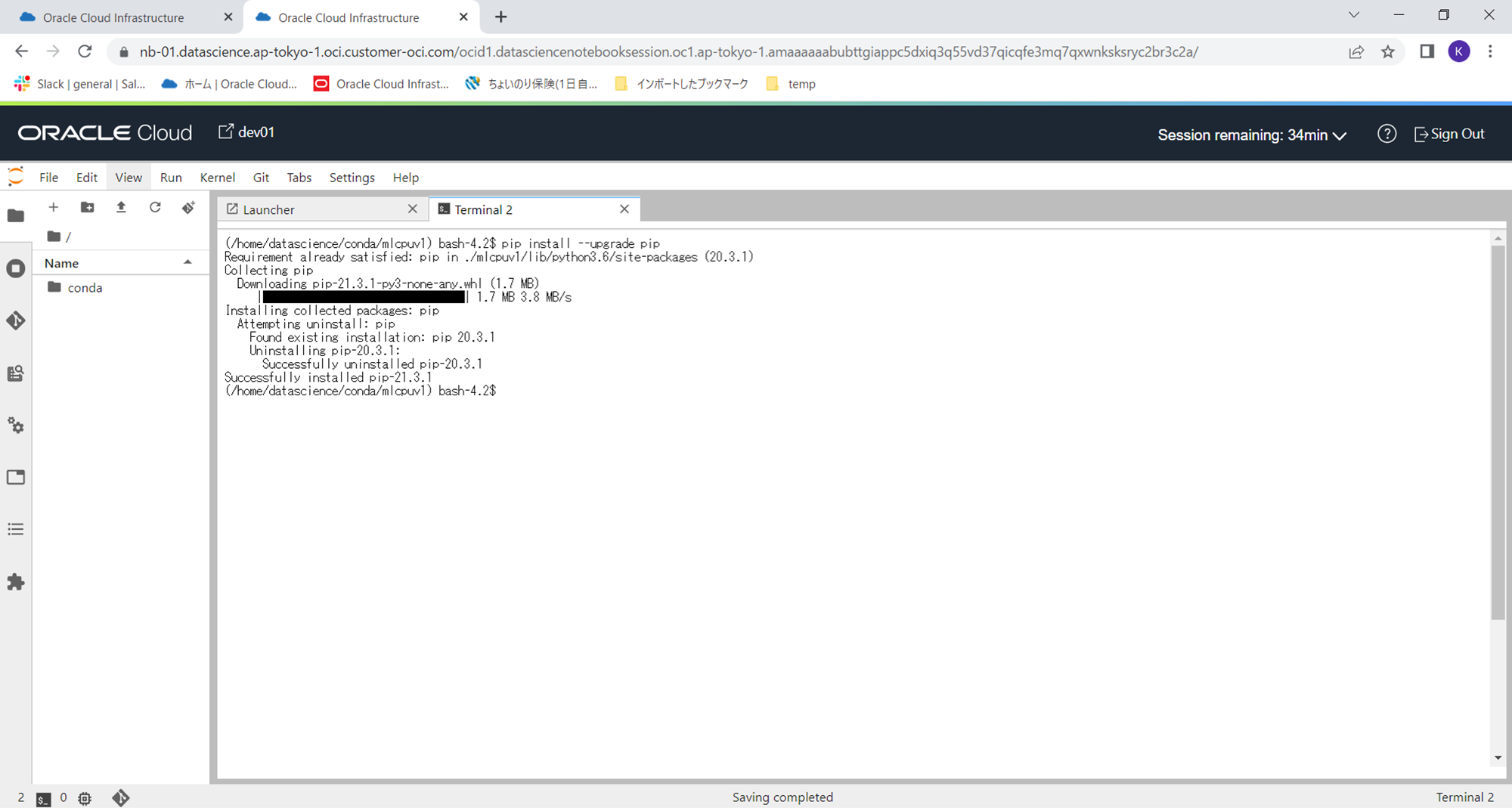
この仮想環境に、ハンズオンで利用するライブラリをインストールします。その前にまずは、下記コマンドでpipのアップグレードを行います。
pip install --upgrade pip
2023年3月1日のハンズオンセミナーではこのセクションの以降の作業は不要ですので、インスタンスを非アクティブにし、課金を停止に移動し、作業を完了させてください。
続けて、下記3つのライブラリをインストールします。
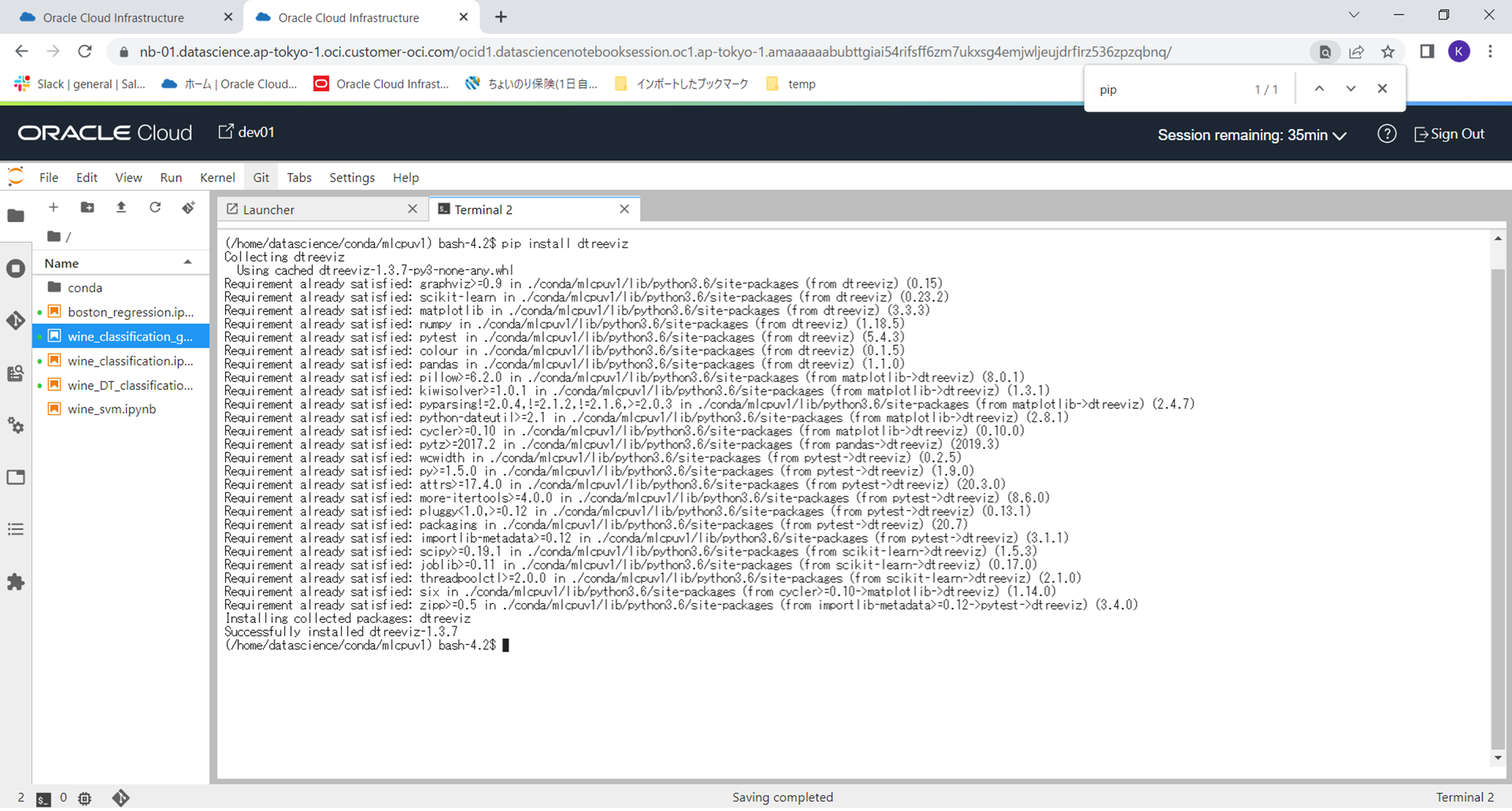
pip install dtreeviz
pip install auto-sklearn
pip install pipelineprofiler
下記が、dtreevizのインストール時の出力画面です。続けて他2つのライブラリ(auto-sklearn、pipelineprofiler)を上記コマンドでインストールしてください。
インストール完了後、再度、Laucherのタブに戻り、Pythonのアイコンをクリックし、「Create Notebook」をクリックします。
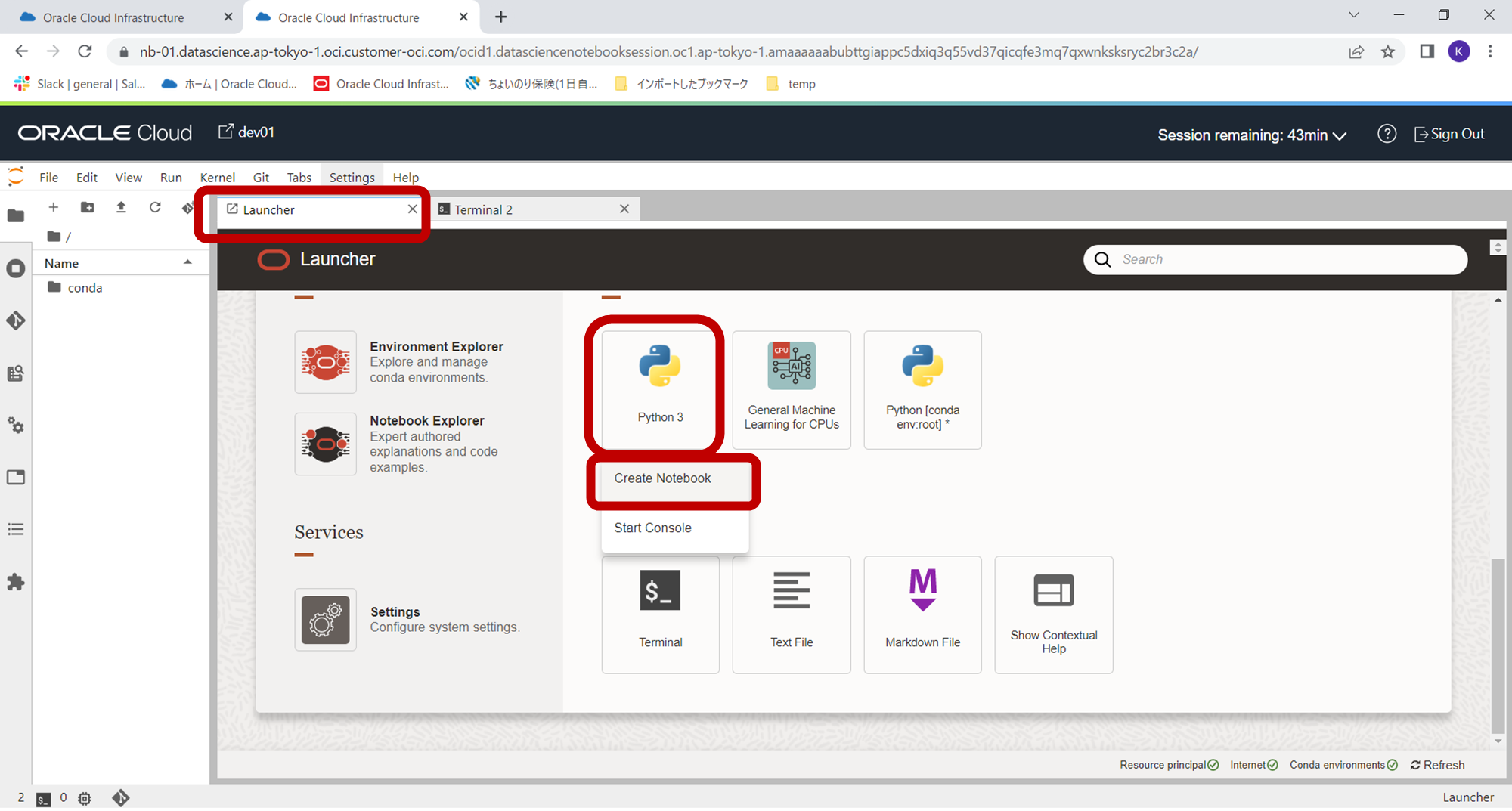
下記のようにノートブックが作成されますので、右側の赤枠の部分をクリックし、このノートブックを実行するカーネルを選択します。
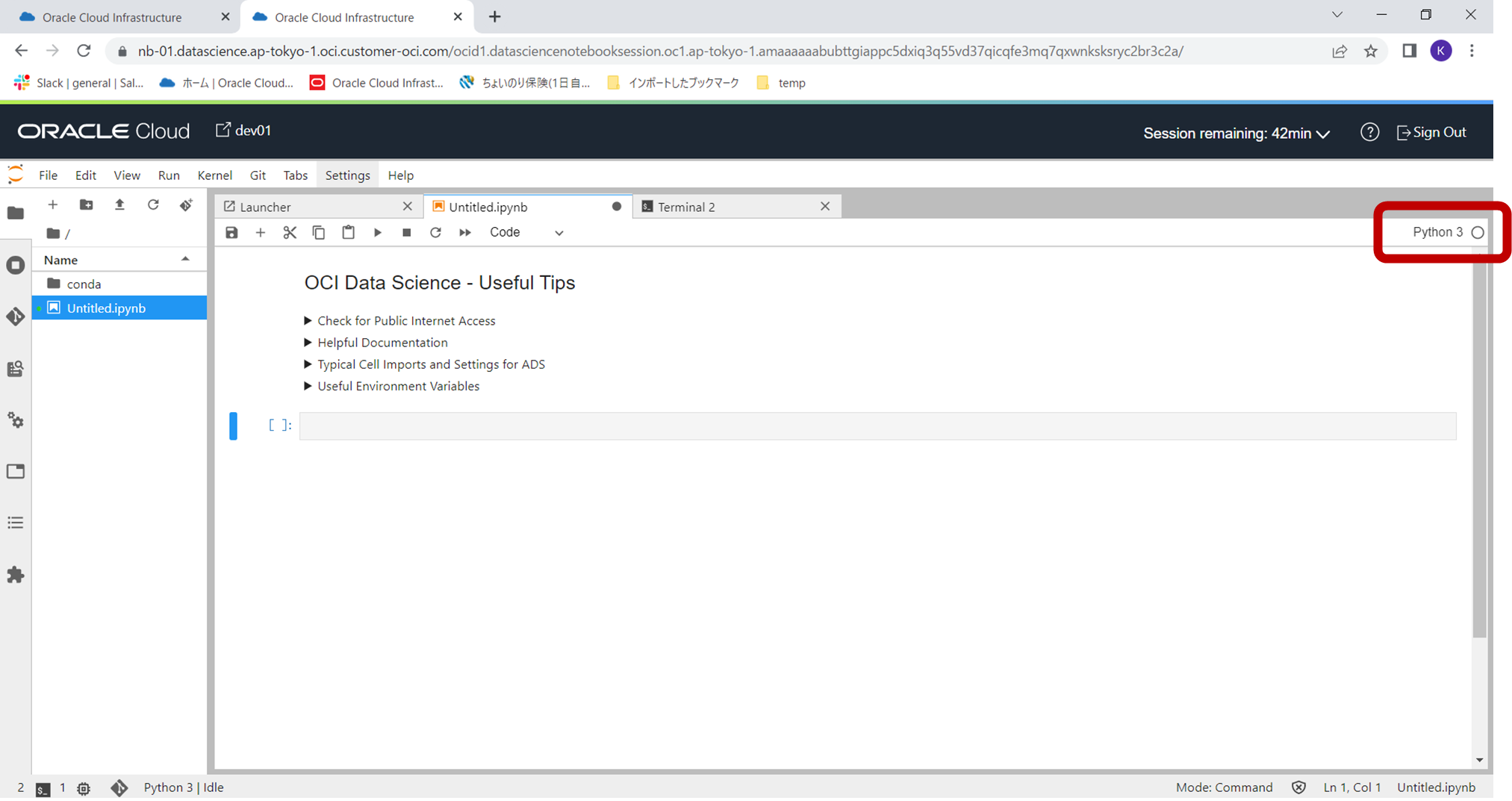
ドロップダウンから、作成済のmlcpuv1を選択します。
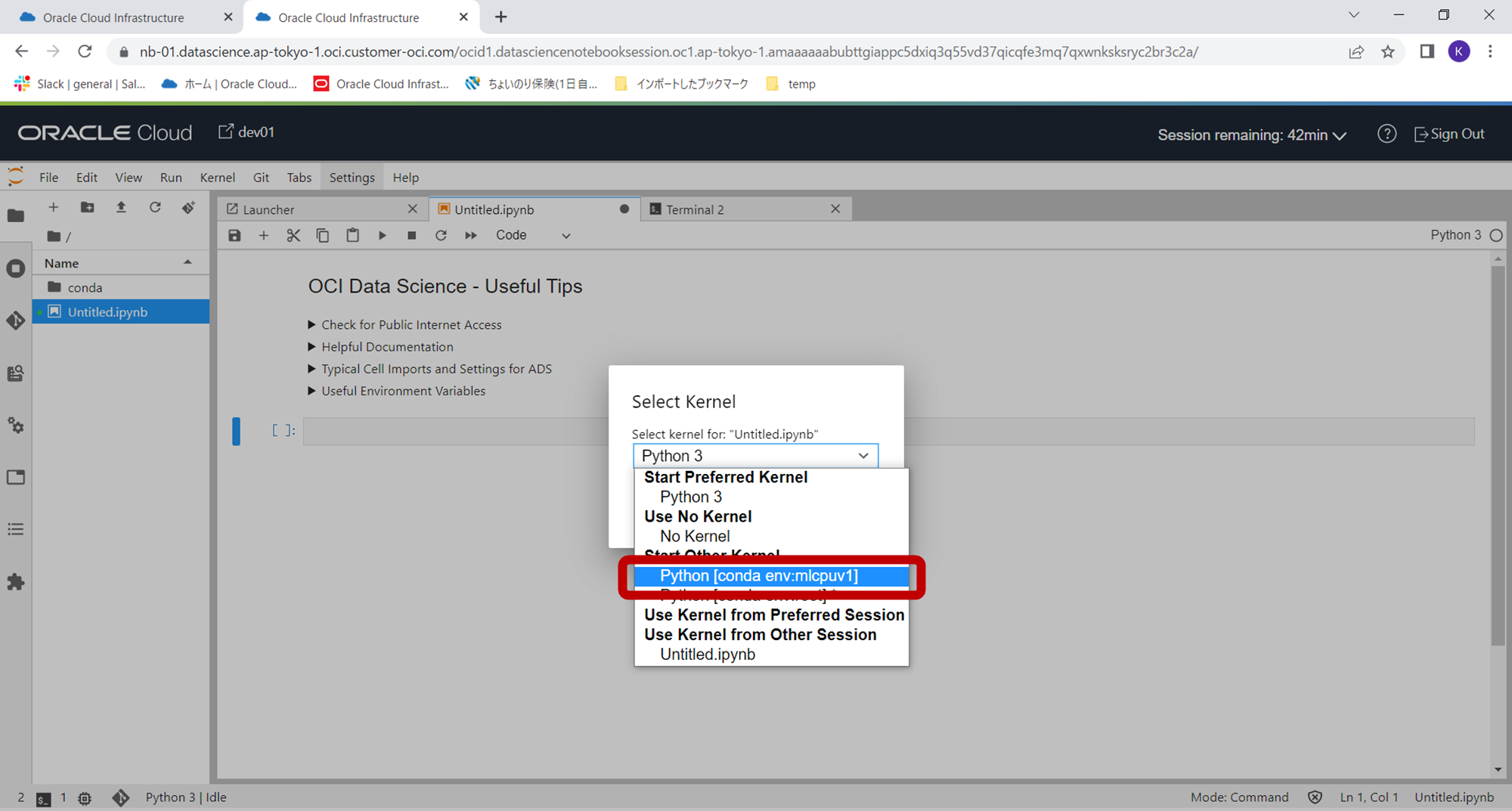
これでカーネルが選択できている状況になっていますので、下記コードを入力し、インストールした3つのライブラリのバージョンを確認してみます。
import dtreeviz
import sklearn
import autosklearn
print(dtreeviz.__version__)
print(sklearn.__version__)
print(autosklearn.__version__)
下記のように何もエラーが表示されずバージョンが表示されれば問題なくインストールが完了しています。
エラーが出た場合は、ライブラリがうまくインストールされていないか、誤った仮想環境で作業をしていたかのどちらかだと思いますので、本記事の仮想環境の作成、ライブラリのインストールの部分を見直してみてください。
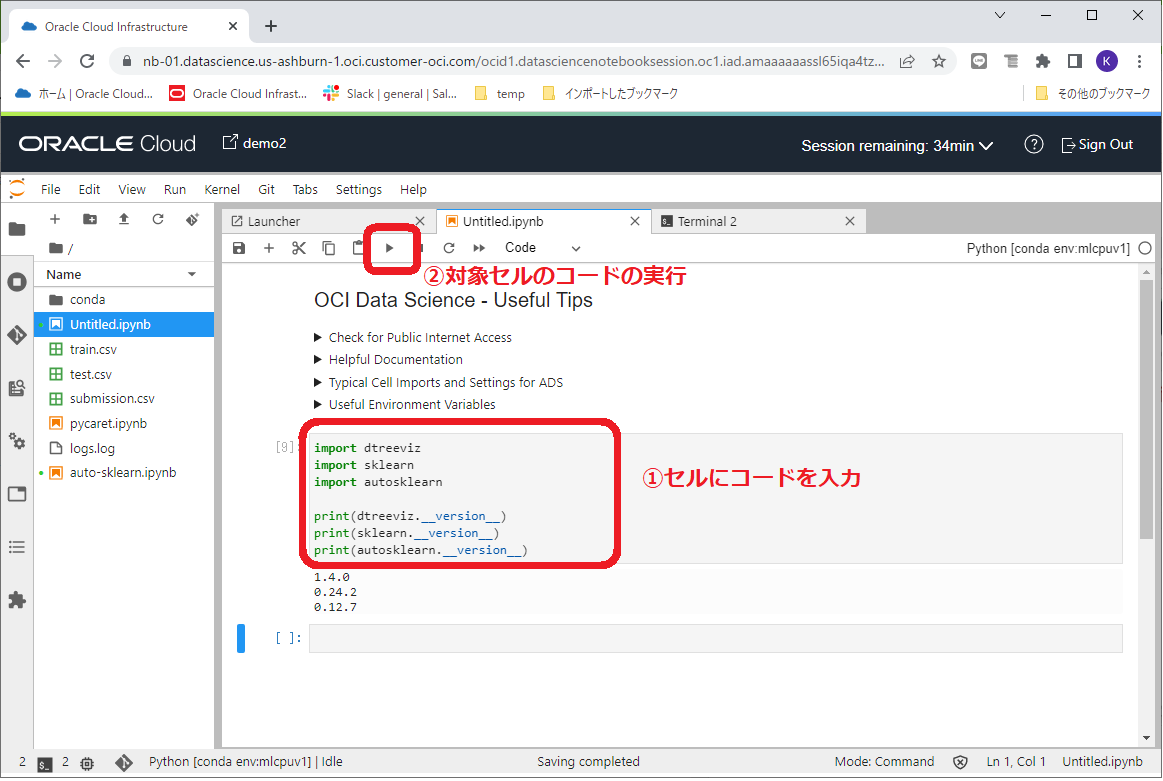
ハンズオンの事前準備は以上になります。
インスタンスを非アクティブにし、課金を停止
事前準備完了後はインスタンスを非アクティブにすることでCPU課金を止めることができますので必ずこちらの設定をお願いいたします。
ノートブック・セッションの画面に戻り、「非アクティブ化」ボタンをクリックします。
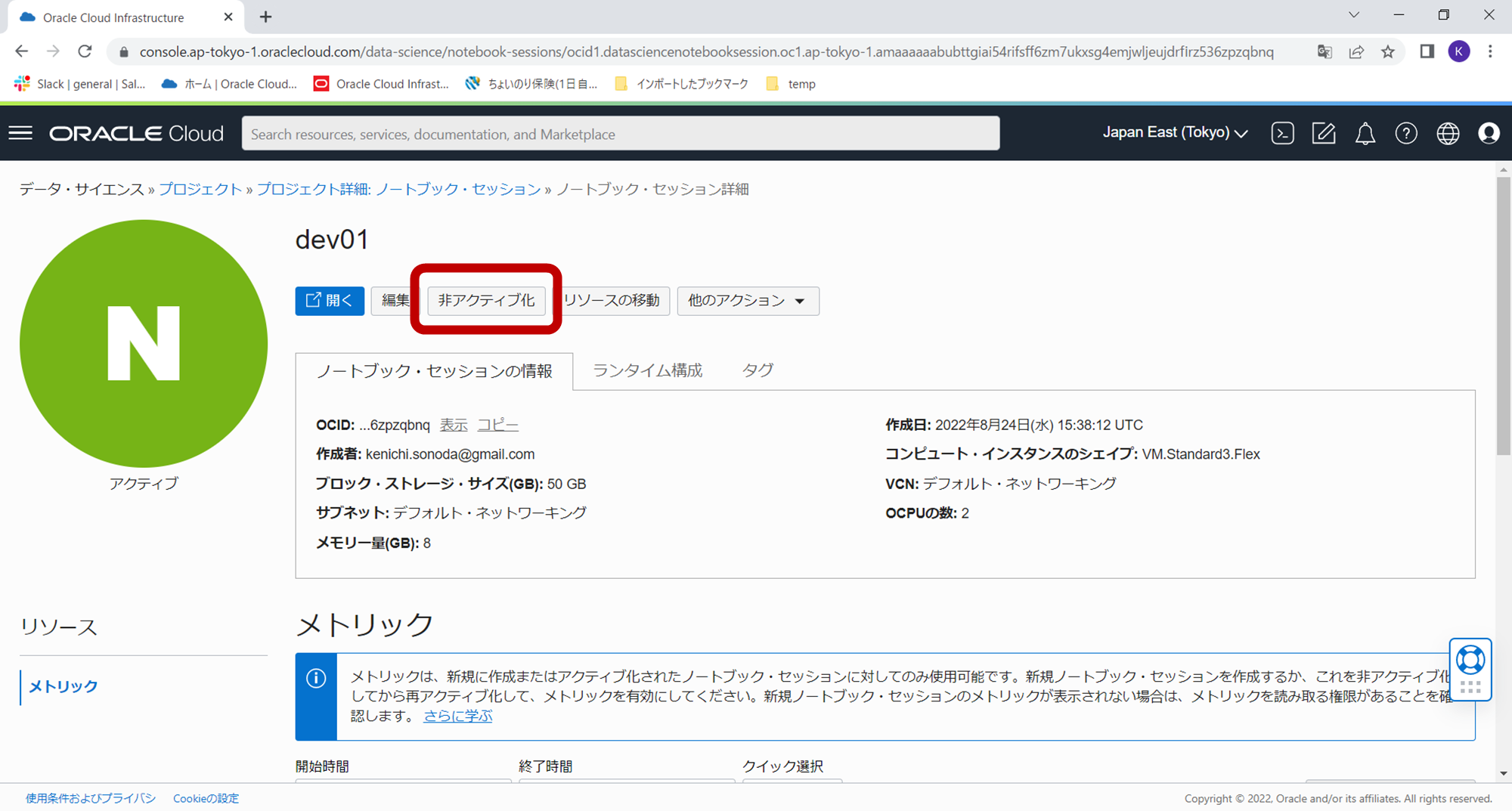
確認ダイアログが表示されますので「非アクティブ化」をクリックします。
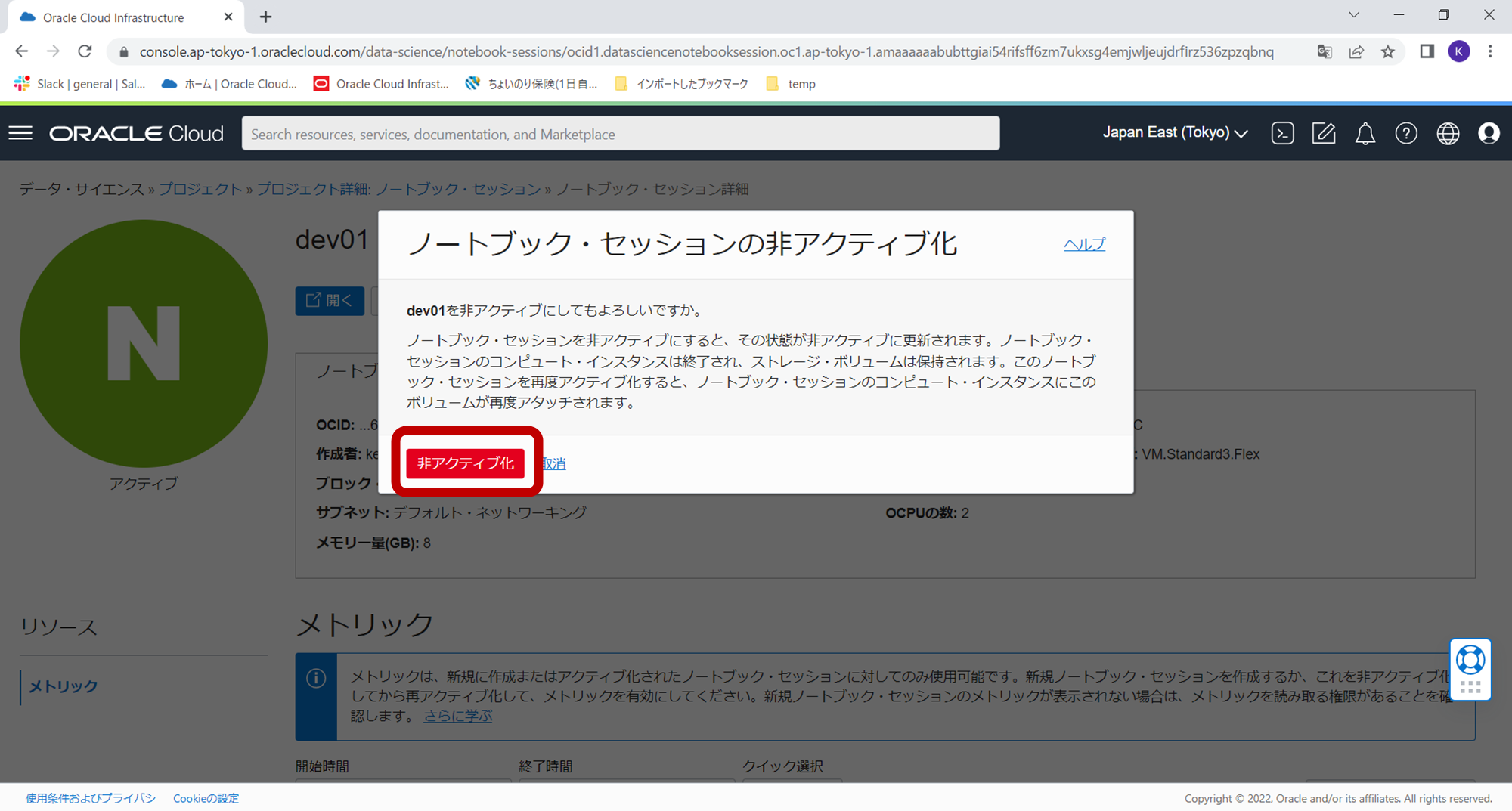
数分でインスタンスが停止し、CPU課金は停止します。ブロックストレージの課金は継続されますのでご注意ください。
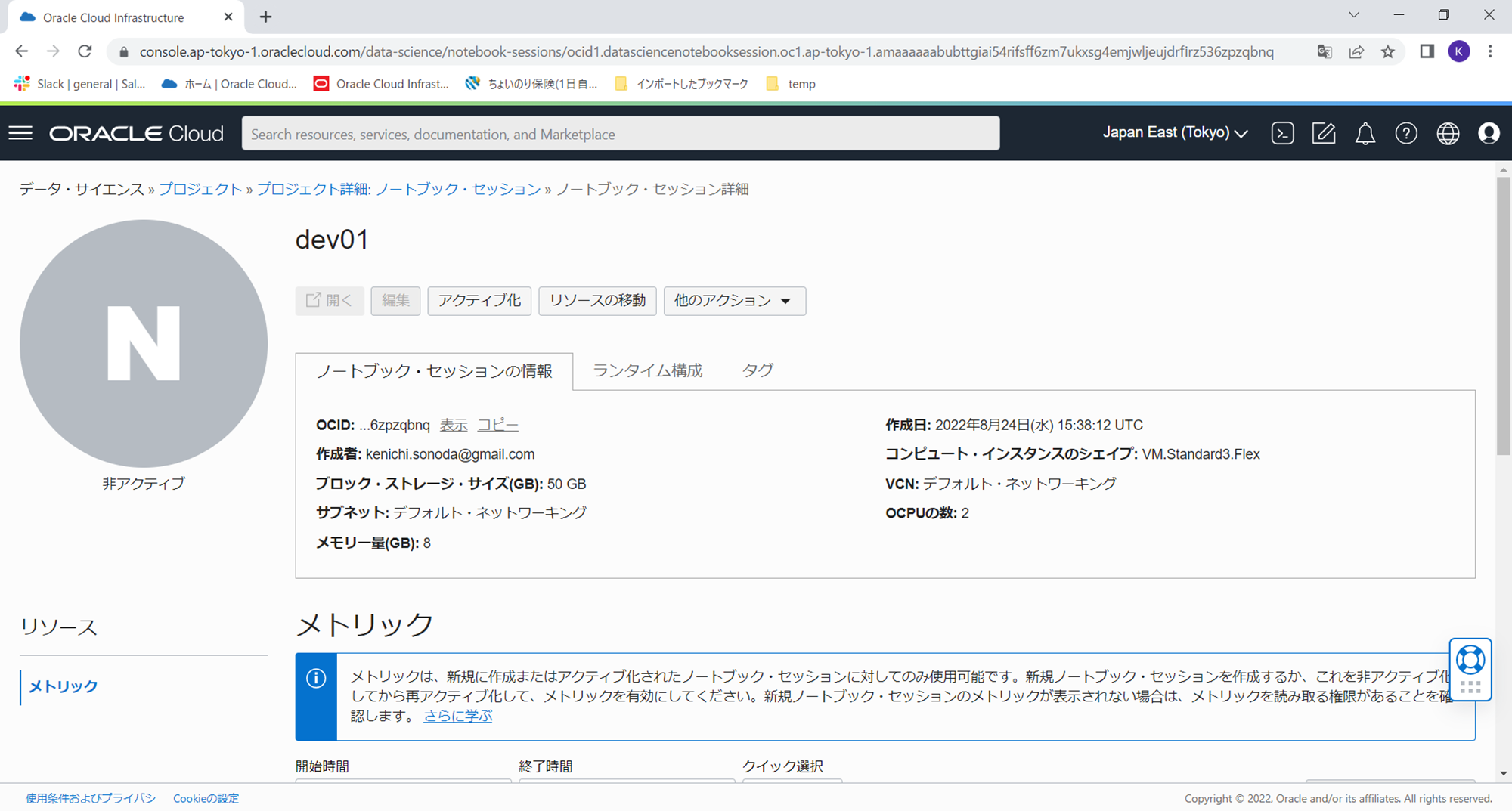
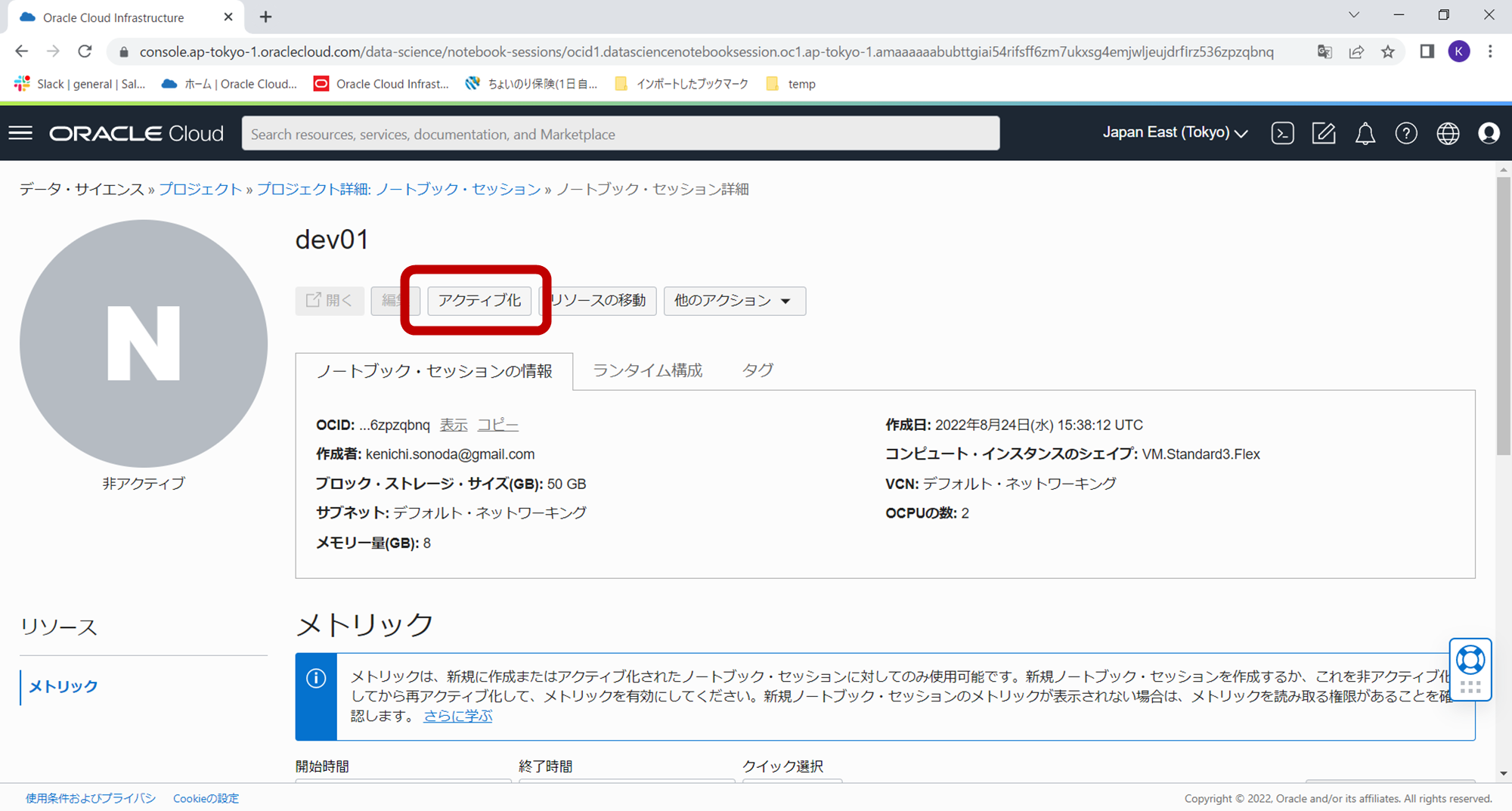
ハンズオン当日に下記、アクティブ化のボタンをクリックし、シェイプを選択することでインスタンスが起動します。
ハンズオン当日は、下記記事で概説している機械学習の基礎について学び、回帰問題と分類問題のサンプルコードをData Science Serviceの上で実際に動かします。