#1.はじめに & 動作環境
バックオフィスにおいて日常的に発生する業務にエクセルの加工作業がある。
これらの多くの作業は同じ作業の繰り返しであることが多いため、これらをできる限り自動化することで業務の効率化と生産性の向上を目指す。
動作環境
OS : Windows10
Python : 3.8.3
jupyter notebook 6.0.1
#2.エクセル関数の洗い出しと絞り込み
日常的に使用するエクセル関数の洗い出しを行う。
同時に、繰り返し行う定型的な作業に使用する関数の絞り込みを行う。
・シェアドライブに保管しているエクセルを開く
・行列の削除
・別名でブック保存
・不要なデータの除外
・複数シートの統合
・merge
・ローカルドライブに保管しているエクセルを開く
#3.工程図 for Excel2 OpenOrders
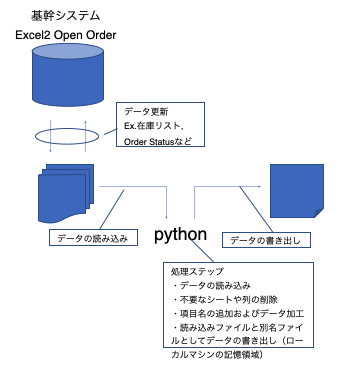
#4.コードの処理の手順概要
1.基幹システムからエクセルに受注データや在庫の情報をダウンロード
2.Pythonを使用してシェアドライブに保存してあるエクセルのデータをpandasに読み込む
3.本作業には不要なおよそ200列を削除
空いた空列に項目名を追加(管理表納入予定日、日付修正、出荷処理)
日付で並び替え(Sort)
#GoLive Openorder list
import pandas as pd
import time
t1 = time.time() # 処理前の時刻
#データ読込
df = pd.read_excel('C:/Users/qz781/Desktop/PythonProject/Python_CJL/02.Backlog Review/BacklogReport_vr3.xlsm', sheet_name='MGHEAD', index_col=1)
#列の削除 →カラムをリストで渡してまとめて列を削除
columns = ['x1','x2','x3','x4','x5']
df1 = df.drop(columns, axis=1)
#新規列の追加
df1["管理表納入予定日"] = ""
df1["日付修正"] = ""
df1["出荷処理"] = ""
#sort
df1 = df1.sort_values(by="MGTRDT", ascending = True)
df1.to_excel('C:/Users/xxx/Desktop/PythonProject/OpenOrders.xlsx', sheet_name='test')
t2 = time.time()# 処理後の時刻
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}") # 経過時間を表示

CustCodeの抽出
4.カスタマーマスターからカスタマーコードとそれに紐づく顧客名及び顧客ごとの出荷処理項目を読み込む
import pandas as pd
#1.データの読み込み
df = pd.read_excel('C:/Users/xxx/Desktop/PythonProject/BacklogReport_vr3.xlsm', sheet_name='OOLINE ( OIS100)', index_col=0)
# 列 "A", "B" の 2 列を抽出
df2 = df.loc[:,['OBORNO','OBCUNO']]
df2.to_excel('C:/Users/xxx/Desktop/PythonProject/OpenOrders_OIS100.xlsx', sheet_name='test')

Order#をキーとしてCustCodeをMerge
5.pandasに読み込んだ受注データとカスタマーマスターを結合し、顧客コードではわかりずらかった顧客名と顧客ごとに違う出荷処理項目を追記して他のメンバーにもすぐにわかるようにする。
6.チェック項目でフィルタリング
7.ローカルドライブに保存。日々MTGでチームと共有し、出荷進捗状況の確認や業務指示に使用する。
# merge1
import pandas as pd
#データ読込
df1 = pd.read_excel('C:/Users/xxx/Desktop/PythonProject/OpenOrders_MGHEAD.xlsx', sheet_name='test', index_col=None)
df2 = pd.read_excel('C:/Users/qz781/Desktop/PythonProject/Python_CJL/02.Backlog Review/OpenOrders_OIS100.xlsx', sheet_name='test2', index_col=None)
#データ型の確認&変更
df2["OBORNO"] = df2["OBORNO"].astype(str)
#df1.dtypes #MGRORN=object
df2.dtypes #OBORNO=int64 →objectに変更
df3 = pd.merge(df1, df2, left_on= "MGRORN", right_on="OBORNO", how="outer")
#filtering
df3 = df3.loc[df3["MGFACI"] == "EJ1"]
df3 = df3.loc[df3["MGTRSL"] != 99]
df3 = df3.loc[df3["MGTRSL"] != 44]
df3.to_excel('C:/Users/xxx/Desktop/PythonProject/OpenOrders_merge1.xlsx', sheet_name='test')
#5.完成 for Excel2 OpenOrders

こちらも使用した資料は実際に業務で使用しているものをダミーデータに置き換えている。また、ダミーに置き換える時間を短くするためにデータ量も極端に圧縮している。
#6.終わりに
また毎日同じ作業をしなくてはならないため、手作業で行うのは苦痛だったがこのように少しでも自動化できる平行して別作業を行うこともできるため効率化にも繋がった。
今回作成したコードをそのまま実務に適用している。
今まで全て手作業で行っていたた。目視で必要な列を抽出かつ200列を削除し、顧客名をVlookupで引っ張ってくる工程に毎日30分程度かかっていた。
Pythonを使用することで20分程度に短縮することができ、加えてPython自動処理中に他の作業を行える
実際の現場では、納期管理表は複数人が共有で更新しているため、項目の追加などフォーマットが随時変わっていくことが考えられる。
そのため後で見直ししたときにすぐに内容がわかり、なおかつ修正しやすいようにできる限りシンプルなコードを心がけていきたい。
今後も学習努力を続け、より効果的な書き方や使い方を身につけたいと考えている。