概要
GPT、Claude、Gemini、Llama など「生成 AI」というキーワードで急速に一般化が進んでいる大規模言語モデルについて、理解を深めるために自身の学びの記録を残します。
学習は、下部に記載の Udemy コースを視聴しながら気になった部分を調べる感じで進めます。
今回は初回なので、 LLM の概要についてです。
LLM の仕組みを学ぶねらい
- 生成 AI を web アプリの機能として組み込むことができるようになりたい
- LLM の仕組みを理解したうえで使いこなせるようになりたい
- LLM の前提となるニューラルネットワークやその他学術的な部分にも触れてみたい
- ChatGPT をはじめとする生成 AI サービスの動作原理について理解を深めたい
- とりあえず LLM でなんか実装してみたい
大規模言語モデル(LLM)とは?
大規模言語モデルとは、文章を扱う AI モデルで、自然言語がインターフェース(入力)となる。
インプットに対する次の単語や文章を精度高く予測することで、もっともらしい文章を生成する。
Transformer という学習モデルの登場によって、大幅に回答精度が向上した。
OpenAI 社の GPT-3 は、1750 億のパラメータでトレーニングされていて、GPT-4 は非公開だが、1 兆を超えるのでは?という話も出ているほど。
Transformer とは
2017 年に導入された深層学習モデルで、主に自然言語処理の分野で利用される。
RNN と同様、自然言語などの時系列データを処理するよう設計されているが、RNN で用いる再帰、CNN で用いる畳み込みは使わず、Attention 層のみで構築される。
翻訳やテキスト要約など、さまざまなタスクで利用可能。
並列化が容易であり、訓練時間を大幅に削減できる。
GPT3 等の LLM は Transformer を用いることによって高速に大量の学習を行い進化している!

ChatGPT とは
OpenAI 社が提供するチャット形式で LLM を利用することができるサービス。
対話に特化した言語モデルで、自然な文章を生成できる。
この特徴を利用して、まるで AI と会話しているかのようなやり取りが可能。
また、プラグインによってさまざまな機能拡張が可能。めちゃくちゃいろんなプラグインが開発されている。
プロンプトエンジニアリング
プロンプトとは、AI に与える命令文のこと。
適切なプロンプトを与えることで正しい(求める)回答を得られる可能性があがる。
指示文の日本語力、AI への指示力が試される。
いつ、どこで、誰が、何を、どのように、なぜ etc.
普段 ChatGPT を使っているなかで個人的に大事だと感じていること
- 生成 AI にやってほしいことを明確に指示する
- 前提情報やどのような形式でアウトプットしてほしいかを補足する
- 回答生成時に考慮してほしいポイントを伝える
- わからない場合は「わからない」と答えてと伝える(これけっこう大事!)
これぐらい注意して問い掛ければ、ある程度ハルシネーションを抑えて求める形の回答が得られやすいと思う。
LLM の課題
モデルの学習コストが高い
学習に高品質で大量のデータ(膨大な計算資源)が必要で、大資本が必要となるため、必然的に Google、Meta のような米大企業や OpenAI、Claude といった有名になった企業がより強い(資金力、調達力がある)状態になっている。環境にも優しくないかも。
プライバシーや機密情報の漏洩懸念
業務で取り扱う機密情報を ChatGPT に入力して答えさせると、モデルがその内容を学習してしまい、他者が ChatGPT を利用した際に機密情報が回答に使われてしまう(漏洩してしまう)リスクがある。
実際、サムスンで機密情報の漏洩事件が過去に起きている。
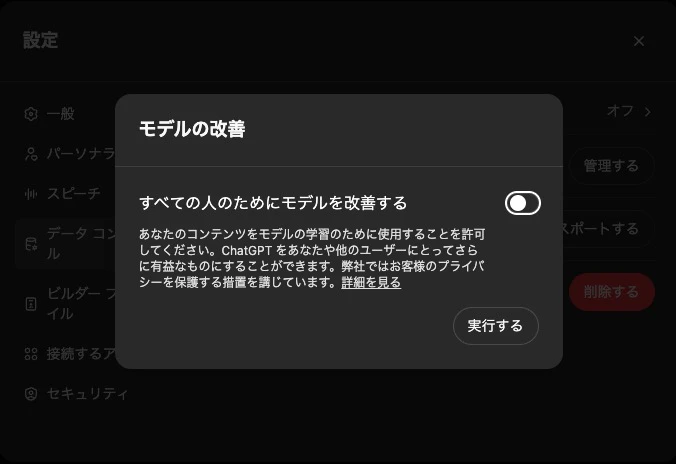
たとえば ChatGPT であれば、自分のインプットデータをモデルの学習に利用しないようにできる「オプトアプト」の設定が可能。
ChatGPT にログインして設定>データコントロール>すべての人のためにモデルを改善するをオフにすれば OK!
その他
- データの偏りがモデルに反映される可能性がある
- ヨーロッパの人、アフリカの人を画像で生成させると、ヨーロッパ人がきれいな身なりで、アフリカ人のイメージが労働者や奴隷を連想させる内容になってしまい差別的だと問題になった
- ハルシネーションが発生する可能性がある
- 「それらしい」回答が、間違った情報である可能性
- コンテンツの粗製濫造
- AI で生成した雑な記事が大量に投稿されたブログとか、サービス運営側で AI によるコンテンツの投稿ルールを定める等の対策が必要(とはいえ、AI で生成したコンテンツであることを判定するのが難しい)
まとめ
LLM がどういうものなのか、特徴や課題点をざっと把握できた。
これらの特徴をふまえて、次は LLM を呼び出して回答を受け取るようなプログラムコードを書いていければ理解が深まると思う。
やっぱりある程度の数学的な知識は身につけておく必要がありそう。がんばる。
用語集
わからない単語もけっこうあるので、随時用語集にまとめておきます。
- パラメータ
- ニューラルネットワークにおける重みやバイアスなどの値であり、モデルが入力データに基づいて出力を計算する際の中心的な役割を果たす。LLM がデータから学習し、予測や生成などのタスク実行能力の基盤となるもの。一般的にパラメータ数が多いほど LLM の性能が向上する(過学習という言葉もあり、一概に多けりゃいい!というわけではないらしい)が、トレーニング時のコスト増加などが課題となっている。
- RNN(Recurrent Neural Network:再帰ニューラルネットワーク)
- 時間的または順序的データを処理するために設計された人工ニューラルネットワーク。過去の情報を保持し、現在の出力に反映させるという特徴がある。時系列データや連続データ(テキスト、音声、動画など)の学習や予測に適している。
- CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)
- 画像認識や画像処理を主な用途として開発された人工ニューラルネットワーク・空間的な構造(画像内の位置情報)やパターンを効率的に学習できるという特徴がある。画像の分類や物体検出、医療での画像解析(セグメンテーション)などに利用される。
- 畳み込み
- 信号処理、画像処理、機械学習などで利用される数学的な演算のこと。ある入力データと小さなフィルタを組み合わせることで特徴を抽出する操作のことを指す。
- Attention(注意、注目の意味)
- 時系列データの特定の部分に注意を向けるように学習させていく方法。どの部分が現在のタスクに最も関連性があるのかを判断して、重みづけを行う。英語 → 日本語の翻訳の場合、ある単語を翻訳するときは元の文中の特定の単語やフレーズに注目する。この「注目」の仕組みを数式的にモデル化したのが Attention とのこと。
- ハルシネーション(Hallucination)
- 現実や事実に基づいていない情報を生成する現象のこと。「幻覚」という意味の心理学用語が使われている。曖昧なプロンプト(指示文)や学習データの偏りなどが原因で、回答として"それらしい"文章をでっちあげてしまう。(例:犬は鳥類であり、卵を産みます)
参考
-
大規模言語モデル(LLM)の仕組み入門【ChatGPT/GPT-4/Transformer】
- Udemy や YouTube で AI 関連の講義をされている我妻さんのコース(有料です)
-
Attention Is All You Need
- このサイトの
View PDFをクリック(タップ)すると英語の論文が読めます
- このサイトの