この記事について
日本ディープラーニング協会(JDLA)の初学者向けAI講座を個人的にまとめたメモです。
受講は無料のため、このまとめ記事で興味を持ったらぜひ本家の講座を受講してみてください。
・AI For Everyone (すべての人のためのAIリテラシー講座) | Coursera
・DXとは?
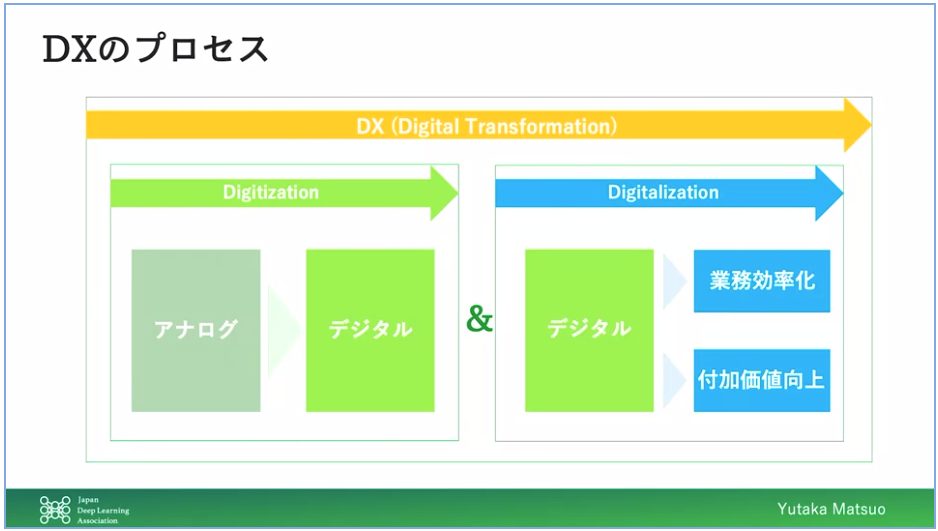
DX(Digital Transformation)は2つある
Digitization:アナログ→デジタル
Digitalization:デジタル化したデータの活用
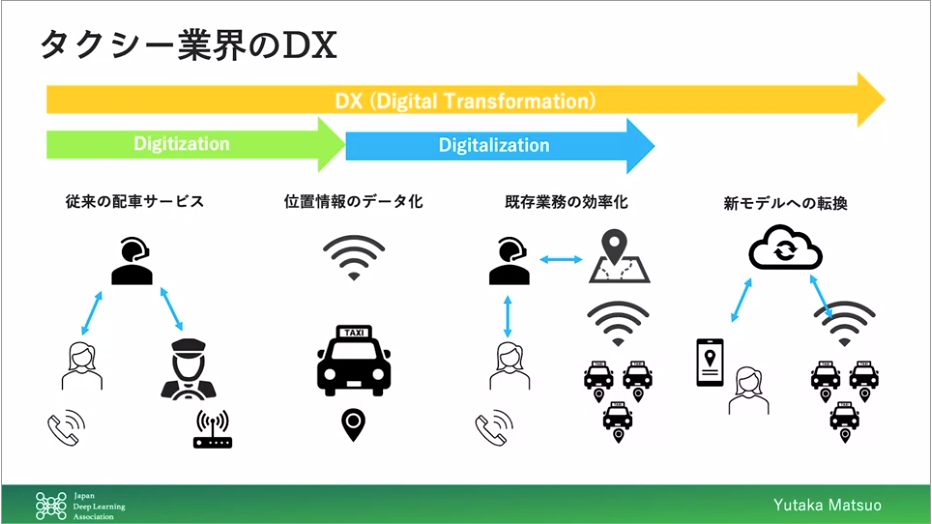
Digitization→Digitalizationが自然な移行だが、
いきなりDigitalizationされたソリューションが出てくることもある
例:タクシーに対するUber、小売店に対するAmazonGoなど
・DXにおけるAI/DLの重要性
これまでデジタル化が難しかった情報がAIによってデジタル化出来るようになってきた
AIによって出来ることが増えた
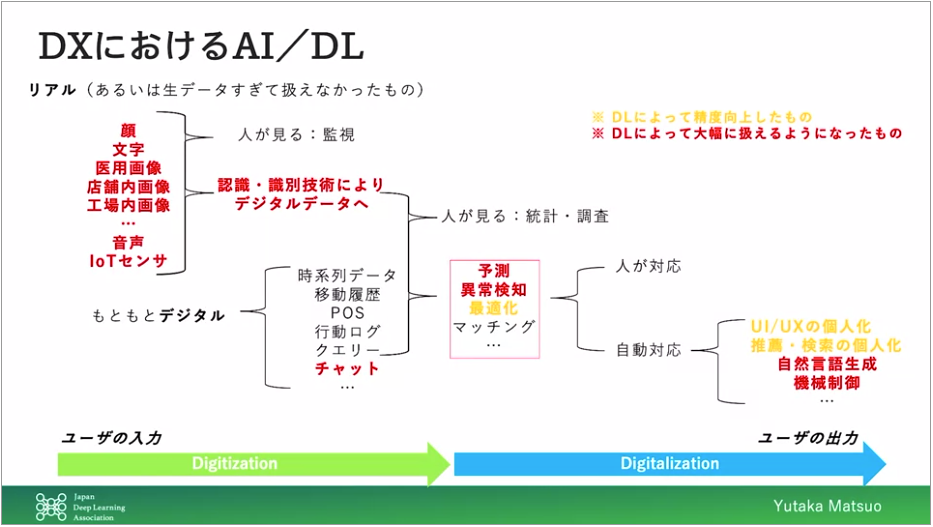
マクロに見れば自動化されていく
サプライ側とデマンド側が近く短くなる
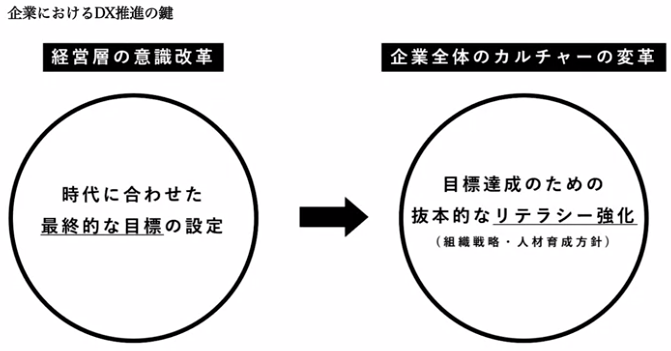
経営層の意識改革が重要、抜本的なリテラシー向上
・イントロダクション
ANI:特化型人工知能 →今はほとんどこっち
AGI汎用人工知能 →人ができることをすべてやる、こっちはまだまだ
・機械学習とは?
入力Aに対し出力Bを出す→「教師あり学習」
AからBへのマッピング
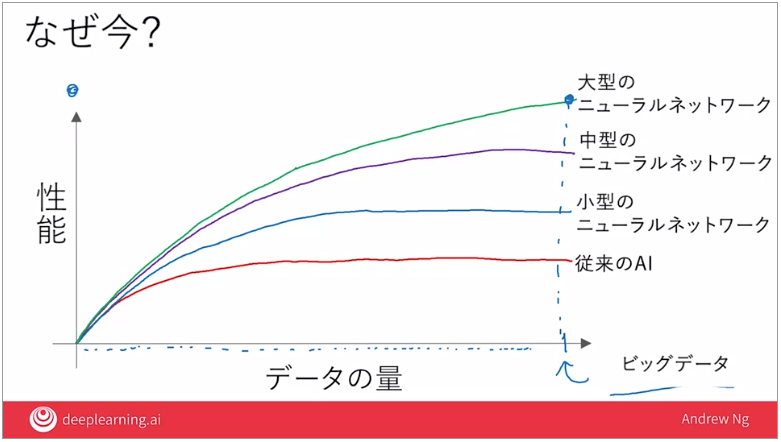
1.デジタルデータの総量が増えた
2.大型のニューラルネットワークを学習→相対的に質が上がる
・データとは?
データセット(表データ)
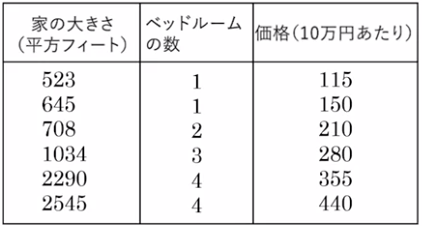

どうやってデータを集めるか?
1.手動でのラベリング →一つ一つのデータに自分でラベリング
2.行動の観察 →状態や結果を観察して自動的に取得
3.Webからダウンロードorパートナーから取得 →既存のデータセットを入手する
データの正しい使い方
データをたくさん集めてからAIチームに投げるのではなく、
ITチームで集めたデータをすぐにAIチームに投げ、フィードバックをもらう方がよい
AIチームにデータだけを丸投げしない
「ゴミを入れれば、ゴミしか出てこない」
データの問題
ラベルの間違い
欠損値が含まれる(Unknown)
データの種類
非構造化データ →画像、音声、テキスト(人間が理解しやすいもの)
構造化データ →表データ(巨大なスプレッドシートなど)
・AIにまつわる専門用語
機械学習とデータサイエンス
機械学習:明確にプログラムとして記述しなくてもコンピューターに学習させる能力を与える研究分野
データサイエンス:データから知識と洞察を抽出する分野
ディープラーニングとは
人工ニューラルネットワークに入力Aを入れる
ニューラルネットワークとディープラーニングはほぼ同義で使われる
・AI企業にするには?
インターネットの台頭から考える
インターネット企業とは?
→ショッピングモール+Webサイト≠インターネット企業
インターネット企業=インターネットを使うと非常にうまくできることをする企業
A/Bテスト、短いサイクル、意思決定がエンジニアや専門的な役職に委譲される
ではAI企業とは?
同じことが言える
→ある企業+ディープラーニング≠AI企業
AI企業=AIを使うとうまくできることをする
戦略的なデータの取得、単一のデータウェアハウス、多岐にわたる自動化、新しい役職(MLE)や分業
AIトランスフォーメーション(5ステップ)
1.パイロットプロジェクトの実施 →重要、まずはAIが出来ること/出来ないことを実際に試して理解する
2.社内チーム組成
3.トレーニング実施
4.AI戦略策定
5.社内外へのコミュニケーション
・機械学習で出来ること、出来ないこと
AIの論文などは出来ることを発表しているので、出来ないことや失敗事例が見えない
教師あり学習
1秒で判断できることは、おそらく自動化できる
長い文章を考えたり、小規模のデータセットで複雑な文章を出力したりは難しい
機械学習の問題をより容易にするもの
1.「単純な」概念の学習
2.大量の利用可能なデータ →入力Aと出力Bのセットで必要
・機械学習で出来ること、出来ないこと(実例)
自動運転車
出来ること:カメラで他の車をとらえる
出来ないこと:歩行者などの車へのジェスチャーから意図を認識する
どちらも同数のデータがあるとした場合、ジェスチャーは相対的にデータが不足する
また、結果の出力についても高い精度が必要になる
X線診断
出来ること:1万枚のラベリングされた画像から肺炎かどうか診断する
出来ないこと:医学の教科書の肺炎を説明している章の10枚の画像から肺炎を診断する
10枚の画像だけでは判断できない、人間は同時に文章なども理解できるがAIには出来ない
・ディープラーニング概要(パート1)
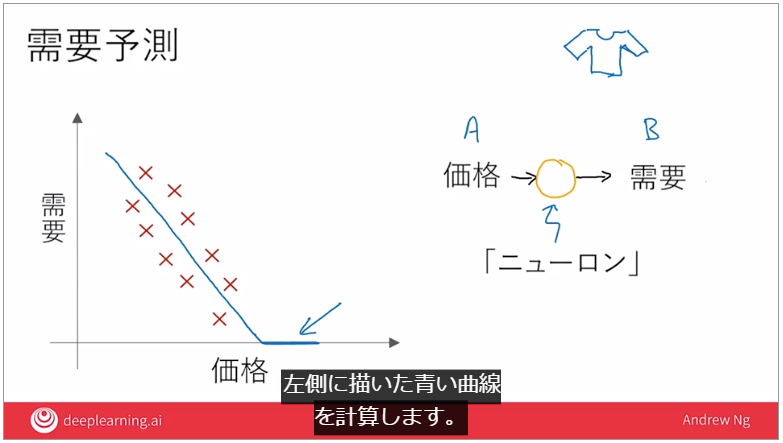
ニューロンとは
例:Tシャツの価格と需要のグラフ
→この価格に対して需要を出力する間にあたるものが「ニューロン」
価格需要比のグラフの場合、ニューロンは↓の青い曲線を計算する
要素が複数ある場合、この組み合わせパターンが増えていく
また、組み合わさった結果のニューロン同士をさらに組み合わせたニューロン、
という形でニューロンからニューロンが作られ、最終的に出力される
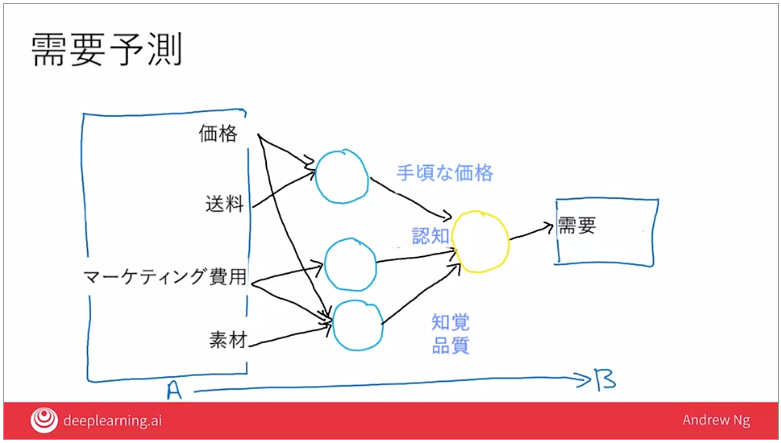
ここでポイントとなるのは、ニューラルネットワーク構築に必要となるのは「入力Aと出力Bのみ」。
上記の例では左側の4つのデータ(実際には大量のデータ=入力A)、
そして最終的に出力される需要=出力B、のみ。
「手頃な価格」「認知」などの中間にある要素はすべて自分で学習し見出すことが出来る。
青いニューロンが何を計算すべきかを把握するのはソフトウェアの仕事。
それぞれは単純な関数だが、それをたくさん組み合わせると複雑な関数が計算でき、
入力Aから出力Bへの非常に正確なマッピングを作り出すことが出来る。
・ディープラーニング概要(パート2)
顔認識
AIは何を基準に判別しているか?
→ピクセル単位で明るさなどを数値化する
モノクロの場合は一つだが、カラーの場合はRGBの三つでそれぞれ明るさを数値化する
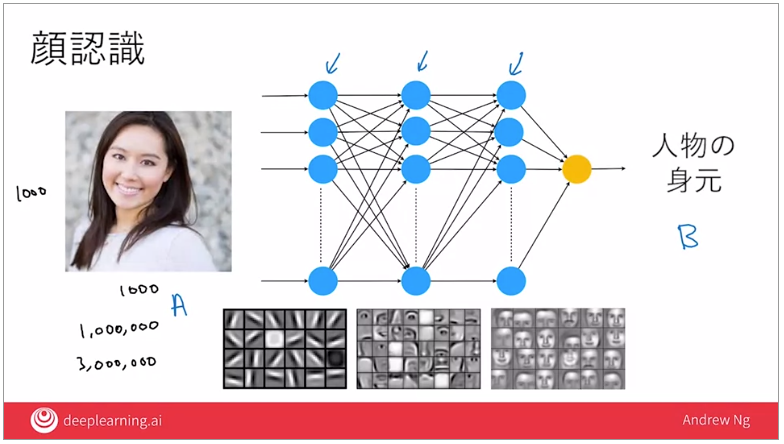
画像が1000x1000ピクセルの場合、グレーで100万ピクセル、カラーで300万ピクセルの値が入力A
出力Bは人物の身元(例えばIDなど)となるが、その中間のニューロンについては前述の通り自動で学習される
通常の学習の進行としては、初期のニューロンではまず画像のエッジを検出することを学び、
それから少ししてオブジェクトの一部(目や鼻などのパーツ)を検出することを学習する。
その後さらに、顔の様々な形を検出することを学ぶ。
最後にこれら全てを組み合わせて、画像の人物の身元(ID)を出力する。