※ 2021/01/04 NVIDIA Ampere アーキテクチャの A40、RTX A6000、GeForce RTX 30 シリーズを追記
※ 2020/06/11 NVIDIA Ampere アーキテクチャの発表に伴い一部更新。
※ 2020/02/24 Google さんのブログで混合精度演算が取り上げられたので、その記事への参照を追加するなどしました。
エヌビディアの佐々木です。
ニューラルネットワークのトレーニングに Volta アーキテクチャ以降の (つまりわりと新しい) GPU をご利用の方は、 Tensor コアによる混合精度演算をぜひ活用してください。Automatic Mixed Precision 機能を使えば既存のモデルを修正する必要がほぼなく、しかし場合によっては 3 倍くらい速くなるかもしれません。詳細はこちら → Automatic Mixed Precision for Deep Learning
と、これだけで終わるのも何なので以下、説明します。
混合精度トレーニング
Mixed Precision Training という Baidu Research と NVIDIA による論文があります。この中では、従来ニューラルネットワークのモデルで一般的に利用されてきた 32 ビットの単精度浮動小数点数 (FP32)に代えて、半分の 16 ビット幅で表現される半精度浮動小数点数 (FP16) を使っても、いくつかの工夫を加えることでモデルの正確度をほぼ落とすことなく、トレーニングを高速化できることが示されています。
FP32 の代わりに FP16 でモデルが表現できるとなれば、当然必要なメモリサイズは半分になり、その分バッチサイズを大きくできますし、ネットワーク越しに重みをやりとりする際の帯域も節約できます。そして、それだけではないのです。先の論文の Introduction にこんな一節があります:
half-precision math throughput in recent GPUs is 2× to 8× higher than for single-precision.
最近の GPU では、FP16 の演算スループットが FP32 の 2 倍から 8 倍高い
そうなんです。この「2 倍」は Pascal アーキテクチャで導入された、「FP32 演算器に FP16 の数値を 2 個詰め込んで一度に演算する」機能で、例えば NVIDIA P100 SXM2 では FP16 の演算性能 (21.2 TFLOPS) が FP32 (10.6 TFLOPS) の 2 倍になっています。そして、ここからがこの記事の本題ですが**「FP32 の 8 倍」**という大幅な性能アップを実現するのが、 Volta アーキテクチャで導入された Tensor コア (てんさーこあ) です。
Tensor コア使ってますか?
Tensor コアは、ニューラルネットワークのトレーニング高速化を主な目的とした追加された行列演算ユニットで、Volta 世代以降の GPU で性能を引き出すために不可欠な要素です。例えば NVIDIA V100 SXM2 の「125 TFLOPS」は Tensor コアを使った FP16/FP32 の混合精度演算性能であり、FP32 の 15.7 TFLOPS とは 8 倍の差があります。そう、先ほど引用した "8× higher than for single-precision" とはこのことです。
また、2020 年 5 月に発表された NVIDIA A100 GPU の新しい Tensor コアでは、FP32 の 19.5 TFLOPS に対して 312 TFLOPS と、その差は実に 16 倍に拡大しています。
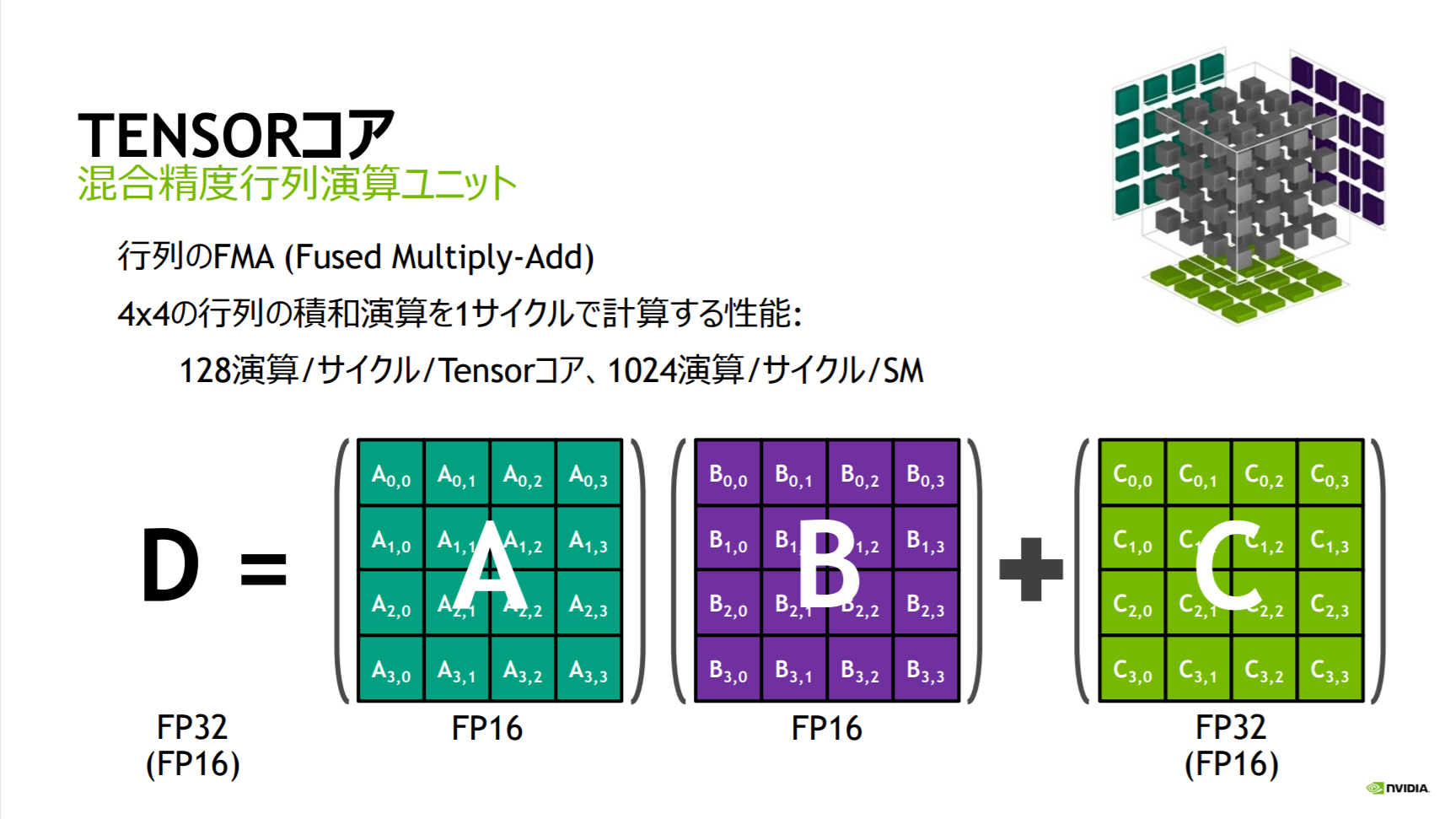
出典: VOLTA AND TURING: ARCHITECTURE AND PERFORMANCE OPTIMIZATION - エヌビディア成瀬, GTC Japan 2018
Tensor コアは今のところ (2020 年 6 月現在) 下記の NVIDIA (Volta / Turing / Ampere) アーキテクチャ GPU に搭載されています。
- NVIDIA Volta (ぼるた) アーキテクチャ
- NVIDIA Turing (ちゅーりんぐ)アーキテクチャ
- NVIDIA Ampere (あんぺあ) アーキテクチャ
しかし、せっかくこれらの GPU を使っていても、Pascal アーキテクチャ以前のプログラムをそのまま動かすだけでは、おそらく **Tensor コアは眠ったまま!**です。もったいないお化けが出そうですね。どんどん Tensor コアを使っていきましょう。そのためのオススメ機能が、この記事で紹介する Automatic Mixed Precision (AMP) です。
Automatic Mixed Precision (AMP)
前述の通り Tensor コアは FP16 に対する演算を行いますから、既存のモデルで Tensor コアを活用するためには、FP32 で表現されている数値を FP16 に変更する必要があります。しかし、FP16 は FP32 と比較して表現できる値の範囲がかなり狭いため、単に FP32 を FP16 に置き換えるだけではモデルの正確度を維持できません。Mixed Precision Training の論文では、モデルを FP16 化しても正確度を落とさない方法として、次の 3 つの工夫が挙げられています。
- (モデルを FP16 化しつつも) 重みのマスターコピーは FP32 で保持
- ロス スケーリング (勾配の値がアンダーフローして 0 になってしまう避けるために、順伝播の結果得られた損失関数の値を数倍してから逆伝播を行う)
- FP16 行列の積和演算において、加算は FP32 で行う
Automatic Mixed Precision (AMP) 機能は、このうち 1. と 2. を自動的に行ってくれます。そして、3. は Tensor コアがまさにその機能を持っています。
NGC のコンテナーイメージで AMP を試してみる
論より証拠、AMP の動作を試してみましょう。今のところ TensorFlow, PyTorch, MXNet が AMP に対応しています。NGC から新しめのコンテナーイメージを持ってくるのが一番簡単です。
TensorFlow
NGC の TensorFlow イメージは、19.03 版以降で AMP に対応しています。
※ TensorFlow 1.14 から、アップストリームのコードにも AMP が取り込まれました。
今回は、最新の 20.03-tf2-py3 版を使ってみようと思います。TensorFlowのバージョンは 2.1.0 です。(この記事の最初の版では、19.06 版を使用していましたが、現状に合わせて記事を更新しています)
次のコマンドで、コンテナーを起動します。
$ docker run --gpus all --rm -it nvcr.io/nvidia/tensorflow:20.03-tf2-py3
※ Docker で GPU を使う準備ができていない方は、こちらの記事を参照の上ご準備ください。
コンテナー内の /workspace/nvidia-examples/ 配下に様々なサンプルプログラムがありますが、今回は画像分類モデルの ResNet50 をトレーニングするスクリプトである /workspace/nvidia-examples/cnn/resnet.py で AMP の効果を試してみます。19.06 のコンテナーイメージに含まれていた /workspace/nvidia-examples/resnet50v1.5/main.py に相当するものですが、コマンドラインオプションなどが少し変わっています。例えば、以前のスクリプトでは --mode=training_benchmark を指定することで、データセットの準備不要な (実行時に乱数で生成する) ベンチマークモードで実行できましたが、今回の resnet.py では --data_dir オプションの指定を省くことでベンチマークモードになります。
まずは AMP 無効で実行
まず、ベースラインとして、AMP を有効化せずに実行してみます。コマンドは次のとおりです。
このスクリプトでは、 --precision オプションの指定で AMP の有効・無効を指定でき、 この値が "fp16" の場合以外は AMP が無効になります。ここでは、32 ビットの単精度浮動小数点数 (FP32) が使われることをわかりやすく示すために "fp32" を指定しています。
/workspace/nvidia-examples/cnn/resnet.py \
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=80 \
--precision=fp32
バッチサイズが 80 になっているのは、私の環境でいろいろ試した結果このあたりが上限だった、という値です。
結果は以下のようなもので、最初の 10 ステップ以外を平均すると、秒間画像処理数が 212 枚といったところです。
global_step: 10 images_per_sec: 41.7
global_step: 20 images_per_sec: 219.5
global_step: 30 images_per_sec: 218.3
global_step: 40 images_per_sec: 213.3
global_step: 50 images_per_sec: 195.7
global_step: 60 images_per_sec: 192.5
global_step: 70 images_per_sec: 212.4
global_step: 80 images_per_sec: 216.0
global_step: 90 images_per_sec: 215.3
global_step: 100 images_per_sec: 215.5
AMP を有効化する
では、AMP を有効化してみましょう。先程のスクリプトに、 --precision=fp16 オプションを与えます。
/workspace/nvidia-examples/cnn/resnet.py \
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=160 \
--precision=fp16
バッチサイズは 160 まで増やすことができ、結果は以下のようなものでした。
global_step: 10 images_per_sec: 102.1
global_step: 20 images_per_sec: 540.2
global_step: 30 images_per_sec: 549.0
global_step: 40 images_per_sec: 546.9
global_step: 50 images_per_sec: 546.2
global_step: 60 images_per_sec: 545.5
global_step: 70 images_per_sec: 545.8
global_step: 80 images_per_sec: 545.5
global_step: 90 images_per_sec: 544.5
global_step: 100 images_per_sec: 543.9
行間画像処理数の平均は、545 枚程度と、AMP 無効時の約 2.6 倍に向上しました。
--precision=fp16 オプションによって実際にどのようなコードが実行されているか、言い換えれば、既存のコードをどう変更すれば AMP を有効にできるかは、/workspace/nvidia-examples/cnn/nvutils/runner.py の 141 行目あたりをご覧ください。(見やすくするために改行位置を修正しています)
if precision == 'fp16':
policy = keras.mixed_precision.experimental.Policy('mixed_float16', loss_scale)
keras.mixed_precision.experimental.set_policy(policy)
簡単ですね!
なお、Policy のコンストラクタの第 2 引数にある loss_scale のデフォルト値は "dynamic" ですが、このサンプルでは /workspace/nvidia-examples/cnn/resnet.py の中で ”128.0” が与えられています。動的に調整するより、決め打ちにしたほうが、やはり少し速いようです。
※ Keras からではなく TensorFlow を直接使う場合は、 tf.train.experimental.enable_mixed_precision_graph_rewrite() をご利用ください。
PyTorch では?
PyTorch の場合 NVIDIA が開発している APEX というライブラリが AMP の機能を提供しています。NGC の PyTorch コンテナーイメージ (19.04 版以降) には APEX が含まれており AMP をすぐに利用できます。/workspace/examples/apex/imagenet/main_amp.py から関連する部分をちょっと抜き出してみましょう。コメントは私が説明のために付けたものです。
# APEX から AMP をインポートして
from apex import amp, optimizers
# AMP を初期化して
model, optimizer = amp.initialize(model, optimizer, opt_level=args.opt_level, keep_batchnorm_fp32=args.keep_batchnorm_fp32, loss_scale=args.loss_scale)
# ロススケーリングして逆伝播
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
簡単ですね!
MxNet では?
MXNet でも NGC コンテナーイメージの 19.03 以降で AMP に対応しており、また最近 (2019年7月末) リリースされた MXNet 1.5.0 からは AMP が本体に取り込まれています。設定方法は PyTorch とほぼ同様です。NGC の MxNet イメージ 内の /workspace/examples/gluon/image-classification/train_imagenet.py をちょっと見てみましょう。
# AMP をインポートして
import mxnet.amp as amp
# 初期化して
amp.init()
amp.init_trainer(trainer)
# ロススケーリングして逆伝播
with amp.scale_loss(Ls, trainer) as scaled_loss:
ag.backward(scaled_loss)
やっぱり簡単ですね!
Tensor コアを活用する多くのサンプルプログラム
NVIDIA Deep Learning Examples for Volta Tensor Cores には Tensor コアの性能を引き出すサンプルプログラムがたくさん用意されています。こちらもぜひご覧ください。
例えば、Mixed Precision Training of CNNは TensorFlow で AMP を使い CIFAR10 データセットでの画像分類トレーニングを高速化する例です。また、PyTorch による Transformer のトレーニング では APEX を使った混合精度演算で 4 倍以上の高速化が達成されています。
[補足] Pascal 以前の GPU で実行したら?
AMP を組み込んだコードを Tensor コアを持たない Pascal アーキテクチャ以前の GPU で実行した場合、AMP 機能の呼び出しがエラーとなることはありませんが、例えば下記のようなメッセージが出力され、モデルの FP16 への自動変換は行われません。当然、学習速度が向上することもありません。
No (suitable) GPUs detected, skipping auto_mixed_precision graph optimizer
また、AMP とは別の話ですが、 NGC のコンテナーイメージは Pascal アーキテクチャ以降の GPU を正式サポートしています。そのため Kepler や Maxwell 世代の GPU では実行できないイメージがある点にご留意ください。
まとめ
NVIDIA A100, V100, T4, TITAN RTX, GeForce RTX 20 系などの比較的新しい GPU をご利用の方、 Tensor コアが眠っていませんか?ぜひ、混合精度演算でニューラルネットワークのトレーニングを高速化しましょう。NGC のコンテナーイメージと Automatic Mixed Precision (AMP) 機能で手軽に始めるのがお勧めです。
関連情報
- Mixed Precision Training - Baidu Research, NVIDIA (ICLR 2018)
- Automatic Mixed Precision for Deep Learning - NVIDIA Developer サイト
- Automatic Mixed Precision for NVIDIA Tensor Core Architecture in TensorFlow
- Using AMP (Automatic Mixed Precision) in MXNet
- NVIDIA Deep Learning Examples for Volta Tensor Cores
- VOLTA AND TURING: ARCHITECTURE AND PERFORMANCE OPTIMIZATION - エヌビディア成瀬, GTC Japan 2018
- VOLTA Tensor コアで、高速かつ高精度に DL モデルをトレーニングする方法 - エヌビディア成瀬, GTC Japan 2017
- Chainer で Tensor コア (fp16) を使いこなす - エヌビディア成瀬, Chainer Meetup #8
- Volta は、Chainer で使えるの? - エヌビディア成瀬, Chainer Meetup #6
- High performance inference with TensorRT Integration
- Your ML workloads cheaper and faster with the latest GPUs
- NVIDIA A100 Tensor Core GPU Architecture
- Inside the NVIDIA Ampere Architecture [S21730]