背景
dataframeをndarrayへと変換した後、分散教分散行列を求める方法が調べても見つからなかったため、以下に方法を示す。
(見つからなかっただけで、絶対にどこかの記事に書いてあると思う...)
分散共分散行列
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9])
y = np.array([9,8,7,6,5,4,3,2,1])
上記のデータxおよびyの分散共分散行列はどのように求めることができるだろうか。
np.cov(x,y)
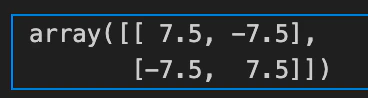
上記の通り書くことで分散共分散行列を求めることができる。
では、一方で以下のようなデータの場合どうだろうか。
X = np.vstack((x,y)).T
X

xとyをそれぞれ列に持ち、各行に値が格納されている場合だ。
(単純にDataFrameと同じ構造だと思って欲しい)
先ほどと同様に以下の通りプログラムを動かしてみる。
np.cov(X)
この場合9x9の行列が返ってくる。
(コメントでこの行列が何をしてしているのか教えて欲しい...)
/*以下追記
@WolfMoon さん、ありがとうございます。
これはcov関数の引数「rowvar」がデフォルトでTrueであり、
この場合行を変数として認識してしまう。
そのため、9個の変数を持つと認識し、9x9の行列が作成されてしまう。
以下のように記載することで、正しく分散共分散行列を求めることもできる。
np.cov(X, rowvar=False)
*/
これはXが9x2の行列のため、9x9の行列が返ってきてしまっている。
では、以下のように書いてみたらどうだろうか。
np.cov(X.T)
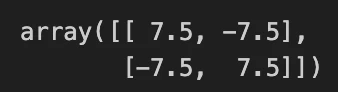
問題なく求めることができたようだ。
まとめ
dataframeと同様の構造を持つndarrayより分散共分散行列を算出する場合は、
np.cov(X.T)のように、転置した行列をcov関数の引数に格納するようにすれば良い。