はじめに
「最近眠りが浅いような気がする」的なことを友人に相談したら、この前**「幸せに眠れるティー」**なるものをもらったのでその効果を検証してみました。Qiitaらしくはないかもしれませんが、まぁお付き合い下さい。

実験手順
もらったティーバックは全部で8個あったので、ハーブティーを飲んだ時と飲まない時合計16日間の睡眠を測定してその効果を検証しました。
睡眠の測定にはUP by Jawbone(つい先日破産してしまったようですが)を使いました。これを寝る前に付けると睡眠時間、入眠までに要した時間、覚醒時間、目覚めた回数、深い眠りの時間、浅い眠りの時間を専用のアプリで返してくれます。覚醒時間というのは眠りに入ったものの中途覚醒状態と判定された時間です。今回検証したいのが「眠りが浅い」現状をハーブティーで改善できるか、なので睡眠効率を
睡眠効率=\frac{睡眠時間ー覚醒時間}{睡眠時間}
と定義して、これがティーを飲んだ時と飲まない時で変化するかを見ていきます。
今回は対象期間を16日で設定したのでアプリからのデータは手作業でcsvファイルに入力しました。
以前jawboneから詳細な睡眠データを取り出すツールも開発したことがあったのですが、今回はマクロなデータをとりたかったのでこのような形にしました。
解析手順
2条件の比較なので普通にt検定してもいいのですが、自分の勉強も兼ねて今回はあえてベイズ統計で仮説を検証することにしました。使用したツールはpystanでモデルコードは以下のとおりです。
data {
int<lower=0> n1;
int<lower=0> n2;
vector[n1] x;
vector[n2] y;
}
parameters{
real mu_x;
real mu_y;
real<lower=0> sigma_x;
real<lower=0> sigma_y;
}
transformed parameters{
}
model {
x ~ normal(mu_x, sigma_x);
y ~ normal(mu_y, sigma_y);
}
generated quantities {
real diff;
real u;
diff = mu_x - mu_y;
u = diff > 0 ? 1:0;
}
具体的には各群に正規分布を仮定して平均を推定、その後、x>yという仮説を生成量uで評価しています。
モデルの構造は関西学院大学の清水先生の「Stan超初心者入門」を参考にしました。
結果
まず最初にお詫びがあります。飲まない条件は8日間コンプリートしたのですが、飲む条件は8日間のうち3日間睡眠トラッカーを付け忘れてしまいました。なのでデータは全部で13サンプル、しかも条件ごとにデータの偏りがあります。以下、ご注意下さい。
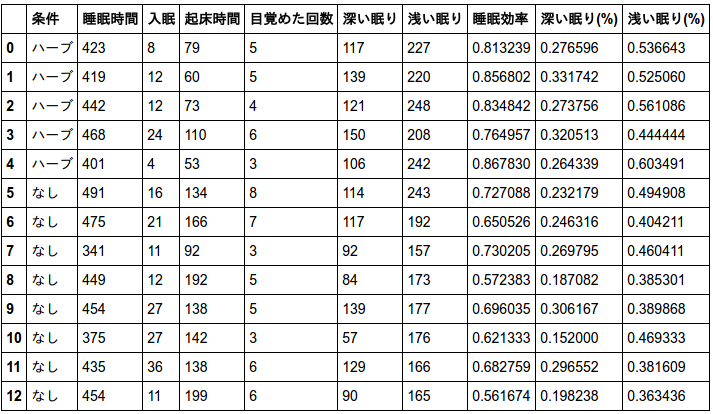
まずは記述統計です。
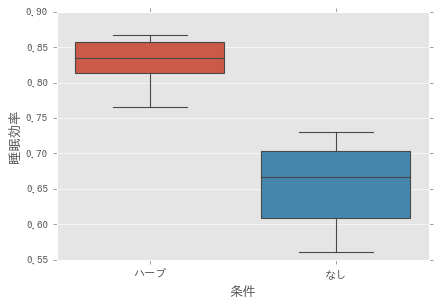
睡眠効率
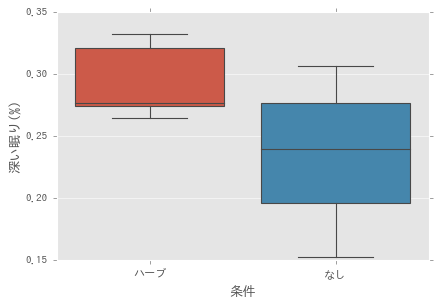
深い睡眠の割合
次に睡眠効率についてstanモデルによる検定の結果です。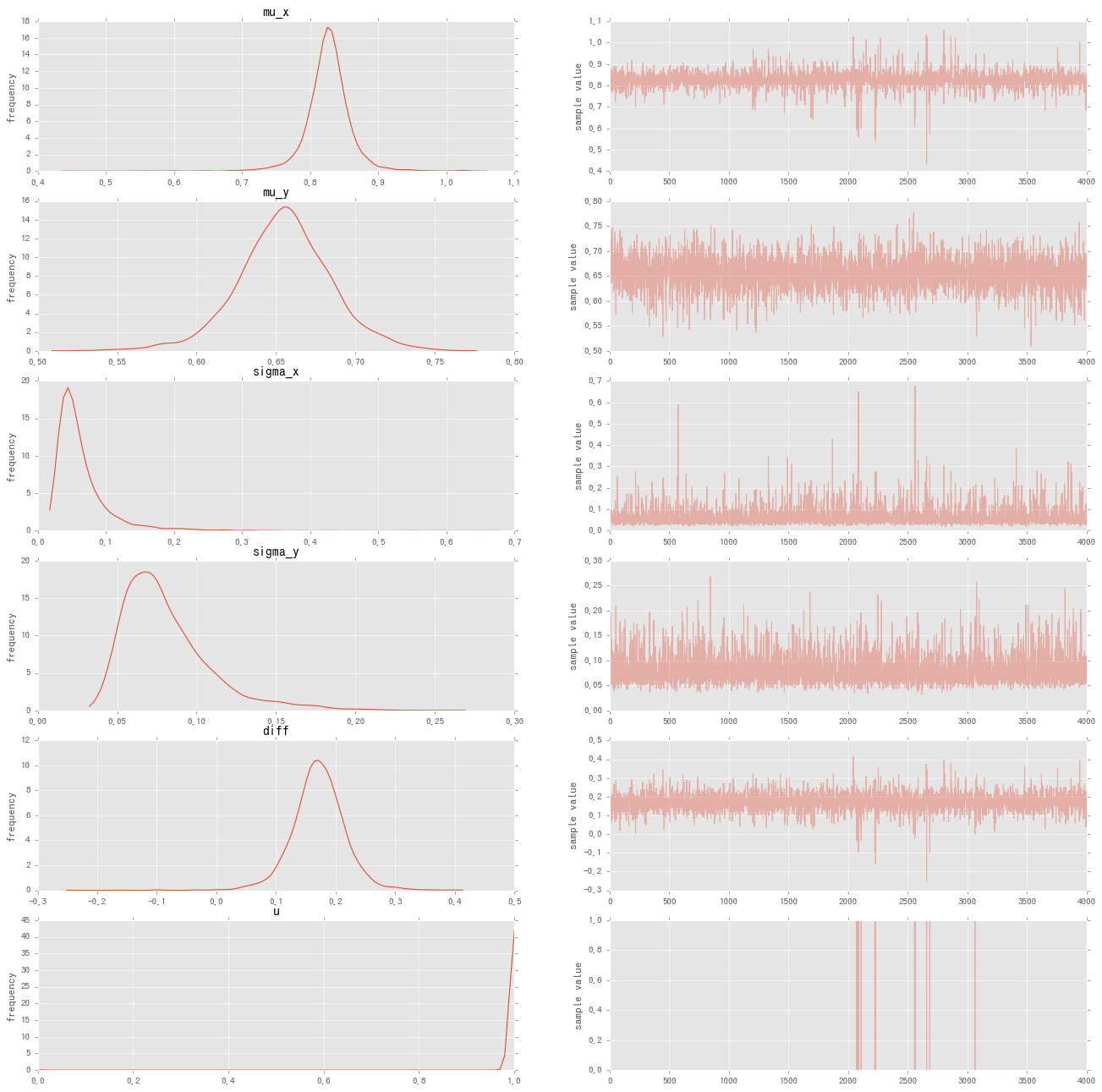
なんと幸せに眠れるハーブティーを飲んだ時のほうが飲まない時よりも睡眠効率が高い可能性が高いという結果が出ました(p<.01)。あまりにも結果がきれいなので調べた自分が一番驚いています。
感想
今回は単にベイズ統計の練習という意味合いでやってみたのですが、幸せに眠れるハーブティー、まじで効果があるかもしれないですね。興味のある方は試してみてはいかがでしょうか。
今回の分析に使ったコードはGistに公開しています。こちらもよければご覧ください。