はじめに
- ちょっとOCRを試してみたいなと思っていたところ、EasyOCRというPythonパッケージを見つけた
- 環境構築や認識する言語の切り替えがお手軽に出来、非常に使いやすい
- 日本人だけが読めないフォントはどう認識するのか、ふと気になり試してみた
- ソースコードはこちら
- ※後から調べて分かったが『日本人「だけ」読めないフォント』が本当に日本人だけ読めないのか、ニューラルネットの力を借りて確認してみたという記事が既にある。本記事はこのEasyOCR版だと思って頂ければ...
EasyOCR
そもそもOCRとは?
- Optical Character Recognitionの略
- ざっくり画像から文字を抽出して認識する技術と理解している
Electroharmonix
- 日本人だけが読めないフォントと言われているフォント
- ちなみに、下記の画像は
モレモコヤロカムヤ巾ロウエメElectroharmonixと書いてある - 記号とかはあるけど、大文字だけで小文字はなさそう

(出典: Electroharmonix)
検証方法
- 下記のフォント使って「Hello, Wolrd」と書かれた画像を生成する
- electroharmonix
- IPAex明朝
- IPAexゴシック
- EasyOCRで以下の言語を指定して文字認識を実行する
- 英語
- 日本語
- 日本語&英語
- EasyOCRの出力した文字列から考察を行う
実装
実装といってもテキスト画像生成がメイン
事前準備
- electroharmonixを含むいくつかのフォントを比較用にインストールしておく
- 今回は比較用にIPAexフォントもダウンロードした
- 必要パッケージのインストール
Pillowを用いた画像生成
主な処理は以下の通り
- フォントサイズ: 48, 文字色: 黒, 背景色: 白に設定
- 指定したフォントでテキストを書いた時の領域(幅、高さ)を算出
- パディングが全体のテキスト領域の10%になるように画像サイズ、テキスト表示位置を設定
@dataclass
class TextImageGenerator:
font_filepath: str = "fonts/ipaexg.ttf"
fontsize: int = 48
px_ratio: float = 0.1
py_ratio: float = 0.1
def generate(
self,
text: str,
color: Color = (0, 0, 0),
bg_color: Color = (255, 255, 255),
) -> Image:
# fontを取得
font = self._get_font()
# 生成画像のサイズ、テキストの左上位置を取得
canvas_size, text_tl = self._get_canvas_size(text, font)
# 下地となるImageを作成
img = self._get_canvas(bg_color, canvas_size)
# 文字を描画
draw = ImageDraw.Draw(img)
draw.text(text_tl, text, fill=color, font=font)
return img
def _get_canvas_size(self, text: str, font: ImageFont.FreeTypeFont) -> Tuple[Tuple[int, int], Tuple[int, int]]:
text_width, text_height = ImageDraw.Draw(Image.new("RGB", (200, 200))).textsize(text, font)
width = int(text_width * (1 + 2 * self.px_ratio))
height = int(text_height * (1 + 2 * self.py_ratio))
text_top_left_x = int(width * self.px_ratio / (1 + 2 * self.px_ratio))
text_top_left_y = int(height * self.py_ratio / (1 + 2 * self.py_ratio))
return (width, height), (text_top_left_x, text_top_left_y)
def _get_canvas(self, bg_color: Color, canvas_size: Tuple[int, int]) -> Image:
return Image.new("RGB", canvas_size, bg_color)
def _get_font(self) -> ImageFont.FreeTypeFont:
return ImageFont.truetype(self.font_filepath, self.fontsize)
EasyOCRを用いた各フォント、言語での文字認識
主な処理は以下の通り
- 生成画像に対してEasyOCRで文字認識を実行する
- 認識した領域ごとに分割されてしまうため、全ての領域の結果を抽出する
- 上記の処理をフォントごと、言語ごとに行う
結果
画像生成結果とOCRの認識結果は下記の通り
画像生成結果
electroharmonix

IPAex明朝
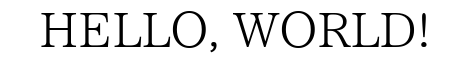
IPAexゴシック
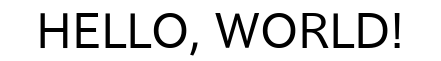
OCR認識結果
| フォント | 言語 | 結果 |
|---|---|---|
| electroharmonix | 英語 | bELLA; WARlDi |
| electroharmonix | 日本語 | カモレレロ,山口ポレワ』 |
| electroharmonix | 英語&日本語 | カモレレロ,山口ポレワ』 |
| IPAex明朝 | 英語 | HELLO, WORLDI' |
| IPAex明朝 | 日本語 | チ__0, 0♪_」 |
| IPAex明朝 | 英語&日本語 | HELLO,VORLD」 |
| IPAexゴシック | 英語 | HELLO, WORLDI |
| IPAexゴシック | 日本語 | んヒ__0一0二_! |
| IPAexゴシック | 英語&日本語 | HELLOWORLD! |
考察
- electroharmonix
- 英語としても結構外れてる...
- 日本人らしい認識だなぁ、一点気になるはヤじゃなくてポって読むのね
- ロ(ろ)と口(くち)を分けてるところも日本人らしくて個人的にビックリした
- 英語入れても日本語と一緒
- IPAex系
- 日本語として読めないのはまぁ分かる
- 英語でも惜しいけど100点ではない「!」と「I」の違いって確かに結構難しい
まとめ
- 他の記事でもみられるように、そもそも英語圏の人でも読みやすいフォントではなさそう
- ただ、思ったよりも日本人寄りの認識結果だった