とりあえずColabのノートブックはこちら。
Radviz とは
Radvizは多次元データを低次元(自分が知る限り2Dもしくは3D)でプロットする可視化手法だ。
pandasを用いると簡単にRadvizを作ることができる。
下記は https://pandas.pydata.org/docs/reference/api/pandas.plotting.radviz.html ほぼそのまんまのコードとその結果だ。
import pandas as pd
df = pd.DataFrame(
{
'SepalLength': [6.5, 7.7, 5.1, 5.8, 7.6, 5.0, 5.4, 4.6, 6.7, 4.6],
'SepalWidth': [3.0, 3.8, 3.8, 2.7, 3.0, 2.3, 3.0, 3.2, 3.3, 3.6],
'PetalLength': [5.5, 6.7, 1.9, 5.1, 6.6, 3.3, 4.5, 1.4, 5.7, 1.0],
'PetalWidth': [1.8, 2.2, 0.4, 1.9, 2.1, 1.0, 1.5, 0.2, 2.1, 0.2],
'Category': [
'virginica',
'virginica',
'setosa',
'virginica',
'virginica',
'versicolor',
'versicolor',
'setosa',
'virginica',
'setosa'
]
}
)
pd.plotting.radviz(df, 'Category', color=['red','green','blue'])
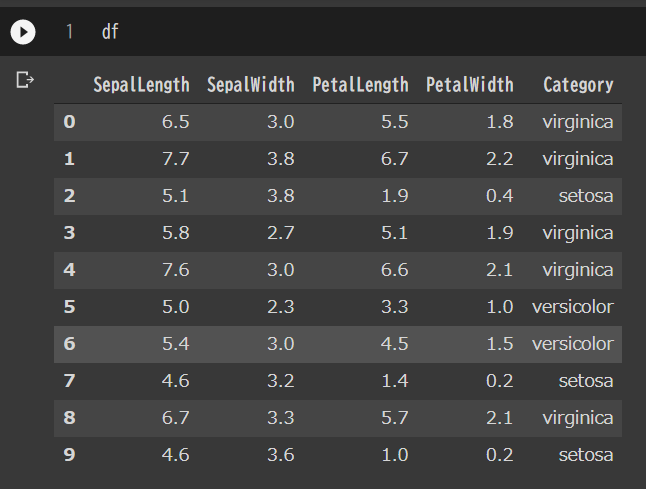

SepalLength、SepalWidth、PetalLength、PetalWidth 近くに点があるがこれらはデータ点ではないので気をつけてほしい。Radvizは
- setosaのカテゴリーのirisは、SepalWidthのデータが他の列と比較して突出して大きい特徴がある
- virginicaのカテゴリーのirisは、setosaのような突出した特徴が無い
ことを示している。
Radviz が可視化するものの確認
によると 「n 個の次元をアンカーとして円周上に配置する。データ点と各アンカーがバネで結ばれているとし、バネの力が釣り合う座標にデータ点を配置する。それぞれの次元において、値が大きいとバネの力を強く、値が小さいとバネの力を弱くする。」
とある。これを先のpandasを用いた例で言いかえて確認していこう。
アンカーの配置
たしかに4次元(SepalLength、SepalWidth、PetalLength、PetalWidth)のアンカーが画像のように円周上に配置されている。
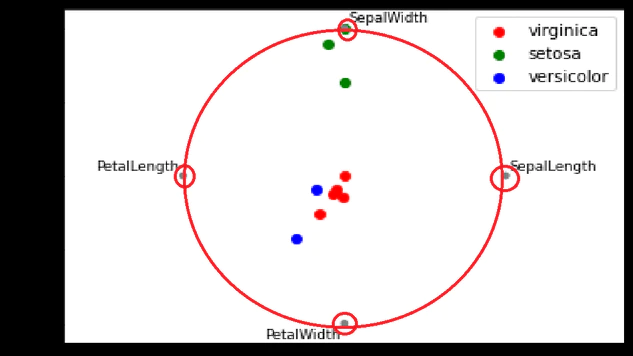
もし8次元のデータなら下記の点にアンカーが配置される
データ点の配置について
「値が大きいとバネの力を強く」が意味することは、アンカーの値が大きいと、アンカーに「近い」位置に点を打つ、ということである。円の中心近くに打つのではない。
ここで注意したいのは「単に」アンカーの値が大きい、ことを意味しているわけではなく「他のアンカーの値と比較して大きい」とアンカー近くに点を打つということだ。
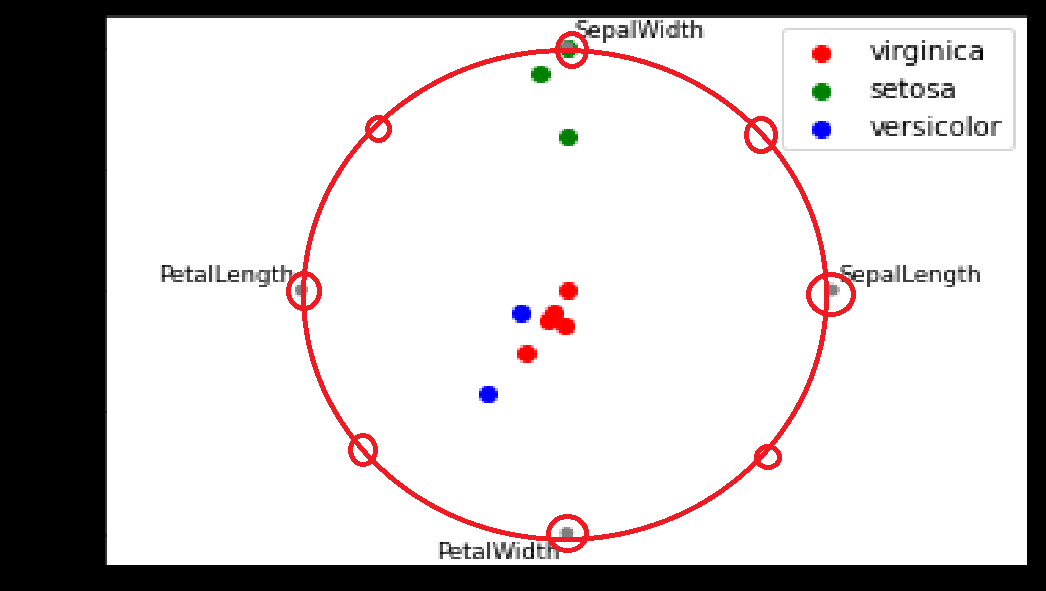
これを確認するために行indexが1の行を抜いてRadvizを作り直してみよう。行indexが1の行のSepalWidthは、行indexが2の行と同じ値「3.8」だが PetalLength、PetalWidthの値は抜群にデカい。

行indexが1の行を抜いてRadvizを作り直すとこうなる。
SepalWidthがその列の値としては最大の「3.8」の行を抜いたにも関わらず、Radvizから抜けた点は「SepalWidthのアンカー近くの点」ではなく「円の中心近くの点」であることがわかるだろうか?
つまり「抜いた点のirisは全体的にサイズがデカく、SepalLength、SepalWidth、PetalLength、PetalWidthのどこかの特徴が突出していたわけではない」からRadvizはそういうもんを真ん中に配置する、ということがわかる。
Radvizをさらに考える
ここであなたは「これアンカーの配置の仕方が重要では?」と思われたかと思う。
たしかにそのとおりだ。が私はその最適化方法をわかっていない。(さらに言うとバネの力についてもよくわかっていない。)
わかっていたら私にもわかる記事を書いて教えていただきたい。
(超尻切れトンボですんません!)