はじめに
プログラミング初心者がAIの画像認識を用いて、初のWebアプリを開発しました。
PCの知識は一般常識程度で、高校時代にExcelやWordを教わっただけで得意とはいえません。
職場でもPCの使用は簡単な文字入力程度です。
そんな初心者ですが、本気でがんばった結果精度98%のAIモデルの構築に成功しました。
その記録をここに残したいと思います。
このブログは長文になりますが、私と同じように未経験から本気でエンジニアを目指している方や、以前プログラミングに挑戦したけど挫折してしまった方など、多くの人に最後までお読みいただけたら幸いです。
自己紹介
山形県で暮らしている26歳女性です。
仕事は半導体の製造工場で外観検査の仕事をしております。
プログラミングをはじめたきっかけですが、昨年25歳のときに今後の人生を考えた際に、このままなにもスキルが身につかない仕事をしていてはよくないと感じていました。そんなときたまたま、Web系エンジニアで自由に働いている方を紹介しているブログを拝見し、エンジニアという職業に興味を持ちました。
それから、エンジニアになるためにはどうしたらいいかを調べ、未経験でも本気で頑張ればできるかもしれないと思い挑戦することに決めました。
しかし、プログラミングの知識は全くなく触ったこともなかったため、まずはProgateでRubyをメインに学習しました。毎日新しい知識が増え、できることが増えていくことに面白みを感じました。
その後、色々と調べていくうちにPythonに興味を持ちました。シンプルで分かりやすい構文と、AIにも使われる言語であることを知り、もっと難しいことに挑戦してみたいと思いAidemyのAIアプリ開発講座6ヶ月コースを受講しました。
そこで学んだ知識を活かして開発したアプリDelisearchを紹介していきます。
目次
アプリ開発の経緯
普段料理をする時に、いつもクックバッドやクラシルといったレシピサイトから、ひとつひとつ食材名で検索をして何を作るか決めています。
そこで、冷蔵庫に余ってる食材から、AIがレシピを考案してくれるアプリがあったら便利だろうなと思い開発に至りました。
理想は、冷蔵庫にカメラを取り付けAIが自動的に冷蔵庫内の食材全てを認識して判別し、アプリより各食材から作れる料理を、主菜や副菜、栄養バランスを考慮した献立まで提案してくれるアプリです。
ただ、今の私の技術ではそこまでは難しいので、まずは食材は野菜のみに限定し、簡単なレシピ提案アプリから開発しました。
アプリ名の由来は、delicious(美味しい) + search(検索)でDelisearchです。
美味しいレシピを検索して見つけてほしいとの思いを込めました。
開発環境
MacBook Air 13 M2
Google Colaboratory
Visual Studio Code
HTML & CSS
JavaScript
Python
Flask
TensorFlow
MySQL
Render
AWS, RDS, EC2
GitHub, GitLFS
参考文献
◼ Deep Learning
◼ Flask
開発したプログラム
このアプリの制作期間は、およそ4ヶ月半です。
内訳として、AIモデルの開発には2ヶ月、フロントエンドとバックエンドの実装には1ヶ月半、データベースの作成とAWSのインフラの構築には1ヶ月かかりました。
最初は1ヶ月ほどで完成させる予定でしたが、データセットを使わずに0からWebアプリを開発すると決めたため、知識不足のままで試行錯誤を重ねることになり、結果的にこのように長い期間がかかってしまいました。
フルスタックでコーディングを行い、アウトプットしたい内容は山ほどありますが、この記事では主にAI画像認識モデルのコードをメインに解説していきます。他の内容についてはまた別の記事でまとめる予定です。
◼ AI画像認識モデルの全体的なコード
最終的なコードは下記の通りです。
20種類の野菜を分類するモデルとなっております。
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import os
import cv2
from sklearn.model_selection import train_test_split
from tensorflow.keras import optimizers
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
# GoogleColaboratoryで画像を読み込むためのコード
from google.colab import drive
drive.mount('/content/drive')
# 画像サイズ
img_size = 224
# 画像の読み込みと水増し
img_kabu = []
img_daikon = []
img_ninjin = []
img_satumaimo = []
img_satoimo = []
img_jagaimo = []
img_tamanegi = []
img_asuparagasu = []
img_kyabetsu = []
img_burokkori = []
img_hourenso = []
img_retasu = []
img_kabocha = []
img_kyuri = []
img_tomato = []
img_nasu = []
img_piman = []
img_enokitake = []
img_shimeji = []
img_maitake = []
img_list = [img_kabu, img_daikon, img_ninjin, img_satumaimo, img_satoimo, img_jagaimo, img_tamanegi, img_asuparagasu, img_kyabetsu, img_burokkori, img_hourenso, img_retasu, img_kabocha, img_kyuri, img_tomato, img_nasu, img_piman, img_enokitake, img_shimeji, img_maitake]
vegetables_list = ['かぶ', 'だいこん', 'にんじん', 'れんこん', 'さつまいも', 'じゃがいも', 'たまねぎ', 'アスパラガス', 'キャベツ', 'ブロッコリー', 'ほうれん草', 'レタス', 'かぼちゃ', 'きゅうり', 'トマト', 'なす', 'ピーマン', 'えのきたけ', 'しめじ', 'まいたけ']
for index, vegetable in enumerate(vegetables_list):
dir_name = '/content/drive/MyDrive/vegetable' + '/' + vegetable
path = os.listdir(dir_name)
num_images = len(path)
print(f'{vegetable}の画像枚数: {num_images}')
for i in range(len(path)):
img = cv2.imread(dir_name + '/' + path[i])
# print(dir_name + path[i])
# チャンネルをRGBに変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# リサイズ
img = cv2.resize(img, (img_size, img_size))
# 垂直反転
img = cv2.flip(img, 0)
img_list[index].append(img)
# 水平反転
img = cv2.flip(img, 1)
img_list[index].append(img)
# -45度回転
M1 = cv2.getRotationMatrix2D((img.shape[1]/2, img.shape[0]/2), -45, 1)
img = cv2.warpAffine(img, M1, (img.shape[1], img.shape[0]))
img_list[index].append(img)
# 45度回転
M2 = cv2.getRotationMatrix2D((img.shape[1]/2, img.shape[0]/2), 45, 1)
img = cv2.warpAffine(img, M2, (img.shape[1], img.shape[0]))
img_list[index].append(img)
# 正規化
X_list = []
for img_class in img_list:
X_class = np.array(img_class, dtype=np.float32) / 255.0
X_list.append(X_class)
X = np.concatenate(X_list)
y = np.array([i for i in range(len(img_list)) for _ in range(len(img_list[i]))])
# 訓練データ, 検証データ, テストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
y_train, y_val, y_test = to_categorical(y_train), to_categorical(y_val), to_categorical(y_test)
print('学習に使用するための訓練データ:', X_train.shape[0])
print('ハイパーパラメータの性能を評価するための検証データ:', X_val.shape[0])
print('学習済みモデルの性能を評価するためのテストデータ:', X_test.shape[0])
print('訓練データに対応するラベルのデータ:', y_train.shape)
print('検証データに対応するラベルのデータ:', y_val.shape)
print('テストデータに対応するラベルのデータ:', y_test.shape)
# vgg16のインスタンスの生成
input_tensor = Input(shape=(img_size, img_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(BatchNormalization())
top_model.add(Dense(20, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 15層目までの重みの固定
for layer in model.layers[:15]:
layer.trainable = False
model.compile(loss='categorical_crossentropy', optimizer=tf.keras.optimizers.legacy.SGD(learning_rate=0.01, momentum=0), metrics=['accuracy'])
# 学習過程の取得
history = model.fit(X_train, y_train, batch_size=64, epochs=20, verbose=2, validation_data=(X_val, y_val))
1. データの収集
画像は既存のデータセットを使用せず、icrawlerでBingとGoogleからスクレイピングしました。
from icrawler.builtin import BingImageCrawler
import os
keywords = ['かぶ', 'だいこん', 'にんじん', 'れんこん', 'さつまいも', 'じゃがいも', 'たまねぎ', 'アスパラガス', 'キャベツ', 'ブロッコリー', 'ほうれん草', 'レタス', 'かぼちゃ', 'きゅうり', 'トマト', 'なす', 'ピーマン', 'えのきたけ', 'しめじ', 'まいたけ']
root_dir = 'vegetable'
for keyword in keywords:
vegetable_dir = os.path.join(root_dir, keyword)
if not os.path.exists(vegetable_dir):
os.makedirs(vegetable_dir)
crawler = BingImageCrawler(storage={"root_dir": vegetable_dir})
crawler.crawl(keyword=keyword, max_num=500)
root_dirに任意のディレクトリ名を入れ、keywordsに収集したい画像の名称リストを作成します。max_numに収集したい画像の枚数を指定します。
実行すると、自動的にvegetableディレクトリが作成され、その中にkeywordsで指定した各野菜のディレクトリが作成されます。そして、収集した画像は各野菜のディレクトリへ保存されます。上記コードはBingの例ですが、GoogleImageCrawlerとすれば同様にGoogleからも収集可能です。
max_numを500枚で指定してみましたが、実際に使用できる画像は各野菜50~100枚程度でした。そのため、同じkeywordsで多くの画像を収集するよりも、英語にしたり検索の仕方を工夫すればより多くの画像を収集できます。
2. データの前処理
収集した画像の中には野菜とは全く関係のないものが混ざっていたため、手作業で一枚一枚削除しました。また、人の手や顔が写っているものや、複数の野菜が写っている画像はトリミングを行い、更に画像を増やしました。最終的に各画像枚数は69~280枚、合計で3073枚になりました。

画像枚数に差がある理由としては、最初は各野菜250枚前後を目安にトリミングを行なっておりましたが、この画像加工の作業がかなりキツく時間もかかり、一旦切り上げたためです。自動でトリミングさせるなど、もっといい方法があるかもしれません。
そして、収集した画像だけでは少ないため画像の水増しを行います。
# 画像の読み込みと水増し
img_kabu = []
img_daikon = []
img_ninjin = []
img_satumaimo = []
img_satoimo = []
img_jagaimo = []
img_tamanegi = []
img_asuparagasu = []
img_kyabetsu = []
img_burokkori = []
img_hourenso = []
img_retasu = []
img_kabocha = []
img_kyuri = []
img_tomato = []
img_nasu = []
img_piman = []
img_enokitake = []
img_shimeji = []
img_maitake = []
まず、各野菜の画像データを格納するために空のリストを用意します。
img_list = [img_kabu, img_daikon, img_ninjin, img_satumaimo, img_satoimo, img_jagaimo, img_tamanegi, img_asuparagasu, img_kyabetsu, img_burokkori, img_hourenso, img_retasu, img_kabocha, img_kyuri, img_tomato, img_nasu, img_piman, img_enokitake, img_shimeji, img_maitake]
vegetables_list = ['かぶ', 'だいこん', 'にんじん', 'れんこん', 'さつまいも', 'じゃがいも', 'たまねぎ', 'アスパラガス', 'キャベツ', 'ブロッコリー', 'ほうれん草', 'レタス', 'かぼちゃ', 'きゅうり', 'トマト', 'なす', 'ピーマン', 'えのきたけ', 'しめじ', 'まいたけ']
次に、各野菜の画像リストをまとめるためのimg_listを作成します。
そして、各野菜の名前をまとめたvegetables_listを作成します。
ここからは、実際の画像の読み込みと水増し処理です。
for index, vegetable in enumerate(vegetables_list):
dir_name = '/content/drive/MyDrive/vegetable' + '/' + vegetable
path = os.listdir(dir_name)
num_images = len(path)
print(f'{vegetable}の画像枚数: {num_images}')
for i in range(len(path)):
img = cv2.imread(dir_name + '/' + path[i])
# print(dir_name + path[i])
# チャンネルをRGBに変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# リサイズ
img = cv2.resize(img, (img_size, img_size))
# 垂直反転
img = cv2.flip(img, 0)
img_list[index].append(img)
# 水平反転
img = cv2.flip(img, 1)
img_list[index].append(img)
# -45度回転
M1 = cv2.getRotationMatrix2D((img.shape[1]/2, img.shape[0]/2), -45, 1)
img = cv2.warpAffine(img, M1, (img.shape[1], img.shape[0]))
img_list[index].append(img)
# 45度回転
M2 = cv2.getRotationMatrix2D((img.shape[1]/2, img.shape[0]/2), 45, 1)
img = cv2.warpAffine(img, M2, (img.shape[1], img.shape[0]))
img_list[index].append(img)
osモジュールを使用して、vegetableディレクトリ内の各野菜の画像ファイルを取得します。その後、取得した画像ファイルを順番に読み込みチャンネルをRGBに変換し、画像を指定のサイズにリサイズ、垂直方向と水平方向に反転、-45度と45度に回転させた画像を追加していきます。画像サイズは転移学習モデルに合わせて、224x224にリサイズしています。
水増しした画像はこんな感じです。

このように水増しすることで、1つの野菜に対して複数の画像データを準備し、データの多様性を高めることができます。今回は画像データを4倍に増やし、最終的に画像枚数は12292枚となりました。
続いて、正規化を行います。
正規化とは、データのスケールを扱いやすいものに整えることです。一般的な手法としては最小-最大スケーリングやZスコア標準化があります。
正規化によってデータの範囲を統一することで、モデルの安定性を向上させることができます。また、データの範囲が狭まるため、学習の収束速度が向上する場合があります。今回は最小-最大スケーリングの手法を用います。
# 正規化
X_list = []
for img_class in img_list:
X_class = np.array(img_class, dtype=np.float32) / 255.0
X_list.append(X_class)
np.array()関数を使用して、画像データをNumPy配列に変換します。
dtype=np.float32を指定することで、配列の要素のデータ型をfloat32に設定します。
取得したNumPy配列を255で割ることで、各要素の値を0から1の範囲に正規化します。
これにより、画像データのピクセル値が0から255の範囲で表される問題を回避し、モデルの学習や予測の安定性を向上させます。
なお、np.float32を使用する理由は、浮動小数点数のデータ型であるfloat32が一般的に深層学習モデルに適しているためです。
X = np.concatenate(X_list)
y = np.array([i for i in range(len(img_list)) for _ in range(len(img_list[i]))])
np.concatenateで、X_list内のNumPy配列を連結して、1つの大きなNumPy配列Xを作成します。
np.arrayで、img_listの要素数を利用して、各画像に対するラベルを生成しています。
その後、データの分割を行います。
それぞれのデータの意味は下記の通りです。
- 訓練データ (Training Data)
訓練データは、モデルの学習に使用されるデータセットの一部です。モデルは訓練データを使用してパターンや関係性を学習し、最適な予測モデルを構築します。訓練データはラベル付けされたデータであり、モデルの重みやパラメータの最適化に使用されます。
- 検証データ (Validation Data)
検証データは、モデルの性能評価やハイパーパラメータのチューニングに使用されるデータセットです。訓練データにおいてはモデルが既知のデータに対して適切に学習できたかを確認するため、検証データにおいては未知のデータに対するモデルの予測性能を評価します。検証データを使用してモデルのパフォーマンスを監視し、必要に応じてモデルの調整や改善を行います。
- テストデータ (Test Data)
テストデータは、モデルの最終的な評価と汎化性能の確認に使用されるデータセットです。モデルが実際の運用環境でどれくらいの予測性能を発揮するかを評価するために使用されます。テストデータはモデルの学習やパラメータチューニングには使用されず、予約されたデータです。
訓練データはモデルの学習に使用され、検証データはモデルのパフォーマンスの評価と改善に使用され、テストデータは最終的な評価とモデルの汎化性能の確認に使用されます。
# 訓練データ, 検証データ, テストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
まず、1行目のtrain_test_splitで画像データを訓練データとテストデータに分割します。
test_size=0.2とすることで、訓練データを80%、テストデータを20%に分けることができます。
次に、2行目のtrain_test_splitで訓練データを80%の割合で使用し、残りの20%を検証データとして切り分けます。
この割合は、モデルの性能を評価するために十分なデータを確保しつつ、十分な量のデータをトレーニングに使用することができるバランスの取れた割合とされています。
random_state=42でシード値を固定します。数値は任意の値で構いません。
シード値を固定することにより、乱数生成やデータの分割などのランダムな処理において、常に同じ結果を得るために使用します。
分割後の各データの数値は下記の通りです。

さらに、ラベルデータに対してOne-Hotエンコーディングを行います。
One-Hotエンコーディングとは、各クラスに対して1つの要素が1であり、他の要素が0のベクトル形式で表現されるよう変換することです。
# One-Hotエンコーディング
y_train, y_val, y_test = to_categorical(y_train), to_categorical(y_val), to_categorical(y_test)
通常、クラスラベルは数値ではなくカテゴリ(例えば、かぶ、だいこん、にんじんなど)で表されます。しかし、ディープラーニングモデルでは数値を扱う方が得意です。そのため、より扱いやすい数値データへの形式に変換する必要があります。
3. モデルの生成
今回は転移学習モデルのVGG16を使用してモデルの定義を行います。
VGG16とは、16層の畳み込み層と、3層の全結合層からなる構成を持つ畳み込みニューラルネットワークです
転移学習を用いる理由としては、今回は画像枚数が少ないためです。転移学習モデルで事前学習済みの重みを使用することで、少ない画像枚数でも精度の向上が見込めます。
実際、転移学習なしでモデルの構築を行いましたが、精度は80%程にしかなりませんでした。
また、VGG19も試しましたが、精度はVGG16の方がよかったためこちらを使用しています。
# vgg16のインスタンスの生成
input_tensor = Input(shape=(img_size, img_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
Input関数で入力層を定義します。3はRGBチャンネルの数です。
VGG16クラスのインスタンスを作成していきます。引数の include_top=False は、VGG16モデルの最後の全結合層を含まないことを意味します。weights='imagenet' は、事前学習済みのImageNetデータセットで学習された重みを使用することを指定しています。
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(BatchNormalization())
top_model.add(Dense(20, activation='softmax'))
top_modelという新しいモデルを作成します。SequentialはKerasのモデルを作成するためのクラスです。Flatten層は、畳み込みベースのモデルの出力を1次元のベクトルに平坦化するために使用します。Dense層は、全結合層を追加するために使用します。256 はユニット数を示しており、活性化関数としてReLUを指定しています。
全結合層のユニット数は2のべき乗の64、128、256、512、1024と試し、層を増やしたりもしましたが、最終的に上記コードが一番最適となりました。
活性化関数(Activation function)とは、あるニューロンから次のニューロンへと出力する際に、あらゆる入力値を別の数値に変換して出力する関数のことです。活性化関数には下記のようなものがあります。
- シグモイド関数(Sigmoid Function)
入力を0から1の範囲に変換するS字曲線の形状を持つ関数です。sigmoid関数は、出力を確率として解釈することができます。値の範囲が0から1であるため、二値分類問題などでクラスの確率を表現するのに適しています。
また、入力が大きくなるほど出力が飽和し、勾配がほとんどゼロに近づく傾向があります。これは勾配消失問題を引き起こしやすく、深いニューラルネットワークにおいて学習が困難になることがあります。
- ReLU関数(Rectified Linear Unit Function)
入力が0以下の場合には出力が0になり、0より大きい場合には入力をそのまま出力します。非線形ながら計算コストが低いため、高速な計算が可能です。また、勾配の計算が比較的簡単であり、勾配消失問題を軽減する効果もあります。しかし、負の入力に対しては一切学習が進まないというデメリットがあります。
- Leaky ReLU関数(Leaky Rectified Linear Unit Function)
ReLU関数の改良版で、入力が0以下の場合に微小な負の傾きを持ちます。ReLU関数の問題点である「死んだニューロン(dead neurons)」を回避するために使用されます。
- ソフトマックス関数(softmax)
多値分類問題において出力層でよく使用される活性化関数です。ソフトマックス関数は、入力値を確率分布として解釈するために使用され、各クラスに対する確率を表現します。各要素の値は0から1の範囲になり、すべての要素の総和は1となります。
今回は多値分類なので中間層にReLUを、出力層にソフトマックスを使用しました。一見、Leaky ReLUの方が良さそうに思えましたが、Wikipediaの記述よりこの関数の命名者は、この活性化関数を使う意味はなかったと報告しているそうです。
次に、正則化と過学習について解説していきます。
正則化とは、モデルのパラメータの学習に使われ、過学習を防ぎ汎化能力を高めるために使われます。
過学習とは、トレーニングデータに過剰に適合し、新しいデータに対する予測性能が低下する現象です。正則化はこの問題を軽減するために、モデルの複雑さや重みの大きさにペナルティを課すことで制御します。
正則化にはL1正則化、L2正則化、早期終了、ドロップアウト等ありますが、今回はドロップアウトを使用します。L1正則化、L2正則化も試しましたが、良い効果は得られませんでした。
ドロップアウト(Dropout)とは、モデルの訓練中にランダムにユニットを無効化することで、過学習を防ぐ手法です。これにより、ニューラルネットワークは特定のニューロンの存在に依存できなくなり、より汎用的な(訓練データのみに依存しない)特徴を学習するようになります。
Dropout(rate=0.5)で割合を50%に設定しています。rate=0.1~0.5の間で試し、一番結果が良かった値で設定しています。
続いて、バッチ正規化について解説します。
バッチ正規化(BatchNormalization)とは、モデルの学習の際にミニバッチを平均0、標準偏差が1となるように正規化を行うことで学習を効率的に行う手法です。主な目的は、学習の安定化と高速化のためです。
最後に、出力層を定義します。今回は20クラスの分類のため、最後の層は20にします。活性化関数は上述の通り、ソフトマックスを使用します。
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
VGG16とtop_modelを連結して新しいモデルを作成します。
# 15層目までの重みの固定
for layer in model.layers[:15]:
layer.trainable = False
モデルの15層目までの重みを固定します。これにより、モデルの一部の層のみを再学習させたり、事前に学習された特徴抽出部分の重みを保持しながら、新しいタスクに適した重みを学習することができます。
model.compile(loss='categorical_crossentropy', optimizer=tf.keras.optimizers.legacy.SGD(learning_rate=0.01, momentum=0), metrics=['accuracy'])
モデルのコンパイルを行い、損失関数、最適化アルゴリズム、評価指標を設定します。
- 損失関数(Loss Function)
モデルが学習中に最小化しようとする目的関数です。損失関数は、モデルの予測結果と真の値の差を評価する指標です。多クラス分類の場合、一般的にはcategorical_crossentropyやsparse_categorical_crossentropyなどが使用されます。
- 最適化アルゴリズム(Optimizer)
モデルの重みを更新するための最適化手法です。最適化アルゴリズムは、損失関数の勾配を使用して、モデルの重みを調整していきます。一般的な最適化アルゴリズムには、確率的勾配降下法(SGD)、Adam、RMSpropなどがあります。
- 評価指標(Metrics)
モデルの評価指標です。学習中に監視され、モデルの性能を評価するために使用されます。例えば、正解率(accuracy)や損失値(loss)などが一般的な評価指標です。
最適化アルゴリズムは色々と試してみましたが、SGDが最も良い精度となりました。
また、SGDはずっと下記コードで実行していました。Aidemyの教材から抜粋したコードです。
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=['accuracy'])
実行結果
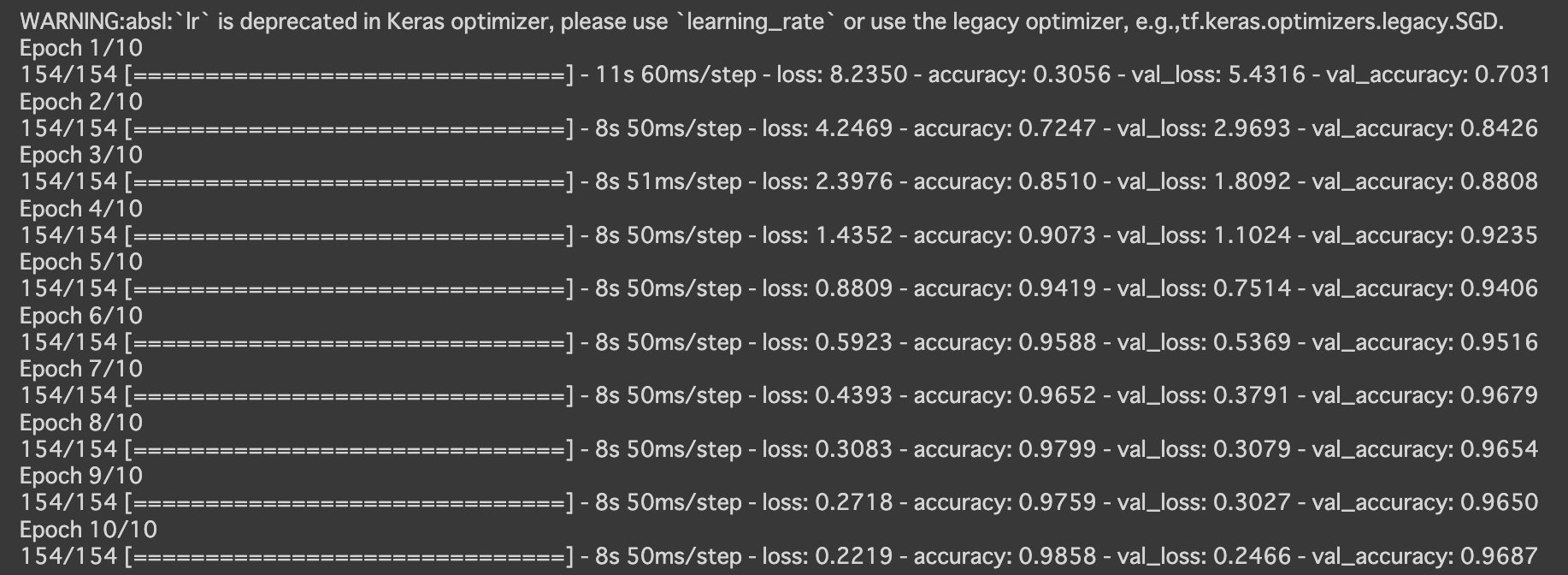
精度は96%と高くそのまま使用していたのですが、ブログの下書きをしていたときにふと気づきました。

ずっと警告文が出ていたことに気づかず、そのまま学習させていました。翻訳すると『警告:absl: 'Ir は Keras オプティマイザーでは非推奨です。「learning _rate」を使用するか、レガシー オプティマイザー (例: tf.keras.optimizers.legacy.SGD) を使用してください。』との事。
特に処理が止まったりすることもなかったため全然気にしていませんでした。指示に従いTensorFlowの公式サイトよりコードの書き方を調べ訂正しました。エラー以外にも、警告文が出ていたらちゃんと確認するのは大事ですね。
4. モデルの学習
いよいよモデルの学習を行います。
# 学習過程の取得
history = model.fit(X_train, y_train, batch_size=64, epochs=20, verbose=2, validation_data=(X_val, y_val))
batch_size、epochs、verboseについて解説します。
batch_sizeとは、モデルが一度に処理するデータの数です。
大きなバッチサイズを選択すると、一度に処理するデータが増えるため、学習が高速化されます。ただし、大きなバッチサイズはメモリの使用量が増え、モデルのパラメータの更新の精度が低下する可能性があります。
一方、小さなバッチサイズを選択すると、メモリの使用量は減少し、パラメータの更新の精度も向上するかもしれません。ただし、学習の進行が遅くなる可能性があります。
一般的な値として16、32、64、128で試してみて、64が最適でした。128にするとColaboのGPU制限がすぐに限界に到達してしまったため、大きなバッチサイズを試してみる際には注意が必要です。
epochsは、訓練データを何回繰り返して学習させるかを指定します。
最初は少ない値0~10で設定し、過学習にならなければ増やしていく感じでいいと思います。最初から50とか100とか設定すると、時間もGPUも無駄になってしまう可能性があります。
verboseは、学習の進行状況の表示モードを指定します。0の場合は表示せず、1の場合は進行状況バーを表示し、2の場合はエポックごとに表示します。基本的にverbose自体設定しなくてもいいのですが、個人的に進行状況バーの表示はいらないので途中から非表示にしました。
最終的な実行結果
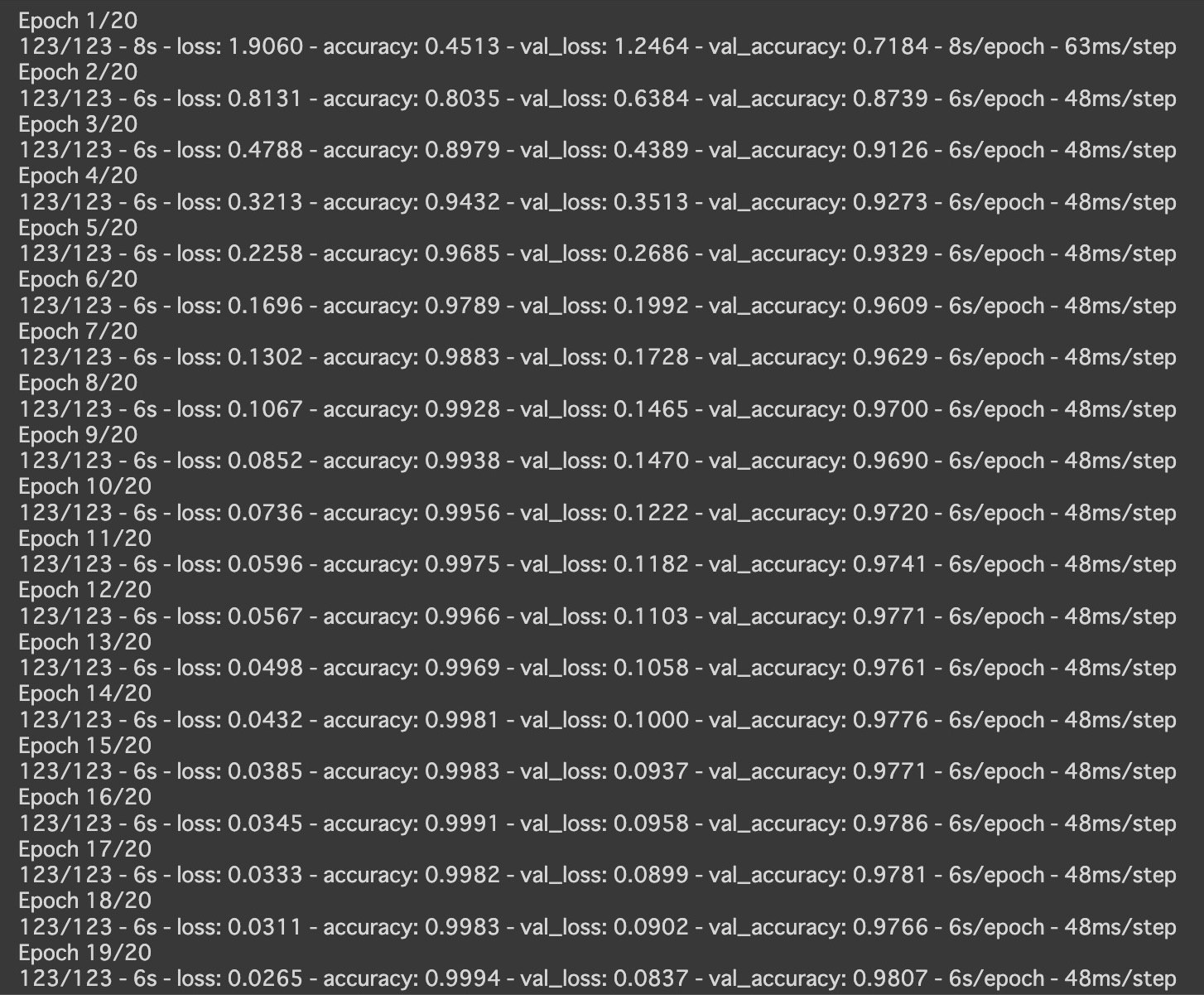
コンパイルのときにコードを訂正したことにより、精度は98%と向上しました!
この結果に至るまでは何十回もやり直し、数ヶ月もの時間がかかり、ColaboのGPU制限に何度も引っかかり、課金してなんとかハイパーパラメータを調整し、ようやく仕上げました。まだまだ精度を上げられそうですが、一旦このモデルでデプロイを行います。
5. モデルの評価
モデルの評価を行います。
上記学習結果をmatplotlibのグラフで可視化していきます。
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
metrics = ['loss', 'accuracy']
plt.figure(figsize=(10, 3))
for i in range(len(metrics)):
metric = metrics[i]
plt.subplot(1, 2, i+1)
plt.title(metric, fontsize = 15)
plt.plot(history.history[metric], label='training')
plt.plot(history.history['val_' + metric], label='test')
plt.legend(loc='best', fontsize = 10)
plt.show()
実行結果

lossの値も0.08と低く、accuracyの0.98と併せて非常にモデルの予測精度が高いことがわかります。
画像データに対して、正解ラベルが当たっているか確認してみます。
# 日本語表記のためにインストール
!pip install japanize-matplotlib
import japanize_matplotlib
# データの可視化
fig = plt.figure(figsize=(10, 4))
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
for i in range(10):
ax = fig.add_subplot(2, 5, i+1)
ax.imshow(X_test[i])
ax.axis('off')
label_index = pred[i]
label_name = vegetables_list[label_index]
ax.set_title(label_name)
plt.suptitle("10 images of test data", fontsize=15)
plt.tight_layout()
plt.show()
実行結果

水増しした画像に対しても、ちゃんと分類できていますね。
新しい画像を入れても分類できるか試してみます。
今回の学習には使用していない新しいだいこんの画像を入れてみました。
import cv2
# 新しい画像の読み込みと前処理
image_path = '/content/drive/MyDrive/vegetable/test_img/daikon.jpg' # 画像のパスを指定
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (img_size, img_size))
img = img.astype(np.float32) / 255.0
img = np.expand_dims(img, axis=0)
# 予測結果の表示
fig = plt.figure(figsize=(8, 4))
ax1 = fig.add_subplot(1, 1, 1)
ax1.imshow(img.squeeze())
ax1.axis('off')
ax1.set_title(vegetables_list[np.argmax(model.predict(img), axis=1)[0]])
plt.tight_layout()
plt.show()
実行結果

ちゃんと正解しています。
他の画像も試して問題ないことを確認しました。
各野菜ごとの正解率を見てみます。
num_classes = 20
# テストデータセットでの予測
y_pred = model.predict(X_test)
predicted_classes = np.argmax(y_pred, axis=1)
# クラスごとの正解数とサンプル数をカウント
class_counts = np.zeros(num_classes)
class_correct = np.zeros(num_classes)
for i in range(len(y_test)):
true_class = np.argmax(y_test[i])
predicted_class = predicted_classes[i]
class_counts[true_class] += 1
if true_class == predicted_class:
class_correct[true_class] += 1
# クラスごとの正解率を計算
class_accuracy = class_correct / class_counts
# クラスごとの正解率を表示
vegetables_list = ['かぶ', 'だいこん', 'にんじん', 'れんこん', 'さつまいも', 'じゃがいも', 'たまねぎ', 'アスパラガス', 'キャベツ', 'ブロッコリー', 'ほうれん草', 'レタス', 'かぼちゃ', 'きゅうり', 'トマト', 'なす', 'ピーマン', 'えのきたけ', 'しめじ', 'まいたけ']
print("各野菜の正解率")
for i in range(num_classes):
print(vegetables_list[i], ': {:.2f}'.format(class_accuracy[i]))
実行結果

かぶとレタスが低いですが、全体的に90%を超えています。
混同行列(正解率、再現率、適合率、F1スコア)の値を確認してみます。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# テストデータの予測
y_pred = model.predict(X_test)
y_pred = np.argmax(y_pred, axis=1)
# 正解率
accuracy = accuracy_score(np.argmax(y_test, axis=1), y_pred)
print('正解率:', accuracy)
# 再現率
recall = recall_score(np.argmax(y_test, axis=1), y_pred, average='macro')
print('再現率:', recall)
# 適合率
precision = precision_score(np.argmax(y_test, axis=1), y_pred, average='macro')
print('適合率:', precision)
# F1スコア
f1 = f1_score(np.argmax(y_test, axis=1), y_pred, average='macro')
print('F1 Score:', f1)
実行結果

どの数値も97%を超えています。
それぞれの意味は下記の通りです。
- 正解率(Accuracy)
モデルが正確に予測した割合を示す指標です。全体の予測のうち、正解した割合を計算します。高い正解率は良いモデルの性能を示しますが、クラスのバランスが偏っている場合には注意が必要です。
- 再現率(Recall)
ポジティブなサンプル(正解クラス)のうち、正しく検出された割合を示す指標です。つまり、実際の正解データのうち、モデルがどれだけ正しく予測できたかを評価します。再現率は、偽陽性を避けることが重要な場合(例: 病気の検出など)に特に重視されます。
- 適合率(Precision)
ポジティブと予測されたサンプルのうち、実際に正解である割合を示す指標です。つまり、モデルがどれだけ正確にポジティブなクラスを予測できたかを評価します。適合率は、偽陽性を避けることが重要な場合よりも、偽陽性を許容できる場合(例: スパムメールの分類など)に重視されます。
- F1スコア(F1 Score)
適合率と再現率の調和平均です。適合率と再現率の両方を考慮した総合的な性能評価指標であり、バランスの取れたモデルの評価に利用されます。F1スコアは、適合率と再現率の両方が高い場合に高い値を示します。
最後に、ヒートマップで可視化します。
from sklearn.metrics import confusion_matrix
import seaborn as sns
# テストデータの予測結果を取得
y_pred = model.predict(X_test)
y_pred = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
# 混同行列を計算
cm = confusion_matrix(y_true, y_pred)
# クラスラベルを指定
labels = vegetables_list
# 混同行列を可視化
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=labels, yticklabels=labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
実行結果

かぶが正解なのに対して、だいこんと分類している数が多いですね。
また、レタスが正解なのに対して、キャベツと分類しているのも多いです。
やはり、見た目が似ているものの分類は苦手なようです。
この結果から、上記でかぶとレタスの正解率が低かった原因がわかりました。
画像枚数が少なかったことも影響しているかもしれません。
6. デプロイ
AIモデルを使用してWebアプリにします。
コードに関しては簡潔に解説します。
from flask import Flask, render_template, request
import tensorflow as tf
import numpy as np
import os
import mysql.connector
app = Flask(__name__)
# AIモデルをロード
model = tf.keras.models.load_model('model.h5')
# 野菜のリスト
labels = ['かぶ', 'だいこん', 'にんじん', 'れんこん', 'さつまいも', 'じゃがいも', 'たまねぎ', 'アスパラガス', 'キャベツ', 'ブロッコリー', 'ほうれん草', 'レタス', 'かぼちゃ', 'きゅうり', 'トマト', 'なす', 'ピーマン', 'えのきたけ', 'しめじ', 'まいたけ']
# index.htmlを表示
@app.route('/')
def index():
return render_template('index.html')
# MySQLに接続するための情報
config = {
'user': "root",
'password': os.environ["PASSWORD"],
'host': os.environ["HOST"],
'database': os.environ["DATABASE"],
'raise_on_warnings': True
}
# result.htmlを表示
@app.route('/result', methods=['POST', 'GET'])
def result():
if 'file' not in request.files:
return "No file uploaded"
file = request.files['file']
# ファイルをアップロードディレクトリに保存
file_path = os.path.join('static', 'uploads', file.filename)
file.save(file_path)
# 画像を前処理
img = tf.keras.preprocessing.image.load_img(file_path, target_size=(224, 224))
img_array = tf.keras.preprocessing.image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
# AIモデルを使用して予測を行う
predictions = model.predict(img_array)
predicted_label = labels[np.argmax(predictions)]
# 予測されたラベルに基づいてデータベースからレシピを取得
conn = mysql.connector.connect(**config)
cursor = conn.cursor()
cursor.execute("SELECT * FROM recipes WHERE vegetable = %s", (predicted_label,))
recipes = cursor.fetchall()
conn.close()
# アップロードしたファイルを削除
os.remove(file_path)
return render_template('result.html', label=predicted_label, recipes=recipes)
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8000))
app.run(host='0.0.0.0', port=port)
Flaskでエンドポイントを設定し、予め作成したindex.html(ホーム画面)とresult.html(レシピ画面)を表示できるようにしています。また、MySQLには環境変数で接続できるようにしております。画像がアップロードされたらAIモデルを通して分類し、分類した野菜からレシピデータの内容を表示する処理を行います。
レシピデータは自作で作成しました。MySQLでrecipesというデータベースを作成した後、INSERT文で一件一件コマンドで入力しました。クックパッドのAPIを使う方法や、データベースの作成時にGUIから簡単に操作する方法もありましたが、SQLの勉強になると思い、全部コマンドでやりきりました。
また、RenderがMySQLに対応していなかったため、MySQLのサーバーはAWSのRDSで構築しました。
もし、初心者がRenderでデータベースを構築する時は素直にPostgreSQLで構築することをおすすめします。RDSでのサーバーの構築は本当に難しく、公式の英語のドキュメントを翻訳しながらなんとかできたレベルです。
PostgreSQLとMySQLの違いについてですが、下記の通りです。
- PostgreSQL
複雑なクエリや大規模なデータベースを扱うことができる機能豊富なデータベースです。
- MySQL
設定や管理が比較的簡単で速い上、信頼性が高く、ナレッジが普及しているシンプルなデータベースです。
今回はデータ数も少なく、処理速度を重視したいためシンプルなMySQLを選びました。
本題に入り、Renderへデプロイします。
まずはローカルリポジトリの内容をリモートリポジトリへプッシュします。
しかし、ここで問題が発生しました。
AIモデルの容量が139MBあったのですが、GitHubで扱える個々のファイルサイズは100MBまでのようでプッシュできませんでした。
AIモデルの容量がなぜこんなにも重いのかわからず、転移学習のせいかなと思いAIモデルを作り直してみました。
結果、精度80%程度で容量33MBのモデルになりました。
さすがにこれでは使えないと思い、なんとか元のAIモデルを使用できないか調べたところ、GitLFSというサービスを通してプッシュすれば容量の大きいファイルを扱えるとの事を知りました。
ここで少し苦戦しましたが、なんとか無事に転移学習したAIモデルをプッシュすることができました。
続いて、Renderへログインしダッシューボードの上部のNew → Web Serviceの順に選択します。
デプロイしたいGitHubのリポジトリを選択し、Connectを押します。
Name : Delisearch(任意のアプリ名)
Region : Singapore(Southeast Asia)
Runtime : Python3
Start Command : python app.py
Freeプランを選択しCreate Web Serviceを押します。
デプロイが始まりますが、エラーが出たら止まるのでlogに従って訂正してください。
さらに、環境変数の設定をします。
私は自分でFlaskのコードを書いたので、.envファイルを作成してデバックモードを使用しながら開発しましたが、Aidemyの教材からコピペしたものを使用する際はこの工程は飛ばしていいと思います。
Environment → Environment Variables → Add Environment Variable
で下記画面になります。

データベースを使用する場合はここでサーバーの接続情報を入れます。
os.environを通して繋いでくれます。
| Key | Value |
|---|---|
| FLASK_APP | app.py |
| FLASK_DEBUG | 0 |
| DATABASE | recipes |
| HOST | データベースのホスト名 |
| PASSWORD | データベースのパスワード |
FLASK_APPにはFlaskのコードを書いたファイル名のapp.pyを入れます。
FLASK_DEBUGは0にするとデバッグモードがオフになり、1にするとオンになります。
開発環境ではデバックモードはオンに、本番環境ではオフにします。
FLASK_ENV=development/productionでデバッグモードをオン/オフに切り替える方法がありますが、Flask2.3以降ではFLASK_DEBUGで設定する方法が推奨されています
本来であればuserも環境変数で設定するのですが、RDSでデータベースを作成したときにユーザー名を深く考えずrootにしてしまい、os.environで接続できなくなってしまったため直接入力しています(後から変更できませんでした)。そのため、管理者権限のroot(ローカルのサーバー)ではありません。rootユーザーは本番環境では使いませんのでご注意ください。
環境変数の設定とデプロイが完了し、Webアプリとして公開できました。
ここまでが本当に長かったです。デザインのこだわった点は、全体的に赤みを帯びた色(食欲をそそる色)にしております。
ちゃんと使えるか試してみます。

学習に使用していないキャベツの画像を入れ、「レシピを検索」を押します。

実行結果

無事にレシピ検索ができました。
他の野菜も一通り試し、ちゃんと分類できるのを確認しました。
ちなみに、レスポンシブデザインにしているのでスマホからでも使用可能です。

下記リンクからぜひ、利用してみてください。
🔗 Delisearch
苦労した点
苦労した点はたくさんあります。
収集した画像の加工だったり、AIモデルの精度を精度を上げるために何度も構築し直したり、
SQLを特に調べないまま使うと決めデータベースとサーバーの構築に苦労したり、
AIモデルがGitHubにプッシュできなくて絶望的な思いをしたり、
ようやくRenderにデプロイできて終わったと思ったらメモリの容量不足でサーバーが落ちたり(無料プランから課金してサーバーを強化しました)
ただ、全てに共通して言えることはちゃんと調べれば解決する方法はあります。
AIモデルも最初の試作は精度20%程度でした。
それからどうやったら精度が上がるのか調べて工夫して、
1行1行のコードの意味をしっかり理解して、
自分で調整できるものは記録を残しながら順番に試してより良い手法を選択して、
エラーが出たらよくわからないままにせず解決策を探して、
そうやって、ひとつひとつの問題を投げ出さずにちゃんと向き合うことでよりよい結果を得られました。
今後の課題
Delisearchはもともと転職のためのポートフォリオとして開発したのですが、今後は下記機能を追加してアップデートしていきたいです。
- 野菜以外の食材の追加
- レシピデータの追加
- AIモデルの精度を上げる
- 様々な郷土料理を取り入れ、メモ書きを追加
- ログイン機能を追加
- アップロードした画像の一覧を追加
- 画像をまとめてアップロードできるようにする
- 一枚の写真から食材をまとめて検出する(物体検知)
まだまだやれることはたくさんあります。
Grad-CAMでAIが画像内のどの箇所が推測の根拠となったのかを可視化する手法も取り入れてみたいし、スマホアプリ化にも挑戦してみたいです。
まとめ
結果的に精度の高いAIモデルは完成しましたが、全体像が見えないまま開発を進めてしまい時間がかかってしまったのが反省点です。
最初に使用する言語や手法、ライブラリ毎の特徴や違い、デプロイまでの手順で何が必要なのか等々、しっかりと下調べしてから計画を建ててから取り組むことが大事です。
コードもコピペして終わりではなく、その意味をちゃんと把握することでエラーが出たときの対処方法もわかるようになってきます。
また、開発する上で作業記録を残すことをおすすめします。ハイパーパラメータの値や手法を変えて精度がどう変わったか、エラーの内容と解決方法、どの点に苦労したか、作業した記録を随時残すことで、後に正確な情報を振り返ることができます。実務を想定してGitHubを使いながらやるのもいいです。
そして、ブログでもSNSでもいいので、アウトプットすることでより理解が深まります。
おわりに
最初は自分のために独りで始めた挑戦でした。
仕事の拘束時間が長く、朝7時には家を出て帰るのは21時半頃で、残業も夜勤もあり不規則な生活のなかで勉強時間を確保してました。時間がないのを言い訳にしたくなく、仕事の休憩時間や帰宅後も余裕がある限り勉強しました。
休日も一日中作業して、エラーが解決できなくて全くなにも進まない日もありました。
正直、辛くて挫折しそうになったときもありました。
しかし、エンジニアになると周りに宣言してたことにより、多くの人が応援してくださいました。
そして、人が人を繋いでくださり、とあるエンジニアの方と出会いました。
その方に開発途中のコードを見てもらい、たくさん助言をいただき、たくさん怒られました笑
初心者だからわからなくていいということはなくて、
わからないことを自分で調べて理解する努力ができるのが、
エンジニアとして当たり前のことなんだと改めて気付かされました。
私は、その方と周りの協力があったおかげで最後まで諦めず頑張ることができました。
本当に感謝しております。
これからも継続して勉強し、
できることを増やし、
自分の開発したもので、
自分のアウトプットした内容で、
誰かの役に立てたら嬉しいです。
長い記事となってしまいましたが、最後までお読みいただきありがとうございました。